随笔小记(十九)
binascii.hex函数和hexlify函数
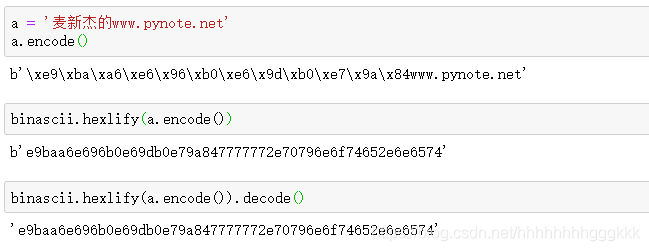
binascii模块也在python的标准库中,hexlify就是十六进制化的意思。据python官方说,binascii模块比较底层,但是速度很快,效果跟bytes.hex一样。
如果是字符串,可以使用这个函数,弥补了hex函数只能对int型数据计算的遗憾。如果不是ascii字符串,而是unicode字符串呢?同样,用encode()函数先转换成byte对象,然后调用此函数。

 参考链接:https://www.pynote.net/archives/1628
参考链接:https://www.pynote.net/archives/1628
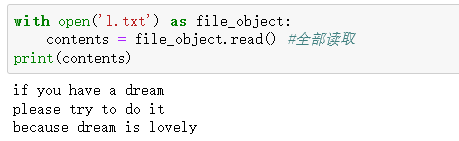
打开并读取文件
使用with则不用再file.close()。


Pyton3获得文件的大小(字节)os.path.getsize

交叉验证在sklearn中的实现
1、实现CV最简单的方法是cross_validation.cross_val_score函数,该函数接受某个estimator,数据集,对应的类标号,k-fold的数目,返回k-fold个score,对应每次的评价分数。
注:
cross_val_score中的参数cv,既可以给定它一个整数,表示数据集被划分的份数(此时采取的是KFold或者StratifiedKFold策略,后面会说明);也可以给定它一个CV迭代策略生成器,指定不同的CV方法。
2、几种不同的CV策略生成器
前面提到,cross_val_score中的参数cv可以接受不同的CV策略生成器作为参数,以此使用不同的CV算法。这里介绍几种sklearn中的CV策略生成器函数。
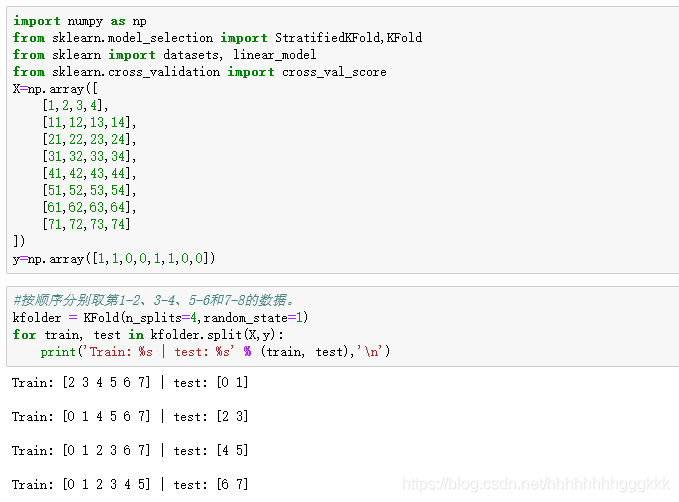
(1)K-fold
(2)Stratified k-fold
(3) Leave-one-out:参数只有一个,即样本数目。等等。

参考链接:
http://blog.sina.com.cn/s/blog_7103b28a0102w70h.html
python sklearn中KFold与StratifiedKFold
首先这两个函数都是sklearn模块中的,在应用之前应该导入:
from sklearn.model_selection import StratifiedKFold,KFold
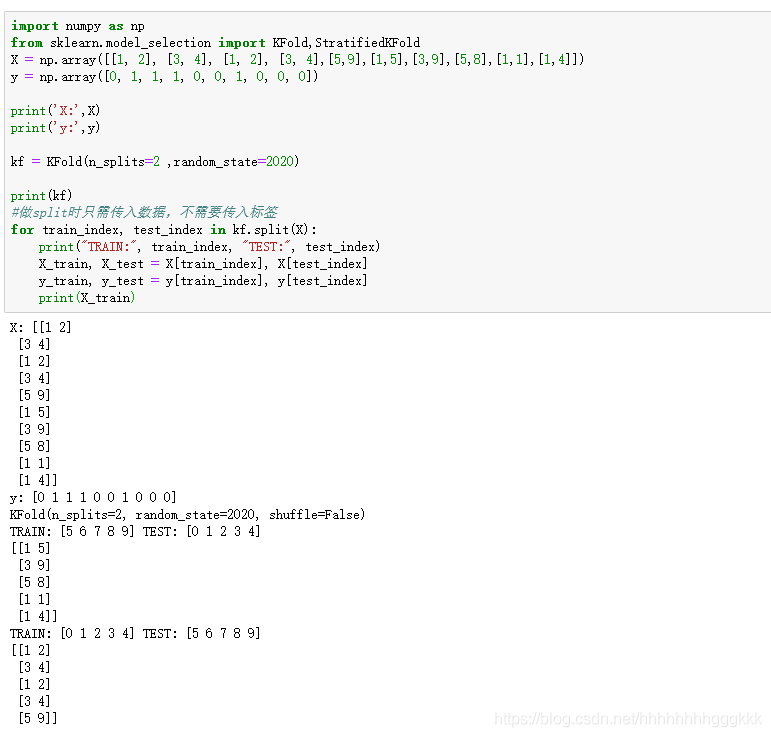
首先说一下两者的区别,StratifiedKFold函数采用分层划分的方法(分层随机抽样思想),验证集中不同类别占比与原始样本的比例保持一致,故StratifiedKFold在做划分的时候需要传入标签特征。
1、KFold函数
KFold函数共有三个参数:
n_splits:默认为3,表示将数据划分为多少份,即k折交叉验证中的k;
shuffle:默认为False,表示是否需要打乱顺序,这个参数在很多的函数中都会涉及,如果设置为True,则会先打乱顺序再做划分,如果为False,会直接按照顺序做划分;
random_state:默认为None,表示随机数的种子,只有当shuffle设置为True的时候才会生效。
 2、StratifiedKFold
2、StratifiedKFold
StratifiedKFold函数的参数与KFold相同。
 参考链接:
参考链接:
https://zhuanlan.zhihu.com/p/150446294