手搓GPT系列之 - 通过理解LSTM的反向传播过程,理解LSTM解决梯度消失的原理 - 逐条解释LSTM创始论文全部推导公式,配超多图帮助理解(中篇)
近期因俗事缠身,《通过理解LSTM的反向传播过程,理解LSTM解决梯度消失的原理 - 逐条解释LSTM创始论文全部推导公式,配超多图帮助理解》的中下篇鸽了实在太久有些不好意思了。为了避免烂尾,还是抽时间补上(上篇在此)。本文承接上篇,继续就Sepp Hochreiter 1997年的开山大作 Long Short-term Memory 中APPENDIX A.1和A.2所载的数学推导过程进行详细解读。希望可以帮助大家理解了这个推导过程,进而能顺利理解为什么那几个门的设置可以解决RNN里的梯度消失和梯度爆炸的问题。一家之言,若有任何错漏欢迎大家评论区指正。好了,Dig in!
上篇文章最后讲到了LSTM中记忆单元的激活状态关于各权重值的求偏导公式(公式15)。这里我们将从公式16开始。
5. 后向传播过程
前面介绍了那么多截断求导,后向传播过程将应用这些经过截断处理的求导公式来计算每个权重的误差值。
5.1 总误差
总误差是指输出单元在第 t t t时刻的输出值与目标值之间的方差。我们设 t t t时刻目标值为 t k ( t ) t^k(t) tk(t)。则有:
E ( t ) = ∑ k : k o u t p u t u n i t ( t k ( t ) − y k ( t ) ) 2 , (16) E(t) = \sum_{k:\ k\ output\ unit} (t^k(t) - y^k(t))^2 \tag{16}, E(t)=k: k output unit∑(tk(t)−yk(t))2,(16)
其中 y k ( t ) y^k(t) yk(t)是输出单元在 t t t时刻的激活值(参考公式6)。
在 t t t时刻,各权重值的梯度(记为 Δ w l m ( t ) \Delta w_{lm}(t) Δwlm(t))计算公式为:
Δ w l m ( t ) = − α ∂ E ( t ) ∂ w l m . (17) \Delta w_{lm}(t) = - \alpha \frac{\partial E(t)}{\partial w_{lm}} \tag{17}. Δwlm(t)=−α∂wlm∂E(t).(17)
其中 l ∈ { k , c j , i n j , o u t j , i } l \in \{ k, c_{j},in_{j},out_{j}, i\} l∈{k,cj,inj,outj,i},分别代表输出单元 k k k,记忆单元 c j c_{j} cj,输入门 i n j in_{j} inj,输出门 o u t j out_{j} outj及隐藏单元 i i i。 α \alpha α为学习率(learning rate),用于控制学习步进,如果学习步进过大,在遇到悬崖时很可能会一下把权重更新太多,跳跃到很远的地方(over shoot),如果学习率太小,影响训练速度。
我们把不同单元和门在 t t t时刻的误差公式定义为:
e l ( t ) : = − ∂ E ( t ) ∂ n e t l ( t ) . (18) e_l(t) := - \frac{\partial E(t)}{\partial net_l(t)}\tag{18}. el(t):=−∂netl(t)∂E(t).(18)
5.2 输出单元误差计算
令 l = k l=k l=k,我们通过式18可以得到输出单元在 t t t时刻的误差:
