深度学习与神经网络
人工智能,机器学习,深度学习,神经网络,emmmm,傻傻分不清楚,这都啥呀,你知道吗?我不知道。你知道吗?我不知道。
来来来,接下来,整硬菜:
先解释一下这几个概念:
人工智能:
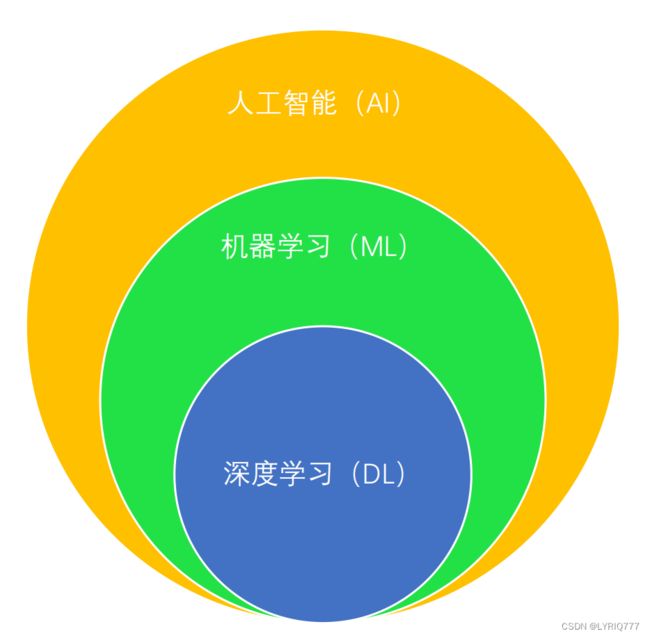
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。人工智能是新一轮科技革命和产业变革的重要驱动力量。
机器学习:一种实现人工智能的方法。
深度学习:一种实现机器学习的技术。
神经网络:一种机器学习的算法。
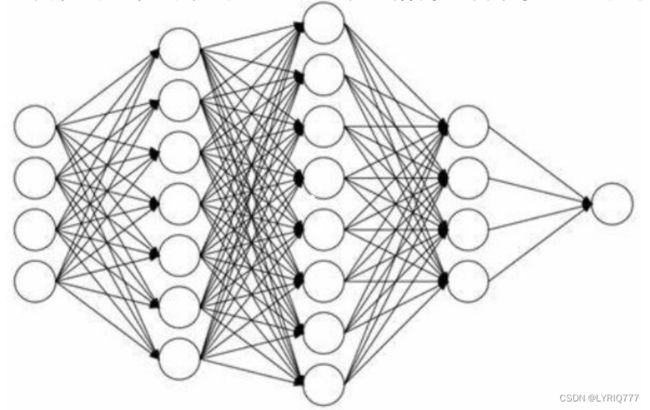
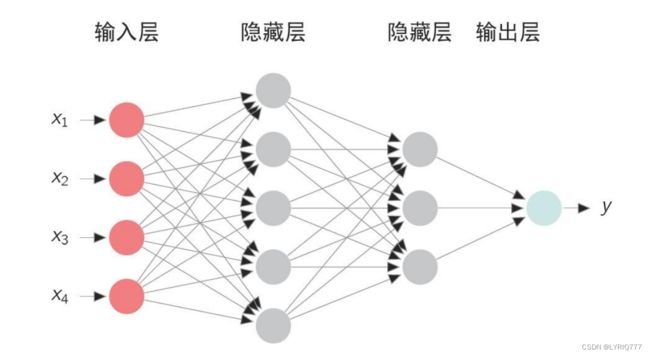
什么是神经网络?

