基于hadoop日志流量分析的spark处理
在hadoop日志流量分析中,处理阶段是处理引擎使用的是mr,根据部分课设需求,需要用Spark处理数据,再次篇文章中就使用spark处理数据并完成可视化分析.
项目介绍虽有不同,但是实际要求与数据都是与hadoop项目是完全一致的,因此下面有些部分重复操作将省略(当然有需要我可把最后从hive中导出来的数据发给出来.)
然后在这里插一句话,码字不易,希望如果对你有帮助,点个赞收藏关注支持一下吧!

首先是pom文件部分,具体配置放下方了。
Spark学习 org.example 1.0-SNAPSHOT 4.0.0 Spark_Core org.apache.spark spark-core_2.12 3.0.0 org.apache.spark spark-sql_2.12 3.0.0 mysql mysql-connector-java 5.1.47 cn.hutool hutool-all 5.8.19 org.apache.spark spark-mllib_2.12 3.4.0 provided org.apache.spark spark-hive_2.12 3.0.0 org.apache.spark spark-streaming_2.12 3.0.0 org.apache.spark spark-streaming-kafka-0-10_2.12 3.0.0 com.fasterxml.jackson.core jackson-core 2.10.1 com.alibaba druid 1.1.10
配置完pom问价,然后根据hadoop做这个项目时候的思想,创建一个agent对象,将一会清洗好的数据放入对象进行操作,如下是具体的日志形式.
这块是agent具体代码,将日志各个字段进行设置,并设置set,get方法(这些注解就是),当然这里繁琐了,这里也可以是用case样例类的格式进行创建对象,可以省略注释操作,自动就有了方法.
class Agent extends Serializable {
@BeanProperty
var valid: Boolean = true
@BeanProperty
var remote_addr: String = null
@BeanProperty
var remote_user: String = null
@BeanProperty
var time_local: String = null
@BeanProperty
var request: String = null
@BeanProperty
var status: String = null
@BeanProperty
var body_bytes_sent: String = null
@BeanProperty
var http_referer: String = null
@BeanProperty
var http_user_agent: String = null
override def toString: String = {
val sb = new StringBuilder
sb.append(this.valid)
sb.append("\001").append(this.getRemote_addr)
sb.append("\001").append(this.getRemote_user)
sb.append("\001").append(this.getTime_local)
sb.append("\001").append(this.getRequest)
sb.append("\001").append(this.getStatus)
sb.append("\001").append(this.getBody_bytes_sent)
sb.append("\001").append(this.getHttp_referer)
sb.append("\001").append(this.getHttp_user_agent)
sb.toString
}
}
这里既然设置完了agent对象了,就要对日志进行操作了,具体代码逻辑如下,清洗方法中还都是一些hadoop项目时的具体处理逻辑,主要是把这些逻辑换成了spark进行实现,就改了一下语法格式,在main中,是设置spark运行环境,配置,利用map方法调用清洗方法对数据进行清洗,用filter方法过滤掉空数据.最终写入本地磁盘路径为“ datas/out5”.
object XiaoHuoLong {
val standard = List("/about",
"/black-ip-list/",
"/cassandra-clustor/",
"/finance-rhive-repurchase/",
"/hadoop-family-roadmap/",
"/hadoop-hive-intro/",
"/hadoop-zookeeper-intro/",
"/hadoop-mahout-roadmap/")
var df1 = DateTimeFormatter.ofPattern("dd/MMM/yyyy:HH:mm:ss", Locale.US)
var df2 = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss", Locale.US)
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[1]").setAppName("test1")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("datas/access.txt")
val mapRDD1: RDD[Agent] = rdd.map(str =>
splitword(str)
)
val mapRDD2 = mapRDD1.map(data => judgment(data))
val filter: RDD[Agent] = mapRDD2.filter(data => !data.toString.contains("\u0001null\u0001null\u0001null\u0001null\u0001null\u0001null\u0001null\u0001null")
)
val value = filter
value.saveAsTextFile("datas/out5")
}
//处理数据ETL
def splitword(str: String): Agent = {
val agent = new Agent()
val arr: Array[String] = str.split(" ")
// println(arr.mkString(","))
if (arr.length > 11) {
agent.setRemote_addr(arr(0))
agent.setRemote_user(arr(1))
var timel = formatDate(arr(3).substring(1))
if (timel == null || timel == "") {
timel = "-invalid_time-"
}
agent.setTime_local(timel)
agent.setRequest(arr(6))
agent.setStatus(arr(8))
agent.setBody_bytes_sent(arr(9))
agent.setHttp_referer(arr(10))
if (arr.length > 12) {
var sb = ""
for (i <- 11 to arr.length - 1) {
sb = sb + arr(i)
}
agent.setHttp_user_agent(sb)
} else {
agent.setHttp_user_agent(arr(11))
}
if (agent.getStatus.toInt >= 400) {
agent.setValid(false)
}
if ("-invalid_time-" == agent.getTime_local) {
agent.setValid(false)
}
} else {
return agent
}
return agent
}
//格式化时间
def formatDate(datestr: String): String = {
try {
df2.format(df1.parse(datestr))
} catch {
case e: ParseException => null
}
}
//添加标识
def filtStaticResource(bean: Agent, pages: List[String]): Agent = {
if (!pages.contains(bean.getRequest())) {
bean.setValid(false)
}
bean
}
//判断
def judgment(agent: Agent): Agent = {
if (agent != null) { // 过滤js/图片/css等静态资源
val agent1: Agent = filtStaticResource(agent, standard)
agent1
} else {
agent
}
}
}
将数据清洗完成后,将具体数据上传值hdfs上。先在启动了Hadoop的Linux系统root目录下创建目录weblog,并将预处理产生的结果文件上传到 weblog 目录下。上传文件由箭头指出.
cd
mkdir weblog
cd weblog
执行 rz 文件上传命令hadoop fs -mkdir -p /weblog/preprocessed
hadoop fs -put part-0000 /weblog/preprocessed
接下来是具体实现数仓部分
启动Hive数据仓库,执行以下操作:
--创建数据仓库
DROP DATABASE IF EXISTS weblog;
CREATE DATABASE weblog;
USE weblog;
--创建表
CREATE TABLE ods_weblog_origin (
valid string, --有效标志
remote_addr string, --来源IP
remote_user string, --用户标志
time_local string, --访问完整时间
request string, --请求的URL
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源URL
http_user_agent string --客户终端标志
)
partitioned by (datestr string)
row format delimited fields terminated by '\001';
--导入数据
load data inpath '/weblog/preprocessed' overwrite into table ods_weblog_origin partition(datestr='20130918');
--生成明细表
--1. 创建明细表 ods_weblog_detwail
CREATE TABLE ods_weblog_detwail (
valid string, --有效标志
remote_addr string, --来源IP
remote_user string, --用户标志
time_local string, --访问完整时间
daystr string, --访问日期
timestr string, --访问时间
month string, --访问月
day string, --访问日
hour string, --访问时
request string, --请求的URL
status string, --响应码
body_bytes_sent string, --传输字节数
http_referer string, --来源URL
ref_host string, --来源的host
ref_path string, --来源路径
ref_query string, --来源参数query
ref_query_id string, --来源参数query的值
http_user_agent string --客户终端标志
)
partitioned by (datestr string);
--2. 创建临时中间表 t_ods_tmp_referurl
CREATE TABLE t_ods_tmp_referurl as SELECT a.*, b.*
FROM ods_weblog_origin a LATERAL VIEW
parse_url_tuple(regexp_replace(http_referer, "\"", ""),'HOST', 'PATH', 'QUERY', 'QUERY:id') b
as host, path, query, query_id;
--3. 创建临时中间表 t_ods_tmp_detail
CREATE TABLE t_ods_tmp_detail as
SELECT b.*, substring(time_local, 0, 10) as daystr,
substring(time_local, 12) as tmstr,
substring(time_local, 6, 2) as month,
substring(time_local, 9, 2) as day,
substring(time_local, 11, 3) as hour
FROM t_ods_tmp_referurl b;
--4. 修改默认动态分区参数
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
--5. 向 ods_weblog_detwail 表中加载数据
insert overwrite table ods_weblog_detwail partition(datestr)
SELECT DISTINCT otd.valid, otd.remote_addr, otd.remote_user,
otd.time_local, otd.daystr, otd.tmstr, otd.month, otd.day, otd.hour,
otr.request, otr.status, otr.body_bytes_sent,
