Day_63-65 集成学习之 AdaBoosting
目录
Day_63-65
一. 基本概念介绍
1. 集成学习
2. 弱分类器与强分类器
二. AdaBoosting算法
1. AdaBoosting算法框架介绍
2. AdaBoosting算法过程
三. 代码的实现过程
1. WeightedInstances类
2. 构造弱分类器的StumpClassifier类和抽象类SimpleClassifier
3. 主类Booster的分析
四. 代码展示
五. 总结
Day_63-65
一. 基本概念介绍
1. 集成学习
集成学习大致可分为两大类:Bagging和Boosting,Bagging在这里不过多介绍,有兴趣的读者请参考另外的资料,这里主要讲Boosting算法。Boosting使用弱分类器,其个体学习器之间存在强依赖关系,是一种序列化方法。Boosting是一族算法,其主要目标为将弱学习器“提升”为强学习器,大部分Boosting算法都是根据前一个学习器的训练效果对样本分布进行调整,再根据新的样本分布训练下一个学习器,如此迭代M次,最后将一系列弱学习器组合成一个强学习器。而这些Boosting算法的不同点则主要体现在每轮样本分布的调整方式上。本文章先讨论Boosting的两大经典算法之一——AdaBoost。

2. 弱分类器与强分类器
这里有几个定义大家随便看看,
①一个分类器的分类准确率在60%-80%,即:比随机预测略好,但准确率却不太高,我们可以称之为“弱分类器”。反之,如果分类精度90%以上,则是强分类器。
②西瓜书上说:弱学习器常指泛化性能略优于随即猜测的学习器(例如在二分类问题上精度略高于50%的分类器)
简而言之弱分类器是比较简单的分类器,举个简单的例子:若有一本书的页数大于500则判定为较难书籍,反之则判定为简单书籍。这是个非常简单的决策树,仅仅通过一个属性(页数)就来判断书籍的难易程度(显然不算太靠谱,但是准确率又大于50%),这便称为一个弱分类器。

二. AdaBoosting算法
1. AdaBoosting算法框架介绍
AdaBoosting算法简单来说就是将多个弱分类器进行拼接得到一个强分类器。首先我们构建出多个弱分类器,接着每个弱分类器乘以对应的权重,然后把它们组合起来得到一个强分类器。最后输入一个测试数据,用这个强分类器进行判别。
举个例子:判断一个房子要不要买?
第一个弱分类器和它对应的权值(w1)

第二个弱分类器它对应的权值(w2)

第三个弱分类器它对应的权值(w3)

最后我们输入一个数据(250万,三室,好地段),得到的结果(1表示买,-1表示不买)是w1×-1+w2×1+w3×1;这个数据若大于0,则买,否则不买。上述只是一个非常简单的例子,这里弱分类器还可以有很多个,并且属性可以重复,因为后期在计算权重(w)的时候,对于一个重复的属性不会有影响。
现在我们的目标就是构建弱分类器,和调整对应的权重。
2. AdaBoosting算法过程
这部分会涉及到许多数学公式,请在小朋友的陪同下观看qaq。
首先我们接下来的所有例子都来自下面的数据
| 属性1 | 属性2 | 属性3 | 属性4 | 标签 | |
|---|---|---|---|---|---|
| 样本1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 样本2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 样本3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 样本4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 样本5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
| 样本6 | 5.4 | 3.9 | 1.7 | 0.4 | Iris-setosa |
| 样本7 | 7.0 | 3.2 | 4.7 | 1.4 | Iris-versicolor |
| 样本8 | 6.4 | 3.2 | 4.5 | 1.5 | Iris-versicolor |
| 样本9 | 6.9 | 3.1 | 4.9 | 1.5 | Iris-versicolor |
| 样本10 | 5.5 | 2.3 | 4.0 | 1.3 | Iris-versicolor |
| 样本11 | 6.5 | 2.8 | 4.6 | 1.5 | Iris-versicolor |