点成线,线成面(网)
生物神经网络的基本工作原理:
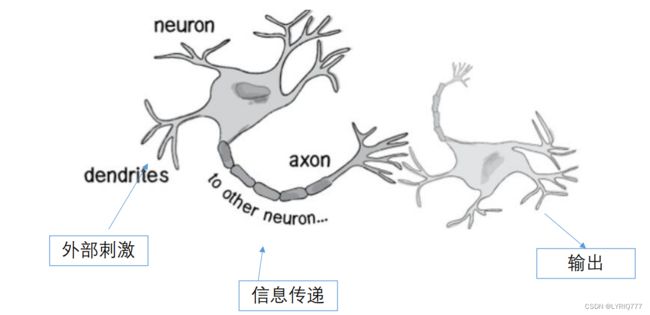
与下图食用更加:
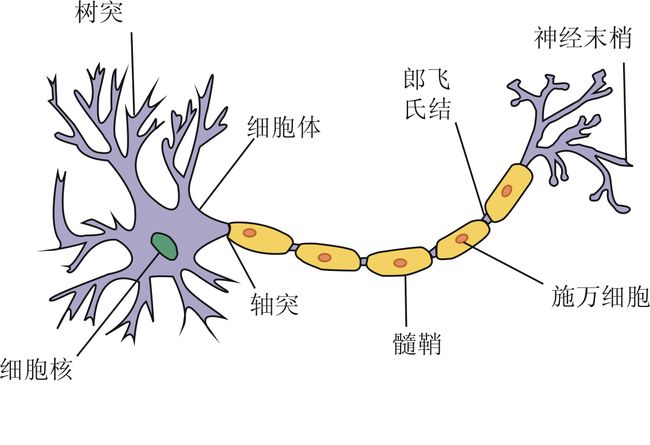
(人工)神经网络:
模拟生物神经网络的一种人工实现。
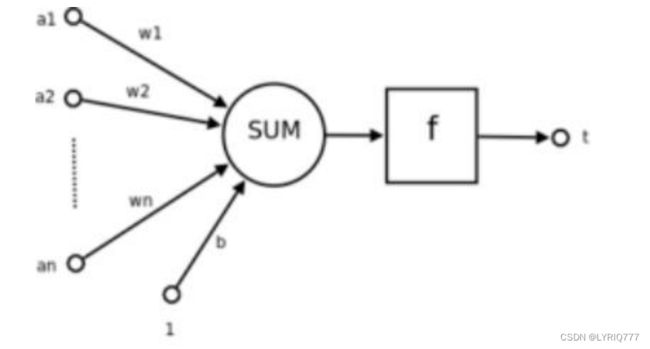
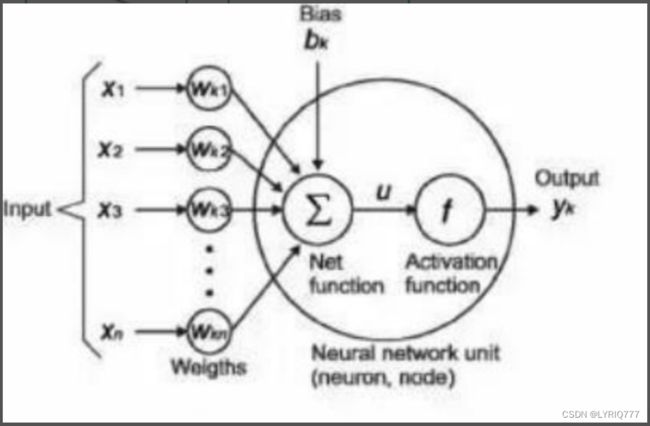
a1~an:输入值
w1~wn:权重
SUM:加权求和
f:激活函数
t:输出
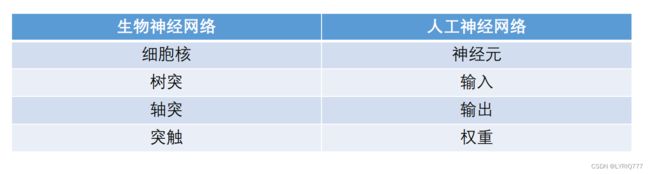
类比之后是不是就很好理解了
我们把上述的步骤简化一下:
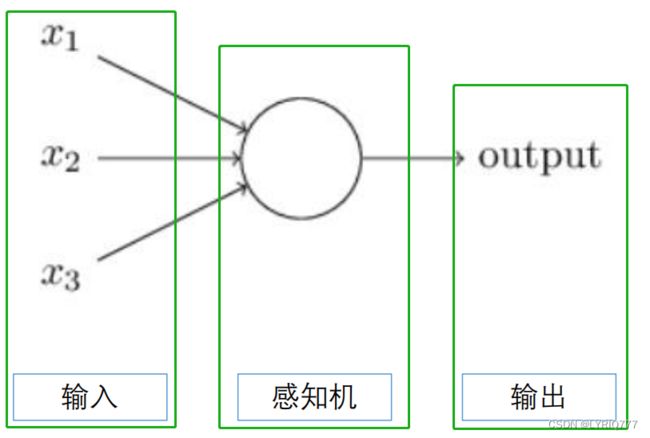
看不懂?那就看这个:
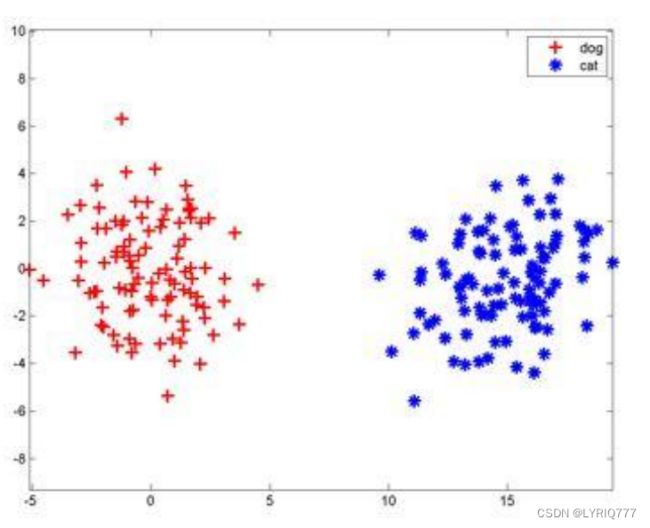
把猫咪和狗子分开,从图中很容易就发现,直接中间切一刀,两边就分开了。函数也很简单y=kx+b,一条直线呗。
