Docker容器网络
文章目录
- Docker容器虚拟化
-
- 虚拟化网络
- 单节点容器通信
- 不同节点容器通信
- Docker容器网络
-
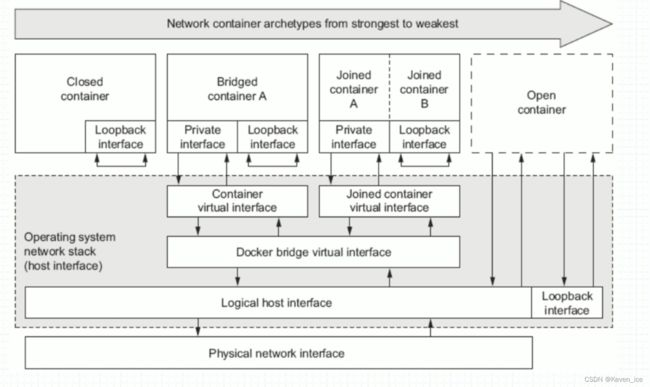
- Docker的四种网络模式
-
- bridge模式
- container模式
- host模式
- none模式
- Docker容器网络配置
-
- Linux内核实现名称空间的创建
-
- ip netns命令
- 创建Network Namespace
- 操作Network Namespace
- 转移设备
- veth pair
- 创建veth pair
- 实现Network Namespace间通信
- 四种网络模式配置
-
- bridge模式配置
- none模式配置
- container模式配置
- host模式配置
- 容器的常用操作
-
- 在容器启动时注入主机名
- 手动指定容器要使用的DNS
- 手动往/etc/hosts文件中注入主机名到IP地址的映射
- 开放容器端口
- 自定义docker0桥的网络属性信息
- docker远程连接
- docker创建自定义桥
Docker容器虚拟化
虚拟化网络
Network Namespace 是 Linux 内核提供的功能,是实现网络虚拟化的重要功能,它能创建多个隔离的网络空间,它们有独自网络栈信息。不管是虚拟机还是容器,运行的时候仿佛自己都在独立的网络中。而且不同Network Namespace的资源相互不可见,彼此之间无法通信。
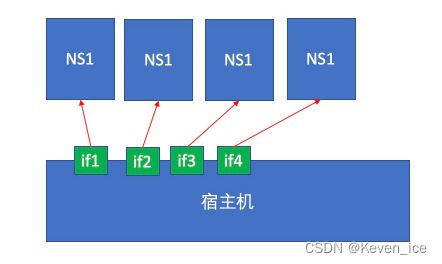
如上图所示,把第一块网卡分配给第一个名称空间,第二块分给第二个名称空间,第三块分给第三个名称空间,第四块分给第四个名称空间。此时其它名称空间都是看不见当前所在名称空间的,因为一个设备只能属于一个名称空间。
这种方式使得每一个名称空间都能配置IP地址,并且与外部网络直接通信,因为它们使用的是物理网卡。
但如果我们所拥有的名称空间数量超过物理网卡数量呢?此时我们可以使用虚拟网卡设备,用纯软件的方式来模拟一组设备来使用。Linux内核级支持2种级别设备的模拟,一种是二层设备,一种是三层设备。
Linux内核模拟的二层设备,每个网络接口设备是成对出现的,可以模拟为一根网线的两端,其中一端模拟主机的虚拟网卡,另一端模拟虚拟交换机,就相当于让一个主机连到一个交换机上去。Linux内核原生支持二层虚拟网桥设备,即用软件虚拟交换机的功能。如下图所示:

那么此时如果再有一个名称空间,它有创建了一对虚拟网卡,一端连接名称空间,一端连接虚拟交换机,此时就相当于两个名称空间连接到了同一个交换机网络中,此时如果两个名称空间的网卡地址配置在同一网段,那么很显然他们之间是可以互相通信的。如下图所示:

从网络通信的物理设备到网卡都是用纯软件的方式来实现,这种实现方式就叫做虚拟化网络。
单节点容器通信
如果在同一个物理机上的两个容器想通信,我们的办法就是在这台主机上建立一个虚拟交换机,而后让两个容器各自用纯软件的方式创建一对虚拟网卡,一半在容器上,一半在虚拟交换机上,从而实现通信。如下图所示:

这就是单节点上两个容器间的通信方式。单节点上两个容器之间的通信也有一些复杂情况,比如我们期望构建的容器要跨交换机通信呢?
