python 爬取网站首页并获取资源文件
一、使用requests模块,如果没有安装请使用如下命令,安装requests模块
pip install requests二、打开PyCharm,创建一个新的py文件
1.请求网站,获取网页信息
首先使用浏览器,获取请求头信息,用于python模拟浏览器行为请求

封装请求方法
def get_html(url):
""" 请求网址 返回网页内容 """
A = requests.Session()
A.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:103.0) Gecko/20100101 Firefox/103.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
}
web = A.get(url, timeout=7)
# 设置解析编码的方式
web.encoding = 'gb2312'
return web2.通过re模块来匹配获取相应资源路径,os模块创建文件夹及创建写入文件
(1)js 路径为src
(2)image 路径为src
(3)css 路径为href 但会与a标签的href重复 故要多增加一点字符串以作区分
代码如下:
def get_all_img(content):
"""获取网页所有 img css js"""
# 更换编码方式
content = content.replace('charset=gb2312', 'charset=utf-8')
# 获取所有img js文件路径
f_re = 'src="(.*?)"'
file_paths = re.findall(f_re, content)
# 获取单引号的img js文件路径
f_re2 = "src='(.*?)'"
file2_paths = re.findall(f_re2, content)
# 获取所有css文件路径
c_re = 'type="text/css" href="(.*?)"'
css_paths = re.findall(c_re, content)
# 合并到一个列表中
file_paths.extend(css_paths)
if file2_paths:
file_paths.extend(file2_paths)
for file in file_paths:
# 获取文件链接后缀名 只获取css image文件
file_infos = file.split('/')
fileName = file_infos[len(file_infos) - 1]
fileExts = fileName.split('.')
ext = fileExts[len(fileExts) - 1].strip()
if file.find('.js') > -1:
dirName = 'js/'
elif ext == 'css':
dirName = 'css/'
elif ext in ['jpg', 'png', 'gif']:
dirName = 'images/'
else:
continue
# 文件夹不存在 则创建文件夹
if not os.path.exists(dirName):
os.mkdir(dirName)
# # 判断文件格式及是否已存在
fileName_end = dirName + fileName
if not os.path.isfile(fileName_end):
# 处理相对路径资源
if file[1:8] == 'uploads':
file = main_url + file
elif file[0:7] == 'scripts':
continue
try:
pic = get_origin_img(file, main_url)
fp = open(fileName_end, 'wb')
fp.write(pic.content)
fp.close()
except BaseException:
print('获取【%s】失败' % file)
continue
content = content.replace(file, '../' + fileName_end)
return content获取资源的请求方法
def get_origin_img(url, referer):
""" 请求网址图片 增加请求头 返回图片二进制 """
A = requests.Session()
A.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0',
'Accept': 'image/webp,*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Connection': 'keep-alive',
'Referer': referer,
}
return A.get(url, timeout=10)3.把网页内容写入本地文件
def record_article(fileName, dirName, content):
""" 文章内容写入处理 """
if not os.path.exists(dirName):
# 递归创建目录
os.makedirs(dirName)
f = os.open(dirName + '/' + fileName, os.O_RDWR | os.O_CREAT)
os.write(f, str.encode(content))
os.close(f)最后调用方法:
html = get_html(url)
content = get_all_img(html.text)
record_article('首页.html', '首页', content)效果如下:
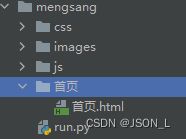
访问本地首页html文件,与原网站一致