数据结构实验二(赫夫曼编码及应用)
参考的大佬的文章改了一些,但是程序还是有bug,经常会乱码,可能在将C++程序换成C程序时某些判断的阈值设置的有些问题,导致乱码的存在,不过我测试的这两篇中文和英文是调好的,目前不会乱码,应付一下实验报告就足够了
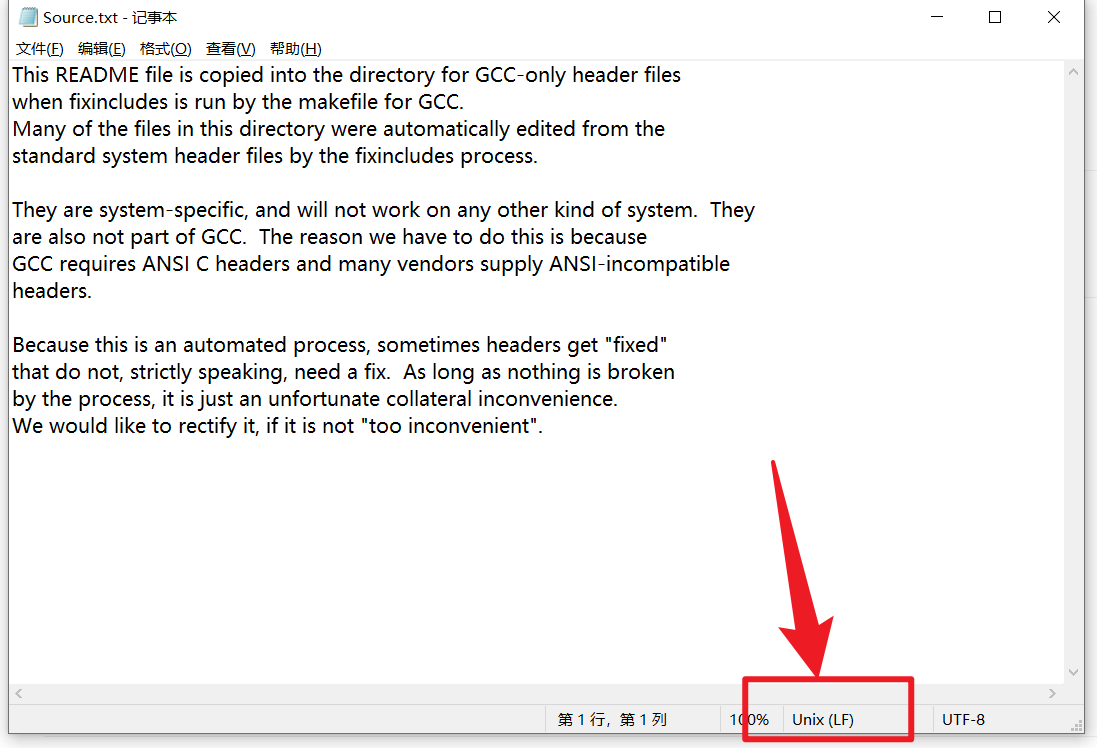
因为整个程序是以\n作为换行符,所以对程序中生成和使用的各类文件有硬性要求,必须是Unix (LF)格式的,不然必乱码
实验目的
掌握赫夫曼树和赫夫曼编码的基本思想和算法的程序实现
实验环境及基础知识
实验环境:
Windows10操作系统、C99标准、CLion 2023.1.3
基础知识:
-
赫夫曼树和赫夫曼编码基本思想和构建方法;
-
线性表数据的排序、插入、删除、修改、查找;
-
C语言文件的建立、读取、写入方法;
-
C语言位运算相关方法等;
-
C语言程序设计方法;
实验内容及要求
实验内容:
实现文件中数据的加解密与压缩:将硬盘上的一个文本文件进行加密,比较加密文件和原始文件的大小差别;对加密文件进行解密,比较原始文件和解码文件的内容是否一致。
实验要求:
-
提取原始文件中的数据(包括中文、英文或其他字符),根据数据出现的频率为权重,构建Huffman编码表;
-
根据Huffman编码表对原始文件进行加密,得到加密文件并保存到硬盘上;
-
将加密文件进行解密,得到解码文件并保存点硬盘上;
-
比对原始文件和解码文件的一致性,得出是否一致的结论。
参考类型定义://双亲孩子表示法
typedef struct {
unsigned int weight;
unsigned int parent, lchild, rchild;
} HTNode, \*HuffmanTree; //动态分配数组存储赫夫曼树
typedef char \* \* HuffmanCode; //动态分配数组存储赫夫曼编码表
需求分析及功能描述
需求分析:
1.用户界面需求:
用户需要一个用户界面来操作程序,包括选择输入文件、执行加密和解密操作以及查看结果。界面应该清晰明了,提供必要的输入和输出字段,以便用户能够轻松理解和操作程序。
2.输入文件处理需求:
用户需要能够选择一个文本文件作为输入,该文件包含要进行加密和解密的数据。程序需要能够读取并处理各种字符(包括中文、英文或其他字符)。
3.赫夫曼编码需求:
程序需要根据输入文件中字符的频率构建赫夫曼树。需要能够通过赫夫曼树生成赫夫曼编码表,用于加密和解密过程中的字符替换。
4.文件加密需求:
程序需要将输入文件中的字符根据赫夫曼编码表进行加密,将字符替换为对应的赫夫曼编码。加密后的数据应保存到硬盘上的一个文件中,供解密使用。
5.文件解密需求:
程序需要能够读取加密文件,并根据赫夫曼编码表将赫夫曼编码还原为原始字符。解密后的数据应保存到硬盘上的一个文件中,供比对原始文件和解码文件的内容是否一致。
6.文件内容比对需求:
程序需要能够比较原始文件和解码文件的内容,以确定解码是否正确。比对结果应该能够清楚地指示原始文件和解码文件的一致性。
7.文件保存需求:
加密文件和解码文件应该保存到硬盘上,以便用户进一步查看和分析。用户应能够选择保存文件的路径和文件名。
8.错误处理需求:
程序需要能够处理各种可能的错误情况,如无效的输入文件、文件读取错误、编码表生成错误等。需要向用户提供相应的错误提示,并在可能的情况下进行恢复或修复。
功能描述
1.用户界面功能:
提供选择输入文件的功能,用户可以通过界面选择一个文本文件作为输入。显示加密和解密操作的按钮,用户可以点击执行相应的操作。提供结果显示区域,用于显示加密文件、解码文件以及比对结果。
2.输入文件处理功能:
读取用户选择的输入文件,并将文件内容存储在内存中供后续处理。处理输入文件中的各种字符,包括中文、英文或其他字符。
3.赫夫曼编码功能:
统计输入文件中字符的频率,并根据频率构建赫夫曼树。根据赫夫曼树生成赫夫曼编码表,将每个字符映射到对应的赫夫曼编码。
4.文件加密功能:
遍历输入文件的每个字符,根据赫夫曼编码表将字符替换为对应的赫夫曼编码。将加密后的数据写入一个新的文件,用于保存加密结果。
5.文件解密功能:
读取用户选择的加密文件,根据赫夫曼编码表将赫夫曼编码还原为原始字符。将解密后的数据写入一个新的文件,用于保存解码结果。
6.文件内容比对功能:
比较原始文件和解码文件的内容,逐个字符进行比对。在比对过程中记录不一致的字符,并统计一致性的比例。在界面上显示比对结果,指示原始文件和解码文件的一致性。
7.文件保存功能:
提供保存加密文件和解码文件的功能,用户可以选择保存的路径和文件名。将加密文件和解码文件保存到指定的位置。
8.错误处理功能:
检测并处理各种可能的错误情况,如无效的输入文件、文件读取错误、编码表生成错误等。在界面上显示相应的错误提示信息。
系统总体设计
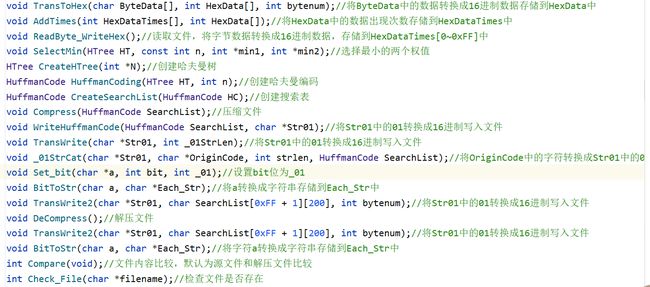
界面显示
在控制台显示系统的操作界面,提供用户友好的交互方式。用户可以看到文件处理系统的标题,并提示选择功能编号。用户需要输入对应的功能编号来选择要执行的操作。系统还提供了一个退出选项,用户可以选择退出系统。用户可以根据界面的提示进行输入,并通过按下回车键确认选择。
主要模块
文件读写模块:负责读取和写入文件数据。
数据处理模块:包括将字节数据转换为16进制数据、统计16进制数据出现次数、创建哈夫曼树、生成哈夫曼编码、创建搜索表等功能。
压缩模块:根据生成的哈夫曼编码和搜索表,将源文件数据进行压缩,并写入压缩文件。
解压模块:读取压缩文件中的数据,根据搜索表进行解压,并写入解压文件。