otr.http_referer, otr.host, otr.path,
otr.query, otr.query_id, otr.http_user_agent, otd.daystr
FROM t_ods_tmp_detail as otd, t_ods_tmp_referurl as otr
WHERE otd.remote_addr = otr.remote_addr
AND otd.time_local = otr.time_local
AND otd.body_bytes_sent = otr.body_bytes_sent
AND otd.request = otr.request;
这里开始创建中间分析表
--数据分析
--流量分析
--创建每日访问量表dw_pvs_everyday
CREATE TABLE IF NOT EXISTS dw_pvs_everyday(pvs bigint, month string, day string);
--从宽表 ods_weblog_detwail 获取每日访问量数据并插入维度表 dw_pvs_everyday
INSERT INTO TABLE dw_pvs_everyday
SELECT COUNT(*) AS pvs, owd.month AS month, owd.day AS day
FROM ods_weblog_detwail owd GROUP BY owd.month, owd.day;
--人均浏览量分析
--创建维度表dw_avgpv_user_everyday
CREATE TABLE IF NOT EXISTS dw_avgpv_user_everyday (day string, avgpv string);
--从宽表 ods_weblog_detwail 获取相关数据并插入维度表 dw_avgpv_user_everyday
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-18', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-18' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-19', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-19' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-20', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-20' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-21', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-21' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-22', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-22' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-23', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-23' GROUP by remote_addr) b;
INSERT INTO TABLE dw_avgpv_user_everyday
SELECT '2013-09-24', SUM(b.pvs)/COUNT(b.remote_addr) FROM
(SELECT remote_addr, COUNT(1) AS pvs FROM ods_weblog_detwail WHERE
datestr = '2013-09-24' GROUP by remote_addr) b;
接下来进行数据到处,我这里使用Datax进行到处的,因为sqoop已经停止维护了,所以要尝试新的工具,当然也可以继续使用sqoop。下面就将两种使用方法都放出来了.
在使用之前一定要需要
1. 创建 MySql 数据库和表
--数据导出
--创建数据仓库
DROP DATABASE IF EXISTS sqoopdb;
CREATE DATABASE sqoopdb;
USE sqoopdb;
--创建表
CREATE TABLE t_avgpv_num (
dateStr VARCHAR(255) DEFAULT NULL,
avgPvNum DECIMAL(6,2) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
sqoop的使用
2. 执行数据导出命令
sqoop export \
--connect jdbc:mysql://hadoop01.bgd01:3306/sqoopdb \
--username root \
--password 123456 \
--table t_avgpv_num \
--columns "dateStr,avgPvNum" \
--fields-terminated-by '\001' \
--export-dir /user/hive/warehouse/weblog.db/dw_avgpv_user_everyday
Datax使用
{
"job": {
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"defaultFS": "hdfs://hadoop01:8020",
"path": "/user/hive/warehouse/weblog.db/dw_avgpv_user_everyday/*",
"column": [
"*"
],
"fileType": "text",
"encoding": "UTF-8",
"nullFormat": "\\N",
"fieldDelimiter": "\u0001",
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"connection": [
{
"table": [
"t_avgpv_num_copy"
],
"jdbcUrl": "jdbc:mysql://hadoop01:3306/sqoopdb?useUnicode=true&characterEncoding=utf-8"
}
],
"column": [
"dateStr",
"avgPvNum"
],
"writeMode": "replace"
}
}
}
],
"setting": {
"speed": {
"channel": 1
}
}
}
}
接下来就是可视化部分,由于篇幅问题,就直接放上最终成果照片.
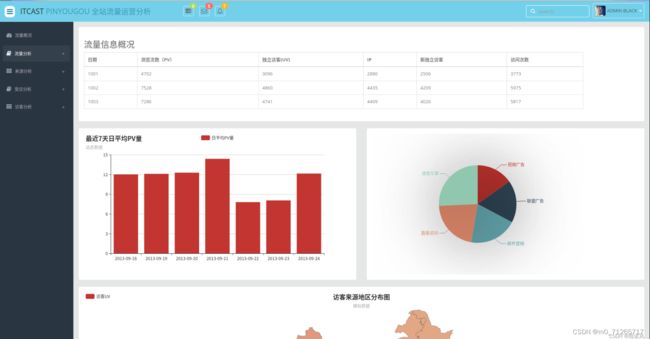 至此,基于spark处理的日志流量分析项目就此完成.
至此,基于spark处理的日志流量分析项目就此完成.
希望大家看完的可以多多评论,有什么不懂的可以评论出来。
然后这篇文章对你有帮助的话,希望能点个小赞,关注支持一下吧!