SeeKeR: 寻找知识的语言模型

本文要解决的问题:
1.当前的LLM能够产生通顺的句子,但就事实性上而言可能并不正确,即不符合客观事实,增大模型尺寸也无法解决;
2.知识库无法实时更新,模型不能get到最新的信息,即只能在训练集(可能是几年前的信息了)上检索并作答;
3.从检索到的多个文档中进行信息融合是一个难点,可能会导致不正确的response(有论文提出模块化可以缓解该问题,即先找到文档的相关部分,然后再生成最终的response)。
文章目录
-
- Abstract
- 1. Introduction
- 2. Related Work
- 3. SeeKeR Model
-
- 3.1 Architecture and Pre-Training
- 3.2 SeeKeR Tasks for Dialogue
- 3.3 SeeKeR Tasks for Language Modeling
- 4. Code
Abstract
最近,语言模型(Language models, LMs)被证明通过将模块化与检索相结合来生成更多的事实响应。作者扩展了Adolphs等人最近的研究,引入了互联网搜索(internet search)作为一个模块。作者的SeeKeR(Search --> engine --> Knowledge --> Response)方法将单个LM连续应用于三个模块任务:search,生成knowledge,生成最终的response。作者表明,当使用SeeKeR作为对话模型时,在相同数量的参数下,它在基于知识的开放域对话(open-domain knowledge-grounded conversations)上的一致性、知识和扰动参与度方面优于最先进的BlenderBot 2模型。SeeKeR作为一种标准语言模型应用于主题提示补全,在真实性和主题性方面优于GPT2和GPT3,尽管GPT3是一个更大的模型。
1. Introduction
众所周知,标准的大型语言模型会生成通顺但事实上并不正确的语句,这一问题并不能通过增加它们的大小来解决。此外,由于他们的知识从训练开始就被冻结在时间上,他们永远无法学习新的事实——他们所掌握的最新信息将是从训练集构建之日起的。最近的一些进展试图解决这些问题。神经检索模型通过访问大型固定知识库增强了seq2seq模型。但是,聚合来自多个检索到的文档是一个难题,它可能导致将多个文档的部分合并到一个事实上并不正确的响应中。模块化方法已被证明有助于缓解这一问题,该方法首先找到文件的相关部分,然后生成最终响应。然而,这些方法都不能包含新的信息,这已经在单独的工作中进行了研究,通过互联网搜索增强了几代人的能力。
在本文中,作者探索了一种模块化架构,该架构试图将这些不同的现有解决方案的最佳元素混合在一起。单个transformer架构被迭代地用于执行三个模块化任务:搜索、生成知识和生成最终响应,其中每个模块的输出被作为额外的输入提供给下一个模块,如下图所示:
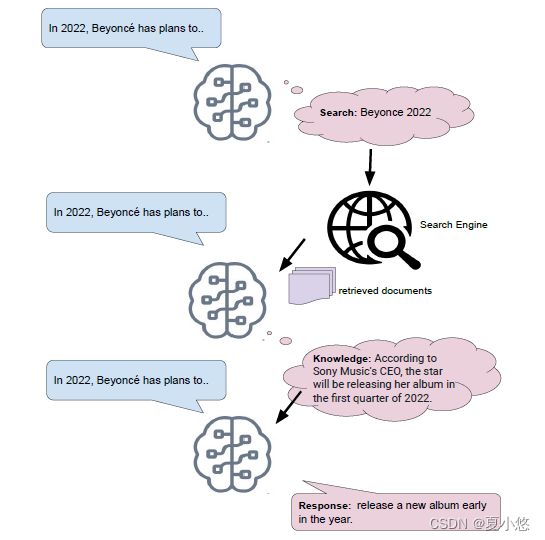
在给定输入上下文的情况下,第一步为互联网搜索引擎生成相关的搜索查询(Search),而第二步则提供返回的文档并生成它们最相关的部分(Knowledge),最后一步使用这些知识来产生其最终响应(Response)。通过将这个难题分解为三个可管理的步骤,相关的最新信息可以被纳入最终的语言模型生成中。
在各种知识密集型数据集上进行预训练和微调后,作者将模块化的语言模型(SeeKeR)应用于对话和快速补全的任务。在开放领域对话中,作者展示了根据人类对一致性(consistency)、知识(knowledge)和每回合参与度(per-turn engagingness)的评分,这种方法优于最先进的BlenderBot 2模型。
作者测试了SeeKeR执行通用且最新的语言建模的能力。为了做到这一点,作者对2022年1月新闻中的主题构建了主题提示,这是模型本身尚未经过训练的数据。根据人类评分者的说法,凭借SeeKeR通过网络搜索整合信息的能力,它在真实性和主题性方面优于GPT2和GPT3。