文件比较模块:比较源文件和解压文件的内容是否相同。
系统执行流程
用户选择功能编号,根据用户输入执行相应的功能。
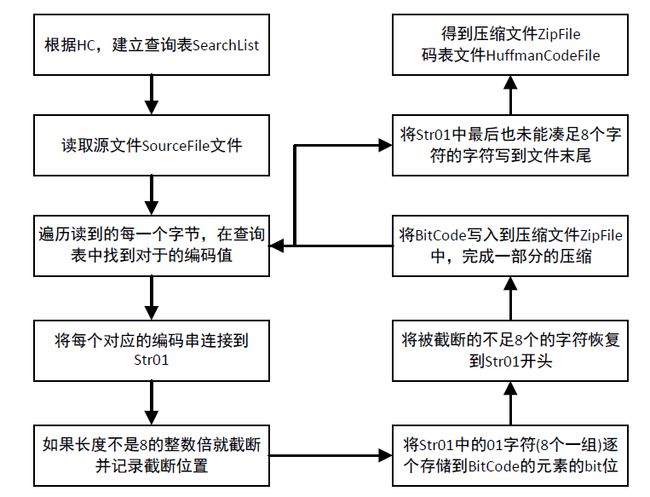
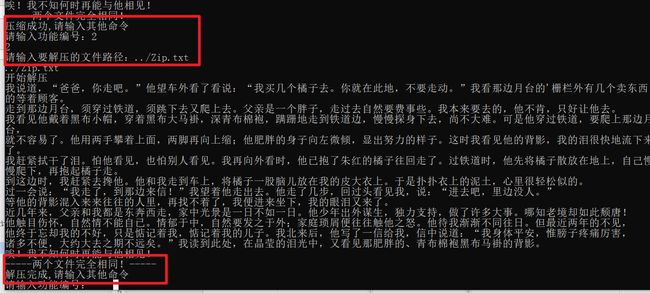
1.压缩文件功能
用户输入要压缩的文件路径。
打开源文件和计数文件,将字节数据转换为16进制数据并统计出现次数,将统计结果写入计数文件。
创建哈夫曼树和哈夫曼编码。
创建搜索表,并将哈夫曼编码写入哈夫曼编码文件。
读取源文件数据,根据搜索表将数据进行压缩,并将压缩后的数据写入压缩文件。
执行解压文件功能。
执行文件比较功能。
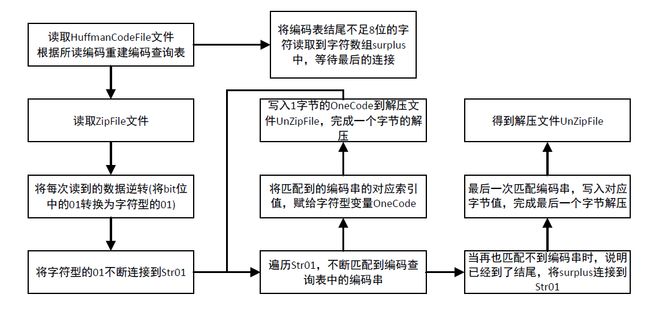
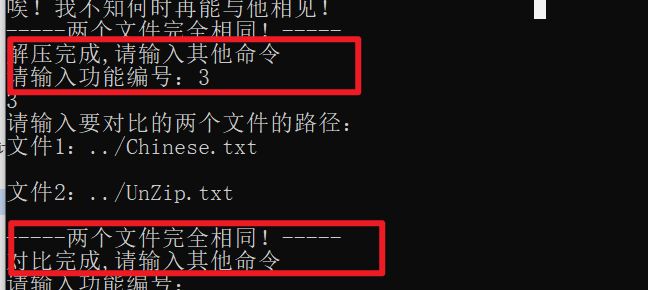
2.解压文件功能
用户输入要解压的文件路径。
读取压缩文件中的数据和哈夫曼编码文件,创建搜索表。
读取压缩文件数据,根据搜索表进行解压,并将解压后的数据写入解压文件。
执行文件比较功能。
3.文件比较功能
读取源文件和解压文件的内容,并逐个比较字符。如果存在不同的字符,输出不相同位置的行号和列号。如果两个文件内容完全相同,输出相同提示。
流程图分析

系统详细设计
主函数设计
1.显示用户操作界面,根据用户输入的功能编号,调用对应的功能函数。
2.将用户输入功能编号,选择调用对应功能的代码放到一个while死循环中,只要用户不输入退出系统的代码,就可以一直执行这个系统。

主要功能函数设计
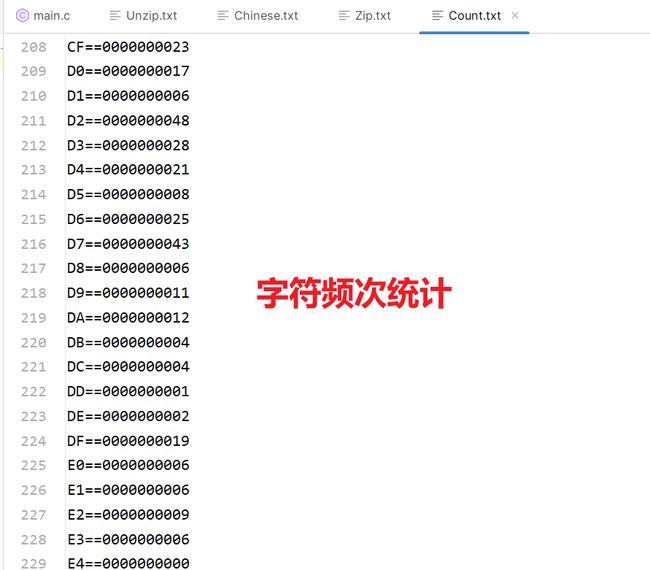
1.字符频次统计函数void ReadByte_WriteHex()
以二进制只读方式读取SourceFile源文件文件,并将文件中的每个字节转换为十六进制表示,并统计每个十六进制值的出现次数,然后将结果写入CountFile文件中。

2.创建赫夫曼树函数HTree CreateHTree(int *N)
基于给定的频次数据,创建一个哈夫曼树。具体功能的详细描述如下:
提取非零权值:根据全局变量 HexDataTimes中存储的频次数据,遍历所有可能的十六进制值(0x00 到0xFF),将非零权值的频次和对应的十六进制值保存在 weight 和 weight_Hex数组中。这样做是为了构建哈夫曼树时只考虑非零频次的节点。
确定叶子节点个数:将非零权值的个数保存在变量 n 中,并通过指针参数 N 返回该值。
计算哈夫曼树节点总数:根据叶子节点个数 n,计算哈夫曼树的总节点数m。每个叶子节点对应一个非零权值。
分配哈夫曼树内存空间:使用 malloc 函数分配 m+1 个 HTNode结构体的内存空间,保存哈夫曼树的节点。
