毕业设计So Easy:Java Web图书推荐系统平台
目录
1、系统模块组成
2、模块详细设计
2.1、数据库设计
2.2、页面原型设计
3、环境的搭建
3.1、数据库的建立与数据的导入
3.2、工程建立
3.3、MyBatis配置
4、数据的清洗
5、系统开发
5.1、控制器类
5.2、模块类
5.3、视图类
6、分析及调优
7、性能测试
很多计算机专业大学生经常和我交流:毕业设计没思路、不会做、论文不会写、太难了......
针对这些问题,决定分享一些软、硬件项目的设计思路和实施方法,希望可以帮助大家,也祝愿各位学子,顺利毕业!

项目专栏:7天搞定毕业设计和论文
对计算机技术感兴趣的小伙伴请关注公众号:美男子玩编程,公众号优先推送最新技术博文,创作不易,请各位朋友多多点赞、收藏、关注支持~
本项目是要开发一套轻量级、功能完善的基于Web的图书推荐系统展示平台。利用此平台,对图书信息进行展示与推荐,对用户提供注册与登录功能。由于原始数据为从豆瓣依照网站网页结构抓取得来,并不适用于系统直接读取,于是需要将原始数据表格进行重新设计,遍历分离所需数据存入新设计的表中,使其可以更便捷的查询与处理。开发过程需要考虑Spring MVC框架,将功能按照模块、视图、控制器三部分分离,模块与视图适度的模块化使其可以较好的重用。beans使用注解来注入,这样可以提高小的个人项目的开发效率。在开发开始,配置Maven来解决需要的依赖包,创建Git仓库,来控制版本。
项目资源下载请参见:0TKS7GNY
1、系统模块组成
首先将系统在Spring MVC的基础上分为了三层,分别为:Web层,服务及模块层,数据层,而Web层中,分为Controller与View模块,View为Controller服务,按照预定义的格式来展示Controller的数据。Controller将数据访问与一些公共的逻辑算法交给Model来处理,Model将处理结果交还给Controller。而Model类就像前面Controller给他的任务,负责与界面无关的逻辑计算与数据库的访问、以及其它格式数据的获取。
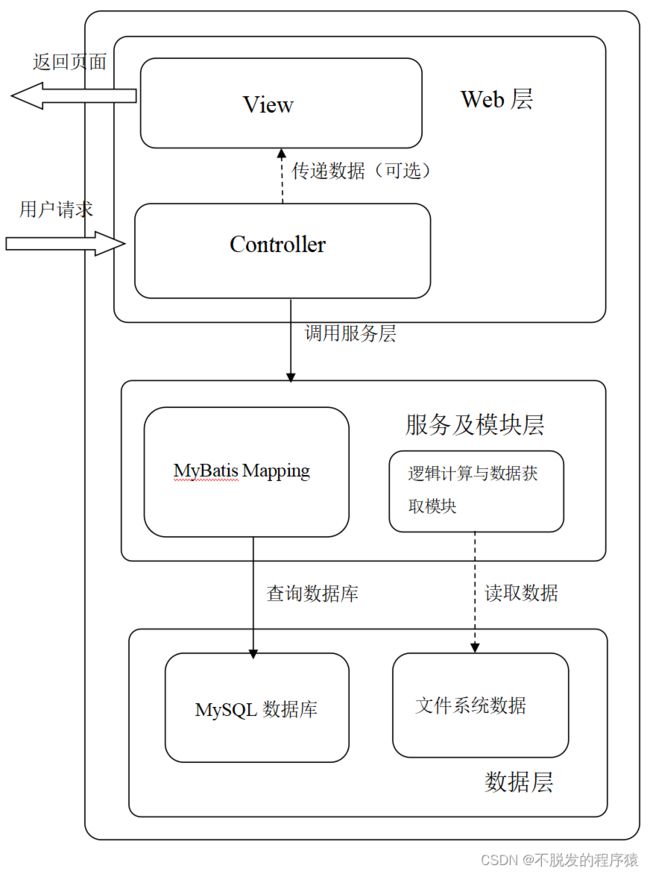
Web层负责处理用户的请求,其中Controller会接收DispatcherServlet分发过来的请求,Controller调用服务与模块层中的模块,进过逻辑计算,生成最终的数据,将数据通过键值对的方式,将视图通过字符串方式传递给DispatcherServlet,DispatcherServlet再读取对应的View,使用View作为模板,生成最终的页面,返回给用户。
服务与模块层负责逻辑计算与数据获取。其中MyBatis Mapping模块为通过MyBatis Generator自动生成的DAO类,以及自定义的DAO类,用于连接MySQL数据库并且执行增删改查操作。而逻辑计算与数据获取模块包含了公共方法类,某些特殊的算法计算,以及对配置文件的查询取值。
最底下的数据层,包括数据库系统与文件系统,是用来存储数据与配置的层。其中数据库采用MySQL数据库,配置文件使用Java自带的.properties文件。
