【云存储】主流分布式文件系统介绍
目录
1、引言
2、云存储与分布式文件系统
2.1、云存储
2.2、分布式文件系统
3、Google的三大云计算与云存储论文
3.1、The Google File System(谷歌文件系统)
3.2、MapReduce:Simplified Data Processing on Large Clusters(MapReduce:大型集群上的简化数据处理)
3.3、Bigtable: A Distributed Storage System for Structured Data(Bigtable:一种用于结构化数据的分布式存储系统)
3.4、三篇论文的重要性
4、主流分布式文件系统介绍
4.1、GFS
4.2、HDFS
4.3、Ceph
4.4、GlusterFS
4.5、Lustre
4.6、GPFS
4.7、FastDFS
4.8、淘宝TFS
4.9、腾讯TFS
5、最后
C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...) https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具案例集锦(专栏文章正在更新中...)https://blog.csdn.net/chenlycly/article/details/131405795 随着信息化程度的不断提高以及云计算技术的普及,全球数据日益膨胀。面对当前PB级的海量数据存储需求,传统的存储系统已无法满足需求,其在容量和性能的扩展上存在很大的瓶颈。云存储以其扩展性强、性价比高、容错性好等优势得到了全面的应用,广泛地应用到各大互联网系统中。今天我们就来讲讲支撑云存储的几个主流的分布式文件系统,以供借鉴和参考。
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具案例集锦(专栏文章正在更新中...)https://blog.csdn.net/chenlycly/article/details/131405795 随着信息化程度的不断提高以及云计算技术的普及,全球数据日益膨胀。面对当前PB级的海量数据存储需求,传统的存储系统已无法满足需求,其在容量和性能的扩展上存在很大的瓶颈。云存储以其扩展性强、性价比高、容错性好等优势得到了全面的应用,广泛地应用到各大互联网系统中。今天我们就来讲讲支撑云存储的几个主流的分布式文件系统,以供借鉴和参考。
1、引言
随着互联网技术与系统的发展、云计算与大数据技术的普及与持续应用,各种大型的互联网系统每天都会产生数以亿计的海量数据,这些海量数据的存储、管理与查询均通过云存储及分布式文件系统技术去完成的。
大家常用的淘宝和京东等大型电商系统,后台维护海量的商品信息、图片信息、交易及物流数据;日常使用的微信,后台需要存放海量的图片文字聊天信息和朋友圈数据,以及视频号视频数据;大家天天刷的抖音、快手短视频系统,后台需要维护海量的短视频文件、直播、带货商品数据。这些海量的数据都是承载在云存储与分布式文件系统技术上的,通过云存储和分布式文件系统去存储管理。
2、云存储与分布式文件系统
2.1、云存储

云存储是实现云计算系统架构中的一个重要组成部分。随着信息技术的不断发展,全球数据规模日益膨胀。由于传统的SAN (Storage Arew Network) 或NAS(Network Attached Storage) 存储技术在存储容量和可扩展性上存在瓶颈,并且在硬件设备的部署数量上也存在一定限制,这使得用户升级系统的成本大大增加。云存储采用可扩展的分布式文件系统,并使用廉价的Pc机来进行系统部署,从而使得整体存储架构能够保持极低的成本。