| 样本12 | 5.7 | 2.8 | 4.5 | 1.3 | Iris-versicolor |
| 样本13 | 6.3 | 3.3 | 6.0 | 2.5 | Iris-virginica |
| 样本14 | 5.8 | 2.7 | 5.1 | 1.9 | Iris-virginica |
| 样本15 | 7.1 | 3.0 | 5.9 | 2.1 | Iris-virginica |
| 样本16 | 6.3 | 2.9 | 5.6 | 1.8 | Iris-virginica |
| 样本17 | 6.5 | 3.0 | 5.8 | 2.2 | Iris-virginica |
| 样本18 | 7.6 | 3.0 | 6.6 | 2.1 | Iris-virginica |
2.1 初始化权重和弱分类器
首先初始化数据的权重(总共18个数据);k表示迭代到第几轮了,i表示第几个数据样本,这里的m表示数据的个数。
![]()
接着我们构建一个弱分类器![]() (这个过程可以暂时跳过,后面我再详谈)。
(这个过程可以暂时跳过,后面我再详谈)。
2.2 计算误差率和弱分类器的权重系数
由于弱分类器的特性,我们在考虑一个弱分类器![]() 对应的输入数据的的时候,只考虑单一属性。例如上面的数据我们随机选择一个属性作为这个弱分类器
对应的输入数据的的时候,只考虑单一属性。例如上面的数据我们随机选择一个属性作为这个弱分类器![]() 的输入(其他属性不考虑,集成学习就是多个弱分类器(
的输入(其他属性不考虑,集成学习就是多个弱分类器(![]() ,
,![]() ...
...![]() )构建在一起的,所以多造几个弱分类器器就行了),若下图所示我们在构造分类器的时候只需要考虑一个属性1。
)构建在一起的,所以多造几个弱分类器器就行了),若下图所示我们在构造分类器的时候只需要考虑一个属性1。

分类问题的误差率很好理解和计算。由于多元分类是二元分类的推广,这里假设我们是二元分类问题(标签种类大于2的处理方法后面也会给出解释),这里我们先假定是二元分类问题输出为{-1,1}。那么对于第k个弱分类器![]() 在训练集上的加权误差率为,
在训练集上的加权误差率为,
![]()
意思就是上述的18个样本数据,通过这个分类器![]() ,得到的分类结果和原本数据的分类结果不一致的话,那么就将这个数据样本的权重系数相加,这就是第k个弱分类器的误差参数
,得到的分类结果和原本数据的分类结果不一致的话,那么就将这个数据样本的权重系数相加,这就是第k个弱分类器的误差参数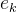 。
。
接着我们计算每个弱学习器的权重参数,对于二元分类问题,第k个弱分类器的![]() 权重系数有如下公式:至于每个弱分类器的权重系数为什么采用这种计算方式,有兴趣的读者请参考文章1,文章2。
权重系数有如下公式:至于每个弱分类器的权重系数为什么采用这种计算方式,有兴趣的读者请参考文章1,文章2。
![]()
2.3 更新数据
现在样本权重![]() 为:
为:
![]()
则更新一轮的样本权重
![]()
其中![]() 是规范化因子,
是规范化因子,
![]()
2.4 最终强分类器和迭代过程
将上述过程进行K次得到K的弱分类器,并且将他们组合起来,最终我们得到了强分类器
![]()
再最后我们回顾一下这个算法的过程:首先我们对18个样本进行初始化权重![]() ,接着将这18个样本输入我们构造的某一个弱分类器
,接着将这18个样本输入我们构造的某一个弱分类器![]() ,计算分类的误差e_{k}(分类的结果和原结果比对不一致的),接着我们更新每个弱分类器的权重参数
,计算分类的误差e_{k}(分类的结果和原结果比对不一致的),接着我们更新每个弱分类器的权重参数![]() ,最后我们得到了一个强分类器
,最后我们得到了一个强分类器 。
。
2.5 弱分类器的构建
详见三. 2.3
2.6 多元分类的处理方法
详见三.2.3
三. 代码的实现过程
这部分代码相当多,而且涉及到许多抽象类和接口,需要单独拎出来分析。所以按着代码的执行过程一步一步从整体框架的角度来分析执行过程。
1. WeightedInstances类
WeightedInstances首先继承的是Instances类,即有Instances类的调用方法如数据处理函数,另外WeightedInstances增加了一个weights数组用于存放每个样本数据的权重。WeightedInstances类可以简单理解成对样本数据权重的计算的类。
/**
* Weights.
