docker+rabbitmq 部署 普通模式 的集群
普通模式集群 介绍:
此模式 也是rabbitmq默认的集群模式,只要 把各个rabbitmq节点加入到集群中,不进行任何操作 便是此模式;
此模式 节点间 只互通元数据(可以理解为 保证队列结构相同,用户上传的数据不通,类似mysql表结构一致,数据不互通);
元数据如下:
a.队列元数据:队列名称和它的属性;
b.交换器元数据:交换器名称、类型和属性;
c.绑定元数据:一张简单的表格展示了如何将消息路由到队列;
d.vhost元数据:为vhost内的队列、交换器和绑定提供命名空间和安全属性;
rabbitmq原文连接,及对应描述如下
Virtual hosts, exchanges, users, and permissions are automatically replicated across all nodes in a cluster. Queues may be located on a single node, or replicate their content for higher availability.
节点间同步数据机制:
假设 某queue分配到了节点2上;生产者 连接的是 节点1,消费者连接的是 节点3 ;
生产者 生成消息到队列时 找到节点1上的queue的owner node指针指向节点2;则 节点1 起到了转发的功能,消息最终存储在节点2上;
消费者 从队列消费消息时 发现queue在节点2上,则 从节点2的queue取消息到节点3(不再次存储在节点3上),然后发送给消费者进行消费;
注意点:
客户端(生产者,消费者) 最好平均连接每一个节点,如果都连接同一个节点,容易产生性能瓶颈(木桶效应);
优点:
相对于 单节点部署 增加了 消息吞吐量能力;
缺点:
持久化队列中,任何一个节点宕机 都会导致整个集群停止工作(无法实现高可用);
非持久化队列中,任何一个节点宕机,其他节点继续提供服务,但是 宕机节点的数据 也丢失了...
Docker部署集群步骤
-
构造镜像,并运行
1.编写rabbitmq Dockerfile,并生成镜像;
在 公共镜像基础上增加 更改apt-get镜像源,并添加 vim,hapoxy等功能软件,并 增加额外的 杀掉rabbitmq后容器保活功能;
Dockerfile文件如下:
# docker build -f Dockerfile --no-cache -t rabbitmq_pro:1 .
# docker run -i -t rabbitmq_pro:1 /bin/bash
FROM rabbitmq:3.8.2-management
MAINTAINER Rgc
LABEL version='1'
WORKDIR /
COPY start.sh ${WORKDIR}
# 更改apt-get镜像源,并添加 vim等功能
RUN mv /etc/apt/sources.list /etc/apt/sources.list.bak && \
echo "deb http://mirrors.163.com/ubuntu/ bionic main restricted universe " >>/etc/apt/sources.list && \
echo "deb http://mirrors.163.com/ubuntu/ bionic-security main restricted universe " >>/etc/apt/sources.list && \
echo "deb http://mirrors.163.com/ubuntu/ bionic-updates main restricted universe " >>/etc/apt/sources.list && \
echo "deb http://mirrors.163.com/ubuntu/ bionic-proposed main restricted universe " >>/etc/apt/sources.list && \
echo "deb http://mirrors.163.com/ubuntu/ bionic-backports main restricted universe " >>/etc/apt/sources.list && \
echo "deb-src http://mirrors.163.com/ubuntu/ bionic main restricted universe " >>/etc/apt/sources.list && \
echo "deb-src http://mirrors.163.com/ubuntu/ bionic-security main restricted universe " >>/etc/apt/sources.list && \