三层之间是互相独立的,只有最近的两层之间可以访问:服务与模块层只可以访问数据层,而Web层只可以调用服务与模块层。其中,服务与模块层中的逻辑计算与数据获取模块,每个模块之间是相互独立的,模块与模块之间不可以互相访问,这样用来降低耦合性,每个模块完成一个完整的任务。由于Web请求的模式决定Web应用只能是被动接收请求,并且Web应用没有涉及费时的网络获取,在代码中没有回调函数,所以层与层之间的调用为单向的,即模块层只可调用数据层,让数据层来执行操作,然后返回数据给模块,Web层调用模块层,将一些逻辑计算与数据获取的过程交给模块来完成,结果返回给Web层,而不可能模块层主动的调用Web层,来对其中的值进行更改,而后返回给用户一个新的页面。在Web层中,View模块只负责对数据进行格式化,生成最终用户页面,因此,它只接收Controller模块的值,而与程序的其它层次模块之间不可以通信。这样,在编写Controller模块时,并不需要了解数据库的组织结构以及配置文件的具体文件名等,只需要知道调用哪个模块,将需要的参数传入模块,模块返回的值就是所需要的数据。而在编写View模块时,也不需要了解其它各个层次都有什么作用,只需要分析页面哪个部分的数据是动态获取的,然后将此部分数据安排给Controller,让Controller传过来就可以了,这样将不同模块之间的耦合性降到了最低。而Controller就像一个乐队的指挥,按照需求调用各个模块,让系统的各个部分井然有序的工作。
2、模块详细设计
2.1、数据库设计
原始数据库
原始数据库存储从豆瓣抓取下来的数据,分为三张表:book_author_info,book_online_info,book_publishing_info。
book_author_info表存储作者信息,分为图书编号、作者姓名、作者简介与介绍四列。作者简介内容包括作者的生平以及与此书和作者都有关的一些事件介绍,介绍列与前者相同。作者姓名列存储了各个作者加国籍的信息,需要进行清洗。
book_online_info表存储图书的一些社会化信息,分为图书编号、标签、访问次数、5星评价数量、4星评价数量、3星评价数量、2星评价数量、1星评价数量、想读用户数量、在读用户数量、已读用户数量、还想阅读的书 这十二列。其中标签列将所有的标签,带上打标签的次数都放到了同一个字符串中,需要对其清洗。
book_publishing_info表存储了图书的出版信息,分为图书编号、ISBN号、书名、作者姓名、图书描述、图书目录、包装类型、定价、总页数、出版社名称、出版时间以及图书封面缩略图名称这十二列。作者姓名与book_author_info表的作者姓名列重复,而定价、总页数等数据使用varchar来存储,出版社也没有构建序号,不便于检索,所以这些内容都需要清洗整理。
清洗后数据库
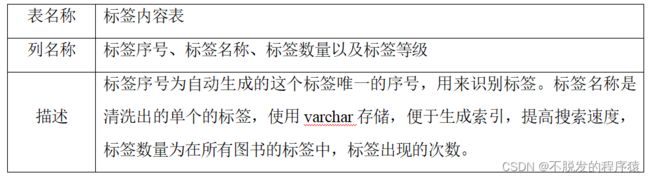
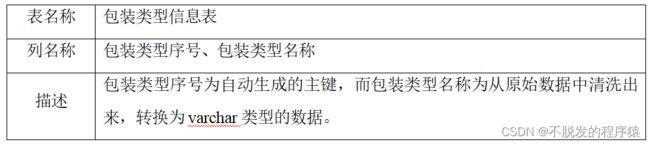