*/
private double[] weights;1.1两个构造函数:
第一个构造函数表示传入数据的路径,读取数据,并且初始化设置weights数组的权重。
第二个构造函数仅仅改变传入参数为Instances类,并且初始化设置weights数组的权重。
/**
******************
* The first constructor.
*
* @param paraFileReader
* The given reader to read data from file.
******************
*/
public WeightedInstances(FileReader paraFileReader) throws Exception {
super(paraFileReader);
setClassIndex(numAttributes() - 1);
// Initialize weights
weights = new double[numInstances()];
double tempAverage = 1.0 / numInstances();
for (int i = 0; i < weights.length; i++) {
weights[i] = tempAverage;
} // Of for i
System.out.println("Instances weights are: " + Arrays.toString(weights));
} // Of the first constructor
/**
******************
* The second constructor.
*
* @param paraInstances
* The given instance.
******************
*/
public WeightedInstances(Instances paraInstances) {
super(paraInstances);
setClassIndex(numAttributes() - 1);
// Initialize weights
weights = new double[numInstances()];
double tempAverage = 1.0 / numInstances();
for (int i = 0; i < weights.length; i++) {
weights[i] = tempAverage;
} // Of for i
System.out.println("Instances weights are: " + Arrays.toString(weights));
} // Of the second constructor1.2 得到样本的权重
由于权重是private型变量,只能通过函数进行访问,所以这里设置了getWeight函数,传入某行i,输出第i行样本数据的权重。
/**
******************
* Getter.
*
* @param paraIndex
* The given index.
* @return The weight of the given index.
******************
*/
public double getWeight(int paraIndex) {
return weights[paraIndex];
} // Of getWeight1.3 WeightedInstances类的核心代码adjustWeights函数
adjustWeights函数表示传入的参数为(上一个分类器的判定结果是否正确构成的数组,和上一个分类器的权重系数![]() ),计算
),计算![]() ,接着对每一个样本进行循环,如果判断正确,则计算公式为:weights[i] /= tempIncrease;否则weights[i] *= tempIncrease;。最后进行归一化操作:tempWeightsSum += weights[i];weights[i] /= tempWeightsSum;。
,接着对每一个样本进行循环,如果判断正确,则计算公式为:weights[i] /= tempIncrease;否则weights[i] *= tempIncrease;。最后进行归一化操作:tempWeightsSum += weights[i];weights[i] /= tempWeightsSum;。
这里的理论基础是:
![]()
![]()
这样我们就更新了下一轮的样本数据的权重值
/**
******************
* Adjust the weights.
*
* @param paraCorrectArray
* Indicate which instances have been correctly classified.
* @param paraAlpha
* The weight of the last classifier.
******************
*/
public void adjustWeights(boolean[] paraCorrectArray, double paraAlpha) {
// Step 1. Calculate alpha.
double tempIncrease = Math.exp(paraAlpha);
// Step 2. Adjust.
double tempWeightsSum = 0; // For normalization.
for (int i = 0; i < weights.length; i++) {
if (paraCorrectArray[i]) {
weights[i] /= tempIncrease;
} else {
weights[i] *= tempIncrease;
} // Of if
tempWeightsSum += weights[i];
} // Of for i
// Step 3. Normalize.