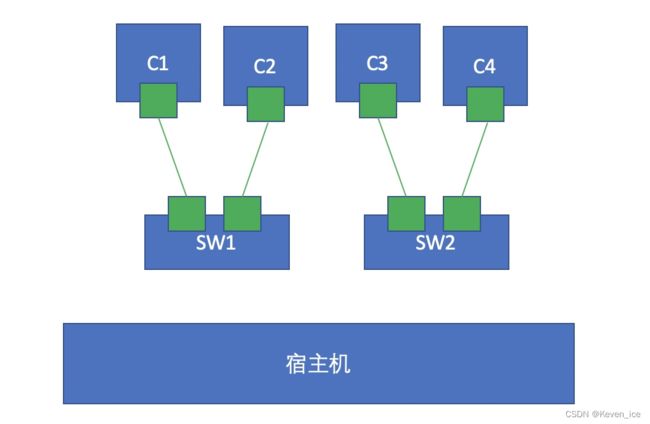
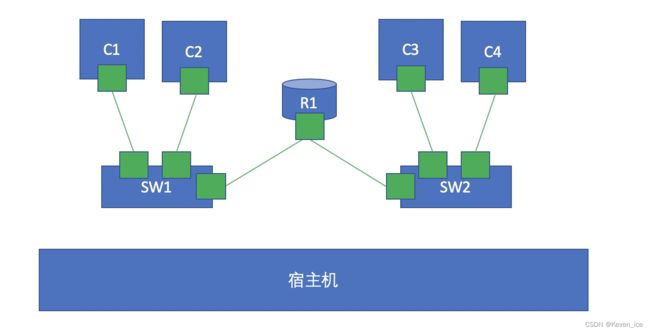
我们做两个虚拟交换机,两个交换机上各自连接不同的容器,如上图所示,此时如果要C1和C3通信又该如何实现呢?其实我们可以通过名称空间创建一对网卡,一端连SW1,另一端连SW2,这样一来两个交换机就连起来了,照理说这样一来C1和C3这两个处于不同交换机的容器就可以实现通信了,但是这样一来又存在另一个问题,那就是如果C1和C3在不同网络呢?如果不在同一网络我们就必须要通过路由转发才能使其通信,也就是我们得在两台交换机之间加一个路由器,其实Linux内核本身就是支持路由转发的,只需要我们将路由转发功能打开即可。此时我们可以再启动一个容器,这个容器里面就跑一个内核,并将其转发功能打开,这样一来就模拟了一台路由器,通过这台路由器来实现路由转发。
不同节点容器通信

如上图所示,此时如果C1要与C5进行通信又该如何实现呢?如果我们采用桥接的方式,很容易产生广播风暴,因此,在大规模的虚拟机或容器的场景中,使用桥接的方式无疑是自取灭亡,所以我们不应该使用桥接的方式来实现通信。
如果一来,我们既不能桥接,又需要与外部来实现通信,那就只能使用NAT技术了。通过DNAT将容器的端口暴露到宿主机上,通过访问宿主机的端口来实现访问容器内部的目的,而在请求端我们需要做SNAT将数据包通过宿主机的真实网卡转发出去。但这样做的话,因为要进行两次NAT转换,所以效率会比较低。
此时我们可以采用一种叫做Overlay Network(叠加网络)的技术来实现不同节点间容器的相互通信功能。

Overlay Network会将报文进行隧道转发,也就是在报文发出去之前要为其添加一个IP首部,也就是上图的1.1和1.2这部分,这里的1.1是源,1.2是目标,当宿主机2收到报文后解封装发现要找的目标容器是C2,于是把包转发给C2。
Docker容器网络
Docker在安装后自动提供3种网络,可以使用docker network ls命令查看
[root@localhost ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
cd97bb997b84 bridge bridge local
0a04824fc9b6 host host local
4dcb8fbdb599 none null local
Docker使用Linux桥接,在宿主机虚拟一个Docker容器网桥(docker0),Docker启动一个容器时会根据Docker网桥的网段分配给容器一个IP地址,称为Container-IP,同时Docker网桥是每个容器的默认网关。因为在同一宿主机内的容器都接入同一个网桥,这样容器之间就能够通过容器的Container-IP直接通信。
Docker的四种网络模式
| 网络模式 | 配置 | 说明 |
|---|---|---|
| host | –network host | 容器和宿主机共享Network namespace |
| container | –network container:NAME_OR_ID | 容器和另外一个容器共享Network namespace |
| none | –network none | 容器有独立的Network namespace,但并没有对其进行任何网络设置,如分配veth pair 和网桥连接,配置IP等 |
| bridge | –network bridge | 默认模式 |
bridge模式
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连在了一个二层网络中。
从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥中。可以通过brctl show命令查看。
bridge模式是docker的默认网络模式,不写–network参数,就是bridge模式。使用docker run -p时,docker实际是在iptables做了DNAT规则,实现端口转发功能。可以使用iptables -t nat -vnL查看。
bridge模式如下图所示:

假设上图的docker2中运行了一个nginx
- 同主机间两个容器间可以互相直接通信。docker1上能直接访问到docker2的nginx站点
- 在宿主机上能直接访问到docker2的nginx站点
- 在node1上配置端口映射就能在另一台主机上访问node1上的nginx站点
Docker网桥是宿主机虚拟出来的,并不是真实存在的网络设备,外部网络是无法寻址到的,这也意味着外部网络无法通过直接Container-IP访问到容器。如果容器希望外部访问能够访问到,可以通过映射容器端口到宿主主机(端口映射),即docker run创建容器时候通过 -p 或 -P 参数来启用,访问容器的时候就通过[宿主机IP]:[容器端口]访问容器。
container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。
container模式如下图所示:
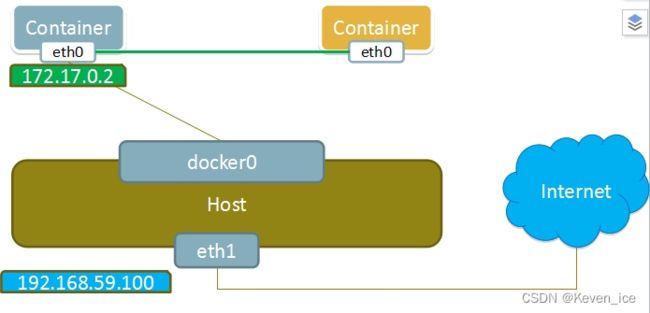