e k ( t ) = − ∂ E ( t ) ∂ n e t k ( t ) = − ∂ E ( t ) ∂ y k ∗ ∂ y k ∂ n e t k ( t ) = − f ′ ( n e t k ( t ) ) ∗ 2 ( t k ( t ) − y k ( t ) ) ∗ ( − 1 ) = 2 f ′ ( n e t k ( t ) ) ( t k ( t ) − y k ( t ) ) \begin{aligned} e_k(t) &= - \frac{\partial E(t)}{\partial net_k(t)}\\ &= - \frac{\partial E(t)}{\partial y^k} * \frac{\partial y^k}{\partial net_k(t)}\\ &= - f'(net_k(t))*2(t^k(t) - y^k(t))*(-1 )\\ &= 2f'(net_k(t))(t^k(t) - y^k(t)) \end{aligned} ek(t)=−∂netk(t)∂E(t)=−∂yk∂E(t)∗∂netk(t)∂yk=−f′(netk(t))∗2(tk(t)−yk(t))∗(−1)=2f′(netk(t))(tk(t)−yk(t))
我们把上边这个式子前面前边的常数 2 2 2让 α \alpha α吸收掉,就可以得到式19:
e k ( t ) = f ′ ( n e t k ( t ) ) ( t k ( t ) − y k ( t ) ) (19) e_k(t) = f'(net_k(t))(t^k(t) - y^k(t))\tag{19} ek(t)=f′(netk(t))(tk(t)−yk(t))(19)
下图为输出单元的梯度传播示意图:
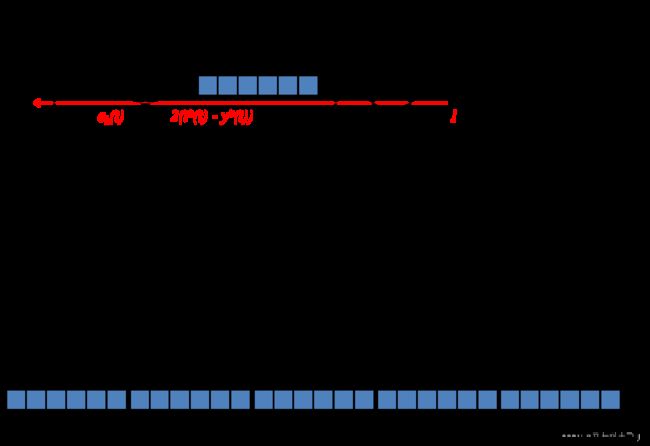
5.3 隐藏单元误差计算
令 l = i l=i l=i,我们可以得到隐藏单元在 t t t时刻的误差:
e i ( t ) = − ∂ E ( t ) ∂ n e t i ( t ) = f i ′ ( n e t i ( t ) ) ∑ k : k o u t p u t u n i t w k i e k ( t ) (20) \begin{aligned} e_i(t) &= - \frac{\partial E(t)}{\partial net_i(t)}\\ &= f_i'(net_i(t))\sum_{k:\ k\ output\ unit}w_{ki}e_k(t)\tag{20}\\ \end{aligned} ei(t)=−∂neti(t)∂E(t)=fi′(neti(t))k: k output unit∑wkiek(t)(20)
下图显示了隐藏单元的梯度传播路线:
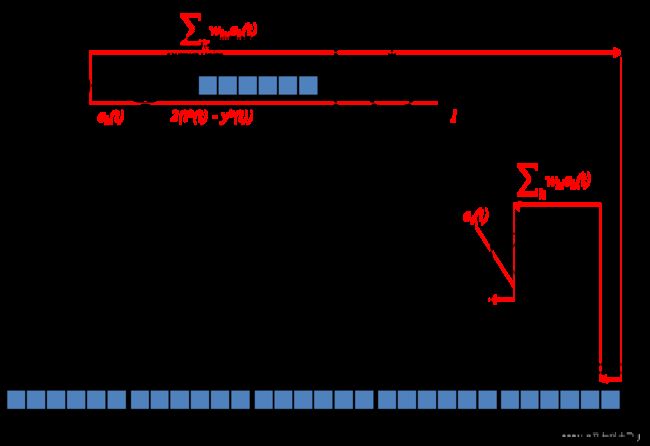
式20的第一个因子很好理解,就是隐藏单元的激活函数的求导。第二个因子会有点难以理解。
∑ k : k o u t p u t u n i t w k i e k ( t ) = ∂ E ( t ) ∂ y i \sum_{k:\ k\ output\ unit}w_{ki}e_k(t) = \frac{\partial E(t)}{\partial y^i} k: k output unit∑wkiek(t)=∂yi∂E(t)
我们只需要画个神经网络的图就很好理解了:
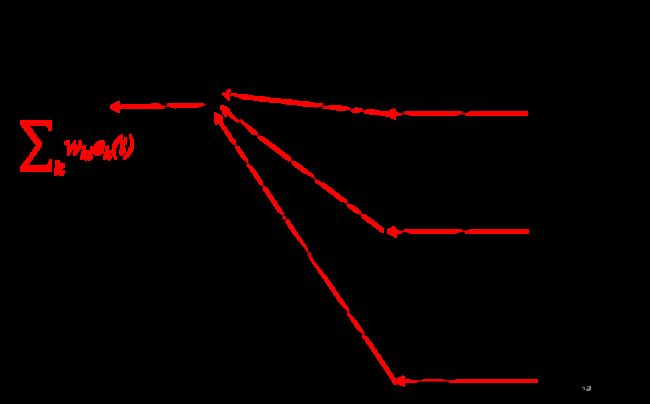
根据后向传播的规则,对于一个数据节点,如果同时作为多个操作节点的输入,那么其梯度值为所有上游梯度值之和。
5.4 输出门误差计算
令 l = o u t j l=out_j l=outj,可得:
e o u t j ( t ) = − ∂ E ( t ) ∂ n e t o u t j ( t ) = f o u t j ′ ( n e t o u t j ( t ) ) ( ∑ v = 1 s j h ( s c j v ) ∑ k : k o u t p u t u n i t w k c j v e k ( t ) ) . (21) \begin{aligned} e_{out_j}(t) &= - \frac{\partial E(t)}{\partial net_{out_j}(t)}\\ &= f_{out_j}'(net_{out_j}(t))(\sum_{v=1}^{s_j} h(s_{c_j^v})\sum_{k:\ k\ output\ unit}w_{kc_j^v}e_k(t))\tag{21}.\\ \end{aligned} eoutj(t)=−∂netoutj(t)∂E(t)=foutj′(netoutj(t))(v=1∑sjh(scjv)k: k output unit∑wkcjvek(t)).(21)