echo "deb-src http://mirrors.163.com/ubuntu/ bionic-updates main restricted universe " >>/etc/apt/sources.list && \
echo "deb-src http://mirrors.163.com/ubuntu/ bionic-proposed main restricted universe " >>/etc/apt/sources.list && \
echo "deb-src http://mirrors.163.com/ubuntu/ bionic-backports main restricted universe " >>/etc/apt/sources.list && \
apt-get update && \
echo y | apt-get install vim && \
echo y | apt-get install iputils-ping && \
echo y | apt-get install haproxy
CMD ["/bin/bash", "start.sh"]同目录下,start.sh文件如下:
#!/bin/bash
# docker logs 原理是 把容器中 所有进程的标准输出 都能打印出来,所以 使用 nohup时 把输出转为标准输出即可
nohup rabbitmq-server &
# 睡眠20s保证rabbitmq服务能完全启动
time sleep 20;
# rabbitmq添加用户名和密码
rabbitmqctl add_user root root
# rabbitmq设置用户权限
rabbitmqctl set_user_tags root administrator
# rabbitmq下发权限
rabbitmqctl set_permissions -p / root ".*" ".*" ".*"
# docker为了容器 保持活性,必须要有一个 前台进程一直运行,否则容器便会关掉
while true; do sleep 1; done
同目录下,通过Dockerfile 生成镜像名称为: rabbitmq_pro:1 命令如下:
docker build -f Dockerfile --no-cache -t rabbitmq_pro:1 .2.使用docker-compose 统一管理4个rabbitmq容器 如下:
docker-compose.yml 文件如下(文件内的 环境变量 设置默认 rabbitmq用户名密码 无效,请忽略):
version: "3.7"
# 此 文件用于测试 rabbitmq高可用
services:
rabbitmq_1:
image: rabbitmq_pro:1
container_name: rabbitmq_1
environment:
RABBITMQ_DEFAULT_USER: root
RABBITMQ_DEFAULT_PASS: root
# volumes:
# 设置 数据 挂载
# - ./rabbitmq:/var/lib/rabbitmq
restart: always
ports:
- 5673:5672
- 15673:15672
networks:
- rb_local
rabbitmq_2:
image: rabbitmq_pro:1
container_name: rabbitmq_2
environment:
RABBITMQ_DEFAULT_USER: root
RABBITMQ_DEFAULT_PASS: root
restart: always
ports:
- 5674:5672
- 15674:15672
networks:
- rb_local
rabbitmq_3:
image: rabbitmq_pro:1
container_name: rabbitmq_3
environment:
RABBITMQ_DEFAULT_USER: root
RABBITMQ_DEFAULT_PASS: root
restart: always
ports:
- 5675:5672
- 15675:15672
networks:
- rb_local
rabbitmq_4:
image: rabbitmq_pro:1
container_name: rabbitmq_4
environment:
RABBITMQ_DEFAULT_USER: root
RABBITMQ_DEFAULT_PASS: root
restart: always
ports:
- 5676:5672
- 15676:15672
- 8100:8100
networks:
- rb_local
networks:
rb_local:
name: rb_local
3.运行docker-compose
由于 本地测试, 端口不能占用,所以 rabbitmq对接父主机 端口 范围为 5673到5676 等等;
同目录下,运行命令如下,使其 后台运行:
docker-compose up -d