云存储是通过集群应用、网格技术、分布式文件系统等,将网络中大量类型各异的存储设备整合起来,并对外提供数据存储和业务访问功能的系统。简单来说,云存储是对虚拟化存储资源的管理和使用。
区别于传统的存储技术,云存储提供了更好的可扩展性,当需增加存储能力时,只需添加服务器即可实现,而不需要对存储系统的结构进行重新设计;同时随着存储能力的增加,云存储系统的性能不会下降。
云存储专注于解决云计算中海量数据的存储问题,它既可以给云计算技术提供专业的存储解决方案,又可以独立发布存储服务。云存储将存储作为服务,它将分别位于网络中不同位置的大量类型各异的存储设备通过集群应用、网格技术和分布式文件系统等集合起来协同工作,通过应用软件进行业务管理,并通过统一的应用接口对外提供数据存储和业务访问功能。在使用一个独立的存储设备时,我们需要了解该设备的型号、接口以及该设备所使用的传输协议。
云存储系统具有良好的可扩展性、容错性,以及内部实现对用户透明等特性,这一切都离不开分布式文件系统的支撑。
2.2、分布式文件系统
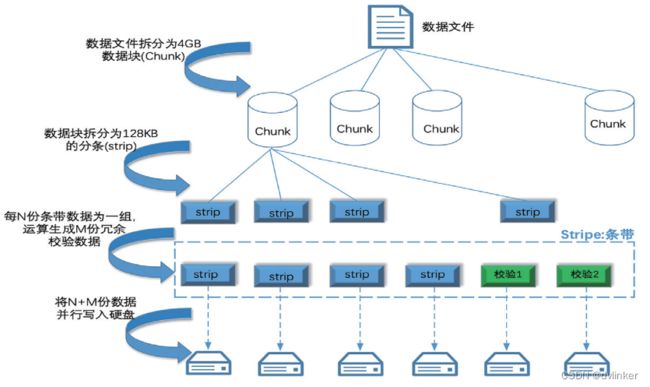
分布式文件系统(Distributed File System,简称DFS)是一种将文件分布存储在多个计算机节点上的文件系统。它通过将文件划分为多个块,并在不同的节点上存储这些块,实现了文件的并行存储和访问。DFS提供了一种透明的文件访问方式,使得用户可以像访问本地文件一样访问分布在多个节点上的文件。
分布式文件系统可以有效解决数据的存储和管理难题,将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统,众多的节点组成一个文件系统网络。每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输。人们在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据。分布式文件系统具有高可靠性、可扩展性和高性能的特点,可以应对大规模数据存储和访问的需求。
现有的云存储分布式文件系统有GFS、HDFS、Lustre、FastDFS、GlusterFS、GPFS、Ceph、淘宝TFS和腾讯TFS等,本文将对这些分布式文件系统进行大概的介绍。
3、Google的三大云计算与云存储论文
说到云存储与分布式文件系统,就必须要讲一讲Google公司发表的三篇影响深远的云计算与云存储相关论文:《MapReduce:Simplified Data Processing on Large Clusters》、《The Google File System》、《Bigtable: A Distributed Storage System for Structured Data》。这三篇论文对云计算和云存储分布式文件系统的发展起到了决定性作用。
3.1、The Google File System(谷歌文件系统)