host模式
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个Network Namespace。容器将不会虚拟出自己的网卡,配置自己的IP等,而是使用宿主机的IP和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
使用host模式的容器可以直接使用宿主机的IP地址与外界通信,容器内部的服务端口也可以使用宿主机的端口,不需要进行NAT,host最大的优势就是网络性能比较好,但是docker host上已经使用的端口就不能再用了,网络的隔离性不好。
Host模式如下图所示:

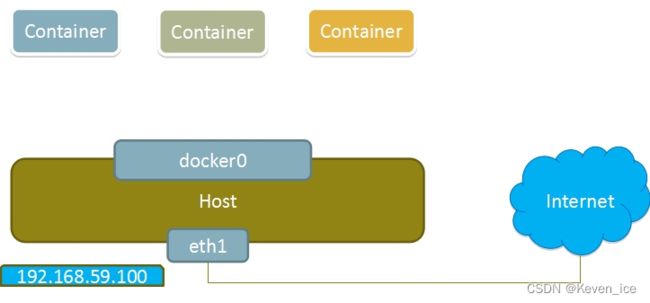
none模式
使用none模式,Docker容器拥有自己的Network Namespace,但是,并不为Docker容器进行任何网络配置。也就是说,这个Docker容器没有网卡、IP、路由等信息。需要我们自己为Docker容器添加网卡、配置IP等。
这种网络模式下容器只有lo回环网络,没有其他网卡。none模式可以在容器创建时通过–network none来指定。这种类型的网络没有办法联网,封闭的网络能很好的保证容器的安全性。
应用场景:
- 启动一个容器处理数据,比如转换数据格式
- 一些后台的计算和处理任务
none模式如下图所示:
docker network inspect bridge #查看bridge网络的详细配置
Docker容器网络配置
Linux内核实现名称空间的创建
ip netns命令
可以借助ip netns命令来完成对 Network Namespace 的各种操作。ip netns命令来自于iproute安装包,一般系统会默认安装,如果没有的话,请自行安装。
可以通过ip netns命令完成对Network Namespace 的相关操作,可以通过ip netns help查看命令帮助信息:
[root@100 ~]# ip netns help
Usage: ip netns list
ip netns add NAME
ip netns attach NAME PID
ip netns set NAME NETNSID
ip [-all] netns delete [NAME]
ip netns identify [PID]
ip netns pids NAME
ip [-all] netns exec [NAME] cmd ...
ip netns monitor
ip netns list-id [target-nsid POSITIVE-INT] [nsid POSITIVE-INT]
NETNSID := auto | POSITIVE-INT
默认情况下,Linux系统中是没有任何 Network Namespace的,所以ip netns list命令不会返回任何信息。
创建Network Namespace
通过命令创建一个名为ns0的命名空间:
[root@100 ~]# ip netns add ns0
[root@100 ~]# ip netns list
ns0
新创建的 Network Namespace 会出现在/var/run/netns/目录下。如果相同名字的 namespace 已经存在,命令会报Cannot create namespace file “/var/run/netns/ns0”: File exists的错误。
[root@100 ~]# ls /var/run/netns/
ns0
[root@100 ~]# ip netns add ns0
Cannot create namespace file "/var/run/netns/ns0": File exists
操作Network Namespace
ip命令提供了ip netns exec子命令可以在对应的 Network Namespace 中执行命令。
查看新创建 Network Namespace 的网卡信息
[root@100 ~]# ip netns exec ns0 ip addr
1: lo: mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
新创建的Network Namespace中会默认创建一个lo回环网卡,此时网卡处于关闭状态。此时,尝试去 ping 该lo回环网卡,会提示Network is unreachable
[root@100 ~]# ip netns exec ns0 ping 127.0.0.1
connect: Network is unreachable
通过下面的命令启用lo回环网卡:
[root@100 ~]# ip netns exec ns0 ip link set lo up
[root@100 ~]# ip netns exec ns0 ping 127.0.0.1
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.030 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.078 ms
转移设备