-
容器内部开始部署集群
配置目标:
此次用3个容器内的 rabbitmq节点 做集群, 容器名 分别是 rabbitmq_1,rabbitmq_2,rabbitmq_3;
rabbitmq_2,rabbitmq_3做 内存节点(数据全部在内存中), rabbitmq_1做磁盘节点(数据在硬盘中);
1.进入每个容器,分别记录下 /etc/hosts 中的 内网IP 和 hostname(此处没有像其他教程一样修改 hostname)
进入容器命令(以rabbitmq_1容器为例):
docker exec -it rabbitmq_1 /bin/bash然后 记录 内部IP和hostname分别为:
内网IP hostname 容器ID web端口 节点类型
172.30.0.3 6e3c19a1cd23 rabbit_1 15673 disk(磁盘) 此节点为 主节点
172.30.0.2 cb959d1f3550 rabbit_2 15674 ram(内存)
172.30.0.5 16e7cb4bcfff rabbit_3 15675 ram(内存)2.设置每个 节点 erlang的cookie一致
rabbitmq是 基于 erlang语言 实现的 AMQP 协议 的产品; rabbitmq要实现分布式集群,则 需要 erlang实现分布式部署; 而要实现 erlang分布式部署,则 需要每个节点上的 .erlang.cookie文件 内容必须相同;
注意 .erlang.cookie文件 权限必须为 400(只读权限),否则 在运行时会失败;
此处 我们 将 rabbitmq_1中的 .erlang.cookie文件 替换给其他2个节点中的文件;
rabbitmq_1通过 cat /var/lib/rabbitmq/.erlang.cookie 获取字符串值
在rabbitmq_2/rabbitmq_3中 命令顺序如下:
rabbitmqctl stop # 先停止rabbitmq服务,否则在修改cookie值后无法通过 命令关闭cd /var/lib/rabbitmq/ && chmod 777 ./.erlang.cookie # 改变文件权限为可修改将 rabbitmq_1中的 .erlang.cookie 值 替换 掉 rabbitmq_2/rabbitmq_3的值;
chmod 400 /var/lib/rabbitmq/.erlang.cookie # 恢复 文件权限为只读,否则启动失败rabbitmq-server -detached # 尝试重新运行rabbitmq服务3. rabbitmq_2/rabbitmq_3 这2个节点加入到 rabbitmq_1中,从而形成集群
在rabbitmq_2/rabbitmq_3中 命令顺序如下:
rabbitmqctl stop_app # 先停止服务如下命令 中 --ram 参数表示 为内存节点,注意 对应rabbitmq配置要设置非持久化,否则还是会同步数据到磁盘,那么内存节点则效果甚微; 不添加 --ram 则表示 磁盘节点;
rabbitmqctl join_cluster --ram rabbit@xxx # 其中 xxx 表示rabbitmq_1的hostname,此命令为 加入到rabbitmq_1集群中rabbitmqctl start_app # 重新启动服务4.通过 web UI 查看集群效果
浏览器中输入 http://127.0.0.1:15675/ 或 http://127.0.0.1:15674 或 http://127.0.0.1:15673/ 得到如下界面:
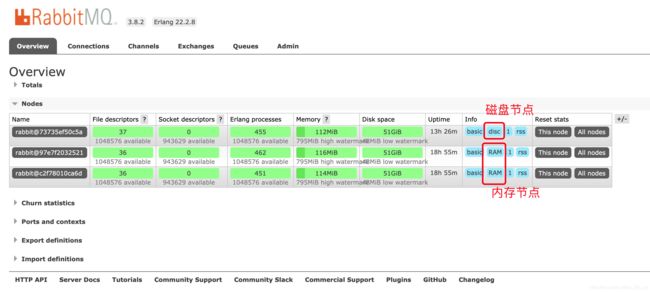
5.测试 此集群
使用 客户端项目 连接 任意 http://127.0.0.1:5675/ 或 http://127.0.0.1:5674/ 或 http://127.0.0.1:5673/ 这个集群中的任何节点的链接 进行测试;
本人测试后悲观的发现:
在持久化queue中,任何一个节点失效 均会 导致整个集群停止服务,导致 所有客户端连接 失败(无法实现高可用),除非把问题节点恢复!
在非持久化queue中,停止任何一个节点 其他节点正常提供服务,但是 缺点是丢失数据呀!
此模式拓展:
由于此模式的缺点比较明显, 因为队列数据只存在某一个节点上; 可以 改为 队列数据 存到所有节点上,并加上 节点间 负载均衡和反向代理的功能,可以实现 所有客户端只连接同一个 服务链接,并在 某节点宕机后 其他节点继续提供服务,从而实现高可用; 这种模式叫做 Classic Mirrored Queues ,也就是 下一篇要讲的 镜像模式)
celery+rabbitmq中 设置持久化 非持久化 队列或消息的方法
相关链接:
https://www.cnblogs.com/flat_peach/archive/2013/04/07/3004008.html#commentform