2. Related Work
作者的工作建立在知识-响应(knowledge to response, K2R)技术的基础上,该技术将对话模型分解为两个阶段:生成知识序列,然后生成以知识为条件的响应序列。这已成功应用于维基百科向导(Wizard of Wikipedia)、QA和LIGHT任务。作者通过添加额外的互联网搜索模块来扩展这种方法,然后将其应用于完全开放的领域对话和通用语言建模。
在对话空间中,与作者的方法最自然的比较是BlenderBot 2(BB2)。BB2以从互联网上检索开放领域对话任务为基础,但没有使用模块化方法来生成知识,而是应用融合解码器(fusion-in-decoder, FiD)方法直接在给定检索到的文档的情况下输出响应,但他们的方法可能存在以下问题:要么错误地将事实混淆在一起,要么生成忽略知识的通用响应,而作者的方法试图解决这些问题。最近使用信息检索的另一种方法是LaMDA,其中检索引擎返回相关信息(而不是一组文档),并被视为一个单独的黑匣子。LaMDA不是公开可用的,不能与之相比。WebGPT也将互联网搜索应用于QA任务,Lazaridou等人的工作也是如此,两者都不适用于对话或一般LM任务,而且这两项工作都不公开。
在语言建模领域,有大量关于最近邻(nearest neighbor)和基于缓存(cache-based)的语言建模的工作,用于访问大量文档。最近,RETRO对数万亿个token的数据库进行了检索。这些工作不使用互联网搜索,而是通过transformer模型和最近邻查找来执行自己的检索方法。由于数据库是固定的,这意味着它不会是最新的知识和时事。最近的一些方法也试图通过编辑和调整语言模型变体来调整知识。
3. SeeKeR Model
作者在本文中介绍的SeeKeR模型具有标准的transformer架构,不同的是,这个相同的encoder-decoder(用于对话)或decoder-only(用于语言建模)模型以模块化的方式多次使用。对于每个模块,在encoder(或decoder)中使用特殊的token来指示正在调用哪个模块。每个模块的输出与原始上下文一起输入到下一个模块中。
SeeKeR由三个模块组成,这些模块按顺序调用:
Search Module: 给定编码的输入上下文,将生成搜索查询。这被输入到搜索引擎中,搜索引擎以一组文档的形式返回结果。根据Komeili等人的研究,在作者的实验中,使用了Bing Web Search API来检索文档(除非另有说明),然后通过与Common Crawl相交来过滤该组文档,并保持top 5。
Knowledge Module: 给定编码的输入上下文和一组检索到的文档,就会生成知识响应。这包括检索到的文档中的一个或多个相关短语或句子。对于encoder-decoder模型,使用融合解码器(fusion-in-decoder, FiD)方法对文档和上下文进行编码;对于decoder-only模型,将文档打包并预处理到输入上下文中。需要注意的是,此任务本质上是一个"copy"任务,因此不必生成新的token;任务的难点在于选择要copy的相关知识。
Response Module: 给定与知识响应连接的编码输入上下文,生成最终响应。模块必须考虑相关的上下文和知识,同时为输入生成新的流畅延续。前面模块对相关知识的提取使这项任务更加容易;相反,传统的seq2seq模型必须同时解决所有这些任务(知识获取、合成和最终响应生成)。
3.1 Architecture and Pre-Training
对于标准语言建模实验,作者将GPT2 transformer视为基本模型,并将其微调为SeeKeR模型(见3.3小节);在这种情况下,作者不进行任何自己的预训练。因此,可以直接与具有相同模型大小和架构的GPT2进行比较。作者在实验中考虑了medium(345M)、large(762M)和XL(1.5B)参数量的模型。