初始化叶子节点:将前 n个节点作为叶子节点,并将对应的权值、父节点、左子节点和右子节点初始化为适当的值。
初始化非叶子节点:对于第 n+1 到第 m个节点,将它们的权值、父节点、左子节点和右子节点初始化为适当的值。
构建哈夫曼树:通过循环从 n+1 到 m的节点,选择两个权值最小的节点作为它们的父节点,并更新父节点的权值为两个子节点的权值之和。这个过程持续到只剩下一个根节点,即HT[m]。
返回哈夫曼树:将构建好的哈夫曼树 HT 返回。

3.创建赫夫曼编码函数HuffmanCode HuffmanCoding(HTree HT, int n)
根据给定的哈夫曼树,生成对应的哈夫曼编码。具体功能的详细描述如下:
分配内存空间:使用 malloc 函数分配 n+1个指针大小的内存空间,用于存储每个字符的哈夫曼编码。同时,使用 malloc 函数分配 n个字符大小的内存空间,作为临时存储每个字符编码的数组 Each_Code。
设置编码结束符:将 Each_Code 数组的最后一个元素设置为 ‘\0’,作为编码的结束符。
生成哈夫曼编码:通过遍历每个字符的节点,从叶子节点向上遍历到根节点,确定每个字符的哈夫曼编码。从当前节点开始,向上追溯父节点,根据左子节点和右子节点的关系,确定当前节点的编码位('0’或 ‘1’),并将编码保存在 Each_Code 数组中。
存储哈夫曼编码:为每个字符分配内存空间,根据 Each_Code数组中的编码内容,将编码复制到 HC[i] 数组中。HC[i] 存储了第 i个字符的哈夫曼编码。
释放内存空间:释放临时存储编码的 Each_Code 数组的内存空间。
返回哈夫曼编码:将生成好的哈夫曼编码 HC 返回。

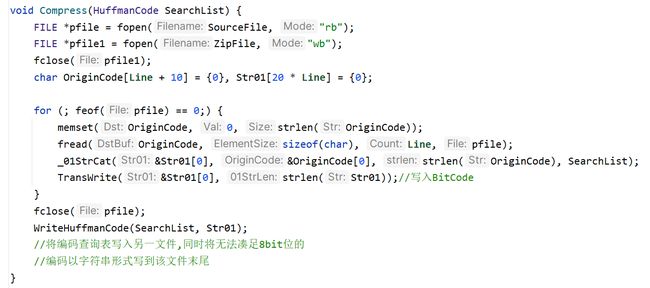
4.压缩文件函数void Compress(HuffmanCode SearchList)
根据给定的编码查询表 SearchList,对源文件进行编码压缩。具体功能的详细描述如下:
打开源文件和压缩文件:使用 fopen函数以二进制只读方式打开源文件,以二进制写入方式打开压缩文件。
逐行读取源文件数据:通过循环从源文件中读取 Line 个字符,存储到 OriginCode数组中。每次循环后,OriginCode 存储了一行数据。
进行编码拼接:调用 _01StrCat 函数,将 OriginCode 数组中的字符根据编码查询表SearchList 进行编码拼接,结果存储在 Str01 数组中。Str01是一个用于存储编码的字符串数组。
编码写入压缩文件:调用 TransWrite 函数,将 Str01中的编码写入压缩文件。该函数将编码转换为比特流,并将比特流写入压缩文件。
关闭源文件:处理完成后,关闭源文件。