清洗后的数据库是可以直接拿来网站使用的,从原始数据库中数据清洗整合出来的数据,分为九张表:book_info,tag_info,book_tag_relation,author_info,book_author_relation,nationality_info,publisher_info,binding_type,book_relation,内容如下表所示:







用户数据
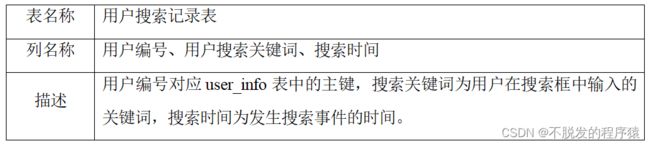
用户数据是用户的登陆注册以及访问记录的表。其中的数据为Web应用自己生成,而不是预先装入系统之中的,分为:user_info,user_visit_history,user_search_history,内容如下表所示:


2.2、页面原型设计
使用快速原型工具Axure RP Pro,根据功能设计了需要实现的页面的原型:首页、搜索结果页、图书展示页、注册页面、登录页面。生成的首页原型效果如下图所示:
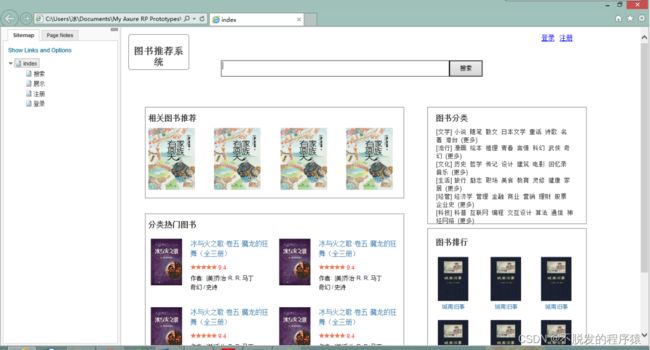
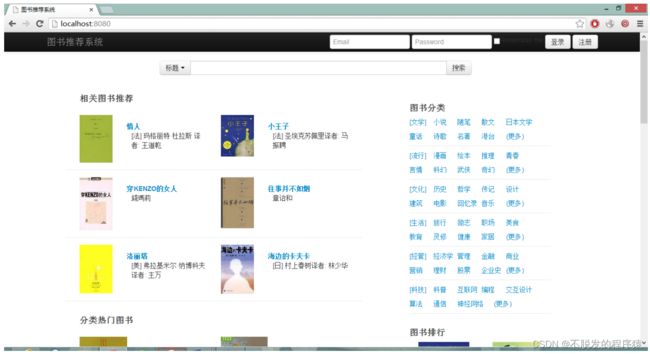
首页顶部包含一个logo,链接到本页;搜索框,提供对图书的搜索入口。以及登陆和注册链接,用于用户的注册与登录管理。正文部分分为四个大模块,名称分别为:相关图书推荐、分类热门图书、图书分类以及图书排行。图书推荐模块列出单本书的缩略图与简要介绍,而分类热门模块列出了几个大的图书分类,以及几本此分类下的比较热门的图书。图书分类模块列出了所有的图书分类,用户可以直接点入查看此分类下的所有图书。图书排行列出前九本最热门的图书。页脚部分注明页面版权信息,以及创建年份。
搜索页面页眉页脚与首页相同,正文部分为一个搜索结果列表,显示搜索结果中的15条记录,每条记录显示图书缩略图、书名、作者、出版社、出版日期、价格以及评分。正文底部是分页,列出了结果的页数,可通过点击来查看后面的搜索结果。右侧列出了热门图书列表,用于向用户推荐。
图书展示页面页眉页脚与首页也相同,正文部分分四大块,第一块为图书基本信息,包括标题、缩略图以及一些图书在版编目信息:作者、出版社、出版时间、页数、定价、装帧、ISBN号。同时还显示评分以及各个星评分数量。第二块为内容简介,是对书内容的简要介绍以及图书目录。第三块为作者简介,是对图书作者以及译者的简要介绍。第四块为相关推荐,展示阅读此书的人还阅读了的书籍。由于原始数据并不包含用户评论,因此用户评论的内容并没有加入展示。
注册页面和登录页面较为简单,用户填写用户名、邮箱、密码、确认密码,之后点击注册即可。登录时,用户输入用户名、密码,然后登录系统,会跳转到首页,首页右侧顶端登录注册不再显示,改为用户名与退出。
3、环境的搭建
3.1、数据库的建立与数据的导入
PowerDesigner创建一个物理数据模型,配置好数据库类型,添加表结构,将在详细设计中所设计的数据库信息与列信息、自增列属性输入到表结构中,生成如下图所示的物理结构设计图。

