【C++】vector基本用法介绍
vector简单介绍
-
- 前言
- vector原型
- vector常用函数接口介绍
-
- vector的构造、析构、赋值
-
- 构造
- 析构
- =
- 修改类的函数
-
- push_back
- insert
-
- find 函数
- erase
- swap
- 关于容量的函数
-
- max_size
-
- sort
- vector\
- vector\<数据类型\>
- 结束

前言
首先,vector的用法和string是非常相似的,前面已经将string的基本用法讲过了,所以这一篇不会讲那么多,就介绍一下vector的基本用法就可以了。
如果对于string不是很熟悉的话可以看一看我前面这篇:string介绍
还是和前面string一样,讲stl不是为了记住,而是为了让大家学会查文档。
还是那个cplusplus的网站:cplusplus
vector原型
vector就是顺序表,在stl库中用到了类模板,我们先来看一下vector的原型:

上面绿色的部分简单说一下:

上面的类模板第一个数据类型没有缺省值,这也就导致了我们平时如果要用vector的话就必须指定其内部存储的数据类型。也就是顺序表中存放的元素类型是什么。
上面的内存池模板参数是带缺省值的,也就是说我们自己可以实现一个内存池,但是这里没法讲,得到以后了再说。我们平时用的时候就直接用库中那个缺省值的内存池就够了。
vector常用函数接口介绍
vector的构造、析构、赋值
构造
长这样:

里面有些类型我们第一次见的话不认识,没关系,其实不认识的都是typedef的,不是什么新的类型。
文档中也是能查到的:

简单解释几个:
value_type:就将模板参数中的第一个T typedef 为value_type成为vector的成员类型,下面的同理。
allocator_type:就是模板参数中的第二个Alloc,也就是那个内存池。
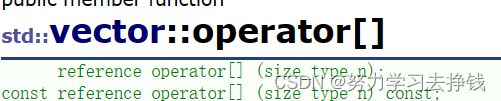
reference:就是T&。引用。
加上const就是const T &比如函数返回值中用到了reference
这个[]就是运算符重载,返回的就是n位置处的引用。
剩下的就不解释了,各位看一看就懂了,不懂的话百度一下。
然后就再继续说构造函数。

其实前面string学好了,这里看起来就很熟悉了。
不过第一个没见过,说一下,就是你可以在定义对象的时候就直接在<>里面传内存池,也可以在构造函数中传内存池。但不常用,就不细说了。
第二个就是开n个空间,并初始化为val。如果val没给值的话,缺省值为value_type(),这就是T(),也就是匿名对象。vector中的数据类型不仅能为int还可以为string、vector(int)等等。而int的匿名对象值为0。

第三个就是迭代器区间初始化。
第四个就是拷贝构造函数。
那么最常用的就是默认无参和拷贝构造,第二个有时候也用。第三个用的就非常少了。
然后上几个例子演示一下:

析构
这个就不讲了,自动调用的东西。
=

这个也没啥好讲的,模拟实现的时候跟构造函数一样要注意深浅拷贝问题就行。
修改类的函数
有尾插尾删,没有头插头删,但是可以用insert和erase来实现。
push_back

上面用到了[ ]操作符。
这里就顺便提一嘴vector遍历的三种方法:
-
下标 + [ ]
就是上面演示的那种。 -
迭代器

vector迭代器的底层还是指针,和string一样。 -
范围for

前面讲string的时候也说了,范围for虽然看起来高大上一点,但是底层就是迭代器。这里也就不过多强调了。
提一嘴,库中的vector没有 << 和 >> 重载,不能直接cout或者cin。
那么pop_back就不演示了,很简单,直接说insert和erase。
insert

用insert和erase先要找到你要插入或删除的位置,这时候叫要用到find函数了。
库中string类提供了find函数,但是vector中并没有提供find,而是用算法库中的find函数,链表list也是。
vector、list等容器是没有提供成员函数find的,因为algorithm(算法)库中提供了一个find函数,可以在某一段迭代器区间内找一个元素,而不像string一样可能找的是一个字符,也可能找的是一个字串,子串的查找是多元素的查找,所以需要string自己提供find函数。
find 函数
库中的find长这样:

在迭代器区间[fist, last)中找val。
注意:在C++中,迭代器区间是左闭右开的[fist, last)。
库中find函数的实现是这样的:

注意到:
当能够找到val时,返回的是val位置的迭代器。
当找不到val时,返回的时last,也就是迭代器区间的末尾位置。
所以说我们在用完find函数并接受了其返回值之后,一定要判断一下返回值是否为end(),如果为end就返回失败了,也就是说没有找到,这时就不能乱用返回的位置了,可能会报错。
那么现在就用find来演示一下insert函数。

尤其注意判断一下。
但是这里不判断的话没事:

而且就算找不到某值,插入不判断也没事,因为会返回end(),end是最后一个有效元素的下一个位置:
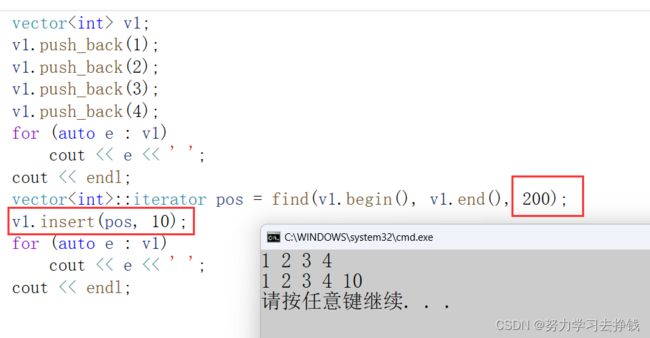
但是这里已经出错了,因为这里的意图是在200前面插入10,但是根本没有200,所以就不插入了:
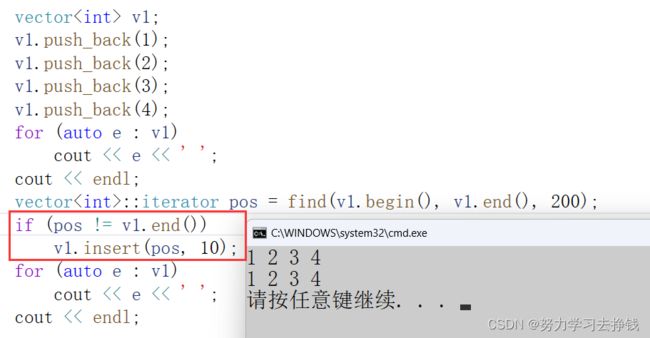
所以还是检查一下最好。
上面insert没有报错不代表都不会报错,下面就来说erase:
erase
长这样:

也是要用到迭代器。
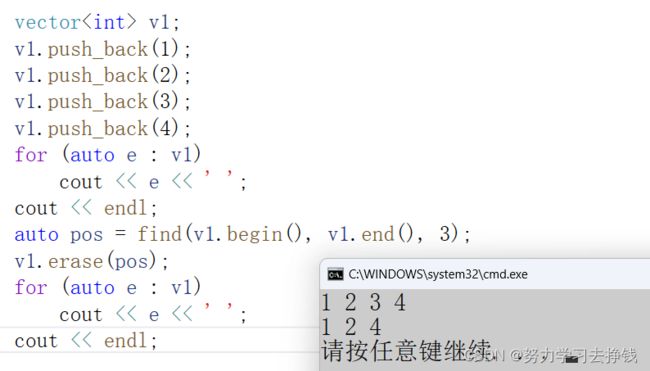
直接给不带判断的例子:
能找到:
找不到:

上面报错报的是删除的迭代器位置超出范围。
所以说find后,要用pos加上判断。

这样就不报错了。
再说一下swap
swap
这个函数是vector库中自己提供的,而我们的算法库中也是有swap的,前面讲string的时候也提到过了。但是算法库中使用swap好多值拷贝,就导致了小号比较大,所以vector为了减少消耗,就提供了自己的swap函数,与库中的原理不同,这个会在模拟实现vector的时候再说。这里只是提一嘴。
关于容量的函数

可以说和string一模一样。
就说一下max_size。
max_size
这个函数返回的是 4G(42亿多字节) 除以 数据类型的大小。
int 为 4字节。
看例子:

除出来就是10亿多。
没什么用,留个印象就行。
剩下的就不说了,和string的一样,前面的博客也都说了。那个shrink_to_fit没说,但是也不常用,就不说了。
下面再说一个算法库中的函数sort
sort
这个函数挺有用的。

也是迭代器区间。
用的算法就是快排。
可以排升序,可以排降序。
默认情况下排升序。
看例子:

然后就是怎么显示排升序和降序。
但是讲之前要先细一下第二个函数模板:
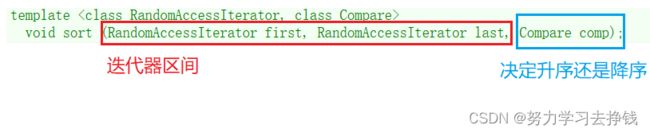
所以说,想要决定升序还是降序的话就要多传一个参数。
这个compare comp是仿函数,现在没法讲,等到讲stack和queue的时候再说。
多的这一个参数库中是有的,两个现成的仿函数,可以直接用。一个叫less,一个叫greater,二者都为类模板,在functional的头文件中。
直接上例子:
排升序用less:

排降序用greater:

但是一般也不这么用。
直接用匿名对象就行:
降序:
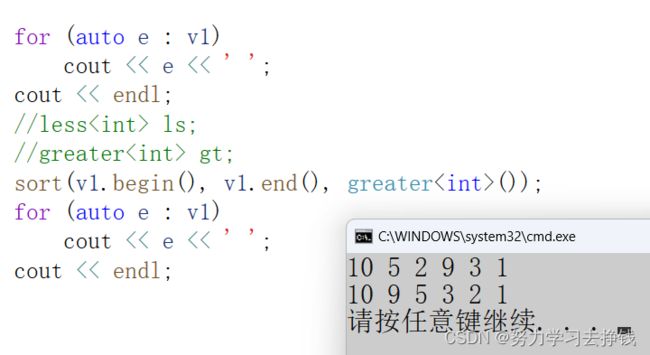
升序:

sort也可用来排string,就是按照ASCII来排。
就不演示了。
vector 和 string的区别
最大的区别就是\0。
string后面是一定有一个\0的,而且有的操作是不一样的,像+=、find、比较大小、to_stirng、<<、>>等等。
所以vector
vector<数据类型>
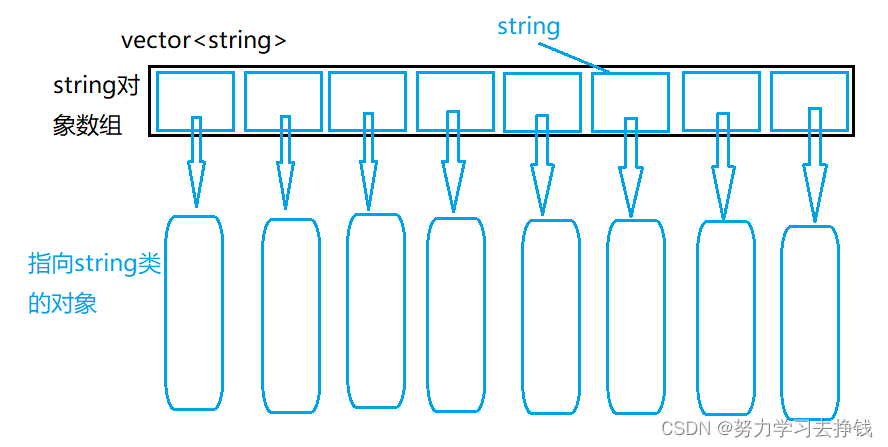
由于vector是类模板,其中的第一个模板参数T可以为很多类型。
可以为string,还可以为vector。
简单给个图解:

讲的话,没啥好讲的,来道例题:
杨辉三角
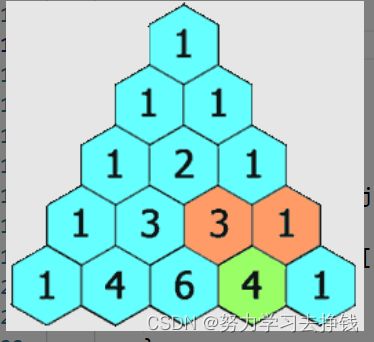
每行的首位元素为1,当前位置的数等于头顶两个数的和。
vector
vector<vector<int>> vv;
使用的时候就直接vv[i][j]就可以。
不用[]的话,应该长这个样子:(vv.operator[i]).operator[j]
就是第i行第j列的元素。
题解给出来:
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> res;
res.resize(numRows);
for(int i = 0; i < res.size(); ++i)
{
res[i].resize(i + 1);
res[i].front() = 1;
res[i].back() = 1;
}
for(int i = 1; i < res.size(); ++i)
{
for(int j = 1; j < res[i].size() - 1; ++j)
{
if(res[i][j] == 0)
{
res[i][j] = res[i - 1][j] + res[i - 1][j - 1];
}
}
}
return res;
}
};