我们可以在不同的 Network Namespace 之间转移设备(如veth)。由于一个设备只能属于一个 Network Namespace ,所以转移后在这个 Network Namespace 内就看不到这个设备了。
其中,veth设备属于可转移设备,而很多其它设备(如lo、vxlan、ppp、bridge等)是不可以转移的。
veth pair
veth pair 全称是 Virtual Ethernet Pair,是一个成对的端口,所有从这对端口一 端进入的数据包都将从另一端出来,反之也是一样。
引入veth pair是为了在不同的 Network Namespace 直接进行通信,利用它可以直接将两个 Network Namespace 连接起来。

创建veth pair
[root@100 ~]# ip link add type veth
[root@100 ~]# ip a
5: veth0@veth1: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether d2:79:52:b0:dd:dc brd ff:ff:ff:ff:ff:ff
6: veth1@veth0: mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 12:1e:41:83:1f:4e brd ff:ff:ff:ff:ff:ff
实现Network Namespace间通信
下面我们利用veth pair实现两个不同的 Network Namespace 之间的通信。刚才我们已经创建了一个名为ns0的 Network Namespace,下面再创建一个信息Network Namespace,命名为ns1
[root@100 ~]# ip netns add ns1
[root@100 ~]# ip netns list
ns1
ns0
然后我们将veth0加入到ns0,将veth1加入到ns1
[root@100 ~]# ip link set veth0 netns ns0
[root@100 ~]# ip link set veth1 netns ns1
然后我们分别为这对veth pair配置上ip地址,并启用它们
[root@100 ~]# ip netns exec ns0 ip link set veth0 up
[root@100 ~]# ip netns exec ns1 ip link set veth1 up
[root@100 ~]# ip netns exec ns0 ip addr add 192.168.66.1/24 dev veth0
[root@100 ~]# ip netns exec ns1 ip addr add 192.168.66.2/24 dev veth1
查看这对veth pair的状态
[root@100 ~]# ip netns exec ns0 ip a
5: veth0@if6: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether d2:79:52:b0:dd:dc brd ff:ff:ff:ff:ff:ff link-netns ns1
inet 192.168.66.1/24 scope global veth0
valid_lft forever preferred_lft forever
inet6 fe80::d079:52ff:feb0:dddc/64 scope link
valid_lft forever preferred_lft forever
[root@100 ~]# ip netns exec ns1 ip a
6: veth1@if5: mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 12:1e:41:83:1f:4e brd ff:ff:ff:ff:ff:ff link-netns ns0
inet 192.168.66.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::101e:41ff:fe83:1f4e/64 scope link
valid_lft forever preferred_lft forever
尝试在ns1中访问ns0中的ip地址:
[root@100 ~]# ip netns exec ns1 ping 192.168.66.1
PING 192.168.66.1 (192.168.66.1) 56(84) bytes of data.
64 bytes from 192.168.66.1: icmp_seq=1 ttl=64 time=0.043 ms
64 bytes from 192.168.66.1: icmp_seq=2 ttl=64 time=0.042 ms
64 bytes from 192.168.66.1: icmp_seq=3 ttl=64 time=0.040 ms
可以看到,veth pair成功实现了两个不同Network Namespace之间的网络交互。
四种网络模式配置
bridge模式配置