写入编码查询表:调用 WriteHuffmanCode 函数,将编码查询表 SearchList写入压缩文件对应的编码文件HuffmanCodeFile中。同时,将无法凑足8位比特位的编码以字符串形式写入文件末尾。
5.解压文件函数void DeCompress()
这段代码的功能是进行解压缩操作,将压缩文件恢复为原始文件。具体功能的详细描述如下:
打开编码查询表文件和解压文件:使用 fopen函数以二进制只读方式打开编码查询表文件,以二进制写入方式打开解压文件。解压文件在打开时会被清空。
读取编码查询表:从编码查询表文件中逐行读取数据,将每行数据存储到 SearchList数组中。同时,读取编码查询表文件末尾的不足8位字符串,存储到 surplus 数组中。
处理编码查询表中的 (null):遍历 SearchList 数组,如果某个元素的值为"(null)",则将其截断,即将第一个字符设置为 ‘\0’。
打开压缩文件:使用 fopen 函数以二进制只读方式打开压缩文件。
解压缩:循环读取压缩文件中的数据,将每行数据转换为比特编码形式,并将其连接到Str01 字符串中。
将 Str01 写入解压文件:调用 TransWrite2 函数,将 Str01中的比特编码解析为原始字符,并将字符写入解压文件中。
关闭压缩文件:处理完成后,关闭压缩文件。
凑足8位编码并写入解压文件:将不足8位的编码字符串连接到 Str01中,凑足8位,并将该编码对应的字符写入解压文件中。
写入换行符:在解压文件末尾写入换行符。
6.文件比较函数int Compare(void)
比较两个文件的内容是否相同,默认比较源文件和解压文件的内容。具体功能的详细描述如下:
打开源文件和解压文件:使用 fopen 函数以只读方式打开源文件和解压文件。
逐字符比较两个文件的内容:通过循环从源文件和解压文件中逐个读取字符进行比较。循环条件是源文件和解压文件都没有到达文件末尾。
判断换行符:如果当前字符是换行符’\n’,则表示当前行结束,将对应文件的行号加一,列号重置为1。
比较字符是否相同:如果源文件和解压文件的当前字符不相同,则输出第一次不相同的位置信息(行号和列号),并跳出循环。
判断文件内容是否完全相同:如果一个文件已经到达文件末尾而另一个文件还有字符未读取,则说明其中一个文件的内容被包含在另一个文件中。根据情况输出相应的提示信息。
关闭文件:处理完成后,关闭源文件和解压文件。
返回比较结果:根据比较的结果,返回一个整数值。如果两个文件完全相同,返回1;如果两个文件不相同,返回0。

辅助函数设计
功能展示
控制台页面展示
各功能模块展示
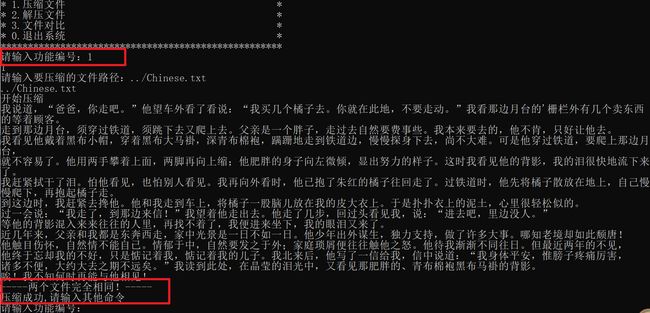
中间产生文件展示


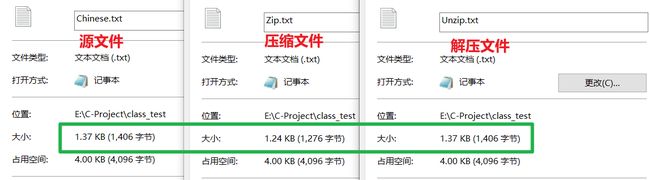
压缩效果展示
中文文件
英文文件
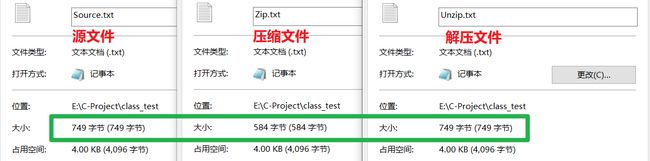
