大模型基础之大语言模型的进展
关键字:LLM大语言模型,fine-tuning微调
预训练语言模型的两种范式
1 特征提取器
提取语言的特征和表示,作为下游模型的输入。例如有名的word2vec模型。
use the output of PLMs as the input of downstream model
2 fine-tuning(微调)
既能提取语言的特征,同时又是下游模型,参数随着训练被更新。例如有名的gpt和bert。
GPT
一个强大的生成模型
从左到右自回归学习地去做预训练。
BERT
双向理解文本,加入mask去遮盖一些词,可以理解成完形填空。随机mask一些词,比例是15%,然后在模型最后一层去预测这些被遮盖的词。
BERT高效的预训练任务:Masked的词预测;下一个句子预测。
BERT存在的问题
预训练和微调间存在鸿沟,[mask] token在预训练中很重要,但是在下游任务中不会出现,也就是不会出现在微调阶段。
预训练效率低,只能预测15%的词。
预训练大语言模型的进展(2023)
参考论文:Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
论文链接:https://arxiv.org/pdf/2304.13712.pdf
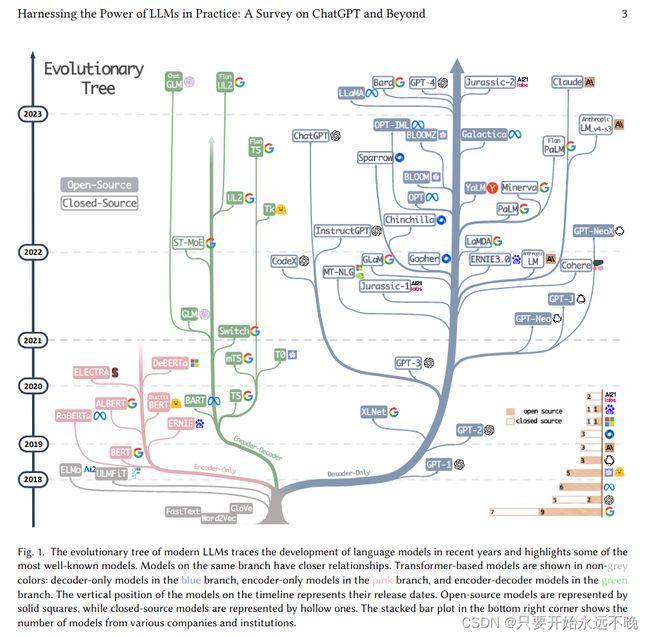
目前大模型进化图如上所示。
什么是大语言模型
LLM是在大量数据集上预先训练的巨大语言模型(模型参数很多),它没有使用数据对特定任务进行微调。
fine-tuned models微调模型通常是较小的语言模型,这些模型也经过预训练,然后在较小的、特定于任务的数据集上进一步调整,以优化它们在该任务上的性能。
从实际的角度来看,我们认为参数小于20B的模型是微调模型。虽然可以微调像PlaM(540B)这样的大型模型,但实际上,这可能非常具有挑战性,特别是对于学术研究实验室和小型团队。对于许多个人或组织来说,使用 3B 参数微调模型仍然是一项艰巨的任务。
大模型分类
如上图所示,大概三种类型:编码器-解码器、仅编码器语言模型、仅解码器语言模型。
仅解码器模型已经逐渐主导了LLM的发展。在LLMs开发的早期阶段,仅解码器模型并不像仅编码器和编码器-解码器模型那样流行。然而,在 2021 年之后,随着改变游戏规则的 LLM - GPT-3 的推出,仅解码器模型经历了显着的繁荣。与此同时,在BERT带来的最初爆炸性增长之后,仅编码器模型逐渐开始消失。
| 类别 | 训练类型 | 模型类型 | 预训练任务 | LLMs |
| Encoder-Decoder or Encoder-only (Bert style) | 掩码语言模型 | 判别式模型 | 预测被mask的单词 | BERT、T5 |
| Decoder-only (GPT style) |
自回归语言模型 | 生成式模型 | 预测下一个单词 | GPT3、GPT4、BLOOM |
BERT风格的语言模型:编码器-解码器或仅编码器
由于自然语言数据很容易获得,并且已经提出了无监督训练范式以更好地利用非常大的数据集,这激发了自然语言的无监督学习。
一种常见的方法是在考虑周围上下文的同时预测句子中的屏蔽单词。
这种训练范式称为掩码语言模型。这种类型的训练使模型能够更深入地理解单词之间的关系以及使用它们的上下文。
这些模型使用Transformer架构等技术在大量文本语料库上进行训练,并在许多NLP任务中取得了最先进的结果,例如情感分析和命名实体识别。掩蔽语言模型的著名例子包括BERT,RoBERTa 和T5 。MLM由于其在广泛的任务中的成功而成为自然语言处理领域的重要工具。
GPT 式语言模型:仅解码器
尽管语言模型在体系结构中通常与任务无关,但这些方法需要对特定下游任务的数据集进行微调。
研究人员发现,扩大语言模型可以显著提高少数样本甚至零样本的表现。游戏规则改变者 GPT-3 首次通过提示和上下文学习展示了合理的少数样本甚至零样本性能,从而展示了自回归语言模型的优越性。
大模型的预训练数据
预训练数据的多样性在塑造模型性能方面也起着至关重要的作用,LLM的选择在很大程度上取决于预训练数据的组成部分。
例如,PaLM 和 BLOOM 擅长多语言任务和机器翻译,具有丰富的多语言预训练数据。此外,PaLM在问答任务中的表现通过结合大量的社交媒体对话和书籍语料库而得到增强。同样,GPT-3.5 (code-davinci-002) 的代码执行和代码完成功能通过在其预训练数据集中集成代码数据来增强。
简而言之,在为下游任务选择 LLM 时,建议选择在类似数据字段上预先训练的模型。
大模型的微调数据
零注释数据:在注释数据不可用的情况下,在零样本设置中使用LLM被证明是最合适的方法。LLM已被证明优于以前的零样本方法。此外,缺少参数更新过程可确保避免灾难性遗忘,因为语言模型参数保持不变。
很少有注释的数据:在这种情况下,将少数样本直接纳入LLM的输入提示中,称为上下文学习,这些示例可以有效地指导LLM推广到任务中。但是,与使用 LLM 相比,由于微调模型的规模较小且过度拟合,性能可能较差。
丰富的注释数据:对于特定任务的大量注释数据可用,可以考虑微调模型和LLM。在大多数情况下,微调模型可以很好地拟合数据。在此方案中,使用微调模型或 LLM 之间的选择是特定于任务的,还取决于许多因素,包括所需的性能、计算资源和部署约束。简要总结:LLM在数据可用性方面更通用,而微调模型可以考虑丰富的注释数据。