在创建容器时添加–network bridge与不加–network选项效果是一致的
[root@100 ~]# docker run -it --name test1 centos /bin/bash
[root@06a64b48b935 /]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
7: eth0@if8: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
[root@100 ~]# docker run -it --name test2 --network bridge centos /bin/bash
[root@dac59dfcdfe1 /]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
none模式配置
[root@100 ~]# docker run -it --name test3 --network none centos /bin/bash
[root@fe70294af1cc /]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
container模式配置
启动第一个容器
[root@100 ~]# docker run -it --name test1 centos
[root@8e761a533ea4 /]# ip a
13: eth0@if14: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
启动第二个容器
[root@100 ~]# docker run -it --name test2 centos
[root@9756946acea6 /]# ip a
15: eth0@if16: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.3/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
第二个容器与第一个容器的IP地址不是一样的,也就是说并没有共享网络,此时如果我们将第二个容器的启动方式改变一下,就可以使两个容器IP一致,也即共享IP,但不共享文件系统。
[root@100 ~]# docker run -it --name test2 --network container:test1 centos
[root@8e761a533ea4 /]# ip a
13: eth0@if14: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
在第二个容器上部署一个站点
[root@8e761a533ea4 /]# echo "test222" > /var/www/html/index.html
[root@8e761a533ea4 /]# httpd
[root@8e761a533ea4 /]# ss -antl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 0.0.0.0:80 0.0.0.0:*
在第一个容器上用本地IP去访问
[root@8e761a533ea4 /]# curl 127.0.0.1:80
test222
由此可见,container模式下的容器间关系就相当于一台主机上的两个不同进程
host模式配置
[root@100 ~]# docker run -it --name test3 --network host centos
[root@100 /]# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:fb:20:70 brd ff:ff:ff:ff:ff:ff
inet 192.168.159.100/24 brd 192.168.159.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fefb:2070/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:71:14:97 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: docker0: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:86:86:9d:97 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:86ff:fe86:9d97/64 scope link
valid_lft forever preferred_lft forever
14: vethb29badc@if13: mtu 1500 qdisc noqueue master docker0 state UP group default
link/ether 7a:99:ab:3f:b6:53 brd ff:ff:ff:ff:ff:ff link-netnsid 2
inet6 fe80::7899:abff:fe3f:b653/64 scope link