对于作者的对话实验,使用了2.7B参数的transformer encoder-decoder模型。为了预训练作者的模型,考虑使用Lewis等人的训练方法,将两个不同的预训练数据集组合用于语言建模和对话:
pushshift.io Reddit: 作者使用了Reddit的变体,该变体也已用于现有的几项研究,特别是用于训练BlenderBot 1和BlenderBot 2。该设置需要进行训练以生成评论,该评论取决于导致评论的完整线程。根据Humau等人的研究,这是一个先前存在的Reddit数据集,由第三方提取和获得,并在pushshift.io上提供,涵盖了2019年7月从PushShift 获得的Reddit,共1.5B个训练样本,该数据集已经使用了许多启发式规则来过滤和清理。
RoBERTa+CC100en: 作者使用了用于训练BASE语言模型的相同数据,该模型由大约100B个token组成,将RoBERTa模型中使用的语料库与CC100语料库的英语子集相结合。
作者将仅在对话建模(pushshift.io Reddit)上的预训练与在语言建模和对话建模任务上的预训练进行了比较,并将后者这一方案称为R2C2(pushshift.io Reddit, RoBERTa+CC100en)。完整的细节,包括架构和预训练超参数,在附录B中进行了讨论。
We compare pre-training only on dialogue modeling(pushshift.io Reddit) to pre-training on both language modeling and dialogue modeling tasks; we refer to the latter as R2C2 (pushshift.io Reddit, RoBERTa + CC100en).
博主的理解:
在这项研究中,研究人员进行了两种不同的预训练方法的比较。第一种方法仅在对话建模任务上进行预训练,而第二种方法则在语言建模任务和对话建模任务上同时进行预训练。
预训练只在对话建模任务上的模型可以被称为"对话建模模型",它使用pushshift.io Reddit数据集作为预训练数据,并通过学习对话数据中的模式和结构来提高对话回应的生成能力。
而R2C2模型是一种结合了语言建模任务和对话建模任务的模型。它在pushshift.io Reddit数据集和CC100en数据集上进行预训练,使用RoBERTa模型作为基础模型。通过同时在两个任务上进行预训练,R2C2模型可以获得更广泛的语言知识,并具备更好的语言理解和生成能力。
这项研究的目的是比较仅在对话建模任务上进行预训练的模型与在语言建模和对话建模任务上同时进行预训练的R2C2模型之间的差异和性能表现,也是为了评估R2C2模型在对话生成方面的优势,并探讨多任务预训练对对话建模的影响。
3.2 SeeKeR Tasks for Dialogue
作者考虑了许多基于对话的微调任务,以使其模型能够在三个模块中的每一个模块中都表现良好。
Search Module Tasks: 作者使用了来自Wizard of Internet(WizInt)任务的数据,该任务由8614个训练对话组成,其中包含42306个给定对话上下文的人工编写的相关搜索查询。可以使用搜索查询数据作为目标,以监督的方式直接训练搜索模块。通过预测相关的搜索查询,在输入上下文中添加特殊的token,以表示transformer正在执行搜索任务。