for (int i = 0; i < weights.length; i++) {
weights[i] /= tempWeightsSum;
} // Of for i
System.out.println("After adjusting, instances weights are: " + Arrays.toString(weights));
} // Of adjustWeights总结:WeightedInstances类的作用主要是构建了一个权重数组weights用于记录每个样本的权重,并且它的核心代码是adjustWeights函数,它的作用是根据上一个分类器的判定结果和上一个分类器的权重值调整下一轮样本数据的权重值。
2. 构造弱分类器的StumpClassifier类和抽象类SimpleClassifier
StumpClassifier是继承SimpleClassifier类,而SimpleClassifier可以理解为一个接口。而StumpClassifier可以理解为构造弱分类器的类。
2.1 基本参数解释
bestCut是切割点(对于所有样本的某一个属性小于bestCut被分类为leftLeafLabel标签,大于bestCut被分类为rightLeafLabel),
/**
* The best cut for the current attribute on weightedInstances.
*/
double bestCut;
/**
* The class label for attribute value less than bestCut.
*/
int leftLeafLabel;
/**
* The class label for attribute value no less than bestCut.
*/
int rightLeafLabel;
/**
******************
* The only constructor.
*
* @param paraWeightedInstances
* The given instances.
******************
*/2.2 构造函数
调用的SimpleClassifier抽象类的函数(继承),
/**
******************
* The only constructor.
*
* @param paraWeightedInstances
* The given instances.
******************
*/
public StumpClassifier(WeightedInstances paraWeightedInstances) {
super(paraWeightedInstances);
}// Of the only constructor下面是父类SimpleClassifier类的构造函数,主要是些赋值操作。
/**
******************
* The first constructor.
*
* @param paraWeightedInstances
* The given instances.
******************
*/
public SimpleClassifier(WeightedInstances paraWeightedInstances) {
weightedInstances = paraWeightedInstances;
numConditions = weightedInstances.numAttributes() - 1;
numInstances = weightedInstances.numInstances();
numClasses = weightedInstances.classAttribute().numValues();
}// Of the first constructor2.3 训练弱分类器(StumpClassifier类的核心代码,文章重点)
我们现在所传入的数据是一堆加了权重的样本数据WeightedInstances类。
首先我们选择样本的一个随机属性selectedAttribute,这是构造这个弱分类的标准
// Step 1. Randomly choose an attribute.
selectedAttribute = random.nextInt(numConditions);接着我们构造一个tempValuesArray数组存储所有样本的selectedAttribute属性的具体值,然后根据tempValuesArray数组的大小进行排序。
// Step 2. Find all attribute values and sort.
double[] tempValuesArray = new double[numInstances];
for (int i = 0; i < tempValuesArray.length; i++) {
tempValuesArray[i] = weightedInstances.instance(i).value(selectedAttribute);
} // Of for i
Arrays.sort(tempValuesArray);
接着我们构造一个数组tempLabelCountArray,这个数组的大小为标签种类个数numClasses,然后扫描整个数据集,将这个数据集每个样本根据标签不同分成numClasses个类,并且记录他们的权值之和。
// Step 3. Initialize, classify all instances as the same with the
// original cut.
int tempNumLabels = numClasses;
double[] tempLabelCountArray = new double[tempNumLabels];
int tempCurrentLabel;
// Step 3.1 Scan all labels to obtain their counts.
for (int i = 0; i < numInstances; i++) {
// The label of the ith instance
tempCurrentLabel = (int) weightedInstances.instance(i).classValue();
tempLabelCountArray[tempCurrentLabel] += weightedInstances.getWeight(i);
} // Of for i
然后我们在这个实际样本里面寻找最佳标签,即遍历数组tempLabelCountArray,找到权值最大的标签种类tempBestLabel,和他们的权值tempMaxCorrect。这里的tempBestLabel和tempMaxCorrect都是实际数据得到的结果,一定要注意。
// Step 3.2 Find the label with the maximal count.