实验总结
在实验中,我们首先定义了赫夫曼树(HuffmanTree)和赫夫曼编码表(HuffmanCode)的数据结构。赫夫曼树用于构建字符频率的最优二叉树,而赫夫曼编码表用于存储每个字符对应的赫夫曼编码。这些数据结构为后续的加密、解密和比对操作提供了基础支持。
首先,我们实现了文件读写模块,用于读取和写入文件数据。通过使用标准库函数,我们能够打开源文件和目标文件,并进行数据的读取和写入操作。这使得我们能够在程序中处理文件数据。
然后,我们实现了数据处理模块,其中包括将字节数据转换为16进制数据、统计16进制数据出现次数、创建赫夫曼树、生成赫夫曼编码、创建搜索表等功能。这些功能通过遍历文件数据、统计频率和构建赫夫曼树来实现。通过赫夫曼编码表,我们能够将字符替换为对应的赫夫曼编码,实现了文件的加密和解密功能。
在压缩模块中,我们使用赫夫曼编码表对源文件进行压缩。遍历源文件中的每个字符,并通过搜索表将其转换为对应的赫夫曼编码。这样,我们可以将字符替换为更短的二进制编码,从而实现文件数据的压缩。压缩后的数据保存在目标文件中。
在解压模块中,我们读取压缩文件和赫夫曼编码表,根据搜索表进行解压。通过将赫夫曼编码转换为对应的字符,我们能够将压缩文件解压为原始文件数据,并将其保存在解压文件中。
最后,我们实现了文件内容比对模块。通过逐个字符比较原始文件和解压文件的内容,我们能够确定解码是否正确。在比对过程中,我们记录不一致的字符,并统计一致性的比例。通过输出比对结果,我们能够清楚地指示原始文件和解压文件的一致性。
在实验中,我们还考虑了错误处理的需求。通过使用条件判断和错误提示,我们能够检测并处理各种可能的错误情况,如无效的输入文件、文件读取错误和编码表生成错误等。这些错误处理机制使得程序具备了一定的鲁棒性,能够应对各种异常情况。
通过本次实验,我们深入了解了赫夫曼编码的原理和应用,并通过代码的实现加深了对赫夫曼编码的理解。我们掌握了文件加解密和压缩的基本操作,并学会了使用赫夫曼编码算法进行数据的压缩和解压缩。这些技能对于实际应用中的文件数据处理具有重要意义,提高了文件数据的安全性和处理效率。
总之,通过本次实验,我们成功实现了文件中数据的加解密与压缩功能,并对赫夫曼编码算法有了更深入的理解。实验过程中,我们不仅学习了赫夫曼编码的原理和实现方法,还掌握了文件读写、数据处理和错误处理等编程技巧。这些技能的掌握为我们今后在文件数据处理和安全传输领域的工作奠定了基础,为我们的学习和职业发展带来了积极的影响。
附录
源码
源码
#include 测试文件
This README file is copied into the directory for GCC-only header files
when fixincludes is run by the makefile for GCC.