valid_lft forever preferred_lft forever
此时如果我们在这个容器中启动一个http站点,我们就可以直接用宿主机的IP直接在浏览器中访问这个容器中的站点了。
容器的常用操作
在容器启动时注入主机名
[root@100 ~]# docker run -it --name test2 --hostname aaa centos
[root@aaa /]# hostname
aaa
手动指定容器要使用的DNS
[root@100 ~]# docker run -it --name test2 --hostname aaa --dns 114.114.114.114 --rm centos
[root@aaa /]# cat /etc/resolv.conf
nameserver 114.114.114.114
手动往/etc/hosts文件中注入主机名到IP地址的映射
[root@100 ~]# docker run -it --name test2 --hostname aaa --add-host www.keven.com:11.11.11.11 --rm centos
[root@aaa /]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
11.11.11.11 www.keven.com
172.17.0.3 aaa
开放容器端口
执行docker run的时候有个-p选项,可以将容器中的应用端口映射到宿主机中,从而实现让外部主机可以通过访问宿主机的某端口来访问容器内应用的目的。
-p选项能够使用多次,其所能够暴露的端口必须是容器确实在监听的端口。
-p选项的使用格式:
-p
将指定的容器端口映射至主机所有地址的一个随机端口
[root@100 ~]# docker run -d --name test1 -p 80 frices/centos:httpd
b4b0af21b0c1d27e40dbac3ccb76b47bdfa3a44b25f2d4824cda6bc58efeba29
[root@100 ~]# docker port test1
80/tcp -> 0.0.0.0:49153
80/tcp -> :::49153
[root@100 ~]# curl 127.0.0.1:49153
It works!
-p
将容器端口映射至指定的主机端口
[root@100 ~]# docker run -d --name test1 -p 8081:80 frices/centos:httpd
832fd59027f7cec95fcccd7ea393f4c8bdd9634d5773c68aab19f59b80344bb3
[root@100 ~]# docker port test1
80/tcp -> 0.0.0.0:8081
80/tcp -> :::8081
-p
将指定的容器端口
[root@100 ~]# docker run -d --name test1 -p 192.168.159.100::80 frices/centos:httpd
b2ff81b3d290e23a6cb5ab65c96f836833e6926cdc4b2362b8f628e6cfdc4639
[root@100 ~]# docker port test1
80/tcp -> 192.168.159.100:49153
-p
将指定的容器端口
[root@100 ~]# docker run -d --name test1 -p 192.168.159.100:8081:80 frices/centos:httpd
f53208aebbce372d01595f545c114eecc166ddfcc8976cea76a45bd476e12325
[root@100 ~]# docker port test1
80/tcp -> 192.168.159.100:8081
具体的映射结果可使用docker port命令查看。
自定义docker0桥的网络属性信息
自定义docker0桥的网络属性信息需要修改/etc/docker/daemon.json配置文件
{
"bip": "192.168.1.1/24", //docker0网桥IP
"fixed-cidr": "192.168.1.0/25", //混合IPv4
"fixed-cidr-v6": "2001:db8::/64", //混合IPv6
"mtu": 1500, //传输速率
"default-gateway": "192.168.1.254", //默认网关
"default-gateway-v6": "2001:db8:abcd::89", //默认IPv6网关
"dns": ["10.20.1.2","10.20.1.3"] //DNS
}
docker远程连接
dockerd守护进程的C/S,其默认仅监听Unix Socket格式的地址(/var/run/docker.sock)
[root@100 ~]# cd /lib/systemd/system
[root@100 system]# vim docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
