如何用python进行数据分析
Python是一个非常强大的数据分析工具,它提供了丰富的库和函数来处理、分析、可视化数据,并在各个领域得到了广泛应用。本文将介绍如何使用Python进行数据分析。以下按照流程简述如下:
- 数据预处理
数据预处理通常是数据分析的第一步,这个过程是为了从原始数据中提取有用的信息以及准备数据用于进一步的分析和建模。其中包括数据清洗、数据整合、数据转换、缺失值填充、异常值处理等。
例如我们可以采用pandas库读取CSV格式的数据集,做一些数据清理操作并查看数据集信息:2
import pandas as pd
# 读取csv文件
data = pd.read_csv("data.csv")
# 去掉重复行
data.drop_duplicates(inplace=True)
# 更改数据类型
data['age'] = data['age'].astype('int')
# 查看数据集信息
print(data.info())1.2.探索性数据分析
探索性数据分析(Exploratory Data Analysis, EDA)是数据分析的一个重要环节,这是为发现数据集中更深层结构与规律,包括数据统计描述、数据可视化等。
例如我们可以绘制年龄和收入之间的散点图以观察相关性:
import matplotlib.pyplot as plt
# 绘制收入和年龄散点图
plt.scatter(data.age, data.income)
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Relationship between Age and Income')
plt.show()- 3.数据建模
根据上述探索性数据分析结果,我们可以为接下来的建模适当调整一些变量,例如数据类型、分箱处理、标准化等。接着,我们可以选择适当的模型进行建模。在机器学习中,存在许多模型可供选择,在这里以线性回归作为例子。
下面是一个使用sklearn库构建一个简单的线性回归模型的示例:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 标准化特征
data['age'] = (data['age'] - data['age'].mean()) / data['age'].std()
# 定义特征和目标列
X = data[['age']]
y = data['income']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
lr = LinearRegression()
# 拟合模型
lr.fit(X_train, y_train)
# 计算测试集均方误差
y_predict = lr.predict(X_test)
mse = mean_squared_error(y_test, y_predict)
print('Mean Squared Error:', mse)- 4模型评估
模型评估是为了评估训练好的模型的性能,通常包括准确率、召回率、f1-score等指标。在这里,我们使用均方误差(Mean Squared Error, MSE)指标评估上述构建的线性回归模型,该指标对于连续值预测是一种常见的衡量指标。
- 5数据可视化
数据可视化是Python数据分析的一个重要方面,可以帮助我们更好地理解数据以及数据之间的关系。Python提供了各种库来做数据可视化,如matplotlib和seaborn。
例如我们可以绘制模型的决策边界,观察模型预测结果:
import numpy as np
import seaborn as sns
# 定义边界起点和终点
x_boundaries = np.array([data['age'].min(), data['age'].max()])
y_boundaries = lr.predict(x_boundaries[:, np.newaxis])
# 绘制收入和年龄散点图
plt.scatter(data.age, data.income)
# 绘制决策边界
sns.lineplot(x_boundaries, y_boundaries, color='red')
plt.xlabel('Age')
plt.ylabel('Income')
plt.title('Relationship between Age and Income')
plt.show()以上就是使用Python进行数据分析的一个基本流程,当然还有很多细节需要注意,比如特征选择、交叉验证、超参数调优等。希望这篇文章能够帮助一些读者更好地开始使用Python进行数据分析,并能够在自己的研究中应用它们。
