浅析C/C++编译流程
更多博文,请看音视频系统学习的浪漫马车之总目录
C/C++编译
浅析C/C++编译本质
一篇文章入门C/C++自动构建利器之Makefile
升级构建工具,从Makefile到CMake
如果你愿意一层一层
一层地剥开我的心
你会发现
你会讶异
你是我
最压抑
最深处的秘密
这是杨宗纬一首很经典的歌,之所以引用它是因为今天的内容就犹如《洋葱》一般,需要一层层地剥开,剥开编译器紧紧裹着的外衣……
该系列前面的文章已经讲了C语言和C++的一些重点难点,从本篇博文开始将开始探索C/C++编译体系(不仅仅像其他很多文章一样只讲那四个主要流程,还会更深入讲链接的本质)以及内存模型相关的内容,从编译体系继而将讲解MakeFile以及cmake的内容,而这些内容,将为以后做音视频开发编译第三方库打下坚实的基础~~
GCC
编译器
只要是程序员,都会知道编译是什么,不过这里还是要简单提两句,这样可以突显文章的完整性(^ _ ^)。我们平时写的编程语言计算机根本看不懂,计算机只懂二进制指令,但是如果要我们写二进制指令那简单很要命且非常低效,所以需要有个中间人作为翻译,那聪明的人们就想出了那不如让计算机自己去处理翻译这件事,所以编译器便应运而生。编译器,就是将我们写的程序(C、C++、Java等)翻译过计算器能够读懂的二进制指令。
GCC是什么
只要是程序员,都会对gcc有所听闻,gcc是当年GNU计划(打造出一套完全自由(即自由使用、自由更改、自由发布)、开源的操作系统)的产物之一,起初是专门针对C语言的编译器,不过后来经过发展,还可以作为C++、Go、Objective -C 等多种编译语言编写的程序的编译器,现在已经可以称之为“GNU 编译器套件”。
现在已经有很多IDE已经集成了gcc了,但是为了可以更加深刻地认识编译过程,所以文章讲解的是使用原汁原味的gcc,即命令行的方式。
gcc和g++
前面说了GCC可以编译C和C++,所以对于C和C++,GCC 编译器已经为我们提供了调用它的接口,对于 C 语言或者 C++ 程序,可以通过执行 gcc 或者 g++ 指令来调用 GCC 编译器。(实际上gcc、g++指令也是对ccp(预处理指令)、cc1(编译指令)、as(汇编指令)指令的包装的)
这里容易误以为gcc 专门用来编译C,g++专门编译C++,其实gcc 指令也可以用来编译 C++ 程序,同样 g++ 指令也可以用于编译 C 语言程序。
实际上,只要是 GCC 支持编译的程序代码,都可以使用 gcc 命令完成编译。
gcc会根据文件名后缀去自行判断出文件类型,即如果遇到文件xxx.c则默认以编译 C 语言程序的方式编译此文件,遇到文件xxx.cpp,则默认以编译 C++ 程序的方式编译此文件。
而g++命令无论目标文件的后缀名是什么,都一律按照编译 C++ 代码的方式编译该文件。因为C++兼容C语言,所以就算遇到xxx.c,g++同样也可以以C++方式编译
不过用gcc编译C++代码,还是会和g++不同,会更加繁琐一些:
在linux终端,假如添加一个c++源文件:
ubuntu@VM-20-7-ubuntu:~/study/projects/main$ vim main.cpp
main.cpp:
#include 执行g++将其编译为可执行文件:
~/study/projects/CatDemo/src$ g++ Cat.cpp
没有报错。
但是如果使用gcc编译:
ubuntu@VM-20-7-ubuntu:~/study/projects/main$ gcc main.cpp
则立马报错:
/usr/bin/ld: /tmp/ccZ7BeFi.o: in function `main':
main.cpp:(.text+0x24): undefined reference to `std::allocator<char>::allocator()'
/usr/bin/ld: main.cpp:(.text+0x3b): undefined reference to `std::__cxx11::basic_string, std::allocator >::basic_string(char const*, std::allocator const&)'
(还有很多)...