使用其自动生成工具,生成用于创建数据库的SQL脚本。之后,使用MySQL工具导入到数据库中。同时,将原始数据也使用MySQL工具导入到数据库中。
3.2、工程建立
使用Eclipse创建一个Spring MVC项目,系统会自动生成一套目录结构。

- src/main/java目录用来存放项目的主体部分的源代码,所有的Controller模块、Model模块,以及DAO的Java类,都放在这里,在发布的时候,这里的源码会在编译成class文件后,放入WEB-INF目录下的classes目录。
- src/main/resources目录用来存放项目的配置文件以及MyBatis的Mapping文件。在部署过程中,也会被放入WEB-INF目录下的classes目录中。
- src/test/java目录用来存放项目的测试类,src/test/resource目录用来存放项目的测试配置文件,这些都会在部署时,放入WEB-INF目录下的test-classes目录中。
- JRE System Library包含系统中安装的JRE的库,在项目创建时,可以选择版本。
- Maven Dependencies包含了在Maven的POM配置文件中所配置的依赖包,这些包在工程创建时,由Maven从Maven仓库中下载到本地缓存,并且链接到工程中。
- src目录分main和test,而main/webapp目录下有resources与WEB-INF目录,其中resources目录是在servlet-context.xml中配置的,用于存放页面中的资源的目录,分为css、img、js三个目录,WEB-INF目录分为classes、spring与views目录以及web.xml文件,web.xml文件为Java Servlet的标准配置文件,Spring就在这里配置进去。classes为应用发布时,.class文件的目录,spring目录为spring配置文件存放的目录,用于修改配置,添加beans用于注入等。views目录为视图模块存放的地方,使用jsp作为视图文件。
- target目录为自动编译的目录,目录中有所有类、测试类的编译结果.class文件,以及Maven的配置文件pom.xml。
- pom.xml文件为Maven的配置文件,它包含了项目的基本配置、依赖包以及插件配置。项目创建时,默认只有Spring MVC的基本配置。
3.3、MyBatis配置
MyBatis官方提供了一个自动生成代码的工具:MyBatis Generator(MBG)。它会检测数据库的所有表,并且生成可以用来访问数据库表的代码。这样可以减轻最初访问数据库所需编写代码的工作量。MBG提供了所有常用的数据库操作:增删改查。对于单表的操作,只需要使用这一套生成的类即可。
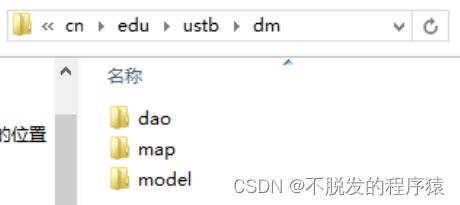