上边这个式子是针对有多个记忆块(memory block),每个记忆块 b l o c k v block_v blockv都与其前边的所有记忆块 b l o c k x , x < v block_x,x
e o u t j ( t ) = − ∂ E ( t ) ∂ n e t o u t j ( t ) = f o u t j ′ ( n e t o u t j ( t ) ) h ( s c j ( t ) ) ∑ k : k o u t p u t u n i t w k c j e k ( t ) . \begin{aligned} e_{out_j}(t) &= - \frac{\partial E(t)}{\partial net_{out_j}(t)}\\ &= f_{out_j}'(net_{out_j}(t))h(s_{c_j}(t))\sum_{k:\ k\ output\ unit}w_{kc_j}e_k(t).\\ \end{aligned} eoutj(t)=−∂netoutj(t)∂E(t)=foutj′(netoutj(t))h(scj(t))k: k output unit∑wkcjek(t).
这个公式有三个因子:
- f o u t j ′ ( n e t o u t j ( t ) ) f_{out_j}'(net_{out_j}(t)) foutj′(netoutj(t)):这是输出门的激活函数的求导,
- h ( s c j ( t ) ) h(s_{c_j}(t)) h(scj(t)):根据向量相乘的求导公式, ∂ y c j ∂ y o u t j = h ( s c j ( t ) ) \frac{\partial y^{c_j}}{\partial y^{out_j}} = h(s_{c_j}(t)) ∂youtj∂ycj=h(scj(t)),
- ∑ k : k o u t p u t u n i t w k c j e k ( t ) \sum_{k:\ k\ output\ unit}w_{kc_j}e_k(t) ∑k: k output unitwkcjek(t):可参考式20的解释。
我们同样可以通过梯度传播图来理解这个公式:

对于任何单元或门 l l l,在时间点 t t t,对权重 w l m w_{lm} wlm的贡献值为:
Δ w l m ( t ) = α e l ( t ) y m ( t − 1 ) . (22) \Delta w_{lm}(t) = \alpha e_l(t)y^m(t-1).\tag{22} Δwlm(t)=αel(t)ym(t−1).(22)
式22的推导过程为:
Δ w l m ( t ) = − α ∂ E ( t ) ∂ w l m ( 式 17 ) = α ( − ∂ E ( t ) ∂ n e t l ( t ) ) ∂ n e t l ( t ) ∂ w l m ( 应用链式规则求导 ) = α e l ( t ) ∂ n e t l ( t ) ∂ w l m ( 代入式 18 ) = α e l ( t ) y m ( t − 1 ) \begin{aligned} \Delta w_{lm}(t) &= - \alpha \frac{\partial E(t)}{\partial w_{lm}}&(式17)\\ & = \alpha(- \frac{\partial E(t)}{\partial net_l(t)}) \frac{\partial net_l(t)}{\partial w_{lm}}&(应用链式规则求导)\\ & = \alpha e_{l}(t) \frac{\partial net_l(t)}{\partial w_{lm}} &(代入式18)\\ &= \alpha e_l(t)y^m(t-1) \end{aligned} Δwlm(t)=−α∂wlm∂E(t)=α(−∂netl(t)∂E(t))∂wlm∂netl(t)=αel(t)∂wlm∂netl(t)=αel(t)ym(t−1)(式17)(应用链式规则求导)(代入式18)
