Linux系统编程:文件系统和inode
目录
一. 磁盘的结构和读写数据的方式
1.1 磁盘级文件和内存级文件
1.2 磁盘的物理结构
1.3 访问磁盘数据的方式
二. 磁盘文件系统
2.1 磁盘的分区管理方法
2.2 文件名和inode的关系
三. 结合文件系统对文件创建和删除的相关问题的理解
3.1 文件创建时操作系统进行的工作
3.2 文件删除时操作系统进行的工作
3.3 查看文件时操作系统进行的工作
3.4 已删除文件的恢复问题
四. 总结
一. 磁盘的结构和读写数据的方式
1.1 磁盘级文件和内存级文件
- 内存级文件:被某个进程打开的文件,文件的内容被加载到了内存。
- 磁盘级文件:没有被进程打开的文件,存储在磁盘。
如果设备断电,内存中的数据会丢失,但是磁盘上存储的数据依旧会被保存下来。也就是说,磁盘是一种永久性的存储介质,永久性的存储介质还有:SSD、光盘、磁带等。
磁盘,是计算机系统中唯一的机械设备。
现代笔记本电脑和很多台式机,都采用SSD来替代机械硬盘。SSD,就是我们常说的固态硬盘,它以固态电子芯片作为存储介质,相对于磁盘,SSD的读写速度更快,成本也较高。大型互联网公司的服务器,一般还是使用磁盘来存储数据。
1.2 磁盘的物理结构
一个磁盘的主要结构包括:磁盘盘片、磁头、音圈马达、主轴等。磁盘盘片用于存储数据,磁头用于从磁盘中读取数据和向磁盘中写数据。
计算机只认识二进制数据,也就是0/1,因此,只要能在磁盘盘片上读写0/1信号即可。磁盘盘片上涂有磁性物质,通过磁头放电,改变磁盘上磁性物质的正负极,从而实现数据的读写。通过磁盘上的正负极信号,来记录二进制数据,从而实现对数据的永久性存储。
 图1.1 磁盘的物理结构
图1.1 磁盘的物理结构
磁盘盘片,根据区域划分原则,可分为如下几块区域:
- 磁道:在一个磁盘盘片上,距离中心轴半径相同的环形面。
- 扇区:一个磁道中的一段扇形区域,每块扇区所对应的圆周角大小相同。
- 柱面:所有磁盘盘片上,以主轴为中心轴,半径相同的圆柱面。(一个磁盘并非只有一个盘片,而是由许多盘片摞起来的)
一个扇区,为一个数据存储的单元。一般一个扇区可以存储512bytes的数据,也有些磁盘一个扇区存储4KB的数据,现在的技术也支持了不同扇区的容量有所不同。
1.3 访问磁盘数据的方式
如果我们想要访问某个特定的数据,要依次进行如下的工作,找到数据存储的位置:
- 确定数据存储在哪个磁盘盘面(确定对应磁头)-- Head
- 确定位于那个磁道(柱面)-- Cylinder
- 确定位于哪个扇区 -- Sector
上述寻址方法,被称为CHS寻址法, 有了CHS,我们就能够访问到任意扇区的数据。
我们可以通过磁带结构,来抽象类比磁盘。如图1.3所示,磁带被环形缠绕在一个柱面上,每层磁带叠加起来,就好比磁盘的盘片结构,磁带上也存在正负极来记录二进制信号。磁带可以展开为线性结构,这个线性结构就类似于数组,而我们可以想象将磁盘当做磁带展开,这样盘形结构就变为了数组似的线性结构。每个数组下标位置,就相当于一个磁盘上的扇区,根据下标就可以转换获取对应的盘面、磁道和扇区。
假设存储空间为1T的磁盘,那么我们就可以假想整个磁盘的存储空间就是一个数组,而向磁盘的某个扇区写数据,就等同于向这个数组中某个特定下标位置写数据。
 图1.3 磁带
图1.3 磁带
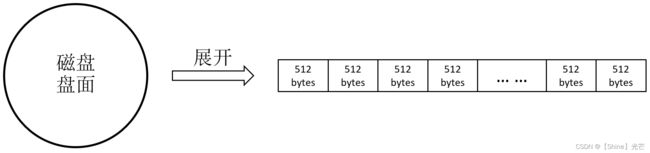 图1.4 磁盘盘面抽象展开图
图1.4 磁盘盘面抽象展开图
二. 磁盘文件系统
2.1 磁盘的分区管理方法