在生成的文件中,dao为mapper接口,存放TableNameMapper.java文件,用来在配置中注入或者使用SqlSession来获取实例,对数据库表执行增删改查操作。model为表结构的类TableName.java和查询条件构造类TableNameExample.java,TableName.java用于存储对应表的响应条目值,用来实现update和insert操作,以及查询出结果的存储。TableNameExample.java用来构造where语句,用于执行select操作。在数据库中有多于两个列的类型为TEXT或者BLOB,那么除了生成TableName.java,还会生成一种TableNameWithBLOBs.java的文件,其中TableName.java负责存储一般的数据类型,TableNameWithBLOBs.java文件负责存储TableName.java中所有数据之外,还包括了TEXT和BLOB类型的数据。mapper目录存储xml配置文件,用于支持在TableNameMapper.java文件中定义的操作。
将代码和配置文件加入到工程中之后,会出现编译错误,显示一些引用的类不存在于工程中。查找原因,发现是因为项目中没有加入数据库与MyBatis的依赖,修改pom.xml配置文件,加入spring-jdbc、mybatis、mybatis-spring与mysql-connector-java依赖配置。
在src/main/resources加入mybatis-config.xml,用来为MyBatis提供连接数据库的配置与Mapper类集合的配置。创建Mysql.properties文件,将配置写入文件中以便复用。
4、数据的清洗
由于原始数据并不能直接拿来使用,因此需要按照之前设计的数据库,将三个表中的原始数据清洗后,存入新设计的表中,程序流程如下图所示:
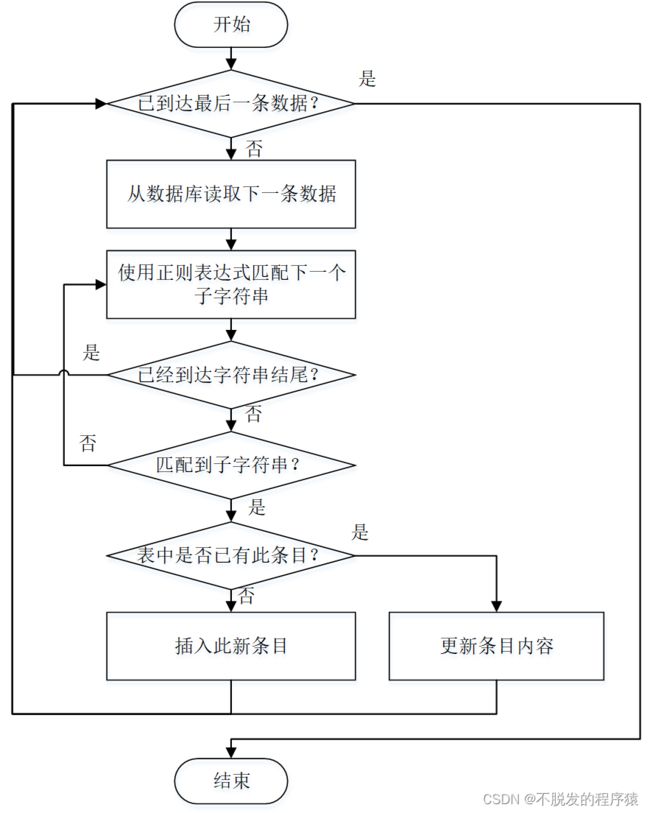
程序会先定义起始和终止图书编号,之后,从第一个图书编号开始,通过主键,查询到图书的数据,将需要的值取出,比如作者信息。作者信息包括了作者国籍、作者姓名以及其它作者姓名,格式如下图所示:
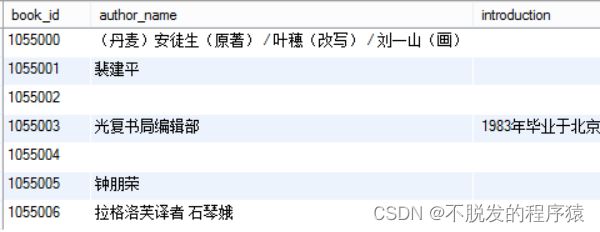
开始打算通过一个完整的正则表达式来对作者信息进行解析,但是由于Java的正则表达式并不能够分辨出中文标点与中文文字,因此,先对字符串做初步的清理:将“编著”、“译者”、“主编”替换为英文斜杠“/”来区分不同的作者,将中英文逗号、中英文括号等内容都替换为英文分号“;”,用于区分国籍与作者。之后,使用将字符串按照斜杠来分割成一个字符串数组,数组中每个字符串代表一个可能带有国家信息的作者名称,使用正则表达式:”^(;([\u4e00-\u9fa5]+);)?([\\w\u4e00-\u9fa5\\.•]+)”来匹配,取出可能以分号加中文字符开头的,作为国籍,以英文字符或者中文字符组成的连续的词作为作者姓名。
之后,拿国籍信息去国籍信息表中查询,没有此项,则作为一个新的条目插入,有则不做处理。在有的数据清洗过程中,比如标签,它有一个统计数据,那么如果表中有这个标签,会将统计数据增加一个。作者姓名与国籍类似,采用相同的方法来存储。之后便查询下一条图书记录。
为了加快读取速度,每次的读取并不只是一条,而是多条图书数据一起读取出来,这样会一次将较多的数据调入内存,降低磁盘IO操作,加快速度。可是由于每本书有三到五个作者,每个作者和国籍都会在解析出来之后变为一个独立的需要插入到数据库中或者去数据库中查询的条目,随着数据条数的增多,同时提交的事务数量会加倍增长,MySQL系统就出现了session数量不足的错误。于是,将每次取出的条数减少,并且在每次操作完成一组数据后,提交并关闭数据库,在需要操作前,再打开数据库。这样就能够即时的关闭用完的session,不会出现由于大量已结束的事务占用session而报错的问题。
同样为了加快数据清洗速度,使用两台电脑,一台运行数据库系统,另一台运行Java程序,MySQL系统打开网络用户的访问权限和所在系统的防火墙3306端口,另一台连接并处理数据。由于数据库操作占比较大的时间,所以瓶颈依旧在运行数据库的系统中,不过相对与在同一个系统中,CPU占用和内存占用有一定程度的下降。
5、系统开发
按照总体设计阶段的分层,将系统分为三个包:cn.edu.ustb.controller、cn.edu.ustb.dm、cn.edu.ustb.model。

5.1、控制器类
controller包为系统结构中的controller模块,根据功能,划分为了五个类:BookInfoController.java负责图书详细信息的展示,IndexController.java负责首页的视图内容获取展示,LoginController.java负责登录信息的处理,RegisterListController.java负责对注册信息的处理,ResultListController.java负责处理查询。
controller类将SqlSessionFactory使用注解的方式注入类中,并且使用注解来实现Controller类与请求映射。使用Log4j工具来输出日志。借鉴Objective-C的方式,使用setter/getter方法来获取变量,以便延迟加载以及提高利用率。
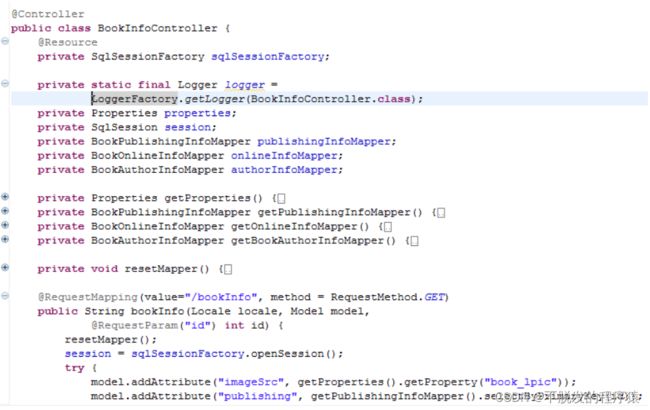
在最开始,Mapper都是使用注解来注入进来的,但是发现SqlSession的开启与关闭不受到控制,完全靠系统来自动完成,那么在并发数量过大之后,大量线程占用session,很容易出现session数量过多的问题,其他人访问不了网站。将Mapper的获取方法改为了使用SqlSession的getMapper方法来获取,这样就可以完全控制session开启时间、结束时间。在每次访问页面的时候,包括浏览器会话没有关闭时刷新,都会重新开启一个新的SqlSession,获取新的Mapper实例,然后执行数据库操作,最后,关闭数据库连接。这样,能够即时的回收过期的SqlSession,防止大量无用的session占用数据库资源。