我们可以把前文中得到的 e i ( t ) , e o u t j ( t ) , e k ( t ) e_i(t),e_{out_j}(t), e_k(t) ei(t),eoutj(t),ek(t)代入上式得到相应的 Δ w l m \Delta w_{lm} Δwlm值。
5.5 输入门的误差计算
由于输入门藏得比较深,因此需要先计算一个中间节点 s c j s_{c_j} scj的误差。
e s c j ( t ) = − ∂ E ( t ) ∂ s c j ( t ) = f o u t j ( n e t o u t j ( t ) ) h ′ ( s c j ( t ) ) ( ∑ k : k o u t p u t u n i t w k c j e k ( t ) ) (23) \begin{aligned} e_{s_{c_j}}(t) &= - \frac{\partial E(t)}{\partial s_{c_{j}}(t)}\\ &= f_{out_j}(net_{out_j}(t))h'(s_{c_{j}}(t)) (\sum_{k:\ k\ output\ unit}w_{kc_j}e_k(t)) \tag{23} \end{aligned} escj(t)=−∂scj(t)∂E(t)=foutj(netoutj(t))h′(scj(t))(k: k output unit∑wkcjek(t))(23)
这个式子有三个因子:
- f o u t j ( n e t o u t j ( t ) ) f_{out_j}(net_{out_j}(t)) foutj(netoutj(t)): ∂ y c j ( t ) ∂ h ( s c j ( t ) ) = f o u t j ( n e t o u t j ( t ) ) \frac{\partial y^{c_j}(t)}{\partial h(s_{c_{j}}(t))} = f_{out_j}(net_{out_j}(t)) ∂h(scj(t))∂ycj(t)=foutj(netoutj(t)),
- h ′ ( s c j ( t ) ) h'(s_{c_{j}}(t)) h′(scj(t)): s c j ( t ) s_{c_j}(t) scj(t)后的激活函数 h h h的求导。
- ∑ k : k o u t p u t u n i t w k c j e k ( t ) \sum_{k:\ k\ output\ unit}w_{kc_j}e_k(t) ∑k: k output unitwkcjek(t):同公式21的解释。
我们令 l = i n j l=in_j l=inj 或者 l = c j v l=c_j^v l=cjv,计算:
− ∂ E ( t ) ∂ w l m = ∑ v = 1 s j e s c j v ( t ) ∂ s c j v ( t ) ∂ w l m . (24) -\frac{\partial E(t)}{\partial w_{lm}} = \sum_{v=1}^{s_j}e_{s_{c_j}^v}(t) \frac{\partial s_{c_j}^v(t)}{\partial w_{lm}}\tag{24}. −∂wlm∂E(t)=v=1∑sjescjv(t)∂wlm∂scjv(t).(24)
同样,式24采用了多记忆块模型,我们为了便于理解先简化为单记忆块模型,上式可以简化为:
− ∂ E ( t ) ∂ w l m = e s c j ( t ) ∂ s c j ( t ) ∂ w l m . -\frac{\partial E(t)}{\partial w_{lm}} = e_{s_{c_j}}(t) \frac{\partial s_{c_j}(t)}{\partial w_{lm}}. −∂wlm∂E(t)=escj(t)∂wlm∂scj(t).