报错的根本原因就在于,该程序中使用了标准库 和 提供的类对象,而 gcc 默认是无法找到它们的,必须通过“-xc++”明确告诉gcc这是C++文件,并且加上编译选项“ -lstdc++ -shared-libgcc ”指定寻找C++的标准库:
ubuntu@VM-20-7-ubuntu:~/study/projects/main$ gcc -xc++ main.cpp -lstdc++ -shared-libgcc
ubuntu@VM-20-7-ubuntu:~/study/projects/main$
这样编译是没有问题的。
因为gcc命令编译C++明显更加麻烦,所以本系列C程序用gcc编译,c++程序用g++编译。
C/C++编译流程
上面的例子是是直接用gcc命令从源代码到可执行文件一步到位处理,但是事实上这里可以分为4个步骤分别是预处理(Preprocessing)、编译(Compilation)、汇编(Assembly)和链接(Linking):
(图片来源:GCC and Make
Compiling, Linking and Building
C/C++ Applications)

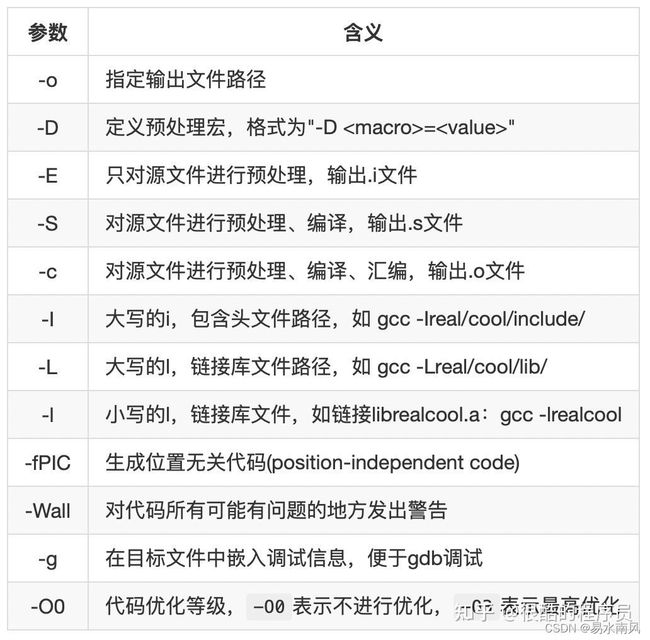
gcc常见参数有(图来自CMake实践应用专题):
预处理
预处理就是真正的编译前的准备工作,过程主要是处理那些源文件和头文件中以#开头的命令,比如 #include、#define、#ifdef 等。预处理的规则一般如下:
- 将所有的#define删除,并展开所有的宏定义。
- 处理所有条件编译命令,比如 #if、#ifdef、#elif、#else、#endif等。
- 处理#include命令,将被包含文件的内容插入到该命令所在的位置,这与复制粘贴的效果一样。注意,这个过程是递归进行的,也就是说被包含的文件可能还会包含其他的文件。
- 删除所有的注释//和/* … */。
- 添加行号和文件名标识,便于在调试和出错时给出具体的代码位置。
- 保留所有的#pragma命令,因为编译器需要使用它们。
预处理由以下命令执行,预处理的结果是生成.i文件。.i文件也是包含C语言代码的源文件,只不过所有的宏已经被展开,所有包含的文件已经被插入到当前文件中。
$gcc -E demo.c -o demo.i
-E表示执行预处理,-o表示输出的文件名称。如果没有指定-o,则会直接在终端显示出预处理后结果文件内容。
举个栗子:
又回到linux终端,创建一个Cat.cpp:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ vim Cat.cpp
创建一个Cat.h:
#ifndef UNTITLED_CAT_H
#define UNTITLED_CAT_H
/**
* 猫
*/
class Cat {
public:
/**
* 猫吃东西
*/
void eat();
};
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ vim Cat.h
定义一个Cat类:
#endif //UNTITLED_CAT_H
#include "Cat.h"
#include 执行预处理命令:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ -E Cat.cpp -o Cat.i
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ls
Cat.cpp Cat.h Cat.i main.cpp
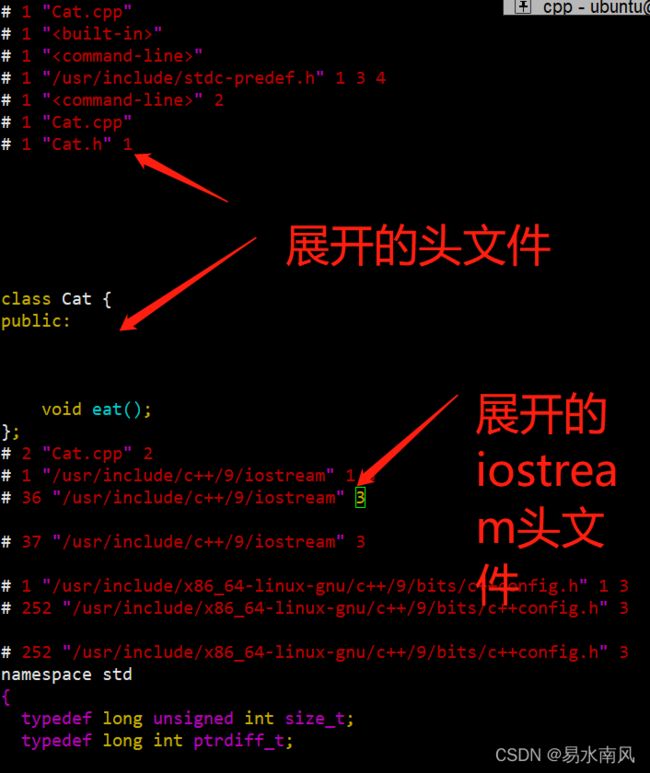
已经生成Cat.i文件了,查看下:
是一个非常长的文件,大部分我们已经看不懂了。这里截图展示主要部分,可以看出,Cat.h和iostream.h2个头文件已经被展开,而只有Cat.h展开,在Cat.i中才能有Cat类的定义,这也是展开头文件的意义所在,并且Cat.h定义的“#ifndef UNTITLED_CAT_H
#define UNTITLED_CAT_H”语句已经不见
