基于蝙蝠算法优化BP神经网络的数据分类算法及其MATLAB实现-附代码
基于蝙蝠算法优化BP神经网络的数据分类算法及其MATLAB实现-附代码
文章目录
- 基于蝙蝠算法优化BP神经网络的数据分类算法及其MATLAB实现-附代码
- 1 蝙蝠算法与BP神经网络分类模型
-
- 1.1 蝙蝠算法BA
- 1.2 one-hot编码
- 2 基于蝙蝠算法BA优化的BP神经网络分类算法
-
- 2.1 优化变量与目标函数的选取
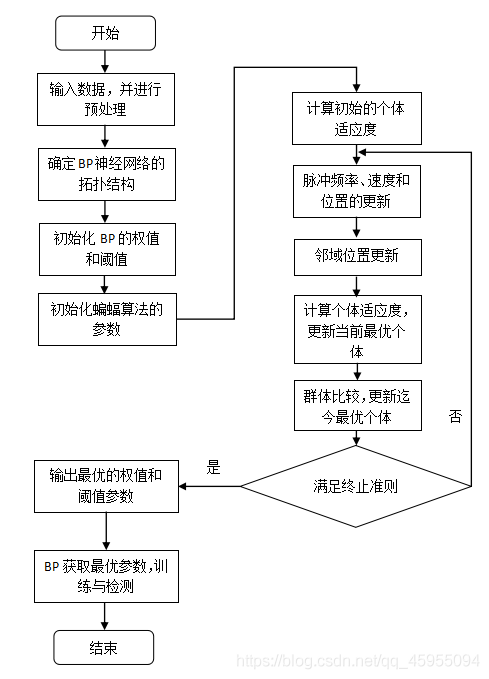
- 2.2 基于BA-BP分类的建模步骤
- 3 算法参数设置
- 4 运行结果
- 5. BP神经网络分类及相关优化算法模型
1 蝙蝠算法与BP神经网络分类模型
BP神经网络通过自身的训练,在训练过程中调整参数,来学习输入数据和输出数据之间的映射规则,从而实现在给定输入时,能得到比较接近期望输出的结果。作为一种传统的深度学习算法,BP神经网络经常用来求解预测方面的问题,比如电力负荷预测,客流量预测,切削力预测。也可以作为分类器,用来解决轴承故障诊断,企业信誉评级等分类问题。在BP神经网络训练的过程中,初始权值和阈值的选取,对最终训练结构有着较大的影响,采用蝙蝠算法作为优化器,以BP分类器的分类精度作为优化目标,来优化网络的权值与阈值,得到较高的分类精度。
1.1 蝙蝠算法BA
蝙蝠算法 (Bat Algorithm, BA) 是一种基于群体智能的优化算法,受蝙蝠回生定位技术的启发,由Xin-She Yang于2010年提出。蝙蝠个体将声音辐射到周围环境,并根据不同物体的回生,来识别猎物,躲避障碍物,以及在黑暗的环境中找到巢穴。蝙蝠算法具有结构简单、参数较少、便于实现等优点,主要用于求解连续型优化问题,在函数优化,图像识别,故障诊断,调度问题等方面有着广泛的应用。
建立蝙蝠算法的数学模型,作出以下几点假设规则:
- 搜索规则: 所有蝙蝠利用回声定位的方法感知距离,并且它们采用一种巧妙的方式来区别猎物和背景障碍物之间的不同。
- 参数变化规则: 蝙蝠在位置 x i x_i xi以速度 v i v_i vi随机飞行,以固定的频率 f m i n f_{min} fmin、可变的波长 λ \lambda λ和音量 A 0 A_0 A0来搜索猎物。蝙蝠根据自身与目标的邻近程度来自动调整发射的脉冲波长(或频率)和调整脉冲发射率 r r r。
- 音量变化规则: 假定音量 A A A是从一个最大值 A 0 A_0 A0(整数)变化到固定最小值 A m i n A_{min} Amin。
蝙蝠算法实施步骤:
-
参数初始化。包括种群大小,最大迭代次数,初始的位置,速度,音量,脉冲频率与发射率。
-
计算初始的最优个体位置与适应度。
-
按以下公式进行脉冲频率、速度和个体位置的更新,并进行范围调整。
{ f k = f min + ( f max − f min ) ⋅ β v k t + 1 = v k t + ( x k t − x ∗ ) ⋅ f k x k t + 1 = x k t + v k t \left\{\begin{array}{l} f_{k}=f_{\min }+\left(f_{\max }-f_{\min }\right) \cdot \beta \\ v_{k}^{t+1}=v_{k}^{t}+\left(x_{k}^{t}-x^{*}\right) \cdot f_{k} \\ x_{k}^{t+1}=x_{k}^{t}+v_{k}^{t} \end{array}\right. ⎩ ⎨ ⎧fk=fmin+(fmax−fmin)⋅βvkt+1=vkt+(xkt−x∗)⋅fkxkt+1=xkt+vkt
