CNN从搭建到部署实战(pytorch+libtorch)
模型搭建
下面的代码搭建了CNN的开山之作LeNet的网络结构。
import torch
class LeNet(torch.nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, 6, 5), # in_channels, out_channels, kernel_size
torch.nn.Sigmoid(),
torch.nn.MaxPool2d(2, 2), # kernel_size, stride
torch.nn.Conv2d(6, 16, 5),
torch.nn.Sigmoid(),
torch.nn.MaxPool2d(2, 2)
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(16*4*4, 120),
torch.nn.Sigmoid(),
torch.nn.Linear(120, 84),
torch.nn.Sigmoid(),
torch.nn.Linear(84, 10)
)
def forward(self, img):
feature = self.conv(img)
flat = feature.view(img.shape[0], -1)
output = self.fc(flat)
return output
net = LeNet()
print(net)
print('parameters:', sum(param.numel() for param in net.parameters()))
运行代码,输出结果:
LeNet(
(conv): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(1): Sigmoid()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): Sigmoid()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Sequential(
(0): Linear(in_features=256, out_features=120, bias=True)
(1): Sigmoid()
(2): Linear(in_features=120, out_features=84, bias=True)
(3): Sigmoid()
(4): Linear(in_features=84, out_features=10, bias=True)
)
)
parameters: 44426
模型训练
编写训练代码如下:16-18行解析参数;20-21行加载网络;23-24行定义损失函数和优化器;26-36行定义数据集路径和数据变换,加载训练集和测试集(实际上应该是验证集);37-57行for循环中开始训练num_epochs轮次,计算训练集和测试集(验证集)上的精度,并保存权重。
import torch
import torchvision
import time
import argparse
from models.lenet import net
def parse_args():
parser = argparse.ArgumentParser('training')
parser.add_argument('--batch_size', default=128, type=int, help='batch size in training')
parser.add_argument('--num_epochs', default=5, type=int, help='number of epoch in training')
return parser.parse_args()
if __name__ == '__main__':
args = parse_args()
batch_size = args.batch_size
num_epochs = args.num_epochs
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = net.to(device)
loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
train_path = r'./Datasets/mnist_png/training'
test_path = r'./Datasets/mnist_png/testing'
transform_list = [torchvision.transforms.Grayscale(num_output_channels=1), torchvision.transforms.ToTensor()]
transform = torchvision.transforms.Compose(transform_list)
train_dataset = torchvision.datasets.ImageFolder(train_path, transform=transform)
test_dataset = torchvision.datasets.ImageFolder(test_path, transform=transform)
train_iter = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_iter = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
