Hadoop期末复习贴-MapReduce
若本文对你有帮助,请记得点赞、关注我喔!
从头开始看hadoop程序hhhh
1)WordCount
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class MyMapReducer {
/**
* 套Mapper的框架,就是一个约束,约束了输入输出的类型,
* 输入:
* 输出:
* context用于存放map处理的结果,也就是输出的工具叫context,也是框架内置的,不用操心。
* 在Mapper框架下,每读一行就会调用一次map函数
*/
public static class mapper extends Mapper<LongWritable, Text, Text, IntWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
/**
* 套Reducer的框架,就是一个约束,约束了输入输出的类型,
* 经过map之后自动的一个combine优化,将同一个Key的value放在同一个组内,形成一个新的好比()
* 输入:
* 输出:
* 在Reducer框架下,每读取一个key,调用一次reduce函数
*/
public static class reducer extends Reducer<Text, IntWritable, Text, Text> {
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();//转化为java类型int
}
context.write(key, new Text(count + ""));//加一个""转化为string类型
}
}
/**
* 处理业务逻辑的整体,叫做job
* 指定哪个作为mapper,哪个作为reducer
* 启动,指定一个job
* @param args
*/
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
/**
* job配置Mapper
* 设置map的输出Key和Value类型
*/
job.setMapperClass(mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
/**
* job配置Reducer
* 设置reducer输出Key和Value类型
*/
job.setReducerClass(reducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定原始数据位置
FileInputFormat.setInputPaths(job,new Path("hdfs://localhost:9000/test"));
//指定处理的结果数据位置
FileOutputFormat.setOutputPath(job,new Path("hdfs://localhost:9000/result"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
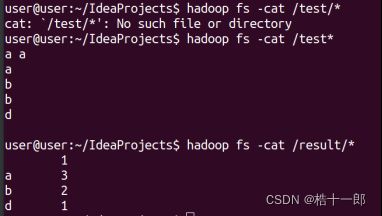
2)求商品最低价
/**
* 比对三家店,挑出物品的最低价
* 确定总体思路:遍历三家商店信息每一行,此时同种商品的不同价格价格已经形成 称为Map部分
* 遍历某一种商品的所有价格,求出最小值,重复直到求得各个商品最小值min_price,称为Reduce部分。
* 所以根据提出的Map部分,也就能确定Map框架的约束
* 再来确定Reduce部分的框架约束,
* 最后强调一遍在MapReduce中,Text-String,IntWritable-Int,LongWritable-Long,NullWritable-Null
*/
package MapReduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Map;
public class MinPrice {
/**
* 通过得到配置文件,再getInstance得到处理业务逻辑整体job
*/
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MinPrice.class);
job.setMapperClass(MyMapper.class);
// job.setMapOutputKeyClass(Text.class);
// job.setMapOutputValueClass(IntWritable.class);
/**
* 输出Text,IntWritable 一个猜测有没有可能根本不需要设置,Map部分的输出
* 猜想正确,job可以省略map部分的输出类型设置
*
* 再次猜想,job是否可以省略reduce部分的输出类型设置
* 猜想错误:必须有reduce部分的输出类型设置
*/
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
/**
* 添加路径
*/
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output"));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private IntWritable price = new IntWritable();
private Text good = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");//通过" ",将Id和Price切割
good.set(strs[0]); //调用set将String->Text
price.set(Integer.parseInt(strs[1]));//变相String->IntWritable
context.write(good, price);
}
}
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//传入,Value存在多个值,所以用一个迭代器的形式,Iterable<~>name,表可用一个同类型的变量去循环name
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int min = Integer.MAX_VALUE;
for (IntWritable val : values) {
if (min > val.get()) { //get让IntWritable到Int,其他同理。
min = val.get();
}
}
context.write(key, new IntWritable(min)); //产生新的键值对
}
}
}

3)内容去重复
/**
* 确定总体思路:Map框架
* Reduce框架
*/
package MapReduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import javax.validation.constraints.Null;
import java.io.IOException;
import java.util.Map;
public class QuChong {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(QuChong.class);
//Job配置Mapper
job.setMapperClass(MyMapper.class);
//job配置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//指定原始数据
FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output"));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString()); //默认用" "来切割字符,完全可以用split来代替
while (itr.hasMoreTokens()) {
// word.set(itr.nextToken());
context.write(new Text(itr.nextToken()), NullWritable.get());
}
}
}
public static class MyReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
public void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}