double tempMaxCorrect = 0;
int tempBestLabel = -1;
for (int i = 0; i < tempLabelCountArray.length; i++) {
if (tempMaxCorrect < tempLabelCountArray[i]) {
tempMaxCorrect = tempLabelCountArray[i];
tempBestLabel = i;
} // Of if
} // Of for i然后我们寻找最佳的切割点,到底该怎么寻找呢?挨着挨着试每一个数据,我们首先设置一个切割点,这个切割点一定不能是数据集本身里面的数据,即这个切割点一定能把数据完全分成两份。
首先我们先设置切割点为最小的值-0.1(这里-0.1就是为了使切割点不和原本的数据集重叠),初始化左右树判定结果都为tempBestLabel(真实数据里面最多的标签类)。
// Step 3.3 The cut is a little bit smaller than the minimal value.
bestCut = tempValuesArray[0] - 0.1;
leftLeafLabel = tempBestLabel;
rightLeafLabel = tempBestLabel;构建一个二维矩阵tempLabelCountMatrix,设置临时切割点tempCut。首先遍历所有的数据(为了找到最好的分割点),临时切割点tempCut= (tempValuesArray[i] + tempValuesArray[i + 1]) / 2并且这里的两个数据不能相等(若相等的话,就不能完全将数据集分成两个了)。这里需要讲一下tempLabelCountMatrix矩阵是用来干什么的,tempLabelCountMatrix矩阵用于记录每次设置tempCut切割点之后,对应遍历整个数据集然后将对应的权重相加到tempLabelCountMatrix。

// Step 4. Check candidate cuts one by one.
// Step 4.1 To handle multi-class data, left and right.
double tempCut;
double[][] tempLabelCountMatrix = new double[2][tempNumLabels];
for (int i = 0; i < tempValuesArray.length - 1; i++) {
// Step 4.1 Some attribute values are identical, ignore them.
if (tempValuesArray[i] == tempValuesArray[i + 1]) {
continue;
} // Of if
tempCut = (tempValuesArray[i] + tempValuesArray[i + 1]) / 2;
// Step 4.2 Scan all labels to obtain their counts wrt. the cut.
// Initialize again since it is used many times.
for (int j = 0; j < 2; j++) {
for (int k = 0; k < tempNumLabels; k++) {
tempLabelCountMatrix[j][k] = 0;
} // Of for k
} // Of for j
for (int j = 0; j < numInstances; j++) {
// The label of the jth instance
tempCurrentLabel = (int) weightedInstances.instance(j).classValue();
if (weightedInstances.instance(j).value(selectedAttribute) < tempCut) {
tempLabelCountMatrix[0][tempCurrentLabel] += weightedInstances.getWeight(j);
} else {
tempLabelCountMatrix[1][tempCurrentLabel] += weightedInstances.getWeight(j);
} // Of if
} // Of for i
每设置一个临时分割点tempcut,都要针对于这个切割点进行上述操作,接着从tempLabelCountMatrix矩阵里面选择出最有可能被分到的标签。
这里的最有可能就是上述 ——二 2.6(多元分类的处理方法)的实现过程,即我们根据分割点统标签的权重大小,最大的那一个作为弱分类器的分类结果。
紧接着我们选择第一行权重最大的标签为tempLeftBestLabel,第一行最大的权重为tempLeftMaxCorrect;同理第二行权重最大的标签为tempRightBestLabel,第二行最大的权重为tempRightMaxCorrect。
// Step 4.3 Left leaf.
double tempLeftMaxCorrect = 0;
int tempLeftBestLabel = 0;
for (int j = 0; j < tempLabelCountMatrix[0].length; j++) {
if (tempLeftMaxCorrect < tempLabelCountMatrix[0][j]) {
tempLeftMaxCorrect = tempLabelCountMatrix[0][j];
tempLeftBestLabel = j;
} // Of if
} // Of for i
// Step 4.4 Right leaf.
double tempRightMaxCorrect = 0;
int tempRightBestLabel = 0;
for (int j = 0; j < tempLabelCountMatrix[1].length; j++) {
if (tempRightMaxCorrect < tempLabelCountMatrix[1][j]) {
tempRightMaxCorrect = tempLabelCountMatrix[1][j];
tempRightBestLabel = j;
} // Of if
} // Of for i这样我们就选出了一个可能的弱分类器,这个分类器怎么样呢?到底好不好呢?接着我们开始和之前的数据进行比较。
如果说这里的分类结果的权重值tempLeftMaxCorrect + tempRightMaxCorrect>tempMaxCorrect(之前的权重值),那就说明这个分类器的效果更好(因为它占有更大的权重)更新一下tempMaxCorrect和最佳切割点bestCut。训练结束

// Step 4.5 Compare with the current best.