在使用getter/setter方法时,刚开始将SqlSession的获取放到了getter中,这样会首先检测有没有实例,没有实例再创建,意图是为了延迟加载,在用到的地方才初始化它,并且防止每次使用都创建新实例。可是在实际中却发现,如果用户刷新页面,或者点击分页按钮,系统会抛出错误,说数据库已关闭,无法执行查询操作。原来每次访问,在浏览器没有结束会话时,Web容器会将Controller类的实例保存在内存中,而每次请求只会执行RequestMapping所指定的函数。于是修改SqlSession的获取方式,在浏览器每次发起请求时,通过SqlSessionFactory类的openSession函数来获取一个SqlSession实例。
Mapper的获取也受到了影响,因为每次访问都会创建一个新的SqlSession实例,那么Mapper如果不为null的话,就不会重新创建Mapper实例,这样,Mapper的SqlSession将是已经关闭的session,它不能够执行任何数据库操作。因此,在每次访问时,会将所有的Mapper都重置为null,以使其重新初始化。
5.2、模块类
模块类包含一些页面需要的数据结构,对数据的加工函数以及分页功能实现。其中,BookClassifyItemModel.java类为单纯的书籍按照分类来显示信息的模块,其中,借鉴了MyBatis的Example类的方法,添加了一个内部类,在父类中编写了创建内部类的函数,用于创建图书列表。
BookListItemModel.java类为图书的基本信息展示类,用在了图书推荐、图书排行、查询结果展示以及图书详细信息中。在类中提供了计算得分的函数,以及格式化日期的函数,用于在页面中显示。
SearchResultPaginationModel.java类为查询结果分页模块,用于支持查询的分页显示以及分页功能。由于数据量巨大,为了提高查询效率,分页查询并没有采用MyBatis的分页查询方法,MyBatis会在第一次查询时,将所有的符合条件的结果读入内存中,之后再根据分页条件来显示,这样,虽然会在页面跳转的时候很快,但在第一次查询时,会有大量的磁盘IO操作,在数据类大的情况下,会对系统性能造成很大的影响,而搜索结果大部分用户只是关注前几页,后面的结果访问量并不大,这样就有些得不偿失。分页查询采用数据库的limit条件,只在每次查询时获取每一页要显示的数据,在创建了索引以后,这个查询过程是非常迅速的,只将需要的数据读入内存。查询效率提高了,就需要自己来实现分页。
5.3、视图类
视图使用jsp作为页面,引入了JSTL的c库来辅助生成布局。

header.jsp为页面顶端的logo、搜索栏与登录注册按钮的部分。footer.jsp为页面底部版权信息的内容。pagination.jsp为分页,根据SearchResultPaginationModel.java的内容来生成分页。
bookInfo.jsp负责显示图书的详细内容,index.jsp负责首页内容的显示,login和register负责登录与注册页面,resultList为搜索结果,只是单纯的搜索结果列表,用于分页时,通过AJAX请求来局部刷新,减少流量。resultListPag为搜索结果页面,是页面的框架,其中引入了resultList,作为第一次访问时,搜索结果的展示。