令 l = i n j l=in_j l=inj,我们进一步计算上式的第二个因子 ∂ s c j ( t ) ∂ w l m \frac{\partial s_{c_j}(t)}{\partial w_{lm}} ∂wlm∂scj(t):
我们代入 s c j s_{c_j} scj的计算公式:
s c j ( t ) = s c j ( t − 1 ) + g ( n e t c j ( t ) ) f i n j ( n e t i n j ( t ) ) s_{c_j}(t) = s_{c_j}(t-1) + g(net_{c_j}(t)) f_{in_j}(net_{in_j}(t)) scj(t)=scj(t−1)+g(netcj(t))finj(netinj(t))
可得:
∂ s c j ( t ) ∂ w i n j m = ∂ s c j ( t − 1 ) ∂ w i n j m + g ( n e t c j ( t ) ) f i n j ′ ( n e t i n j ( t ) ) y m ( t − 1 ) (25) \frac{\partial s_{c_j}(t)}{\partial w_{in_j m}} = \frac{\partial s_{c_j}(t-1)}{\partial w_{in_j m}}+ g(net_{c_j}(t))f_{in_j}'(net_{in_j}(t))y^m(t-1)\tag{25} ∂winjm∂scj(t)=∂winjm∂scj(t−1)+g(netcj(t))finj′(netinj(t))ym(t−1)(25)
题目都做到这里了,估计大家都可以理解上边这个式子怎么得到的吧。
到此我们可得在时间 t t t, w i n j m w_{in_j m} winjm的误差更新值为:
Δ w i n j m ( t ) = α ∑ v = 1 s j e s c j ( t ) ∂ s c j ( t ) ∂ w i n j m . (26) \Delta w_{in_j m}(t) = \alpha \sum_{v=1}^{s_j} e_{s_{c_j}}(t) \frac{\partial s_{c_j}(t)}{\partial w_{in_j m}}\tag{26}. Δwinjm(t)=αv=1∑sjescj(t)∂winjm∂scj(t).(26)
下图显示了输入门的误差传播路径:
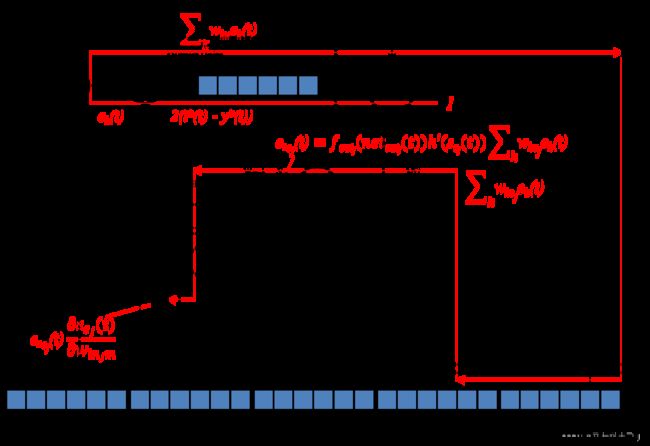
5.5 记忆单元的误差计算
令 l = c j l=c_j l=cj,为了计算记忆单元的误差公式,我们先计算 ∂ s c j ( t ) ∂ w c j m \frac{\partial s_{c_j}(t)}{\partial w_{c_j} m} ∂wcjm∂scj(t):
代入 s c j s_{c_j} scj的计算公式:
s c j ( t ) = s c j ( t − 1 ) + g ( n e t c j ( t ) ) f i n j ( n e t i n j ( t ) ) s_{c_j}(t) = s_{c_j}(t-1) + g(net_{c_j}(t)) f_{in_j}(net_{in_j}(t)) scj(t)=scj(t−1)+g(netcj(t))finj(netinj(t))
可得:
∂ s c j ( t ) ∂ w c j m = ∂ s c j ( t − 1 ) ∂ w c j m + g ′ ( n e t c j ( t ) ) ( f i n j ( n e t i n j ( t ) ) ) y m ( t − 1 ) . (27) \frac{\partial s_{c_j}(t)}{\partial w_{c_j} m} = \frac{\partial s_{c_j}(t-1)}{\partial w_{c_j m}} + g'(net_{c_j}(t))(f_{in_j}(net_{in_j}(t)))y^m(t-1)\tag{27}. ∂wcjm∂scj(t)=∂wcjm∂scj(t−1)+g′(netcj(t))(finj(netinj(t)))ym(t−1).(27)
上式的理解类似于式25。
因此记忆单元的权重 w c j m w_{c_j m} wcjm在 t t t时刻的更新值为:
Δ w c j m ( t ) = α e s c j ( t ) ∂ s c j ( t ) ∂ w c j m . (28) \Delta w_{c_j m} (t)=\alpha e_{s_{c_j}}(t) \frac{\partial s_{c_j}(t)}{\partial w_{c_j} m}\tag{28}. Δwcjm(t)=αescj(t)∂wcjm∂scj(t).(28)
误差值传播路径图:

5.6 权重更新算法的时间复杂度
令 K K K为输出向量的长度, C C C为记忆单元块的个数(在我们简化的单记忆块的版本中,该值为1), S S S为每个记忆块中记忆单元的个数, H H H为隐藏单元的向量长度, I I I为与记忆单元、门、和隐藏单元互相连接的向量度。
这个 I I I指的就是向量 y u y^u yu的长度,如下图所示:

所有权重数据的个数为 W W W:
W = K H + K C S + C S I + 2 C I + H I . W = KH + KCS +CSI + 2CI + HI. W=KH+KCS+CSI+2CI+HI.
其中:
- K H + K C S KH + KCS KH+KCS 为 w k w_k wk的权重个数。
- C S I CSI CSI: w c j w_{c_j} wcj的权重个数。
- 2 C I 2CI 2CI: w i n j , w o u t j w_{in_j},w_{out_j} winj,woutj的权重个数之和。
- H I HI HI: w i w_i wi的权重个数。
更新所有权重需要 K H + K C S + C S I + 2 C I + H I KH + KCS + CSI + 2CI + HI KH+KCS+CSI+2CI+HI步操作, O ( W ) = O ( K H + K C S + C S I + H I ) O(W) = O(KH+KCS+CSI + HI) O(W)=O(KH+KCS+CSI+HI)
在程序开发过程中,我们只需要实现等式(19),(20),(21),(22),(23),(25),(26),(27),(28)。因此我们只需要逐步计算每个等式的时间复杂度即可算出整个算法的时间复杂度。
- 式19: e k ( t ) = f ′ ( n e t k ( t ) ) ( t k ( t ) − y k ( t ) ) e_k(t) = f'(net_k(t))(t^k(t) - y^k(t)) ek(t)=f′(netk(t))(tk(t)−yk(t)),需要 K K K步计算,
- 式20: e i ( t ) = f i ′ ( n e t i ( t ) ) ∑ k : k o u t p u t u n i t w k i e k ( t ) e_i(t) = f_i'(net_i(t))\sum_{k:\ k\ output\ unit}w_{ki}e_k(t) ei(t)=fi′(neti(t))∑k: k output unitwkiek(t),需要 K H KH KH步计算,
- 式21: e o u t j ( t ) = f o u t j ′ ( n e t o u t j ( t ) ) ( ∑ v = 1 s j h ( s c j v ) ∑ k : k o u t p u t u n i t w k c j v e k ( t ) ) e_{out_j}(t) = f_{out_j}'(net_{out_j}(t))(\sum_{v=1}^{s_j} h(s_{c_j^v})\sum_{k:\ k\ output\ unit}w_{kc_j^v}e_k(t)) eoutj(t)=foutj′(netoutj(t))(∑v=1sjh(scjv)∑k: k output unitwkcjvek(t)),需要 K C S KCS KCS步计算,
- 式22: Δ w l m ( t ) = α e l ( t ) y m ( t − 1 ) \Delta w_{lm}(t) = \alpha e_l(t)y^m(t-1) Δwlm(t)=αel(t)ym(t−1),当 l = k l=k l=k时需要 K ( H + C ) K(H+C) K(H+C)步计算,当 l = i l=i l=i时需要 H I HI HI步计算,当 l = o u t j l=out_j l=outj时需要 C I CI CI步计算,