if (tempMaxCorrect < tempLeftMaxCorrect + tempRightMaxCorrect) {
tempMaxCorrect = tempLeftMaxCorrect + tempRightMaxCorrect;
bestCut = tempCut;
leftLeafLabel = tempLeftBestLabel;
rightLeafLabel = tempRightBestLabel;
} // Of if最后总结一下,train这部分代码相当难理解,主要是要明白输入参数是什么,输出参数是什么以及我们构建的每一个变量的作用是什么,除此之外还需要对AdaBoosting算法理解到位才行。然后train主要做的一个工作就是根据样本的某一个属性,构建分类器,这个分类器怎么样构建的(挨着挨着试,试出来最优的分类器(权重最大));以及对于多元分类问题的处理方式(普通的AdaBoosting算法是二元分类问题),都是在这里解决,可以说这部分理解到位之后,后面就是豁然开朗。
2.4 弱分类器的预测
上面搞了这么大一堆东西,主要不就是为了得到一个弱分类器吗?他来了,
传入某一个样本(paraInstance);接着bestCut作为最佳分类点,selectedAttribute为挑选的属性,leftLeafLabel为小于bestCut的分类结果,rightLeafLabel为大于bestCut的分类结果。

3. 主类Booster的分析
完成了上述的过程,我们终于到主类了
3.1 基本初始化
首先来看这个算法的起点——主函数
/**
******************
* For integration test.
*
* @param args
* Not provided.
******************
*/
public static void main(String args[]) {
System.out.println("Starting AdaBoosting...");
Booster tempBooster = new Booster("D:/data/iris.arff");
// Booster tempBooster = new Booster("src/data/smalliris.arff");
tempBooster.setNumBaseClassifiers(100);
tempBooster.train();
System.out.println("The training accuracy is: " + tempBooster.computeTrainingAccuray());
tempBooster.test();
}// Of main这里有一个构造函数Booster,输入的是文件的路径,这个构造函数的主要作用是赋值某些参数,没什么特别的,看看就好
/**
******************
* The first constructor. The testing set is the same as the training set.
*
* @param paraTrainingFilename
* The data filename.
******************
*/
public Booster(String paraTrainingFilename) {
// Step 1. Read training set.
try {
FileReader tempFileReader = new FileReader(paraTrainingFilename);
trainingData = new Instances(tempFileReader);
tempFileReader.close();
} catch (Exception ee) {
System.out.println("Cannot read the file: " + paraTrainingFilename + "\r\n" + ee);
System.exit(0);
} // Of try
// Step 2. Set the last attribute as the class index.
trainingData.setClassIndex(trainingData.numAttributes() - 1);
// Step 3. The testing data is the same as the training data.
testingData = trainingData;
stopAfterConverge = true;
// System.out.println("****************Data**********\r\n" + trainingData);
}// Of the first constructor接着我们来到主函数里面的tempBooster.setNumBaseClassifiers(100),这里主要是设置弱分类器的个数。
详细的setNumBaseClassifiers函数如下所示,classifiers构造弱分类器的数组,每个数组的值空间里面都是一个弱分类器的数据结构;classifierWeights是每个弱分类器的权重。
/**
******************
* Set the number of base classifier, and allocate space for them.
*
* @param paraNumBaseClassifiers
* The number of base classifier.