Python是进行数据分析的常用工具之一,可以利用其强大的数据处理、统计和可视化库来进行数据分析。
以下是进行数据分析的一般步骤:
- 数据获取:获取需要分析的数据集。可以使用 Pandas 库中的函数从 CSV、Excel等文件格式导入数据或者直接从数据库中获取数据。
- 数据清洗:清洗并整理数据,例如删除重复值、处理缺失值、转换数据类型等等操作。这一步可以使用 Pandas 库提供的各种数据清洗方法。
- 数据探索性分析(EDA):通过可视化和统计汇总分析数据的特征、变量关系、数据分布以及异常值等信息。这一步可以使用 Matplotlib、Seaborn 等库将数据可视化呈现, 进行统计描述和数据建模。
- 数据建模:通过机器学习模型对数据进行建模和预测,如线性回归、决策树、随机森林等。这一步可以使用 Scikit-Learn 等机器学习库。
- 结果输出:将分析结果以图表、报告等的形式展现出来,使得业务人员能够容易看懂。
Python有很多数据分析相关的库和工具,例如NumPy、Pandas、Matplotlib、Seaborn、Scikit-Learn等。熟练掌握这些库的使用,就可以轻松地进行数据分析了。
这是我所弄的一些代码运行截图
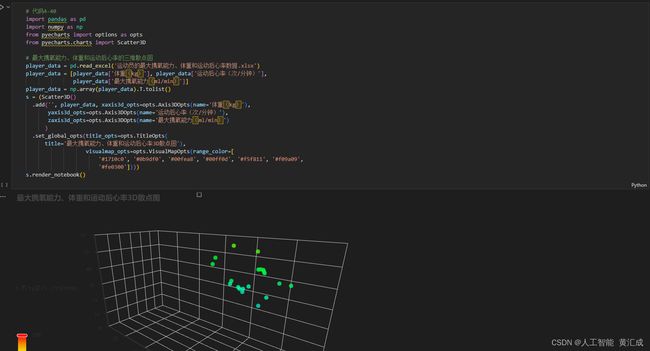

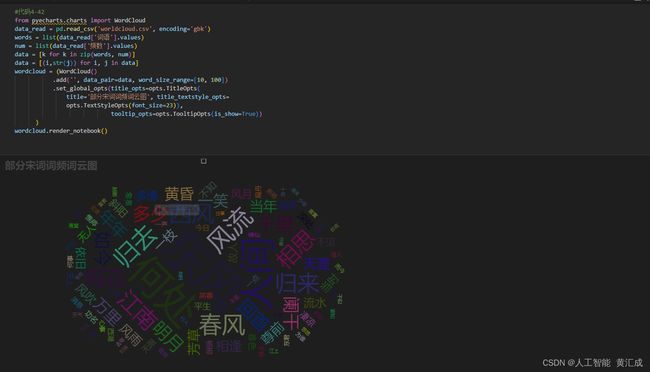
下面也给大家说一下如何便捷领悟python数据分析
Python是一种广泛使用的编程语言,可以用于处理和分析各种类型的数据。Python有着丰富的内置库和第三方库,可以完成各种类型的数据分析任务。下面是掌握python数据分析的建议:
-
学习基础知识:在学习Python数据分析之前,需要先了解Python编程语言基础知识,包括变量、循环、条件语句等基本概念和语法。
-
学习NumPy、Pandas和Matplotlib等库:这些库是Python进行数据分析的核心库。NumPy提供用于数值计算的高效数据处理工具;Pandas提供了强大的数据操作和处理功能,可以轻松读取、清洗和处理数据;Matplotlib则提供了生成图形、绘制曲线等数据可视化工具。通过学习这些库的使用方法,可以快速进行数据处理和分析,并呈现出专业级的数据报告和可视化结果。
-
实践项目:阅读书籍和教程是理论学习,而实践是真正掌握数据分析的关键。可以找到一些相关的数据集,并尝试从中挖掘数据信息。这不仅可以加深理解,还能够锻炼实际应用的技能。
-
推荐一些优秀的学习资源:
(1) 《利用Python进行数据分析》(Python for Data Analysis, 2nd Edition)• Wes McKinney
(2) 《Python数据科学手册》(Python Data Science Handbook)• Jake VanderPlas
(3) Coursera优秀数据科学课程,例如:Michigan大学的Applied Data Science with Python专项课程
在这也说一下python与其他数据分析的区别
Python与其他数据分析工具之间存在一些显著的区别。以下是几个主要的区别点:
-
功能和难度:与传统的基于GUI的软件(如SPSS、SAS等)相比,Python提供了更多的灵活性和自由度,也需要更多的编程学习和实践。但是这种自由度也使得Python可以处理大规模、复杂和不规则的数据。
-
开放性和社区支持:Python是一个开源的编程语言,有着庞大的用户群体和强大的社区支持,这使得人们可以使用各种类型的插件和扩展来进行数据处理和分析。
-
跨平台性:Python是一种具有高度可移植性的编程语言,可以在Windows、MacOS、Linux等多种操作系统上运行。
-
数据库支持:与其他数据分析工具相比,Python提供具有更广泛的数据库支持。除了可以连接关系型数据库(MySQL、PostgreSQL等),还可以连接非关系型数据库(MongoDB等)。
-
学习门槛: Python在学习上相对于其他分析工具,可能需要学习一定的编程基础,例如Python语言本身的语法和一些常见的数据结构。而某些GUI数据分析工具在功能上比较封装,初学者可以直接上手,不需要太强的编程能力。
总的来说,Python作为一种编程语言,可以进行开发和构建各种有用的工具,同时进行数据分析也成为了Python广泛使用的领域之一。与此相比,其他常见的数据分析工具可能会更加专注于某一领域中所需求解问题的功能,掌握python数据分析需要多动手实践,同时在不断的实践、讨论中渐渐提升自己的能力水平。希望这些建议对您有所帮助。