for epoch in range(num_epochs):
train_l, train_acc, test_acc, m, n, batch_count, start = 0.0, 0.0, 0.0, 0, 0, 0, time.time()
for X, y in train_iter:
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l += l.cpu().item()
train_acc += (y_hat.argmax(dim=1) == y).sum().cpu().item()
m += y.shape[0]
batch_count += 1
with torch.no_grad():
for X, y in test_iter:
net.eval() # 评估模式
test_acc += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
n += y.shape[0]
print('epoch %d, loss %.6f, train acc %.3f, test acc %.3f, time %.1fs'% (epoch, train_l / batch_count, train_acc / m, test_acc / n, time.time() - start))
torch.save(net, "checkpoint.pth")
该代码支持cpu和gpu训练,损失函数是CrossEntropyLoss,优化器是Adam,数据集用的是手写数字mnist数据集。训练的部分打印日志如下:
epoch 0, loss 1.486503, train acc 0.506, test acc 0.884, time 25.8s
epoch 1, loss 0.312726, train acc 0.914, test acc 0.938, time 33.3s
epoch 2, loss 0.185561, train acc 0.946, test acc 0.960, time 27.4s
epoch 3, loss 0.135757, train acc 0.960, test acc 0.968, time 24.9s
epoch 4, loss 0.108427, train acc 0.968, test acc 0.972, time 19.0s
模型测试
测试的代码非常简单,流程是加载网络和权重,然后读入数据进行变换再前向推理即可。
import cv2
import torch
from pathlib import Path
from models.lenet import net
import torchvision.transforms.functional
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = net.to(device)
net = torch.load('checkpoint.pth')
net.eval()
with torch.no_grad():
imgs_path = Path(r"./Datasets/mnist_png/testing/0/").glob("*")
for img_path in imgs_path:
img = cv2.imread(str(img_path), 0)
img_tensor = torchvision.transforms.functional.to_tensor(img)
img_tensor = torch.unsqueeze(img_tensor, 0)
print(net(img_tensor.to(device)).argmax(dim=1).item())
输出部分结果如下:
0
0
0
0
0
0
0
0
模型转换
下面的脚本提供了pytorch模型转换torchscript和onnx的功能。
import torch
from models.lenet import net
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
net = net.to(device)
net = torch.load('checkpoint.pth')
x = torch.rand(1, 1, 28, 28)
x = x.to(device)
traced_script_module = torch.jit.trace(net, x)
traced_script_module.save("checkpoint.pt")
torch.onnx.export(net,
x,
"checkpoint.onnx",
opset_version = 11
)
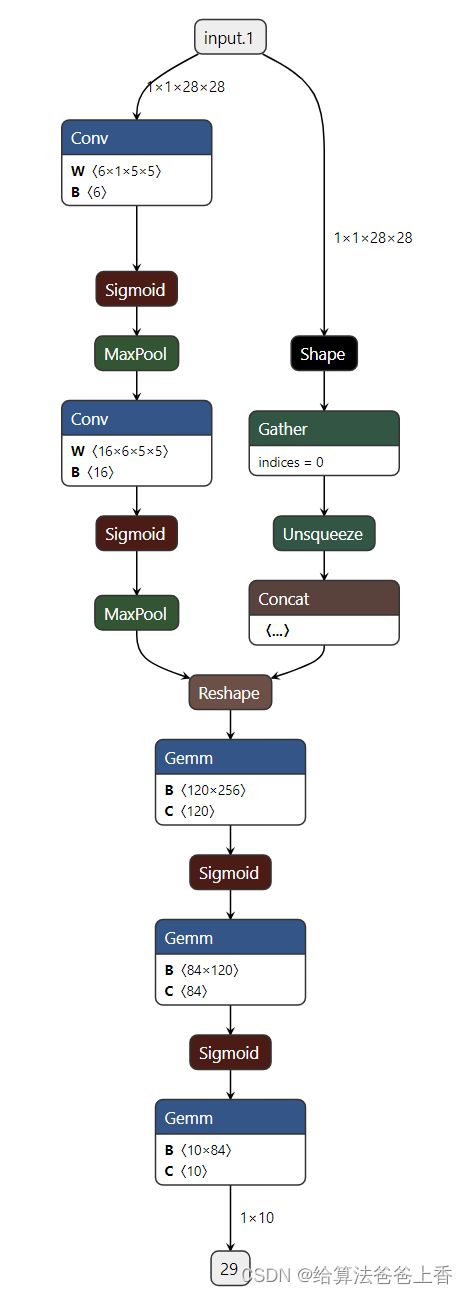
onnx模型netron可视化结果如下:
模型部署
10.png图片
![]()
libtorch部署
#include 输出结果:
8.0872 -6.3622 0.0291 -1.7327 -4.0367 0.8192 0.8159 -3.2559 -1.8254 -2.2787
[ CUDAFloatType{1,10} ]
0
[ CUDALongType{1} ]
opencv dnn部署
只用OpenCV也可以部署模型,其中的dnn模块可以解析onnx格式模型。
#include 输出结果:
0
本文的完整工程可见:https://github.com/taifyang/deep-learning-pytorch-demo