问题来了!
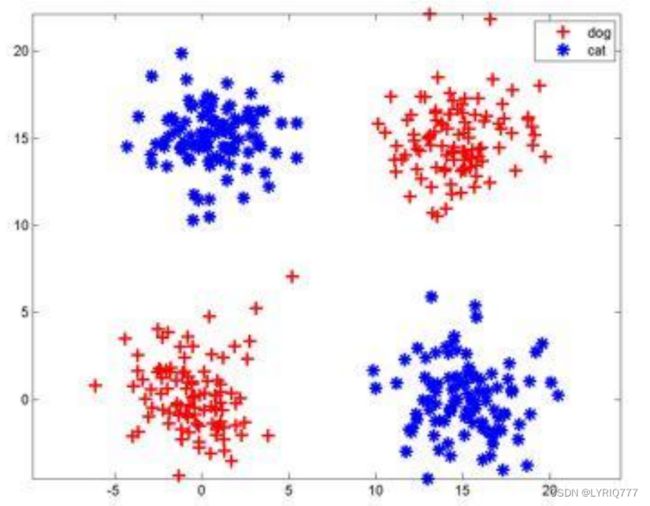
如果我掏出这样的模型,那么阁下应该如何应对。
那就多层神经网络(多切几刀,手动狗头)
诶!!!它来了
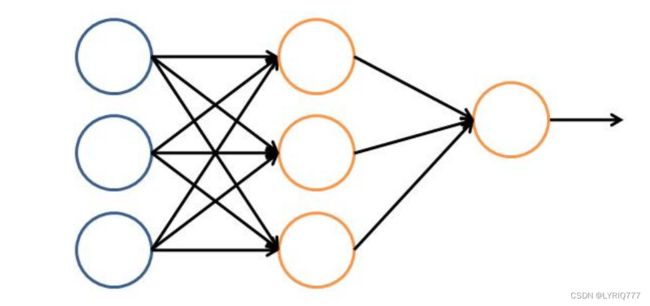
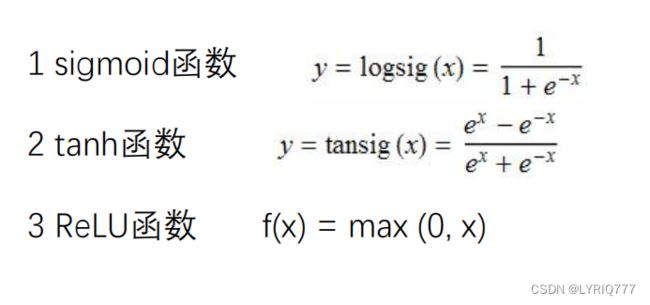
所以怎么理解呢,改变他们的线性关系,这个与另一个特征结合起来就很好理解,归一化。
先看下几个激活函数的曲线图
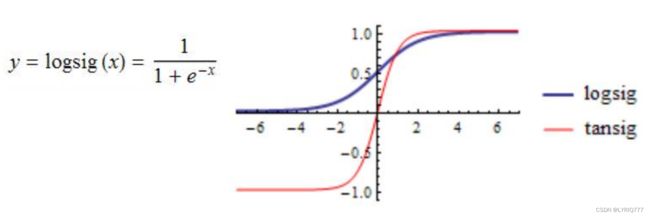
sigmoid:
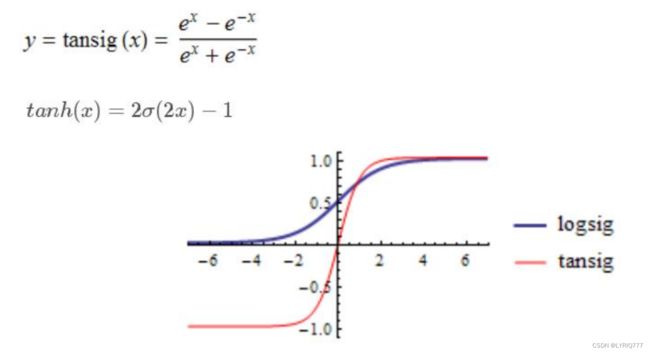
tanh:
RELU:
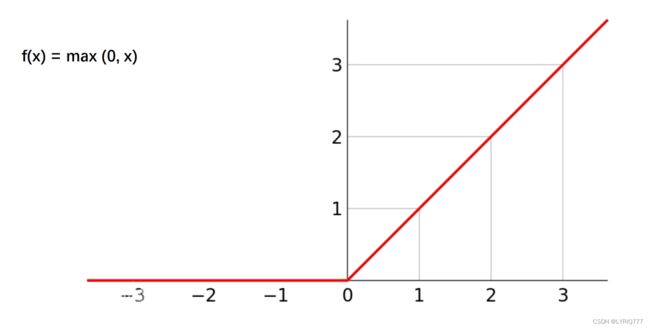
可以看出,除了RELU之外,其他两个都被某种神秘力量掰弯了,嗯?掰弯了,哲学♂大扳手!!!
但其实RELU也被折了一下,他们都失去了一些宝贵的东西(我指的是线性),除了RELU,其他两种在归一化的特性显示也特别明显。
后面还会介绍其他激活函数,后期单独出一期各个激活函数的优缺点及比较。一键三连走起好吧。
张量tensor
什么是张量?张亮麻辣烫,哇,脆皮豆腐贼好吃(口水)
[
[1,2],
[3,4]
],
[
[5,6],
[7,8]
],
[
[9,10],
[11,12]
]
]
[
[1,2],
[3,4],
[13,14]
],
[
[5,6],
[7,8],
[15,16]
],
[
[9,10],
[11,12],
[17,18]
]
]
如何设计神经网络
对隐含层的感性认识
举个栗子:你喜不喜欢我?你只需要回答喜欢还是不喜欢,而不是扯其他乱七八糟的东西。
那么所有的节点都应该是这样的,我希望的是得到一个肯定的回答,而不是模棱两可的回答。
我希望所有的节点都是钢铁直男。
什么是深度学习(Deep Learning)?
The biggest title in this blog!!!
给你点color see see