4)整数排序
/**
* 整体思路:因为Map产生键值对之后,会自动进行Shuffle。Shuffle会默认将键值对升序排序
* 确定Mapper约束:
* Reducer约束:
*/
package MapReduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.validation.constraints.Null;
import java.io.IOException;
import java.util.StringTokenizer;
public class IntSort {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(IntSort.class);
/**
* 配置Mapper
*/
job.setMapperClass(MyMapper.class);
/**
* 配置Reducer
*/
job.setCombinerClass(MyReducer.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path("hdfs://localhost:9000/input"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/output"));
System.out.println(job.waitForCompletion(true) ? 0 : 1);
}
public static class MyMapper extends Mapper<LongWritable, Text, IntWritable, NullWritable> {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer str = new StringTokenizer(value.toString());
while (str.hasMoreTokens()) {
context.write(new IntWritable(Integer.parseInt(str.nextToken())), NullWritable.get());
}
}
}
public static class MyReducer extends Reducer<IntWritable, NullWritable, IntWritable, NullWritable> {
public void reduce(IntWritable key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
/**
* 可能存在相同整数,所以根据Values中的数量,填充Context。有可能有点懵,下面回顾一下,只回顾一次。
* 在map中,除了Shuffle外,还有一个combine功能。将所有key相同的键值对,组成一个新的键值对.
* 那么在这里的map中,我给的value是NullWritable,加入有两个10,就会产生<10,<[空值],[空值]>>
* 最后job输出context,由于value是空值,就会呈现出整数排序的现象。
*/
for (NullWritable val : values) {
context.write(key, NullWritable.get());
}
}
}
}

5)对象排序
Good.class
package MapReduce.ObjectSort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Good implements WritableComparable<Good> {
private String id;
private int visitCount;
public Good() {
}
public Good(String id, int visitCount) {
this.id = id;
this.visitCount = visitCount;
}
//重载
public String toString() {
return id + "\t" + visitCount;
}
public String getId() {
return id;
}
public int getVisitCount() {return visitCount;}
/**
* Good(对象)类型作为Map/Reduce的键类型,要用到序列化和反序列化
* 序列化:内存对象->字节。反序列化:字节->内存对象
* 需要在传输中实现,内存对象和字节序列相互转化
* Hadoop自定义了一套序列化与反序列化。
*
* @param out
*/
//序列化
public void write(DataOutput out) throws IOException {
out.writeUTF(id);//尤其注意,字符串序列化,用的是writeUTF
out.writeInt(visitCount);//writeInt
}
//反序列化
public void readFields(DataInput in) throws IOException {
id = in.readUTF();
visitCount = in.readInt();
}
//this为指定的数,another为参数。return
public int compareTo(Good another) {
if (this.visitCount > another.visitCount) return -1;
if (this.visitCount < another.visitCount) return 1;
return this.id.compareTo(another.id);
}
}
ObjectSort.class
/**
* id0 100
* id1 40
* id2 90
* id3 36
* 整体思路:将看做Key,NullWritable为Value ,以此来进行Shuffle
* 确定了Mapper的约束:
* 确定了Reducer的约束:
* 如果要对几组对象进行排序,要让该类实现WritableComparable该接口
* 再在该类中重载三个函数
* void write(DataOutPut out) //序列化,将对象转化为字节
* void readFields(DataInput in) //反序列化,将字节转化为对象
* public int compareTo()
*/
package MapReduce.ObjectSort;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.validation.constraints.Null;
import java.io.IOException;
public class ObjectSort {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ObjectSort.class);
//配置Mapper
job.setMapperClass(MyMapper.class);
//配置Reducer
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Good.class);
job.setOutputValueClass(NullWritable.class);
//指定路径
FileInputFormat.addInputPath(job,new Path("hdfs://localhost:9000/input"));
FileOutputFormat.setOutputPath(job,new Path("hdfs://localhost:9000/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* 自动根据Good中的三个重载,进行Shuffle
*/
public static class MyMapper extends Mapper<LongWritable, Text, Good, NullWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] strs = value.toString().split(" ");
Good good = new Good(strs[0], Integer.parseInt(strs[1]));
context.write(good, NullWritable.get());
}
}
public static class MyReducer extends Reducer<Good, NullWritable, Good, NullWritable> {
protected void reduce(Good key,Iterable<NullWritable>values,Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
}