Knowledge Module Tasks: 作者对几个知识密集型的NLP任务进行多任务处理,其中模型的目标是生成用于最终响应的knowledge。首先使用基于知识的对话数据集,其中包含所用黄金知识(gold knowledge)的注释:Wizard of Internet(WizInt)和Wizard of Wikipedia(WoW);然后,使用各种QA任务:SQuAD、TriviaQA、Natural Questions(NQ)和MS MARCO。作者使用MS MARCO的"Natural Language Generation"竞赛赛道(NLGen v2.1),在该赛道上,注释者(annotator)必须"provide your answer in a way in which it could be read from a smart speaker and make sense without any additional context"。因此,原始目标与其中一个输入文档没有直接重叠,可以通过找到与答案重叠程度最高的输入句子来修改任务以满足这一约束,并将其作为目标。如果F1重叠小于0.5,则可以放弃该样本,从原始的808731个样本中留下281658个。对于NQ,作者使用三种不同的设置:将所有文档作为输入,仅使用黄金文档,并使用采样的对话历史上下文。最后,也可以在该设置中使用传统的对话任务:PersonaChat,Empathetic Dialogues (ED)和Blended Skill Talk (BST),使用与中相同的程序:从同样出现在上下文中的原始对话响应中提取一个实体,并将其设置为训练的知识目标。作者还使用了Multi-Session Chat (MSC)任务,使用与MS MARCO相同的方法来预测与原始目标最相似的前一行(具有相同的F1重叠阈值),并将其设置为知识目标。
Response Module Tasks: 作者也将知识任务的子集用于响应任务,但具有修改的输入和目标。在这种情况下,输入上下文包含通常的对话,连接到黄金知识响应(上一个任务中的目标),周围环绕着特殊的token。新的目标是来自原始数据集的标准对话响应。例如,在MS MARCO的情况下,这涉及到从检索到的文档中的输入问题和最接近的句子到原始数据集中的实际答案的映射。请注意,虽然我们可以使用MS MARCO任务(因为我们可以访问长形式的会话响应),但我们将SQuAD、TriviaQA和NQ排除在响应建模之外,因为它们通常都包含短形式的答案。我们还使用了基于知识的对话任务(维基百科的向导和互联网的向导),因为每个对话响应都附有编写它所需的相关知识。对于PersonaChat、ED和BST,可以使用原始响应作为目标,但作者还将在知识任务构建过程中计算的黄金知识实体连接到上下文中。
作者在附录C中提供了进一步的细节,包括数据集大小。
3.3 SeeKeR Tasks for Language Modeling
Search Module Tasks: 由于无法像访问对话那样访问用于语言建模的人工策划的搜索查询数据集,因此在这种情况下,作者基于预测文档标题来构建任务。使用Common Crawl数据集,给定的输入示例是单个web文档,在任意点随机剪切该文档,并且只保留开头(以便对从左到右的生成进行建模)。作者想要生成的目标输出是文档的标题,还通过删除括号中的短语或连字符来启发式地简化文档,以使学习到的查询术语更通用。作者用这个任务的另一个变体进行多任务:对于给定的目标句子,预测其相应的“知识”句子的文档标题。最后,还将多任务与向导的互联网搜索查询任务进行了比较,如3.2小节所述。
Knowledge Module Task: 为了构建这样的知识任务,作者还从Common Crawl数据集开始,将其分解为句子。在Common Crawl上构造了一个Lucene搜索引擎,然后,对于文档的给定目标语句,找到与目标最相似的语句,该语句既不相同,也不在同一文档中。跳过少于5个单词或与F1重叠少于0.33的句子,和上面的一致。在训练过程中,仅限于知识和目标延续具有共享实体的示例。因此,作者构建了一个任务——除了输入文档之外,还提供了包含检索到的判决的文档——以模拟搜索检索设置,目标是检索到的句子。
Response Module Task: 响应任务的构造与知识任务类似,只是输入只是通常的语言建模上下文加上知识句子(由特殊的标记包围)。目标是下一个句子(token)。
4. Code
https://parl.ai/projects/seeker/