由于一个磁盘的存储空间相对较大,为了便于管理,一般会对磁盘进行分区管理,这就好比我们将电脑的存储空间分为C盘、D盘、E盘。磁盘的存储空间,会被划分为若干个Block Group和一个Boot Block,Boot Block记录整个文件系统相关的属性信息,如果Boot Block中的数据丢失,那么对整个文件系统来说将是灾难性的,因此,在每个block group中,会有一块Super Block,用于备份文件系统的属性信息。当Boot Block中的信息丢失时,OS会去Block Group中寻找备份信息。
每个Block Group又可以根据存储数据的不同,分为这几个区域:Super Block、Group Descriptor Table、Block Bitmap、inode Bitmap、inode Table、Data Blocks。在这些分区里,存储了文件的数据和属性,以及块组和文件系统相关的属性信息。
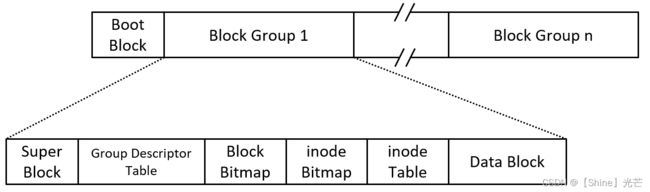 图2.1 磁盘分区图
图2.1 磁盘分区图
每块Block Group(块组)内部分区存储的内容为:
- Data Block:数据块,存储文件的正文内容,一般来说,每个块组的容量为4KB。
- inode Table:inode表,每个文件会分的一块128bytes的inode空间,用于存储文件的属性信息。同时,每个inode都有与之对应的inode编号,对应于某个特定的文件,如果拿到文件的inode编号,就可以找到对应的inode模块,获取文件的属性信息。
- inode Bitmap:与inode Table对应的位图,每个二进制比特位对应一个inode Table的下标位置,0表示该inode Table位置(某个inode编号)没有被使用,1表示被使用了。
- Block Bitmap:与Data Block对应的位图,每个存储文件内容的Data Block如果被使用了,与之对应的Block Bitmap的二进制位就为1,否则为0。
- Group Descriptor Table:块组描述表,记录该Block Group(块组)中,使用了几个inode,还剩几个inode,使用了几个Data Block,还有多少Data Block没有使用等信息。
- Super Block:记录整个文件系统的属性信息,如果Boot Block或某个块组上的Super Block上存储的信息被破坏,那么其他块组中的Super Block就存储了其备份信息,用于OS恢复文件系统属性信息。之所以要在多个块组保存多份文件系统属性信息,是因为如果文件系统属性信息被破坏或丢失,那么整个文件系统就会崩溃。
在磁盘的每个块组上记录上面的这些信息,让每个文件的属性和内容可追溯、可管理。在磁盘中,文件的内容和文件的属性是分开存储的,文件 = 文件内容 + 文件属性。
一个Data Block存储4KB的数据,磁盘和内存进行IO操作的基本单位为4KB,但是,一个扇区一般存储512Bytes的数据,不让一个扇区存储的数据量和磁盘和内存进行IO操作的基本单位保持一致主要出于以下两个方面考虑:(1)如果IO的基本单位太小,那么就会大幅增加IO的次数,降低计算机系统的整体效率。(2)如果让磁盘扇区大小和IO基本单位大小一致,那么如果磁盘扇区大小发生变化,那么就需要更改OS的源代码,不让它们一致,是为了实现硬件层面和软件层面的解耦,软件工程要求高内聚低耦合。
2.2 文件名和inode的关系
存储在特定块组中的每个文件,都会有一个独立的、与之对应的inode编号,通过这个inode编号,可以在inode Table中,查找到特定的下标位置,以获取文件的属性信息。
Linux系统内置的ll、stat等获取文件属性信息的指令,其底层都是通过拿到文件的inode编号,进而在inode Table中获取文件的属性信息来实现的。
那么,文件的内容又是怎样获取的呢,怎样知道某个文件的内容存储在哪个Data Block中呢?