这篇论文是由Sanjay Ghemawat、Howard Gobioff和Shun-Tak Leung共同编写,发表于2003年11月。这是Google分布式文件系统的雏形,它旨在解决分布式存储问题,以应对Google的大规模数据集群以及存储机器发生故障的情况。 GFS可以处理超过100TB以上的数据集,加速数据读取和写入,处理大规模数据存储集群。GFS设计灵活,支持扩展性好,可通过多个GFS实例在网络上运作,广泛地应用于谷歌搜索、谷歌地球、YouTube等Google产品中。
3.2、MapReduce:Simplified Data Processing on Large Clusters(MapReduce:大型集群上的简化数据处理)
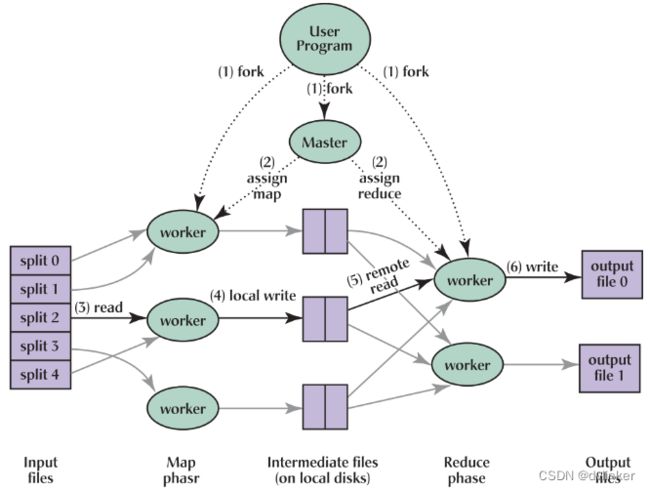
这篇论文是Google公司云计算领域中的重要代表作之一,它的作者是Jeffrey Dean和Sanjay Ghemawat,发表于2004 年12月,它主要讨论在大规模集群下一种简化了的数据处理模型。MapReduce是一种大规模数据处理技术,其主要目的是在一个大型集群中分布式与并行执行(Distribute and Parallel Execution)处理任务。
MapReduce将计算逻辑分解成两个部分:Map阶段和Reduce阶段。在Map阶段,数据被按键提取;在Reduce阶段,数据被收集以计算结果。这两个阶段可以在许多物理节点上并行执行,大大提高了计算效率。此外,该论文引入了GFS分布式文件系统,为MapReduce提供了强大的文件系统支持。
3.3、Bigtable: A Distributed Storage System for Structured Data(Bigtable:一种用于结构化数据的分布式存储系统)
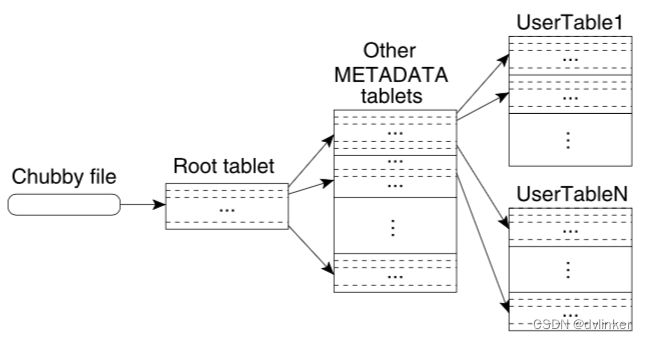
这篇论文发表于2006 年,Fay Chang等作者介绍了Bigtable(BigTable是Google公司发布的一种存储结构化数据的海量分布式系统)。BigTable可以作为一个高效、可扩展和完全分布式的数据存储系统,适用于多种场景,如谷歌地图、谷歌搜索等,拥有与Google公司在搜索技术领域的强大实践和数据分析能力。
BigTable的特点是具备高可靠性、支持自动切换控制,负责数据自动均衡,允许按行键进行数据存储,并可以处理多用户访问数据的问题BigTable还支持在内存中缓存销毁过的数据和对未来数据的预测,并能够并行部署在上千个计算节点上。
3.4、三篇论文的重要性
这三篇论文的发表,基本上就标志着整个大数据和云存储时代的到来,我们一般也把它们称为是大数据领域的三驾马车。第一篇论文解决的是分布式存储的问题;第二篇论文解决的是分布式计算的问题;第三篇论文解决的是大规模结构化数据的存储和查询问题。Google 在发表这些论文之前内部已经构建出了相应的系统,而且在公司内部得到了广泛的应用。
这三篇论文涵盖了Google公司当时在云计算和大数据领域的最佳技术实践,让读者深入了解了Google的MapReduce、GFS和Bigtable技术的内在实现机制。这些技术在设计上强调了分布式和并行计算的重要性,并广泛应用于Google的搜索引擎、广告显示等业务中,为广大用户提供了高效、可靠、具有弹性的云计算服务。
毫无疑问,这三篇论文在云计算与大数据领域均具有重要的参考价值,对分布式文件系统的发展起到了至关重要的推动作用,后续发展起来的多个分布式文件系统均借鉴了GFS中的设计理念和思想!
4、主流分布式文件系统介绍
云存储系统具有良好的可扩展性、容错性,以及内部实现对用户透明等特性,这一切都离不开分布式文件系统的支撑。现有的云存储分布式文件系统包括GFS、HDFS、Lustre、FastDFS、PVFS、GPFS、PFS、Ceph和TFS等。它们的许多设计理念类似,同时也各有特色。下面对现有的分布式文件系统进行详细介绍。
4.1、GFS
GFS(Google File System)是Google用C++开发的分布式文件系统,发布于2003年,它是为了解决Google内部海量数据存储和处理的问题而开发的。GFS的设计目标是能够在廉价的硬件上运行,并且能够处理PB级别的数据。
到目前为止,Google主流的开发语言仍然是C++,大部分开源项目均是使用C++实现的,比如大家熟知的开源浏览器项目Chromium(Chrome浏览器)、开源实时音视频处理开源库WebRTC。
GFS采用了分布式存储和处理的方式,将数据分散存储在多个节点上,同时提供了高可靠性、高可扩展性和高性能的特性。GFS的核心思想是将大文件分割成多个块(chunk),每个块都会被复制多份存储在不同的节点上,以保证数据的可靠性。同时,GFS还提供了多种数据访问方式,包括随机访问和顺序访问,以满足不同的应用需求。GFS还提供了一些高级特性,比如快照、数据迁移、数据备份等,以提高系统的可靠性和可用性。
GFS采用了主从结构,由一个主节点和多个从节点组成,主节点负责管理整个文件系统,维护文件系统的元数据信息,从节点则负责存储数据块,并提供数据读写服务。GFS还采用了一些优化策略,如数据本地性优化、块迁移等,以提高数据访问效率和性能。
GFS在Google公司内部被广泛应用,已经成为Google大规模数据处理和分析的重要基础设施之一,广泛地应用于谷歌搜索,谷歌地球,YouTube等Google产品中。GFS的应用范围广泛,包括搜索引擎、大数据分析、科学计算等领域。同时,GFS发布时间较早,也成为了众多开源分布式文件系统的设计和实现的重要参考,后来发展起来的很多分布式文件系统均借鉴了Google相关的论文和技术文档中的实现方案和设计思想。
GFS主要应用于大规模数据处理、分析和存储等方面,而接下来说到的HDFS,则更加适用于海量数据的存储和访问。
4.2、HDFS
2003年谷歌发表了GFS论文,向业界介绍了其分布式文件系统设计方案。当时,著名的开源搜索引擎Apache Lucene的作者Doug Cutting也正在被同样的问题所困扰,看到谷歌的这篇论文后,他很吃惊,这正是他所需要的!于是,以此GFS的设计为蓝图,他开始用Java实现一个分布式文件系统,这就是后来的Hadoop HDFS。

HDFS(Hadoop Distributed File System)是Hadoop生态系统中的一个开源分布式文件系统,用于存储和处理大规模数据集。它是基于Google的GFS(Google File System)设计的,具有高可靠性、高可扩展性和高容错性等特点。
HDFS将大文件分割成多个块(默认大小为128MB),并将这些块存储在不同的节点上,以实现数据的分布式存储和处理。它采用主从架构,其中有一个NameNode负责管理文件系统的命名空间和块的位置信息,而多个DataNode负责存储实际的数据块。
HDFS是一个高容错性、高可靠性、高扩展性的系统。它可以自动进行故障恢复,具有数据冗余备份机制,能够在节点故障时快速进行数据迁移和备份。同时,它也支持多种数据访问协议,包括Hadoop的API、WebHDFS、FTP等。它被广泛应用于大数据处理、机器学习、人工智能等领域。