- 式23: e s c j ( t ) = f o u t j ( n e t o u t j ( t ) ) h ′ ( s c j ( t ) ) ( ∑ k : k o u t p u t u n i t w k c j e k ( t ) ) e_{s_{c_j}}(t) = f_{out_j}(net_{out_j}(t))h'(s_{c_{j}}(t)) (\sum_{k:\ k\ output\ unit}w_{kc_j}e_k(t)) escj(t)=foutj(netoutj(t))h′(scj(t))(∑k: k output unitwkcjek(t)),需要 K C S KCS KCS步计算,
- 式25: ∂ s c j ( t ) ∂ w i n j m = ∂ s c j ( t − 1 ) ∂ w i n j m + g ( n e t c j ( t ) ) f i n j ′ ( n e t i n j ( t ) ) y m ( t − 1 ) \frac{\partial s_{c_j}(t)}{\partial w_{in_j m}} = \frac{\partial s_{c_j}(t-1)}{\partial w_{in_j m}}+ g(net_{c_j}(t))f_{in_j}'(net_{in_j}(t))y^m(t-1) ∂winjm∂scj(t)=∂winjm∂scj(t−1)+g(netcj(t))finj′(netinj(t))ym(t−1),需要 C S I CSI CSI步计算,
- 式26: Δ w i n j m ( t ) = α ∑ v = 1 s j e s c j ( t ) ∂ s c j ( t ) ∂ w i n j m \Delta w_{in_j m}(t) = \alpha \sum_{v=1}^{s_j} e_{s_{c_j}}(t) \frac{\partial s_{c_j}(t)}{\partial w_{in_j m}} Δwinjm(t)=α∑v=1sjescj(t)∂winjm∂scj(t),需要 C S I CSI CSI步计算,
- 式27: ∂ s c j ( t ) ∂ w c j m = ∂ s c j ( t − 1 ) ∂ w c j m + g ′ ( n e t c j ( t ) ) ( f i n j ( n e t i n j ( t ) ) ) y m ( t − 1 ) \frac{\partial s_{c_j}(t)}{\partial w_{c_j} m} = \frac{\partial s_{c_j}(t-1)}{\partial w_{c_j m}} + g'(net_{c_j}(t))(f_{in_j}(net_{in_j}(t)))y^m(t-1) ∂wcjm∂scj(t)=∂wcjm∂scj(t−1)+g′(netcj(t))(finj(netinj(t)))ym(t−1),需要 C S I CSI CSI步计算,
- 式28: Δ w c j m ( t ) = α e s c j ( t ) ∂ s c j ( t ) ∂ w c j m \Delta w_{c_j m} (t)=\alpha e_{s_{c_j}}(t) \frac{\partial s_{c_j}(t)}{\partial w_{c_j} m} Δwcjm(t)=αescj(t)∂wcjm∂scj(t),需要 C S I CSI CSI步计算。
把所有步骤加起来就是:
K + K H + K C S + K ( H + C ) + H I + C I + K C S + 4 C S I = K + 2 K H + K C + 2 K C S + H I + C I + 4 C S I = O ( K H + K C S + C S I + H I ) K + KH + KCS + K(H+C) + HI + CI + KCS + 4CSI = K + 2KH + KC + 2KCS + HI +CI + 4CSI = O(KH+KCS+CSI+HI) K+KH+KCS+K(H+C)+HI+CI+KCS+4CSI=K+2KH+KC+2KCS+HI+CI+4CSI=O(KH+KCS+CSI+HI)
因此可以得到LSTM每一时间步的计算时间复杂度为:
O ( K H + K C S + C S I + H I ) = O ( W ) (29) O(KH+KCS+CSI + HI)=O(W)\tag{29} O(KH+KCS+CSI+HI)=O(W)(29)
由于文章太长,我把整个文章分为上中下三篇,在下篇我将给大家介绍在LSTM模型的后向传播过程中,误差信号的缩放情况。
上篇:上篇在此
中篇:中篇在此
下篇:下篇在此