式中, β \beta β是随机数,服从[01]均匀分布。 -
邻域搜索。按以下公式在最优解附近进行位置的搜索。
x n e w = x o l d + ε A t , r a n d > r k t x_{n e w}=x_{o l d}+\varepsilon A^{t}, rand>r_{k}^{t} xnew=xold+εAt,rand>rkt
式中, r k t r_{k}^{t} rkt为当前的脉冲发射率, A t A^t At为音量。 -
围捕猎物。按以下公式更新脉冲发射率与音量 (不断减小表示围捕靠近猎物的过程)。
-
计算并记录迄今最优个体。
-
重复执行步骤3-6,至满足终止准则,输出最优解与最优适应度。
1.2 one-hot编码
BP神经网络的原理理解请参考博客: BP神经网络时间序列预测。基于BP神经网络预测算法,结合one-hot编码,实现BP分类器。
one-hot编码又叫独热编码,采用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,并且在任意时候只有一位有效,是二进制的向量编码方式。二进制向量,除了整数的索引标记为1之外,其余都是零值。如下所示:

图中,对于四个类型,在编码的二进制列向量中,1的索引数值为相应的标签编号。一方面,由于BP神经网络预测一般为连续型结果,所以采用one-hot方式编码将离散的类型问题转换为连续性问题,再对预测结果进行解码为类型,可避免预测的结果为非整型数值。另一方面,与直接预测1 2 3 4类型的做法相比,这种做法不会出现其他类型如第5和第6类。
解码示意图:
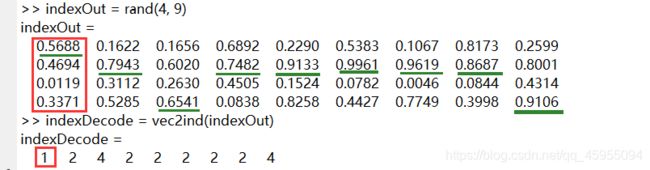
如图所示, 通过解码,实现二进制的连续数值到最大值索引的离散类型的转换。
2 基于蝙蝠算法BA优化的BP神经网络分类算法
2.1 优化变量与目标函数的选取
针对BP神经网络的权值和阈值初始值取值对训练的BP结果有较大影响,使用蝙蝠算法BA进行参数的全局寻优。目标函数采用训练样本与预测样本整体的准确率。目标函数公式如下:
Fobj = Accuracy train + Accuracy test 2 \text { Fobj }=\frac{\text { Accuracy }_{\text {train }}+\text { Accuracy }_{\text {test }}}{2} Fobj =2 Accuracy train + Accuracy test
适应度越大,即优化模型的识别准确率越高,表明训练准确,且兼顾模型的预测精度更好。
2.2 基于BA-BP分类的建模步骤
数据来源: 采用意大利红酒数据集进行分类模型的实现。数据集大小为178组样本,每组样本都具有13个特征,3种标签类型。获取的类型一般采用二进制索引编码:
| 类型 | 编码 |
|---|---|
| 1 | 1 0 0 |
| 2 | 0 1 0 |
| 3 | 0 0 1 |
为了方便操作,将特征与整数类型放到EXCEL中,在程序对数据预处理时,使用代码命令进行编码。读取代码的命令如下:
%% 读取数据
data=xlsread('数据.xlsx','Sheet1','A1:N178'); %使用xlsread函数读取EXCEL中对应范围的数据即可
%输入输出数据
input=data(:,1:end-1); %data的第一列-倒数第二列为特征指标
output_labels=data(:,end); %data的最后面一列为标签类型
建模步骤: 使用蝙蝠算法优化BP神经网络的权值和阈值参数,建立基于蝙蝠算法优化的BA-BP分类模型步骤如下:
(1)将样本分为训练集和测试集,并进行特征归一化和标签编码。
(2)将BP分类器的准确率作为目标函数,对蝙蝠算法进行初始化设置,包括种群数量、最大迭代次数、优化变量范围等算法参数。
(3)采用蝙蝠优化算法,以目标函数取值最大作为寻优目标,获取最优参数。
(4)利用测试集数据对优化后的BP神经网络进行测试。
(5)输出基于蝙蝠算法BA-BP分类模型的测试集分类结果。
3 算法参数设置
%初始化BA参数
popsize=30; %初始种群规模
maxgen=50; %最大进化代数
dim=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum; %自变量个数
lb=repmat(-3,1,dim); %自变量下限
ub=repmat(3,1,dim); %自变量上限
vmin = 0.01*ones(1,dim); % 最小速度
vmax = 1.2*ones(1,dim); % 最大速度
%频率范围
Qmin = 0.1; % 最小频率
Qmax = 2; % 最大频率
A = 0.7; % 音量 (不变或者减小)
r = 0.5; % 脉冲率 (不变或增加)
Af = 0.1; % 音量更新系数
Rf = 0.1; %排放速率更新常数
蝙蝠算法BA优化后的参数赋给BP神经网络:
w1=Best_pos(1:inputnum*hiddennum); %输入层到中间层的权值
B1=Best_pos(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum); %中间各层神经元阈值
w2=Best_pos(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum); %中间层到输出层的权值
B2=Best_pos(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum); %输出层各神经元阈值
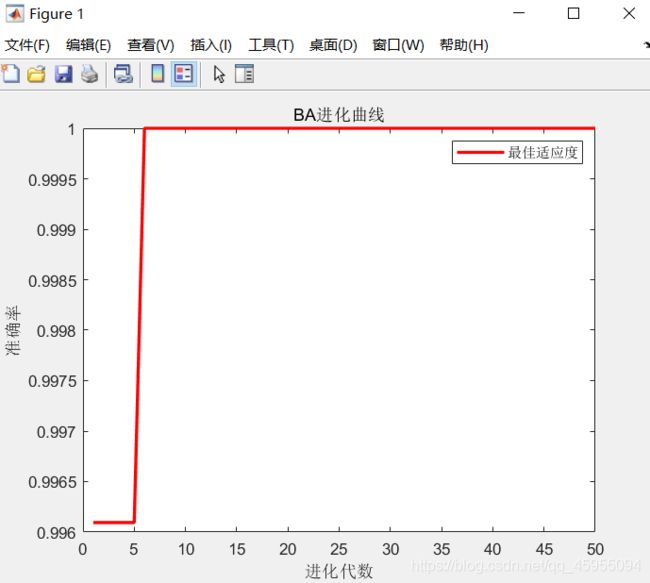
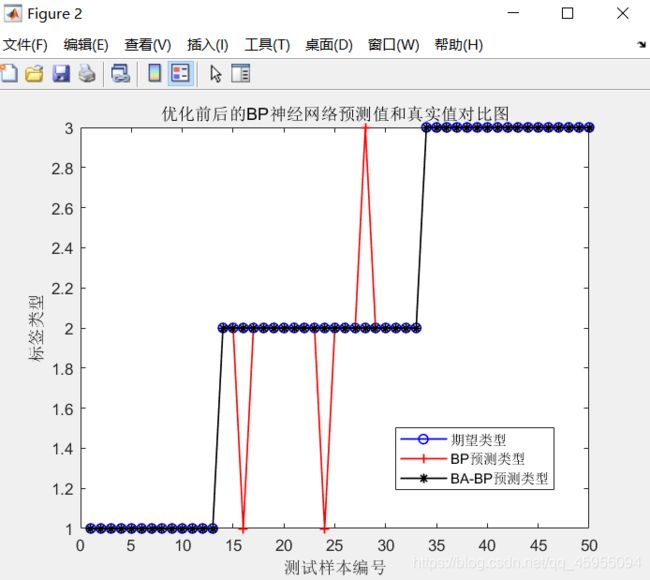
4 运行结果

5. BP神经网络分类及相关优化算法模型
CSDN下载代码地址
https://download.csdn.net/download/qq_57971471/87730510
以下介绍了常见的BP神经网络分类算法模型及编写相应的代码,相关模型原理见博客主页。
|分类模型|
|–|–|
|BP神经网络分类及优化算法模型
|BP神经网络数据分类算法MATLAB代码
|BP神经网络数据分类的GUI实现
|遗传算法GA优化BP分类算法MATLAB代码
|麻雀搜索算法SSA优化BP神经网络分类MATLAB代码
|蝙蝠算法BA优化BP神经网络分类MATLAB代码
|Elman神经网络数据分类算法MATLAB代码
|遗传算法GA优化最小二乘支持向量机分类MATLAB代码
|灰狼优化算法GWO优化最小二乘支持向量机分类MATLAB代码
蝙蝠算法优化BP神经网络分类博客文章的代码地址
https://download.csdn.net/download/qq_57971471/87730510