HDFS存储非常大的文件,比如成百上千MB、GB,甚至TB级别的文件, 一次写入多次读取,可以做到低成本部署,可以运行在廉价PC设备上,不需要特别高的配置。但不适合大量小文件,不支持频繁任意修改。延时要求在毫秒级别的应用,不适合采用 HDFS,HDFS是为高吞吐数据传输设计的,延时较高。
4.3、Ceph
Ceph是Califomia大学Santa Cruz分校的Sage Weil博士设计的一种基于Ceph对象存储的分布式文件系统。Ceph云存储文件系统的主要目标是设计基于POSIX的无节点故障分布式文件系统,并且数据文件具有容错和无缝复制功能。
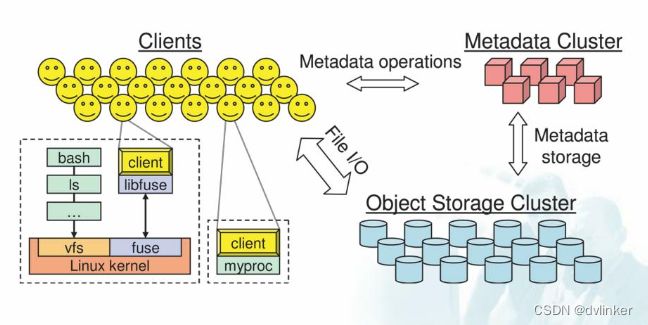
Ceph文件系统提供了一个统一的命名空间,可以跨多个节点和存储池访问数据。CephFS可以通过多种方式与应用程序和操作系统集成,例如使用NFS、CIFS/Samba或FUSE。CephFS提供了一个类似于传统本地文件系统的接口,但它是在多个存储节点上分布式存储和管理数据。Ceph使用RADOS(可扩展对象存储)作为其后端存储,这使得它能够提供高可用性、高性能和可扩展性,可以支持PB级别的存储容量和数千个客户端。
Ceph支持POSIX文件系统接口,这使得它能够与现有的应用程序和工具集成。它还提供了许多高级功能,如快照、克隆、多协议支持等。CephFS还具有自动数据分布和负载均衡功能,这使得它能够在多个节点上平衡数据负载,从而提高性能和可靠性。
Ceph的优势在于它的扩展性,它的性能随着磁盘数量线性增长,因此在多机的情况下,RBD理论的IOPS和吞吐率会高于单机的RAID。但是Ceph的性能还是受限于网络的带宽。使用Ceph能够降低硬件成本和运维成本。
CephFS是一个开源项目,它是Ceph存储系统的一部分,由Ceph社区维护和支持。目前Ceph也是OpenStack的主流后端存储,随着OpenStack在云计算领域的广泛使用,Ceph已经被广泛应用于云计算、大数据和高性能计算等领域。Ceph目前已经被开源社区大量的采用,市场上也出现了很多基于Ceph的存储系统于产品。Ceph主要是面向企业级的存储,目前国内携程、乐视、有云、宝德云、联通等都在使用Ceph 存储集群方案。
4.4、GlusterFS
GlusterFS是一个开源分布式文件系统,通过RDMA和TCP/IP方式将分布到不同服务器上的存储空间汇集成一个大的网络化并行文件系统。GlusterFS主要由 Z RESEARCH 公司负责开发。GlusterFS 具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS 可以将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据,可为各种不同的数据负载提供优异的性能。
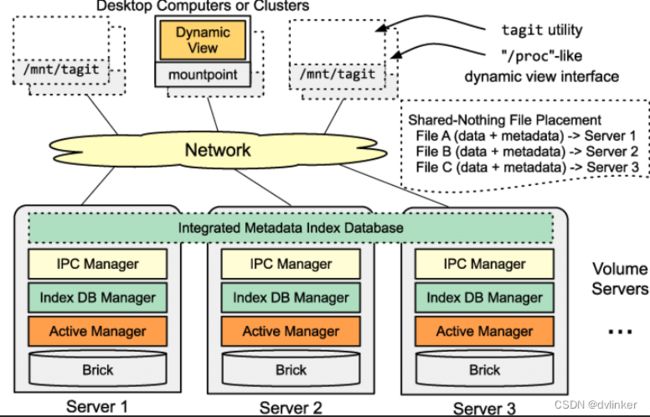
GlusterFS 主要由存储服务器(Brick Server)、客户端以及 NFS/Samba 存储网关组成。在GlusterFS 架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。