因为文件实在太大,所以让我们执行直接看文件结尾:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ vim Cat.i +
终于看到我们的主角Cat本尊了(预处理后Cat.i竟然接近3万行,可想而知展开的iostream.h有多么庞大。。)
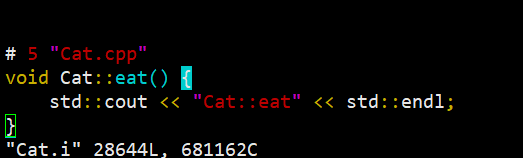
可以看到原来定义的宏#define EAT "Cat::eat"已经展开,即用对应的值替换使用的位置,这也验证了前面的说法。
编译
编译就是把预处理完的文件进行一些列的词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。编译是整个程序构建的核心部分,也是最复杂的部分之一。
GCC中使用:
$gcc -S demo.i(或demo.c) -o demo.s
-S表示将源文件(有没有经过预处理的都可以)转化为汇编文件,文件名后缀为s。
现在对上面的Cat.i进行编译:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ -S Cat.i -o Cat.s
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ls
Cat.cpp Cat.h Cat.i Cat.s main.cpp
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$
查看下Cat.s:
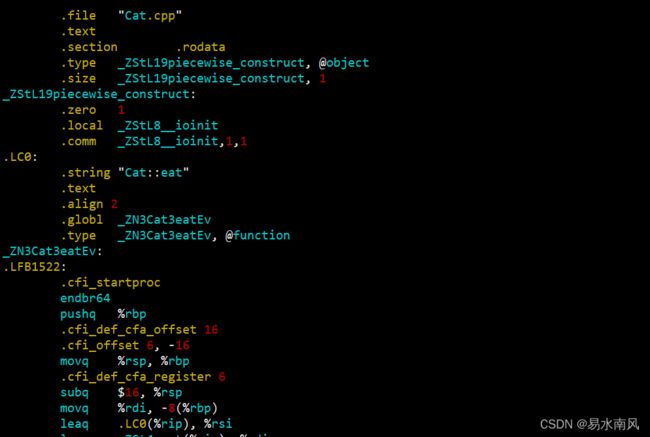
这就是我们曾经熟悉的汇编代码了。
因为汇编语言不是本文的主要内容,所以暂时先跳过这部分内容。
汇编
就是将汇编代码转化为机器码的过程,这个过程相对编译简单很多,没有复杂的语法,也没有语义,也不需要做指令优化,主要是汇编语句和机器指令的对照表一一翻译就可以了。
命令为:
$gcc -c demo.i(或demo.c或demo.s) -o demo.o
-c表示由源文件或汇编文件生成机器码的目标文件,后缀为o。
汇编下Cat,s:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ -c Cat.s -o Cat.o
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ls
Cat.cpp Cat.h Cat.i Cat.o Cat.s main.cpp
目标文件与可执行文件的组织形式非常类似,只是有些变量和函数的地址还未确定,程序不能执行。所以下一步链接的一个重要作用就是找到这些变量和函数的地址。
为了更本质地理解下一个步骤——链接,我们需要先对目标文件结构有一定的了解。
在 Linux 下,将目标文件与可执行文件统称为 ELF文件。
目标文件有三种形式:
- 可重定位目标文件:包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件,对应linux的.o和静态链接库。
- 可执行目标文件:包含二进制代码和数据,其形式可以被直接拷贝到存储器中执行,对应可执行文件。
- 共享目标文件:一种特殊类型的可重定位目标文件,可以再加载或运行时被动态加载到存储器并链接,对应动态链接库。
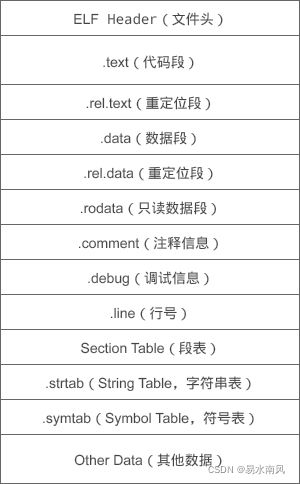
以下是ELF文件的结构(图来源于:目标文件和可执行文件里面都有什么?):
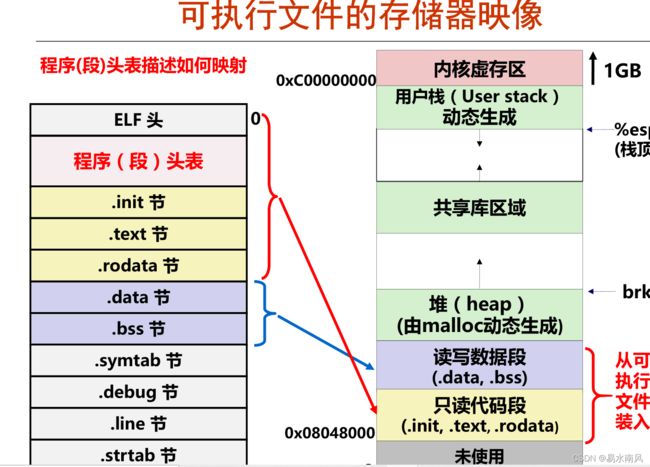
各个段和虚拟内存的映射关系(图来源于南京大学 计算机系统基础(一)主讲:袁春风老师课件):
其中我们暂时只需要了解以下几个段:
- ELF Header文件头:描述了整个目标文件的属性,包括是否可执行、是动态链接还是静态链接、入口地址是什么、目标硬件、目标操作系统、段表偏移等信息。
- .text代码段:存放编译后的机器指令,也即各个函数的二进制代码。一个C语言程序由多个函数构成,C语言程序的执行就是函数之间的相互调用。