每个Data Block,都有一个特定的编号,每个文件的inode中,会记录有文件对应的Data Block编号, 只需要根据inode中记录的Data Block编号,就可以找到与之对应的Data Block,从而找到文件的内容。如图2.2所示,inode中有一个blocks数组,记录存储这个文件内容的Data Block编号。
获取某个文件的内容的流程为:拿到文件的inode编号 -> 找到与之对应的inode -> 找到inode内部的Blocks数组,获取存储这个文件的内容Data Blocks -> 访问Data Blocks获取文件内容。
那么,如果文件很大,需要庞大数量的Data Blocks才能放下的时候,又该怎么办呢,总不能将这些Data Blocks的编号全都放到inode中的Blocks数组中吧? -- Data Blocks中不仅可以存储文件的具体内容,也可以存储其它的Data Block编号,这个可以根据Data Blocks中记录的其他Data Block编号,找到存储了具体文件内容的Data Blocks。
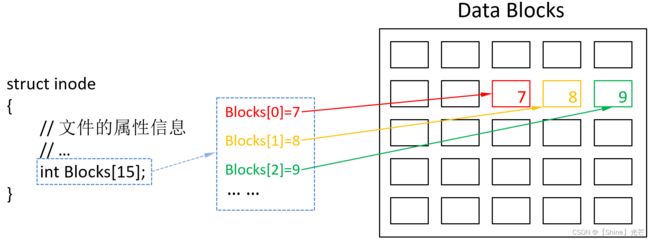 图2.2 通过inode编号获取文件内容
图2.2 通过inode编号获取文件内容
inode中,并不会存储文件的文件名!
提问,如何通过文件名获取文件对应的inode编号呢?目录(文件夹),也属于文件,有与之对应的inode编号和Data Blocks,目录的Data Blocks中存储该目录下文件名和inode编号之间的映射关系,这就解释了为什么同一目录下不允许有同名的文件,因为如果有同名文件,就无法建立文件名与inode编号之间准确的映射关系。
在某一特定磁盘块组Data Group中,inode和Data Block的数量都是固定的。这就解释了为什么有时候明明块组中还有内存空间,但却无法成功创建新文件的现象。这有可能是因为inode Table被用完了,但Data Blocks还没用完,或者Data Blocks被用完了,但是inode Table还没有被用完。
三. 结合文件系统对文件创建和删除的相关问题的理解
3.1 文件创建时操作系统进行的工作
遍历块组的inode Bitmap,查找一个还没有被使用的inode编号,分配给新建的文件 -> 将对应的inode Bitmap的二进制为置为1 -> 向inode中写入文件的属性信息 -> 为文件分配Data Blocks,记入inode中,并将Block Bitmap中与之对应的二进制位置为1 -> 将文件名及其与inode编号之间的映射关系写入到文件所在目录对应的Data Blocks中。
3.2 文件删除时操作系统进行的工作
根据文件名,从文件所在路径的Data Blocks中获取该文件的inode编号 -> 根据inode编号,在inode Tables中,找到与之对应的inode,从inode中获取该文件占用的Data Blocks编号 -> 将inode Bitmap和Blocks Bitmap中对应的二进制位置0 -> 在文件所在的目录的Data Blocks中,解除文件名和inode编号的映射关系。
注意:删除文件不需要清除Data Blocks中的文件内容,只要改变位图标记、解除文件名和inode编号之间的映射关系即可。因此,删除一个大文件所耗费的时间远低于拷贝一个大文件的时间。
3.3 查看文件时操作系统进行的工作
根据文件名拿到与之对应的inode编号 -> 通过inode编号找到该文件的inode -> 从inode中获取存储该文件内容的Data Blocks -> 访问指定的Data Blocks,查看文件内容。
3.4 已删除文件的恢复问题
当用户删除一个文件时,OS会有记录相应的删除日志,日志中会包含文件的inode编号。由于删除文件并不会删除掉inode Tables和Data Blocks中的内容,因此,可以通过已删除文件的inode编号,获取存储文件内容的Data Blocks,这样就可以实现对删除文件的恢复。
但是,恢复删除文件有一个必要的前提:原来文件所使用的inode Tables和Data Blocks均没有被覆盖。如果被覆盖,那么文件就无法恢复,写文件、新建文件等各种操作,都有可能造成被删除文件的inode Tables和Data Blocks被覆盖,因此,如果误删了重要文件,在文件恢复之前,什么都不应该做!
四. 总结
-
文件根据是否被进程打开,分为内存级文件和磁盘级文件。
-
磁盘的主要结构有:盘片、磁头、主轴、音圈马达等。数据存储在磁盘盘片上,磁盘盘片被划分为一个个的磁道和扇区,一个扇区为一个磁盘存储单元。磁盘盘片上涂有磁性物质,磁性物质的正负极,代表二进制数据的0和1,磁头负责在磁盘盘片上读取数据和向磁盘写数据。
-
通过CHS法,找到数据在磁盘中的盘片、磁道和扇区,就可以获取对应的数据。
-
磁盘中是被分为若干个块组进行分区管理的,每个块组存储有文件的属性信息和文件的内容,文件的属性信息和内容是分开存储的,每个文件占用一个inode来存储属性信息,占用若干个Data Blocks存储文件内容。
-
目录也是文件,与它自己的inode和Data Blocks,目录的Data Blocks中存有该目录下文件的文件名和与之对应的inode编号。