GlusterFS 支持 TCP/IP 和 高速网络互联。客户端可通过原生 GlusterFS 协议访问数据,其他没有运行 GlusterFS 客户端的终端可通过 NFS/CIFS 标准协议通过存储网关访问数据。存储服务器主要提供基本的数据存储功能,客户端弥补了没有元数据服务器的问题,承担了更多的功能,包括数据卷管理、I/O 调度、文件定位、数据缓存等功能,利用 FUSE(File system in User Space)模块将 GlusterFS 挂载到本地文件系统之上,来访问系统数据。
GlusterFS支持多种协议,包括NFS、CIFS、Gluster Native和Hadoop HDFS。它还提供了各种管理工具,包括CLI和Web界面,易于管理和监控。GlusterFS适用于需要存储大量数据、需要高可用性和可扩展性的场景,比如云存储、大数据分析、虚拟化等。
GlusterFS直接摒弃了元数据集中管理的架构,而是采用了思想更为超前的去中心化架构。任何一个节点都是对等的,每个节点的目录属性里面存储了自己的元数据,大家通过共识机制,而非管理机制,那么客户端“只需要遵循共识机制来访问集群的数据节点。GlusterFS想通过去中心这种方式,避开传统分布式文件系统的因为单点故障而高度依赖的高可用架构所带来的复杂度。
4.5、Lustre
Lustre是一种基于对象存储技术的高性能并行分布式文件系统,主要用于大规模计算集群、高性能计算和数据中心存储。它可以在数千台服务器之间分布数据,实现高可用性、高性能和高扩展性。
Lustre最初由Sun Microsystems开发,现在由OpenSFS和Intel等公司维护和开发。目前,该文件系统已经广泛用于国外许多高性能计算机构,如美国能源部、Sandia国家实验室、Pacific Northwest国家实验室等。全球超级计算机500强中有多家采用的都是Lustre文件系统。
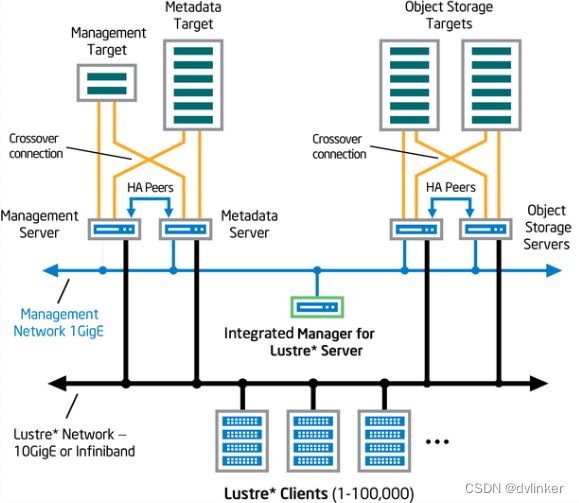
Lustre文件系统的大文件性能良好 ,其通过基于对象的数据存储格式,将同一数据文件分为若干个对象分别存储于不同的对象存储设备。大文件I/O操作被分配到不同的对象存储设备上并行实施,从而实现很大的聚合带宽。此外,由于Lustre融合了传统分布式文件系统的特色和传统共享存储文件系统的设计理念,因此其具有更加有效的数据管理机制、全局数据共享、基于对象存储、存储智能化,以及可快速部署等一系列优点。
尽管如此,由于Lustre采用分布式存储结构将元数据和数据文件分开存储,访问数据之前需要先访问元数据服务器,这一过程增加了网络开销,从而使得Lustre的小文件I/O操作性能较差。
Lustre文件系统的设计目标是提供高性能、可扩展性和可靠性。它使用分布式元数据和数据存储,可以支持PB级别的数据存储和处理。Lustre还支持POSIX、MPI-IO等多种文件系统接口,使其适用于各种科学计算和数据分析应用程序,目前已被广泛用于高性能计算、科学计算和大数据分析等领域。
4.6、GPFS
GPFS(General Parallel File System)是一种高性能并行文件系统,由IBM公司开发,它最初是为IBM的超级计算机设计的,旨在提供高性能、高可靠性和可扩展性。现已成为开源软件,已被广泛地应用于多种大型集群、超级计算机以及需要高性能和可靠性的企业应用中。
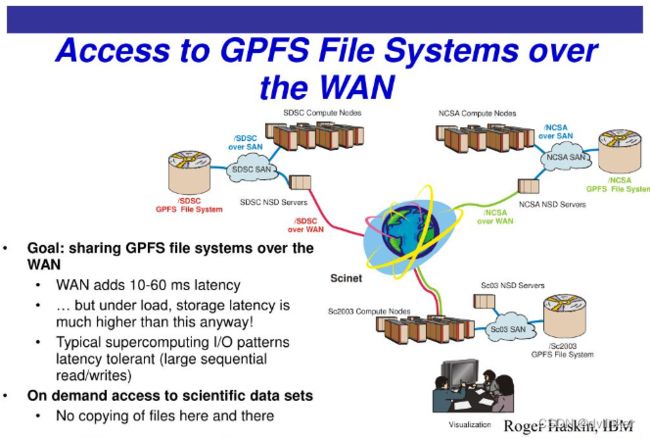
在系统结构上,GPFS主要借鉴了IBM Linux集群系统中的虚拟共享磁盘技术,计算节点可以通过使用交换网络来同时并行访问系统中多个磁盘中的数据,并依赖这一访问方式来实现较高的I/O带宽。
