JVM常见面试题
一.了解JVM的发展史
1.Sun Classic VM
早在1996年Java1.0版本的时候,Sun公司发不了一款名为Sun Classic vm的java虚拟机,它同时也是世
界上第一款商业java虚拟机,jdk1.4 时完全被淘汰。
这款虚拟机内部只提供解释器。
如果使用JIT编译器,就需要进行外挂。但是一旦使用了JIT编译器,JIT就会接管虚拟机的执行系统。解释
器就不再工作。解释器和编译器不能配合工作。
比特就业课
现在Hotspot内置了此虚拟机;
2.Exact VM
为了解决上一个虚拟机问题,jdk1.2时,sun提供了此虚拟机。
Exact 具备现代高性能虚拟机的雏形,包含了一下功能:
- 热点探测(将热点代码编译为字节码加速程序执行);
- 编译器与解析器混合工作模式。
只在Solaris平台短暂使用,其他平台上还是 classic vm
英雄气短,终被Hotspot虚拟机替换。
3.HotSpot VM
HotSpot 历史 - 最初由一家名为“Longview Technologies”的小公司设计;
- 1997年,此公司被Sun收购;2009年,Sun公司被甲骨文收购。
- JDK1.3时,HotSpot VM成为默认虚拟机
目前 HotSpot 占用绝对的市场地位,称霸武林。
不管是现在仍在广泛使用JDK6,还是使用比较多的JDK8中,默认的虚拟机都是HotSpot;
Sun/Oracle JDK和OpenJDK的默认虚拟机。从服务器、桌面到移动端、嵌入式都有应用。
名称中的HotSpot指的就是它的热点代码探测技术。它能通过计数器找到最具编译价值的代码,触发即
时编译(JIT)或栈上替换;通过编译器与解释器协同工作,在最优化的程序响应时间与最佳执行性能中取
得平衡。
4.JRockit
JRockit 是专注于服务器端应用,目前在HotSpot的基础上,移植JRockit的优秀特性。
它可以不太关注程序的启动速度,因此JRockit内部不包含解析器实现,全部代码都靠即时编译器编译后
执行;
大量的行业基准测试显示,JRockit JVM是世界上最快的JVM。
使用JRockit产品,客户已经体验到了显著的性能提高(一些超过了70%)和硬件成本的减少(达
50%);
优势:全面的Java运行时解决方案组合。
JRockit面向延迟敏感型应用的解决方案JRockit Real Time提供以毫秒或微秒级的JVM响应时间,适合财
务、军事指挥、电信网络的需要;
MissionControl服务套件,它是一组以极低的开销来监控、管理和分析生产环境中的应用程序的工具;
2008,BEA被Oracle收购。
Oracle表达了整合两大优秀虚拟机的工作,大致在JDK8中完成。整合的方式是在HotSpot的基础上,移
植JRockit的优秀特性。
5.J9 JVM
全称:IBM Technology for Java Virtual Machine,简称IT4J,内部代号:J9。
市场定位于HotSpot接近,服务器端、桌面应用、嵌入式等多用途JVM,广泛用于IBM的各种Java产品。
比特就业课
目前,有影响力的三大商用虚拟机之一,也号称是世界上最快的Java虚拟机(在IBM自己的产品上稳定);
2017年左右,IBM发布了开源 J9 VM,命名 OpenJ9,交给Eclipse基金会管理,也称为Eclipse
OpenJ9。
6.Taobao JVM(国产研发)
由 AliJVM 团队发布。阿里,国内使用Java最强大的公司,覆盖云计算、金融、物流、电商等众多领域,
需要解决高并发、高可用、分布式的复合问题。有大量的开源产品。
基于OpenJDK 开发了自己的定制版本AlibabaJDK,简称AJDK。是整个阿里JAVA体系的基石;
基于OpenJDK HotSpot JVM发布的国内第一个优化、深度定制且开源的高性能服务器版Java虚拟机,它
具有以下特点(了解即可): - 创新的GCIH(GC invisible heap)技术实现了off-heap,即将生命周期较长的Java对象从heap中移
到heap之外,并且GC不能管理GCIH内部的Java对象,以此达到降低GC的回收评率和提升GC的回
收效率的目的。 - GCIH中的对象还能够在多个Java虚拟机进程中实现共享。
- 使用crc32指令实现JVM intrinsic降低JNI的调用开销;
- PMU hardware的Java profiling tool和诊断协助功能;
- 针对大数据场景的ZenGC。
taobao JVM应用在阿里产品上性能高,硬件严重依赖intel的cpu,损失了兼容性,但提高了性能,目前已
经在淘宝、天猫上线,把Oracle官方JVM版本全部替换了
二.JVM运行原理
程序在执行之前先要把java代码转换成字节码(class文件),JVM 首先需要把字节码通过一定的方式.
类加载器(ClassLoader) 把文件加载到内存中 运行时数据区(Runtime Data Area) ,而字节码文件是 JVM 的一套指令集规范,并不能直接交个底层操作系统去执行,因此需要特定的命令解析器 **执行引擎(Execution Engine)**将字节码翻译成底层系统指令再交由CPU去执行,而这个过程中需要调用其他语言的接口 本地库接口(Native Interface) 来实现整个程序的功能,这就是这4个主要组成部分的职责与功能
这里用文字描述了一下,下面还是用图片来展示一下,具体的一个流程.