[root@100 system]# systemctl daemon-reload
[root@100 system]# systemctl restart docker
[root@100 system]# ss -antl |grep 2375
LISTEN 0 128 *:2375 *:*
//测试
[root@100 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f28b25b79a04 frices/centos:httpd "./httpd.sh" 24 minutes ago Up 2 seconds 0.0.0.0:49153->80/tcp, :::49153->80/tcp test1
[root@139 ~]# docker -H 192.168.159.100:2375 ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f28b25b79a04 frices/centos:httpd "./httpd.sh" 35 minutes ago Up 10 minutes 0.0.0.0:49153->80/tcp, :::49153->80/tcp test1
docker创建自定义桥
创建一个额外的自定义桥,区别于docker0
[root@100 ~]# docker network create -d bridge --subnet "192.168.45.0/24" --gateway "192.168.45.2" N1
c470d9a1a77c46c64f7ec62f0c0e3af268f2fb67415d4e6bbf885a785e3ee62d
[root@139 ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
c470d9a1a77c N1 bridge local
04d9cdf7d3aa bridge bridge local
fc6ba83a6b64 host host local
d17511a4f89c none null local
使用新创建的自定义桥来创建容器:
[root@139 ~]# docker run -it --name test2 --network N1 centos
[root@9c323716da32 /]# ip a
5: eth0@if6: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:2d:01 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.45.1/24 brd 192.168.45.255 scope global eth0
valid_lft forever preferred_lft forever
再创建一个容器,使用默认的bridge桥:
[root@139 ~]# docker run -d -it --name test3 centos
72b93be0f13f21804c3c94d987e728714a6b094e2126a93720d285fd3488be05
[root@139 ~]# docker exec -it test3 /bin/bash
[root@72b93be0f13f /]# ip a
9: eth0@if10: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
此时两个容器间不能通信
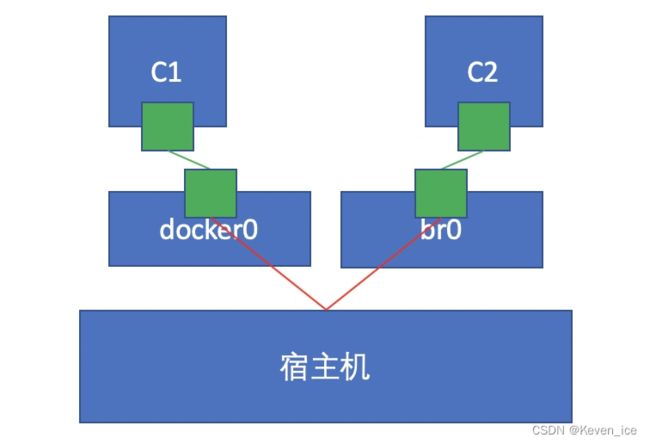
如果想实现通信,需要将其中一个容器加入到另一个容器的网络
[root@139 ~]# docker run -d -it --name test3 --net=N1 centos
7b9309f887fc2f86ae83b8bcfdc323c2009ce5fa5f82e1a8eb1bacc30b65349d
[root@139 ~]# docker exec -it test3 /bin/bash
[root@7b9309f887fc /]# ip a
11: eth0@if12: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:2d:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.45.3/24 brd 192.168.45.255 scope global eth0
valid_lft forever preferred_lft forever
[root@7b9309f887fc /]# ping 192.168.45.1
PING 192.168.45.1 (192.168.45.1) 56(84) bytes of data.
64 bytes from 192.168.45.1: icmp_seq=1 ttl=64 time=0.147 ms
64 bytes from 192.168.45.1: icmp_seq=2 ttl=64 time=0.128 ms