GPFS提供了高效的文件共享和数据访问方式,支持多个节点同时读写同一文件,同时可以提供高可靠性的数据保护,如镜像、备份和恢复。GPFS采用了先进的数据分布和存储技术,可以将数据分散到多个磁盘和节点上,从而提高了数据访问速度和可用性。它还支持多种文件系统接口,如POSIX、MPI-IO和NFS等,使其易于集成到现有应用程序中。
GPFS的主要特点是通过循环的方式将大文件存储在不同的磁盘上,同时通过合并操作来处理小文件的读写,使用动态选举的元数据结点来管理元数据。此外,GPFS还具有基于日志的失效节点的自动恢复策略以及集中式的数据锁机制。
4.7、FastDFS
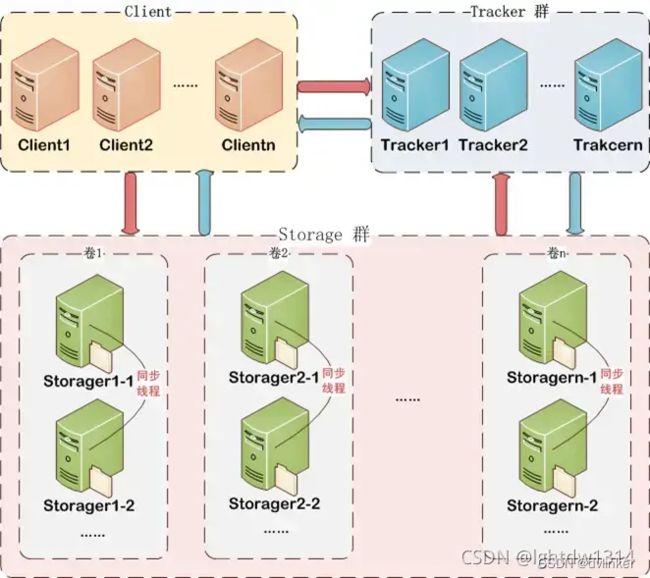
FastDFS是一款开源轻量级分布式文件系统,由时任淘宝资深技术专家、开发平台部资深架构师的余庆开发,于2008年7月发布。它主要用于大规模分布式存储和文件管理,它提供了高可用性、高性能和可扩展性的特点,适用于存储大量的文件,并且可以快速访问和检索这些文件。
FastDFS用纯C语言实现,支持linux、freeBSD、AIX等unix系统,功能包括文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题,特别适合以文件为载体的在线服务,如相册网站、视频网站等。
FastDFS架构由一个或多个跟踪器(tracker)服务器和多个存储节点(storage node)组成。跟踪器服务器负责管理文件上传、下载、删除等操作的元数据信息,而存储节点则负责实际存储文件的内容。通过跟踪器服务器,客户端可以找到存储节点,进行文件的上传和下载等操作。
目前国内使用FastDFS的厂商比较多,比如大家熟知的支付宝、京东商城、赶集网、迅雷、58同城、51CTO、UC等。
4.8、淘宝TFS
TFS(Taobao File System)是淘宝自主研发的一个高可扩展、高可用、高性能、面向互联网服务的的分布式文件系统,针对海量小文件的随机读写访问性能做了特殊优化,承载着淘宝主站所有图片、商品描述等数据存储。TFS主要解决了海量文件存储、访问、管理和分发的问题,其设计目标是提供高可用性、高性能、高扩展性和容错性的分布式文件系统。TFS采用了多个特性来实现这些设计目标,如分布式存储、多副本备份、多级缓存、动态负载均衡、智能文件路由等。TFS主要应用于淘宝的存储和图片服务器,能够支持亿级并发访问和海量文件存储。
淘宝网最早采用NetApp提供的网络存储设备,但是在2006~2007年期间,由于数据量的急剧膨胀,我们面临着系统更新换代的压力,而由于应用连接数量和文件数量的限制,实际上简单的升级已经变得非常昂贵且得不偿失了。淘宝系统中的商品图片、商品描述、交易快照、社区图片等数据,一个突出特点是单个文件尺寸较小,通常不大于1MB,但是数量巨大,传统的文件系统或者网络存储设备很难解决类似的问题。
数据是淘宝应用的核心,在这方面淘宝需要提供更加安全、高效、廉价的解决方案,需要发展自己的技术,更加适应淘宝网自身的应用特性和发展趋势。经评估,当时已有的一些开源分布式文件系统都无法完全满足需求。所以决定搞自主研发,正好2007年Google公布了GFS(Google File System)的设计论文,借鉴了论文中的很多设计思想。巧合的是,几乎是同样的时间,腾讯也在开发他们的文件存储系统,甚至取的名字都一样,都叫TFS,是不是有些神奇?淘宝TFS的全称是Taobao File System,腾讯的TFS全称是Tencent File System。
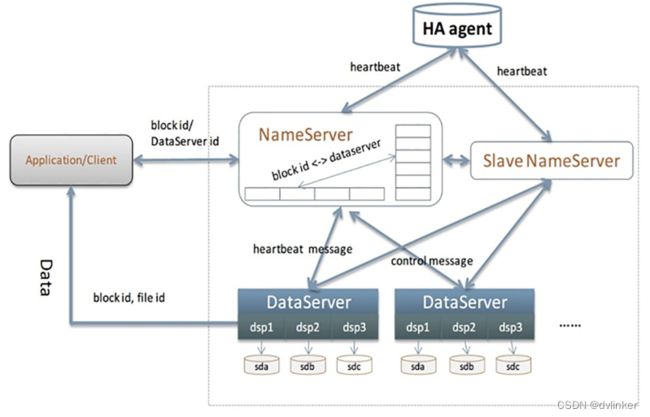
TFS针对淘宝系统中海量小文件的随机读写访问性能做了特殊优化。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。淘宝为了TFS得到更好的发展,在2010年将TFS开源。
一个TFS集群由两个NameServer节点和多个DataServer节点组成,TFS的服务程序都是作为一个用户级的程序运行在普通Linux机器上。TFS将众多的小文件合并成大文件,并称这个大文件为Block,Block存储在DataServer上,每个Block在TFS系统内均拥有唯一的Id号。NameServer负责维护block与DataServer之间的映射关系。NameServer采用HA结构,即双机互为热备份,来实现容灾功能,两台NameServer同时运行,其中一台为主节点,另外一台作为备用节点。当主NameServer节点出现故障后,迅速将备份NameServer切换为主节点并对外提供服务。
TFS的主要特性如下:
1)完全扁平化的数据组织结构,抛弃了传统文件系统的目录结构。
2)在块设备基础上建立自有的文件系统,减少EXT3等文件系统数据碎片带来的性能损耗。
3)单进程管理单块磁盘的方式,摒除RAID5机制。
4)带有HA机制的中央控制节点,在安全稳定和性能复杂度之间取得平衡。
5)尽量缩减元数据大小,将元数据全部加载入内存,提升访问速度。
6)跨机架和IDC的负载均衡和冗余安全策略。
7)完全平滑扩容。
正如大家所说,国内自主研发的文件系统真是可谓凤毛麟角,开源的文件系统就更是罕见,我现在所知道是就是FastDFS和TFS。从这个意义上,Taobao的开源精神是很值得称道的。TFS分布式文件系统,经过淘宝等业务系统的验证与多年的锤炼,做了大量的优化和改进,其性能和稳定性是值得期待的。
4.9、腾讯TFS
腾讯TFS(Tencent File System)是腾讯自研的海量文件系统,自2006年平台上线,经过多年不断技术演进,目前TFS承载了包括QZone相册、微信朋友圈图片、QQ邮件、微云、腾讯云COS等公司重要产品的数据存储任务。
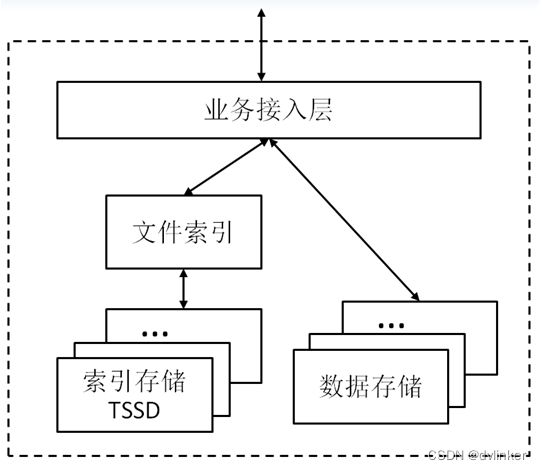
TFS文件系统提供以文件为粒度的上传,下载,删除等数据访问服务,系统分为接入,文件索引,索引存储,数据存储四个部分。接入层串联文件上传、下载、删除、查询索引等关键流程,提供简单的事务机制;文件索引层管理文件的元数据;索引存储提供key-value接口的分布式存储和访问(TSSD),用于存储文件的元数据;数据存储提供基于机械磁盘的数据存储和访问,用于存储文件内容。以QZone相册为例,索引存储中保存着相册列表、图片排重索引以及图片数据的原信息,而文件索引层则负责上面三种索引的逻辑组织,图片数据存储在数据存储层中。
在丰富的业务场景驱动下,TFS的数据存储也发展出来不同的差异。根据业务的场景、数据冷热层度,提供高性能数据存储—基于存储单元结对的Append-Only存储引擎、更低成本的数据存储—一体化的纠删码存储引擎。
5、最后
本文大概地探究了当前几个主流的分布式文件系统,做一个大概的整理与普及,希望能给大家提供一定的借鉴或参考。