三.JVM运行时的数据区
JVM 运行时数据区域也叫内存布局,但需要注意的是它和 Java 内存模型((Java Memory Model,简称
JMM)完全不同,属于完全不同的两个概念,它由以下 5 大部分组成:
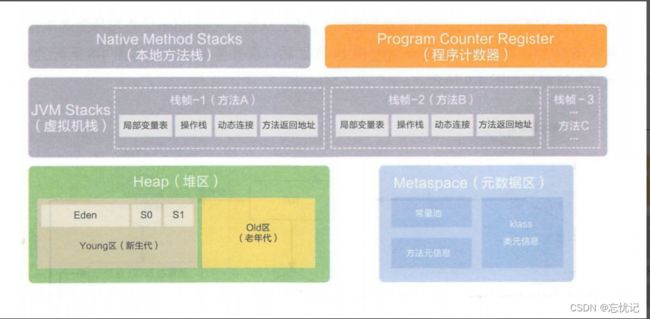
3.1 堆
堆的作用:程序中创建的所有对象都在保存在堆中.
用于存储对象实例和数组,是 JVM 中最大的一块内存区域,它是所有线程共享的。堆通常被划分为年轻代和老年代,以支持垃圾回收机制。

3.2 虚拟机栈
java 虚拟机栈的作用:Java 虚拟机栈的生命周期和线程相同,Java 虚拟机栈描述的是 Java 方法执行的
内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数
栈、动态链接、方法出口等信息。咱们常说的堆内存、栈内存中,栈内存指的就是虚拟机栈。
Java 虚拟机栈中包含了以下 4 部分:

- 局部变量表: 存放了编译器可知的各种基本数据类型(8大基本数据类型)、对象引用。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在执行期间不会改变局部变量表大小。简单来说就是存放方法参数和局部变
量。 - 操作栈:每个方法会生成一个先进后出的操作栈。
- 动态链接:指向运行时常量池的方法引用。
- 方法返回地址:PC 寄存器的地址。
3.3 本地方法栈
本地方法栈和虚拟机栈类似,只不过 Java 虚拟机栈是给 JVM 使用的,而本地方法栈是给本地方法使用的。
3.4 程序计数器
程序计数器的作用:用来记录当前线程执行的行号的。
程序计数器是一块比较小的内存空间,可以看做是当前线程所执行的字节码的行号指示器。
如果当前线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;
如果正在执行的是一个Native方法,这个计数器值为空。
程序计数器内存区域是唯一一个在JVM规范中没有规定任何OOM情况的区域!
3.5 方法区
方法区的作用:用来存储被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据的.
四.JVM类加载过程
对于一个类来说,它的生命周期是这样的:
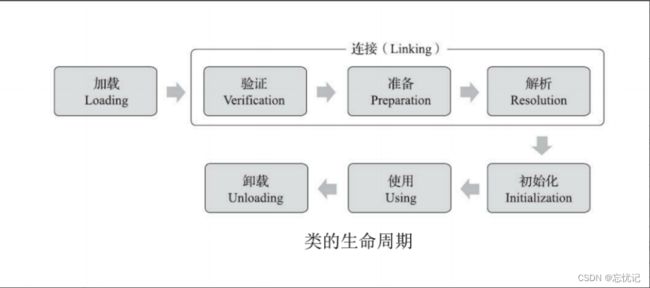
其中前 5 步是固定的顺序并且也是类加载的过程,其中中间的 3 步我们都属于连接,所以对于类加载来
说总共分为以下几个步骤:
- 加载
- 连接
- 验证
- 准备
- 解析
- 初始化
下面我们将逐一解释下面的流程
4.1 加载
加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段,它和类加载 Class Loading 是不同的,一个是加载 Loading 另一个是类加载 Class Loading,所以不要把二者搞混了。
简单来说就是找到.class_文件,并且读文件内容.
4.2 验证
验证是连接阶段的第一步,这一阶段的目的是确保Class文件的字节 流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信 息被当作代码运行后不会危害虚拟机自身的安全。
验证选项:
文件格式验证
字节码验证
符号引用验证
看一下下面官网文档所定的标准的clss文件