每个页面都引入header.jsp与footer.jsp,用来引入所需要的布局文件与页面脚本,构建起基本的页面框架。页面导航栏的布局采用Bootstrap的导航栏样式,登录可以从导航栏上直接输入来登录。搜索条件分为标题、作者、出版社,可以对这三者进行查询。
采用JSTL的标准c标签库,方便的实现循环(c:forEach)、判断(c:if、c:when),
页面整体布局采用Bootstrap的响应式布局,首页、搜索结果页将正文部分分为左右两块,图书信息页面只有一个块。在首页中各个块中,每本书作为一个row类型,每个row又分为两个span,用于分割左右两块。一部分布局是由自定义的main.css文件来定制。而自定义的JavaScript也由在footer中引入的main.js来定制那些比如搜索按钮点击事件、分页按钮点击事件、登录等等。
分页按钮的样式采用了Bootstrap的分页按钮,参考Amazon查询结果的分页效果,在页数多于9页的情况下,翻到中部,则只显示部分挨着的页码,结合SearchResultPaginationModel类的结构,完成了查询的分页。
6、分析及调优
首页为所有页面中最为复杂的页面,需要查询四块内容。
四块内容分别需要按照各自的查询条件来排序,然后取前几个符合条件的结果。在刚开始,没有对数据库优化之前,页面打开速度几乎需要3秒,对查询SQL进行分析,发现,大部分操作时间都消耗在了排序上,于是对排序条件创建了索引,首页的首次打开延迟变得小于1秒,并且由于在控制器中使用getter\setter,部分没有参数的数据会在查询之后一直留在内存中,不会进行第二次查询,所以刷新会返回304,页面内容没有改变。

由于此平台不涉及搜索算法的研究,所以搜索结果为从数据库字符串中like出来的。考虑到数据库巨大,若不做处理,将会严重影响查询效率。于是按照查询特点,对图书标题、出版日期两列做了索引,查询速度有了成倍的提升。再加上每次查询使用limit,磁盘内存间的交换操作减少了许多。
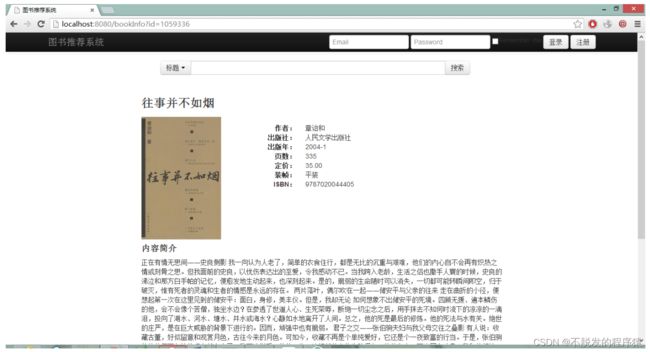
对图书的缩略图、内容以及作者简介做了展示,还有登录失败后会跳转到的登录页面,注册按钮点击后跳转到的注册页面,相对于其它两个相对功能较单一,性能也没有太大的提升空间。
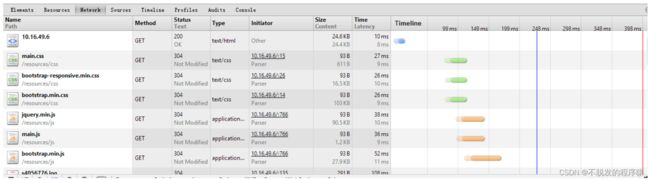
7、性能测试
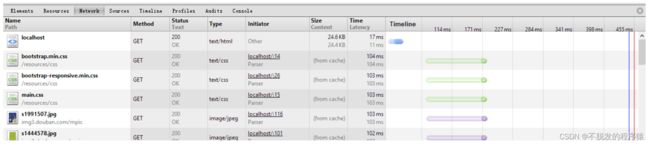
使用Chrome浏览器的开发者工具来进行测试。首次加载首页需要等待6ms,其它静态的css与js文件几乎不需要时间,在统计结果中,显示为0。之后刷新,Tomcat会从内存中直接取得返回结果。由下图可知,加载页面仅需要用时2ms。
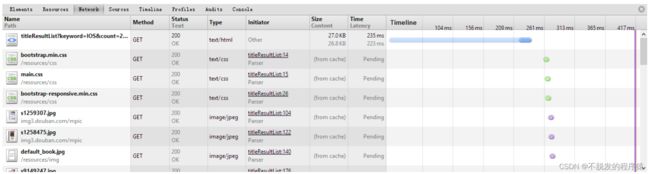
在查询结果页面,查询一个关键词“IOS”,页面的等待时间为223ms。同样由于缓存的作用,刷新的等待时长变为8ms。

项目资源下载请参见:0TKS7GNY