- .data:数据段,存放全局变量和静态变量。(对应漫谈C语言内存管理中说的全局数据区)
- .rodata :只读数据段,存放一般的常量、字符串常量等对应漫谈C语言内存管理中说的常量区。
- .rel.text.、rel.data:重定位段,包含了目标文件中需要重定位的全局符号以及重定位入口。
- .symtab 符号表,保存了全局变量名、局部变量名、函数名等在字符串表中的偏移。
汇编文件生成目标文件的过程,除了将汇编指令转化为二进制指令以外,还有一件很重要的事情,就是输出符号表。
什么是符号呢?在漫谈C语言内存管理中的“变量的本质”一小节说过,变量(函数名)就是地址的助记符,是为了方便人处理而存在的,它们也被称为“符号”,它们的起始地址就成为“符号定义”,当它们被调用的时候也称为符号引用。
再说下符号表是什么,这对于理解后面的链接本质极为关键。符号表本质上是一种数据库,用来存储代码中的变量,函数调用等相关信息。该表以key-value 的方式存储数据。变量和函数的名字就用来对应表中的key部分,value部分包含一系列信息,例如变量的类型,所占据的字节长度,或是函数的返回值。
通过命令
readelf -h Cat.o
查看Cat.o的ELF Header:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ readelf -h Cat.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
//小端模式
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
//可重定位目标文件
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
//入口地址 //因为不能执行,所以入口地址为0x0
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 1912 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 16
Section header string table index: 15
目前需要关注的信息已用注释标注出,可以看出Cat.o是一个可重定位的目标文件,即需要和其他可重定位的目标文件链接成一个可执行文件才可以运行。
直接查看下生成的Cat.o,因为是二进制文件,不能直接打开,这里可以用objdump命令来反汇编查看它的符号表信息:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ objdump -t Cat.o
Cat.o: file format elf64-x86-64
SYMBOL TABLE:
//l表示局部符号,仅本文件内可见
0000000000000000 l df *ABS* 0000000000000000 Cat.cpp
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 l d .data 0000000000000000 .data
0000000000000000 l d .bss 0000000000000000 .bss
0000000000000000 l d .rodata 0000000000000000 .rodata
0000000000000000 l O .rodata 0000000000000001 _ZStL19piecewise_construct
0000000000000000 l O .bss 0000000000000001 _ZStL8__ioinit
000000000000003b l F .text 000000000000004d _Z41__static_initialization_and_destruction_0ii
0000000000000088 l F .text 0000000000000019 _GLOBAL__sub_I__ZN3Cat3eatEv
0000000000000000 l d .init_array 0000000000000000 .init_array
0000000000000000 l d .note.GNU-stack 0000000000000000 .note.GNU-stack
0000000000000000 l d .note.gnu.property 0000000000000000 .note.gnu.property
0000000000000000 l d .eh_frame 0000000000000000 .eh_frame
0000000000000000 l d .comment 0000000000000000 .comment
//l表述全局符号,可被链接器处理到 //很眼熟?没错,就是eat方法,存放在.text段(代码段)中
0000000000000000 g F .text 000000000000003b _ZN3Cat3eatEv
//UND表示定义未知,需要被链接
0000000000000000 *UND* 0000000000000000 _ZSt4cout
0000000000000000 *UND* 0000000000000000 _GLOBAL_OFFSET_TABLE_
0000000000000000 *UND* 0000000000000000 _ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc
0000000000000000 *UND* 0000000000000000 _ZSt4endlIcSt11char_traitsIcEERSt13basic_ostreamIT_T0_ES6_
0000000000000000 *UND* 0000000000000000 _ZNSolsEPFRSoS_E
0000000000000000 *UND* 0000000000000000 _ZNSt8ios_base4InitC1Ev
0000000000000000 *UND* 0000000000000000 .hidden __dso_handle
0000000000000000 *UND* 0000000000000000 _ZNSt8ios_base4InitD1Ev
0000000000000000 *UND* 0000000000000000 __cxa_atexit
这里可以清楚看到各个段的信息,需要注意的点已经用注释标出,这里需要特别关注的就是_ZN3Cat3eatEv,即eat方法是放在.text段的,等会查看main.o的时候注意看下区别。,另外就是UND表示定义未知,需要被链接的符号。
汇编介绍到此结束,主要就是介绍了目标文件的结构,为链接做铺垫,接下来就是最受瞩目的链接阶段了,因为这是多文件模块开发的基石,也是整个编译阶段对于我们来说最需要关注的点。
链接
链接简单来说就是在多模块程序中,一个源文件会引用到其他源文件的变量或者方法,但是编译成目标文件都是针对单个源文件的,所以此时目标文件并不知道被引用的其他模块的变量或者函数的具体地址,所以此时目标文件中这些被引用的变量或者函数的地址是处于被搁置的状态,而链接就是将这些目标文件合并在一起,让这些被引用的变量或者函数的地址确定下来的过程,即将符号定义的地址填入符号引用处。
举个不太准确的例子来讲,就如同用乐高积木搭一个足球场,分模块就是场地、观众席、顶棚、外墙几个模块,而各个模块之间有连接的地方,在整体合起来的之前,虽然观众席知道底部将与场地连接,但是由于现在场地还在另一个地方组装,所以暂时在底部先留个坑位,等到各个模块组合(链接)在一起的时候,在和场地的具体连接处连接。
总的来说,链接分为2步:
1. 目标文件段的合并,符号表合并完毕之后,再进行符号解析。
2. 符号重定向。
目标文件段的合并就是将相同的文件段合并在一起,如图(图来源于南京大学 计算机系统基础(一)主讲:袁春风老师课件):
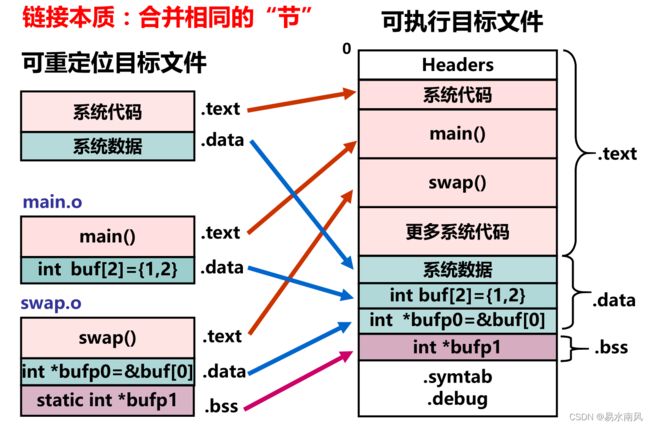
符号解析就是链接器将每个符号的引用和符号定义建立关联。
而重定位就是计算每个定义的符号在虚拟地址空间的绝对地址,然后将可执行文件符号引用处的地址修改为重定位后的地址信息。
为了更好展示链接,对Cat做了一点小改动,加上了一行:
#include "Cat.h"
#include 创建一个main.cpp:
#include 编译成目标文件并查看符号表信息:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ -c Cat.cpp
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ objdump -t Cat.o
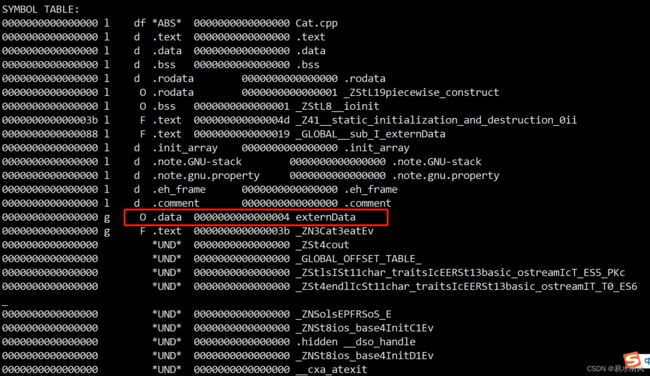
可以看到新增的全局变量(符号)externData:
编译main.cpp并查看生成的目标文件:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ -c main.cpp
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ objdump -t main.o
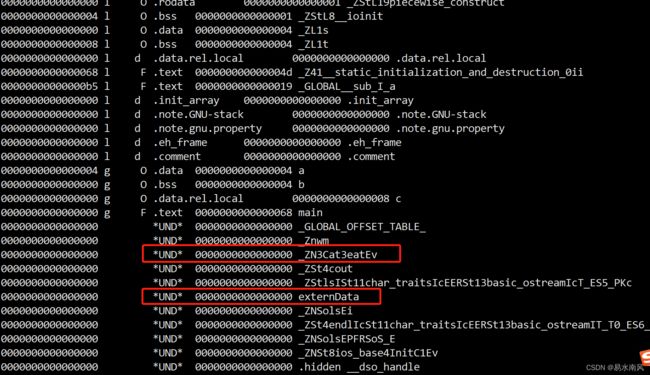
注意到Cat的eat方法(main.cpp中的cat->eat();)和引用Cat的externData变量是UND的,就是处于前面说的未知定义,等待链接赋值真正地址的状态。
此时将main,cpp和Cat.cpp链接起来:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ main.o Cat.o -o Main.exe
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ls
Cat.cpp Cat.h Cat.i Cat.o Cat.s main.cpp Main.exe main.o
用readelf命令查看生成的Main.exe的Elf文件头:
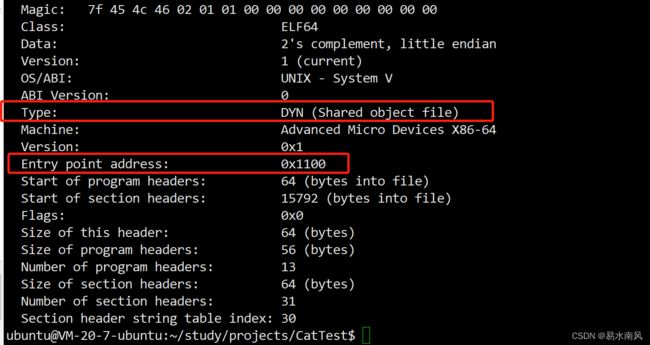
可以看到入口地址有了,说明程序可以运行了,但是不对,type是DYN (Shared object file),而不是EXEC (Executable file)。
经过多方查找,发现gcc默认加了–enable-default-pie选项(gcc编译选项fpic/fPIC, fpie/fPIE的说明):
Position-Independent-Executable是Binutils,glibc和gcc的一个功能,能用来创建介于共享库和通常可执行代码之间的代码–能像共享库一样可重分配地址的程序,这种程序必须连接到Scrt1.o。标准的可执行程序需要固定的地址,并且只有被装载到这个地址时,程序才能正确执行。PIE能使程序像共享库一样在主存任何位置装载,这需要将程序编译成位置无关,并链接为ELF共享对象。
引入PIE的原因是让程序能装载在随机的地址,通常情况下,内核都在固定的地址运行,如果能改用位置无关,那攻击者就很难借助系统中的可执行码实施攻击了。类似缓冲区溢出之类的攻击将无法实施。而且这种安全提升的代价很小
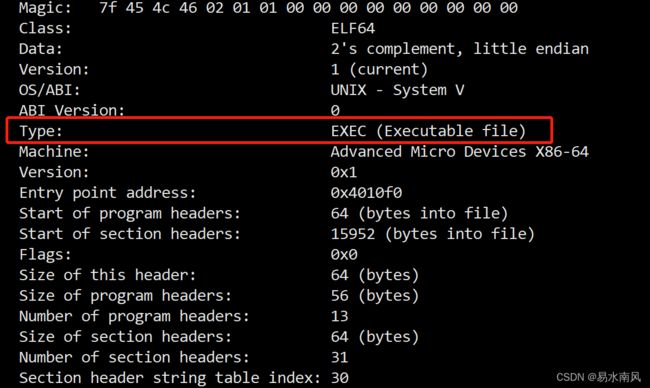
添加-no-pie选项即可关闭Position-Independent-Executable:

这次Type正常了:
查看下Main.exe的符号表:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ objdump -t Main.exe
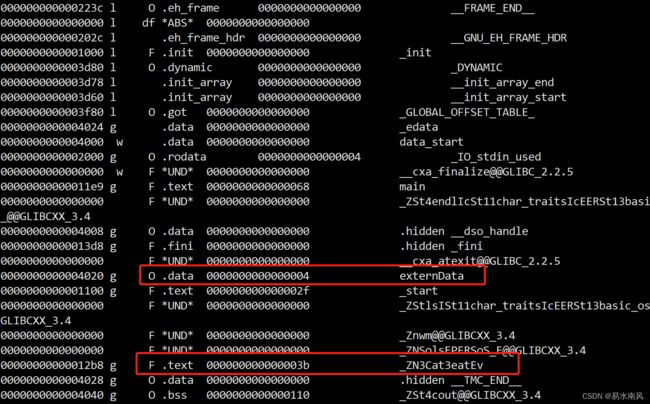
**可以非常开心的看到Cat的eat方法和引用Cat的externData变量此时已经有地址了,分别放在了.data和.text段中。**这就是链接最关键的处理。
运行下一切正常,说明已经链接成功~~

关于链接更多细节,可以看下深入理解计算机系统 “链接”一章以及南京大学 计算机系统基础(一)主讲:袁春风老师。
静态链接库、动态链接库
C/C++中的库文件,类似Java的Jar包,本质就是一个压缩文件,里面是实现某个功能模块的各种代码的打包。通过库文件,可以方便地复用代码,极大地提升了开发的效率。
比如C 语言标准库中提供有大量的函数,如 scanf()、printf()、strlen() 等,只要在源文件中引入对应的头文件,就可以访问到库文件的函数或者变量。而这种头文件和库文件相结合的访问机制的好处在于,我们可以通过头文件去对外暴露一些外部要用到的接口和变量的同时,不对外暴露内部实现的源码。
在C/C++中,库文件在链接阶段处理,有2种链接方式,一种是静态链接,即在生成可执行文件之前链接,另外一种是动态链接,即在生成可执行文件之后进行。
静态链接库就是将整个库文件在生成可执行文件之前的链接阶段都打包到可执行文件中
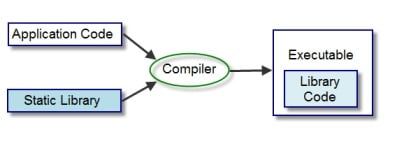
优势是:
- 可执行文件可以独立运行,无需另外带上库文件
- 相对于动态链接库,可以在运行的时候节省链接的时间(不过几乎可以忽略)
劣势是:
- 一旦库文件需要更改,整个可执行文件都要重新链接生成新的可执行文件。
- 和使用动态链接库生成的可执行文件相比,静态链接库生成的可执行文件的体积更大,所以更占用磁盘空间。
- 系统中如果有多个程序使用到该库文件,则会因为重复使用而导致内存空间的浪费。
动态链接库则是在运行时才链接到可执行文件中
优势是:
- 一旦库文件需要更改,只需要更换库文件即可,可执行程序无需修改。
- 和使用静态链接库生成的可执行文件相比,使用动态链接库的可执行文件的体积更小,所以更省磁盘空间。
- 系统中如果有多个程序使用到该库文件,可以复用,即不会造成内存空间的浪费。
劣势是:
- 可执行文件不可以独立运行,需另外带上库文件
- 相对于静态链接库,在运行的时候会增加动态链接的时间(不过几乎可以忽略)
可以看出静态链接库和动态链接库优点和缺点和相反的,而综合来看,动态库更加灵活和省空间,所以一般优先使用动态链接库。
生成静态链接库
为了更能体会静态链接库的打包,我在原文件夹中添加Dog类:

Dog.h:
#ifndef UNTITLED_DOG_H
#define UNTITLED_DOG_H
class Dog {
public:
//狗只有一个方法“叫”
void shout();
};
#endif //UNTITLED_DOG_H
Dog.cpp:
#include "Dog.h"
#include 修改main.cpp:

main.cpp改为:
#include 生成Dog.cpp和main.cpp对应的目标文件:

制作动态库一般用ar打包压缩指令,先man以下ar看下介绍:
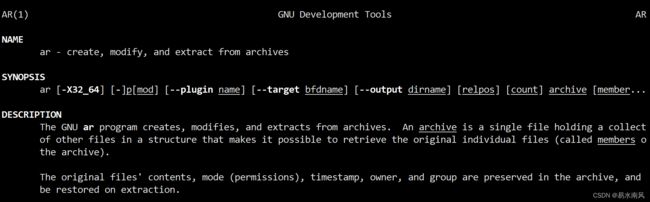
简单讲就是ar指令可以创建、修改、抽取一个归档打包文件。
生成静态链接库的参数一般是rcs,通过man可以看到:
r:
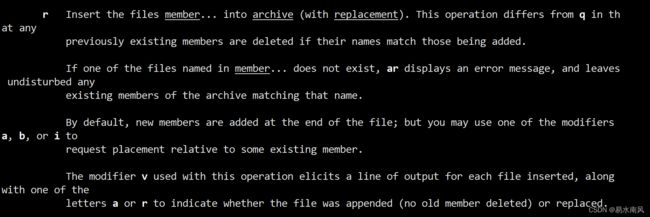
v:

s:

具体就不翻译了,各位自己理解吧哈哈~~
这里将Cat.o和Dog.o打包成一个静态链接库Animal.a(linux环境静态链接库后缀为a):

看,已经生成了静态链接库Animal.a了!
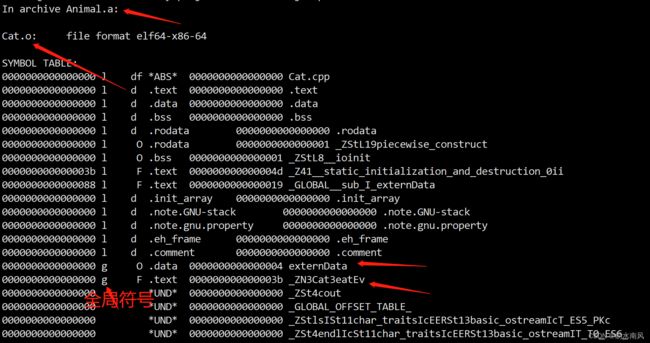
先看下Animal.a的符号表:
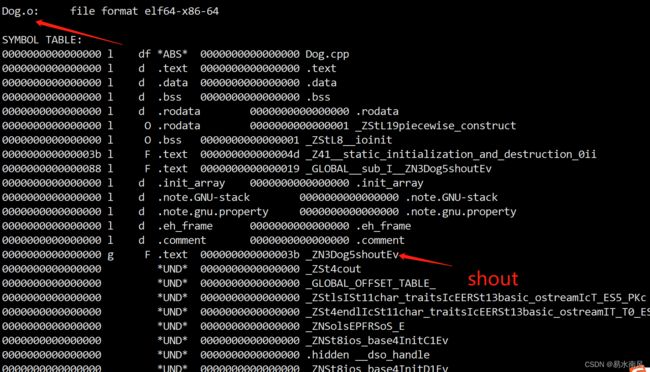
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ objdump -t Animal.a
可以看到依次显式出Cat.o和Dog.o的符号表,可以看出Cat.o和Dog.o的的确确已经被打包进去了~
链接静态库使用g++ -static,-static 选项强制 GCC 编译器使用静态链接库:
![]()
由于没有显式指定名字,所以a.out就是链接后的可执行文件。执行下:

毋庸置疑,静态链接库已经链接成功了。
生成动态链接库
动态库由于其需要在程序运行时去加载链接,所以情况会与静态库有所不同。
(以下内容主要来自 深入理解计算机系统)
对于动态共享库而言,主要目的就是允许多个正在运行的继承共享内存中的相同库代码,这里遇到的问题就是多个进程如何共享一个库的代码呢?
方法一:
给每个共享库事先分配一个块专用的地址空间,要求加载器总在这个地址加载共享库。
缺点:
- 对地址空间使用效率不高,因为即使不加载这个共享库,这部分空间依旧得分配出来。
- 一旦库被修改,还要调整这块分配的空间,这使得它难以管理
- 如果共享库很多,就很容易出现地址空间之间出现许多不能使用的内存碎片空间
方法二:
基于方法一的种种缺点,所以出现了“与位置无关的代码”,目的是让库代码可以在任意地址加载执行。(即用相对地址)
首先要知道的是,在一个目标模块(包含共享目标模块)中,数据段总是在代码段后面的,代码段和数据段之间的相对距离固定,和代码段和数据段的绝对地址无关。
所以一个目标模块内的的调用或者引用偏移量是已知的,所以本身就是PIC代码。只有对外部的函数调用和变量引用才需要处理为PIC,因为它们都要求在链接时重定位。
在生成PIC代码的时候,编译器会在数据段开始创建一张“全局偏移量表“GOT”,GOT包含每个被这个目标木块引用的全局数据目标的表目,然后给每个表目生成一个重定位记录,在加载动态库时,动态链接器会重定位GOT的每个表目,使得它包含正确的位置。
(这里只是简单说明下,详细可以看南京大学 计算机系统基础(一)主讲:袁春风老师)
首先生成与位置无关代码的目标文件:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ g++ Cat.cpp Dog.cpp -c -fpic
然后将目标文件生成动态链接库:
g++ -shared Cat.o Dog.o -o Animal.so
已经生成动态链接库:
-rwxrwxr-x 1 ubuntu ubuntu 17072 Dec 18 12:37 Animal.so
再用动态库和main.cpp生成可执行文件:
g++ main.cpp Animal.so -o Animal.exe
可以看到已经生成可执行文件:
-rwxrwxr-x 1 ubuntu ubuntu 17680 Dec 18 20:44 Animal.exe
顺手运行下:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ./Animal.exe
./Animal.exe: error while loading shared libraries: Animal.so: cannot open shared object file: No such file or directory
额。。找不到动态链接库。
别忘了,动态库是运行时加载的,这里报错是找不到动态库文件。通过ldd命令可以看到可执行文件中动态库的信息:
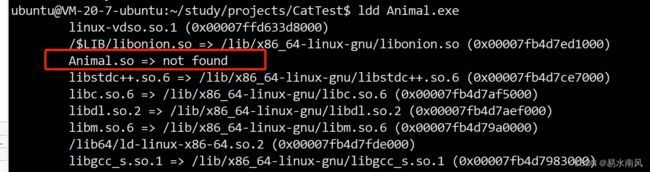
可以看到我们动态库确实没找到。为什么呢?
首先动态库的加载是通过动态链接器完成的,动态链接器是操作系统的一个独立的进程,加载动态库时,在它内部有一个默认的搜索顺序,按照优先级从高到低的顺序分别是:
- 可执行文件内部的 DT_RPATH 段
- 系统的环境变量 LD_LIBRARY_PATH
- 系统动态库的缓存文件 /etc/ld.so.cache
- 存储动态库 / 静态库的系统目录 /lib/, /usr/lib 等
1属于可执行文件内部的,我们改变不了。
2一般是在终端输入export LD_LIBRARY_PATH=$ LD_LIBRARY_PATH:xxx,其中 xxx 为动态链接库文件的绝对存储路径
3一般是修改~/.bashrc 或~/.bash_profile 文件,即在文件最后一行添加export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:xxx(xxx 为动态库文件的绝对存储路径)。保存之后,执行source .bashrc指令(此方式仅对当前登陆用户有效)。
4最简单,直接拷贝动态库到系统目录 /lib/, /usr/lib即可,不过为了以后更新动态库方便,一般是创建一个软链接。
这里我就直接用4的方法在系统目录 /lib/, /usr/lib下创建Animal.so的硬链接:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ sudo ln Animal.so /usr/lib/libAnimal.so
再执行ldd命令查看可执行文件:
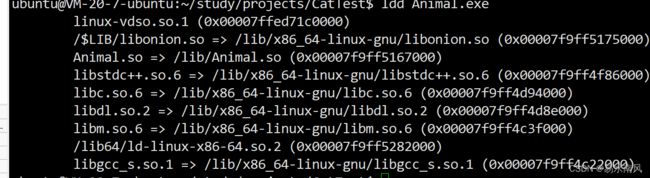
已经找到动态库了
执行下:
ubuntu@VM-20-7-ubuntu:~/study/projects/CatTest$ ./Animal.exe
Cat::eat
externData:10
I am dog
Here is a Cat
完美~~
总结
又是一篇好长好长的博文,写了三个星期,虽然类似的内容网上很多,但是还是希望能尽量写得比大部分文章深一些,又通俗易懂一些吧,由于水平有限,有错误请各位指正哈~~下一篇就开始讲自动构建方面的内容——一篇文章入门C/C++自动构建利器之Makefile
如果觉得本文有帮助,别忘了点赞关注哦~