Transformer、Bert、GPT简介
Transformer
首先看一下trasformer结构

简单回顾一下,encoder将token编码处理,得到embedding.然后送入decoder。decoder的input是前一个时间点产生的output。

Masked Multi-Head Attention,Masked的意思是,在做self-attention的时候,这个decoder只会attend到已经产生的sequence(这个sequence长度和encoder的输出长度不一样),因为没有产生的部分无法做attention
一个有趣的动画:
Encode:所有word两两之间做attention,有三个attention layer
Decode:不只 attend input 也会attend 之前已经输出的部分
损失函数:
Q&A
q1:decoder的输入长度为什么和encoder的不一样,decoder的输入是什么?
训练时是GT+Positional Embedding。没有Positional Embedding的Attention mask只能做到看到当前位置之前的所有信息,而做不到有序
预测时是(1)起始符以及后续。
以问答为例,训练阶段我是知道decoder最终输出是“I am fine”,所以decoder的【输入】在训练阶段分别为(1)起始符(2)起始符+I(3)起始符+I+am(4)起始符+I+am+fine,因为我们知道正确的最终输出是什么,所以这4个阶段是可以并行执行的.
但是预测阶段,我们是不知道decoder的输出的,所以我们只能decoder的输入只能逐步进行(1)起始符(2)起始符+decoder预测单词1(3)起始符+decoder预测单词1+decoder预测单词2…,这样
BERT
结构:
BERT只使用了transformer的encoder部分.
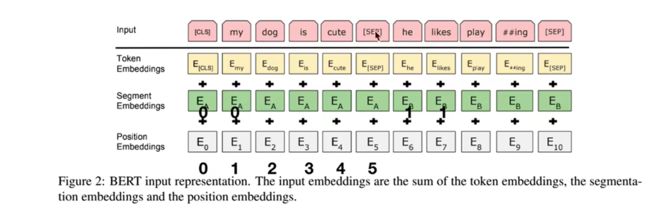
input: token embedding +segment embedding + position embedding
会将输入的自然语言句子通过WordPiece embeddings来转化为token序列。之所以会有segment embedding是因为bert会做NSP(next sentense prediction)任务,判断两个句子间的关系,需要sentense级别的信息
output:为预测这些被遮盖掉的token,被mask掉的词将会被输入到一个softmax分类器中,分类器输出的维度对应词典的大小。
方法:
AE:auto encoder

损失函数为:负对数似然函数 + 二分类损失函数
具体的损失函数参看BERT损失函数
Q&A
q1:BERT怎么实现双向的:
对比GPT,BERT使用了双向self-attention架构,而GPT使用的是受限的self-attention, 即限制每个token只能attend到其左边的token。
为了能够双向地训练语言模型,BERT的做法是简单地随机mask掉一定比例的输入token(这些token被替换成[MASK]这个特殊token),然后
GPT
GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT 预训练的方式是使用 Mask LM。
例如给定一个句子 [u1, u2, …, un],GPT 在预测单词 ui 的时候只会利用 [u1, u2, …, u(i-1)] 的信息,而 BERT 会同时利用 [u1, u2, …, u(i-1), u(i+1), …, un] 的信息
结构
GPT只使用了transformer的decoder部分,并去掉了第二个multi self attention layer
方法:
AR:auto regressive

损失函数为:给定一个无标签的序列 u = { u 1 , u 2 , ⋯ u i } u= \{u_1, u_2 , \cdots u_i \} u={u1,u2,⋯ui},语言模型的优化目标是最大化下面的似然值:
L 1 ( U ) = ∑ i log P ( u i ∣ u i − k , … , u i − 1 ; Θ ) L_{1}(\mathcal{U})=\sum_{i} \log P\left(u_{i} \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1(U)=i∑logP(ui∣ui−k,…,ui−1;Θ)
Q&A
q1:GPT是一个单词一个单词的预测概率嘛?
是的。