******************
*/
public void setNumBaseClassifiers(int paraNumBaseClassifiers) {
numClassifiers = paraNumBaseClassifiers;
// Step 1. Allocate space (only reference) for classifiers
classifiers = new SimpleClassifier[numClassifiers];
// Step 2. Initialize classifier weights.
classifierWeights = new double[numClassifiers];
}// Of setNumBaseClassifiers3.2 训练函数
①由于我们的分类器的个数是100(也是迭代的次数),第一重循环是迭代的次数(100次)。接着做了一个if判断语句,若迭代的次数是第一次时,我们直接初始化权重类WeightedInstances;若不是第一次时,根据上一个分类器的分类结果classifiers[i - 1].computeCorrectnessArray()和分类器的权重值classifierWeights[i - 1]进行调整(详见三. 1.3);总之我们得到了每一个样本现在的权重对象tempWeightedInstances。
/**
******************
* Train the booster.
*
* @see algorithm.StumpClassifier#train()
******************
*/
public void train() {
// Step 1. Initialize.
WeightedInstances tempWeightedInstances = null;
double tempError;
numClassifiers = 0;
// Step 2. Build other classifiers.
for (int i = 0; i < classifiers.length; i++) {
// Step 2.1 Key code: Construct or adjust the weightedInstances
if (i == 0) {
tempWeightedInstances = new WeightedInstances(trainingData);
} else {
// Adjust the weights of the data.
tempWeightedInstances.adjustWeights(classifiers[i - 1].computeCorrectnessArray(),
classifierWeights[i - 1]);
} // Of if②最后根据这个tempWeightedInstances对象的权重和数据训练得到classifiers[i](弱分类器的数值(bestcut,leftlabel,rightlabel))。
// Step 2.2 Train the next classifier.
classifiers[i] = new StumpClassifier(tempWeightedInstances);
classifiers[i].train();③接着我们计算这个弱分类器器的误差
tempError = classifiers[i].computeWeightedError();以下是computeWeightedError()函数
tempCorrectnessArray = computeCorrectnessArray();用于计算通过这个分类器,得到判定数组tempCorrectnessArray[ ](若通过这个弱分类器得到的是和数据一样的标签,则为true,否则为false)。
接着我们遍历整个判定数组tempCorrectnessArray,如果判定数组的某个值为false,则将它的权重相加到resultError。即文章理论部分的。
/**
******************
* Compute the weighted error on the training set. It is at least 1e-6 to
* avoid NaN.
*
* @return The weighted error.
******************
*/
public double computeWeightedError() {
double resultError = 0;
boolean[] tempCorrectnessArray = computeCorrectnessArray();
for (int i = 0; i < tempCorrectnessArray.length; i++) {
if (!tempCorrectnessArray[i]) {
resultError += weightedInstances.getWeight(i);
} // Of if
} // Of for i
if (resultError < 1e-6) {
resultError = 1e-6;
} // Of if
return resultError;
}// Of computeWeightedError
} // Of class SimpleClassifier以下是computeCorrectnessArray函数
/**
******************
* Which instances in the training set are correctly classified.
*
* @return The correctness array.
******************
*/
public boolean[] computeCorrectnessArray() {
boolean[] resultCorrectnessArray = new boolean[weightedInstances.numInstances()];
for (int i = 0; i < resultCorrectnessArray.length; i++) {
Instance tempInstance = weightedInstances.instance(i);
if ((int) (tempInstance.classValue()) == classify(tempInstance)) {
resultCorrectnessArray[i] = true;
} // Of if
// System.out.print("\t" + classify(tempInstance));
} // Of for i
// System.out.println();
return resultCorrectnessArray;
}// Of computeCorrectnessArray ④由上述关系得到![]() ,接着用计算这个分类器的权重值
,接着用计算这个分类器的权重值![]() ,分类器数(迭代次数)自加1。
,分类器数(迭代次数)自加1。
// Key code: Set the classifier weight.
classifierWeights[i] = 0.5 * Math.log(1 / tempError - 1);
if (classifierWeights[i] < 1e-6) {
classifierWeights[i] = 0;
} // Of if
System.out.println("Classifier #" + i + " , weighted error = " + tempError + ", weight = "
+ classifierWeights[i] + "\r\n");
numClassifiers++;⑤最后每次迭代完成之后都需要计算一下这些所有已经构建的分类器的分类效果(训练集作为测试集),如果训练结果为1,那么不用继续迭代了,直接输出已经得到的分类器的值(这个时候可能没有达到100次,但是预测准确率已经达到1了,比如迭代到第k次,那么我们只需要取前k个弱分类器即可,后面的分类器直接抛弃)
if (stopAfterConverge) {
double tempTrainingAccuracy = computeTrainingAccuray();
System.out.println("The accuracy of the booster is: " + tempTrainingAccuracy + "\r\n");
if (tempTrainingAccuracy > 0.999999) {
System.out.println("Stop at the round: " + i + " due to converge.\r\n");
break;
} // Of if
} // Of if计算准确率的代码computeTrainingAccuray()函数
/**
******************
* Compute the training accuracy of the booster. It is not weighted.
*
* @return The training accuracy.
******************
*/
public double computeTrainingAccuray() {
double tempCorrect = 0;
for (int i = 0; i < trainingData.numInstances(); i++) {
if (classify(trainingData.instance(i)) == (int) trainingData.instance(i).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
double tempAccuracy = tempCorrect / trainingData.numInstances();
return tempAccuracy;
}// Of computeTrainingAccuray3.3 测试函数
System.out.println("The training accuracy is: " + tempBooster.computeTrainingAccuray());
tempBooster.test(); /**
******************
* Test the booster.
*
* @param paraInstances
* The testing set.
* @return The classification accuracy.
******************
*/
public double test(Instances paraInstances) {
double tempCorrect = 0;
paraInstances.setClassIndex(paraInstances.numAttributes() - 1);
for (int i = 0; i < paraInstances.numInstances(); i++) {
Instance tempInstance = paraInstances.instance(i);
if (classify(tempInstance) == (int) tempInstance.classValue()) {
tempCorrect++;
} // Of if
} // Of for i
double resultAccuracy = tempCorrect / paraInstances.numInstances();
System.out.println("The accuracy is: " + resultAccuracy);
return resultAccuracy;
} // Of test这里是核心,主要是tempLabel = classifiers[i].classify(paraInstance);得到具体样本的分离标签tempLabel,接着tempLabelsCountArray[tempLabel] += classifierWeights[i];,统计每个标签的分类器权重值。最后选出最大的权重对应的标签即作为预测结果。
/**
******************
* Classify an instance.
*
* @param paraInstance
* The given instance.
* @return The predicted label.
******************
*/
public int classify(Instance paraInstance) {
double[] tempLabelsCountArray = new double[trainingData.classAttribute().numValues()];
for (int i = 0; i < numClassifiers; i++) {
int tempLabel = classifiers[i].classify(paraInstance);
tempLabelsCountArray[tempLabel] += classifierWeights[i];
} // Of for i
int resultLabel = -1;
double tempMax = -1;
for (int i = 0; i < tempLabelsCountArray.length; i++) {
if (tempMax < tempLabelsCountArray[i]) {
tempMax = tempLabelsCountArray[i];
resultLabel = i;
} // Of if
} // Of for
return resultLabel;
}// Of classify四. 代码展示
详见文章(19条消息) 日撸 Java 三百行(61-70天,决策树与集成学习)_闵帆的博客-CSDN博客
五. 总结
在做较大的算法学习的时候,我觉得第一重要的是理解到算法的过程,为什么要这么设置这个计算方法,需要达到的最优化目标是什么。这些都是数学基础,可用数学公式描绘出来,一步一步踏踏实实了解到每个公式的具体含义是什么。
完成上述理论学习之后,为了加深自己的理解,可以举一个数据集的例子,比如怎么样对数据进行处理的,数学公式的展现是怎么样体现的。
最后到了代码的编写阶段,按着上面两步,编写代码其实就是复现的过程,写代码和理解理论本来就是相辅相成的过程,学习理论才可以写得出来代码,写出来代码又对理论进行了加深和巩固,这编写代码我们需要做的只不过是按着步骤一一做下去而已。