Many of the files in this directory were automatically edited from the
standard system header files by the fixincludes process.
They are system-specific, and will not work on any other kind of system. They
are also not part of GCC. The reason we have to do this is because
GCC requires ANSI C headers and many vendors supply ANSI-incompatible
headers.
Because this is an automated process, sometimes headers get "fixed"
that do not, strictly speaking, need a fix. As long as nothing is broken
by the process, it is just an unfortunate collateral inconvenience.
We would like to rectify it, if it is not "too inconvenient".
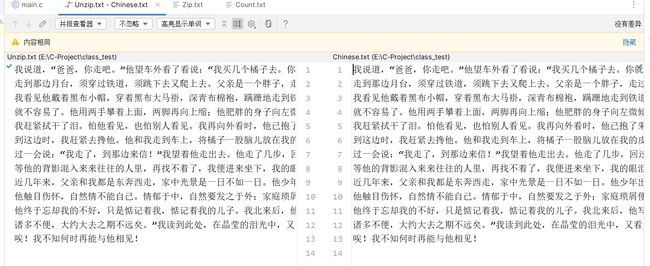
我说道,“爸爸,你走吧。”他望车外看了看说:“我买几个橘子去。你就在此地,不要走动。”我看那边月台的'栅栏外有几个卖东西的等着顾客。
走到那边月台,须穿过铁道,须跳下去又爬上去。父亲是一个胖子,走过去自然要费事些。我本来要去的,他不肯,只好让他去。
我看见他戴着黑布小帽,穿着黑布大马褂,深青布棉袍,蹒跚地走到铁道边,慢慢探身下去,尚不大难。可是他穿过铁道,要爬上那边月台,
就不容易了。他用两手攀着上面,两脚再向上缩;他肥胖的身子向左微倾,显出努力的样子。这时我看见他的背影,我的泪很快地流下来了。
我赶紧拭干了泪。怕他看见,也怕别人看见。我再向外看时,他已抱了朱红的橘子往回走了。过铁道时,他先将橘子散放在地上,自己慢慢爬下,再抱起橘子走。
到这边时,我赶紧去搀他。他和我走到车上,将橘子一股脑儿放在我的皮大衣上。于是扑扑衣上的泥土,心里很轻松似的。
过一会说:“我走了,到那边来信!”我望着他走出去。他走了几步,回过头看见我,说:“进去吧,里边没人。”
等他的背影混入来来往往的人里,再找不着了,我便进来坐下,我的眼泪又来了。
近几年来,父亲和我都是东奔西走,家中光景是一日不如一日。他少年出外谋生,独力支持,做了许多大事。哪知老境却如此颓唐!
他触目伤怀,自然情不能自已。情郁于中,自然要发之于外;家庭琐屑便往往触他之怒。他待我渐渐不同往日。但最近两年的不见,
他终于忘却我的不好,只是惦记着我,惦记着我的儿子。我北来后,他写了一信给我,信中说道:“我身体平安,惟膀子疼痛厉害,
诸多不便,大约大去之期不远矣。”我读到此处,在晶莹的泪光中,又看见那肥胖的、青布棉袍黑布马褂的背影。
唉!我不知何时再能与他相见!