4.3 准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
4.4 解析
解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
4.5 初始化
初始化阶段,Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
讲了这么久,我们来提一个问题.
类加载 这个动作,什么时候会触发.
1.创建了这个类的实例
2.使用了这个类的静态方法/静态属性
3.使用子类,会触发父类的加载.
五.双亲委派模型
5.1 什么是双亲委派模型
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最 终都应该传送到最顶层的启动类加载器中,只有当父加载器反馈自己无 法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去完成加载
5.2 双清委派模型的组成部分
具体的组成部分如下:

知道了具体的组成部分以后,我们将进一步的取模拟一个类加载的过程,具体的描述如下图
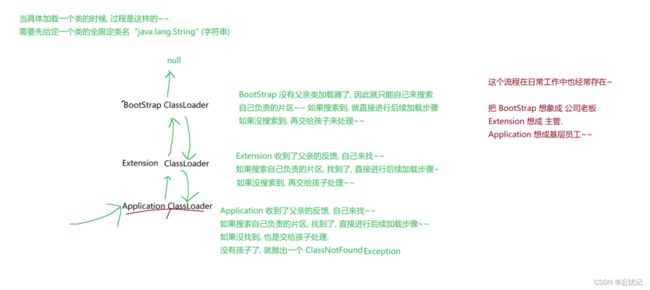
在了解了双亲委派模型的具体流程之后,我们来做一个小小的总结.
它的优点如下.
- 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。
- 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object
类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
六.垃圾回收相关
垃圾回收机制,其实是帮助程序员来自动释放内存的.为什么这么说呢,在学习c语言的时候,就有,malloc手动分配内存,释放内存就要用free函数手动释方,免得引起内存泄露.但是后面java等众多编程语言引入了垃圾回收机制GC,来解决这个问题,能够减少内存泄露的出现概率.
但是我们在解释垃圾回收之前,我们要明白,我们释放的实际上是堆上的空间.
GC实际上分为两个阶段:
1.找谁是垃圾.
2.释放,把垃圾对象的内存释放掉
现在下面我们将逐一解释这几个方面.
6.1 判定垃圾的算法(死亡对象的判断算法)
引用计数算法
先来看看具体的描述:
引用计数描述的算法为:
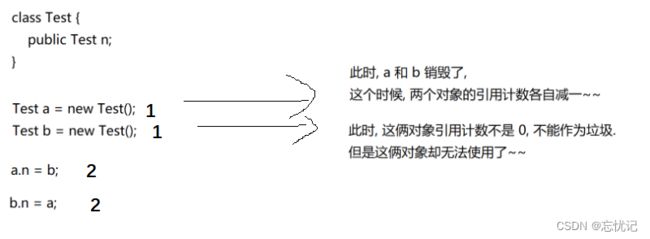
给对象增加一个引用计数器,每当有一个地方引用它时,计数器就+1;当引用失效时,计数器就-1;任何时刻计数器为0的对象就是不能再被使用的,即对象已"死"。
引用计数法实现简单,判定效率也比较高,在大部分情况下都是一个不错的算法。
来具体的看一下我的解释和描述:

当计数算法是有缺陷的.
具体的缺陷如下:
1.浪费内存空间
2.存在循环引用的情况!!
会导致到用计数的判定逻辑出错!!
具体原因如下:
可达性分析
还是简单的来看以下具体的描述
此算法的核心思想为 : 通过一系列称为"GC Roots"的对象作为起始点,从这些节点开始向下搜索,搜索走过的路径称之为"引用链",当一个对象到GC Roots没有任何的引用链相连时(从GC Roots到这个对象不可达)时,证明此对象是不可用的。
具体就像一棵二叉树一样,具体的模拟结构入下:
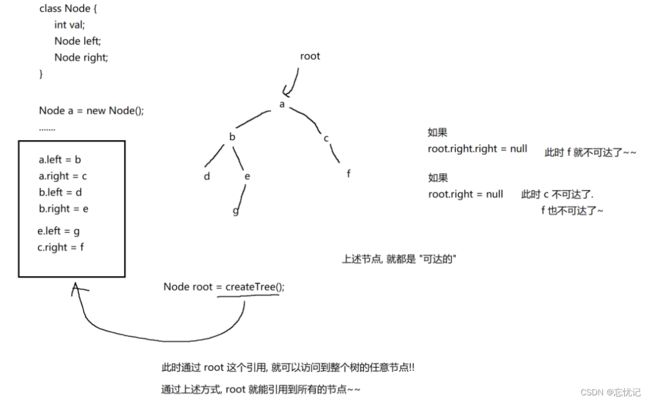
可达性分析,总的来说,就是从所有的gcroots 的起点出发,看看该对象里又通过引用能访问哪些对象.顺藤摸瓜的,把所有可以访问的对象都给遍历一遍.(遍历的同时把对象标记成“可达" )剩下的自然就是"不可达".
当然,知道具体怎么回事之后,我们还是来总结一下:
可达性分析,克服了引用计数的两个缺点,但是也有自己的问题:
1.消耗更多的时间,因此某个对象成了垃圾,也不一定能第一时间发现,因为扫描的过程,需要消耗时间的
2.在进行可达性分析的时候,要顺藤摸瓜,一旦这个过程中,当前代码中的对象的引用关系发生变化了,就还麻烦了.
因此就是这样的机制,我们在执行这种算法机制去发现垃圾的时候,为了更准确的完成这个"摸瓜"的过程,需要让其他的业务线程暂停工作!!! 但是又会引发一个新的问题就是STW问题.
这里的STW问题,就不做过多赘述了,大家有兴趣的可以去了解一下.
6.2 释放内存的方法(垃圾回收算法)
标记-清除算法
"标记-清除"算法是最基础的收集算法。算法分为"标记"和"清除"两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象.
具体的过程如下:

具体的缺点如下:
"标记-清除"算法的不足主要有两个 :
- 效率问题 : 标记和清除这两个过程的效率都不高
- 空间问题 : 标记清除后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够连续内存而不得不提前触发另一次垃圾收集。
复制算法
具体的过程如下:
复制算法是将内存分为大小相同的两块区域,每次只使用其中的一块区域,这样在进行垃圾回收时就可以直接将存活的东西复制到新的内存上,然后再把另一块内存全部清理掉。

复制算法,解决了内存碎片问题,也有缺点!!
1.内存利用率比较低!!
2.如果当前的对象大部分都是要保留的,垃圾很少,此时复制成本就比较高.
标记-整理算法
标记过程仍与"标记-清除"过程一致,但后续步
骤不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉端边界以外的内存。具体流程如下:

标记-整理算法解决的问题如下:
1.解决内存碎片问题
⒉搬运开销也还是比较大的
分代算法
分代算法和上面讲的3种算法不同,分代算法是通过区域划分,实现不同区域和不同的垃圾回收策略,从而实现更好的垃圾回收。这就好比中国的一国两制方针一样,对于不同的情况和地域设置更符合当地的规则,从而实现更好的管理,这就时分代算法的设计思想。
这里最重要的一个点就是哪些对象会进入新生代?哪些对象会进入老年代.
我还是举一个例子,来构建这个流程.流程图入下:
