Spark:Core(三)
目录
01:上篇回顾
02:学习目标
03:外部数据源:场景
04:外部数据源:写Hbase
05:外部数据源:读Hbase
06:外部数据源:写MySQL
07:广播变量:Broadcast Variables
08:累加器:Accumulators
09:内核调度:宽窄依赖
10:内核调度:Shuffle
11:内核调度:基本概念
12:内核调度:调度流程
13:内核调度:并行度
14:SparkCore中的问题
15:SparkSQL的诞生与发展
16:功能特点与应用场景
17:DSL实现WordCount
18:SQL实现WordCount
附录一:Spark Maven依赖
01:上篇回顾
https://blog.csdn.net/m0_57498038/article/details/119106044
-
RDD的创建方式有几种?
-
方式一:并行化一个已存在的集合
sc.parallize / sc.makeRDD -
方式二:读取外部存储系统
sc.textFile/sc.wholeTextFile/sc.newAPIHadoopRDD
-
-
RDD的算子分为几类,有什么区别?
-
Transformation :转换算子
-
不会触发job以及Task的运行,Lazy模式设计
-
返回值:RDD类型
-
-
Action:触发算子
-
会触发job以及Task的运行,数据的使用
-
返回值:非RDD类型
-
-
-
常用的RDD函数有哪些?
-
基本函数:map、flatMap、filter、take、top、foreach
-
分区操作函数:xxxxPartition
-
函数:mapPartitions,foreachPartition
-
功能:对RDD的每个分区调用参数函数进行处理
-
场景:基于分区的资源构建
-
-
重分区函数
-
函数:repartition、coalesce
-
功能:调整RDD的分区个数,返回一个新的RDD
-
区别
-
repartition:用于调大分区个数,必须经过shuffle
-
coalesce(分区个数,是否经过shuffle:false):用于调小分区个数
-
-
-
聚合函数
-
函数
-
reduce:分区内聚合和分区间聚合逻辑一致,没有初始值
-
fold:分区内聚合和分区间聚合逻辑一致,有初始值
-
aggregate:分区内聚合和分区间聚合逻辑可以自定义,有初始值
-
-
功能:实现分布式的聚合
-
-
PairRDD函数
-
函数:xxxxxByKey
-
reduceByKey:按照key分组,使用reduce聚合
-
aggregateByKey:按照key分区,使用aggregate聚合
-
|
-
底层:combinerByKey:先分区内聚合,再分区间聚合
-
groupByKey:按照key进行分组
-
将所有数据放在一起以后再统一分组
-
-
sortByKey:按照Key实现排序
-
-
关联函数:Join
-
rdd1:KV
-
rdd2:KW
-
rdd1.join(rdd2) = RDD:[K,(V,W)]
-
-
-
-
RDD的数据,怎么保证安全性?
-
血链机制:通过依赖关系来恢复RDD的数据
-
-
RDD的persist机制是什么?
-
功能:将RDD缓存在Executor中内存或者磁盘中,避免RDD的重复构建
-
函数:persist、cache、unpersist
-
级别
-
磁盘
-
内存
-
优先内存,内存不足再存磁盘
-
-
-
RDD的checkpoint是什么?
-
功能:将RDD的数据持久化存储在HDFS
-
应用:非常重要的RDD或者数据量非常大
-
函数
-
设置检查点目录:sc.setCheckpointDir
-
设置检查点:rdd.checkpoint
-
-
-
persist与checkpoint的区别是什么?
-
存活周期
-
persist:主从释放:unpersist
-
checkpoint:手动删除
-
-
数据内容
-
persist:RDD
-
checkpoint:RDD数据
-
-
-
疑问整理
-
persist保存血脉关系不太懂。没有persist,走的血脉来恢复RDD。有了persist,可以直接在缓存拿RDD,不走血脉。如果缓存的数据没了,那RDD保存的血脉关系不也跟着没了。没有领会到这保存血脉的作用
-
persist是缓存数据的,task结束缓存就会删除,在没有设置缓存的情况下,数据会进行缓存吗?
-
不会
-
-
在stage中,左边运行过的repartition在程序运行一次后再次运行就会变成灰色的,相当于直接拿到了原来运行过的数据,这个过程属于缓存吗?
-
不属于:属于shuffle的磁盘数据
-
设计:为了避免重复运行相同Stage
-
-
02:学习目标
-
SparkCore
-
外部数据源:读写Hbase、MySQL
-
共享变量:广播变量、累加器
-
内核调度
-
宽窄依赖
-
Shuffle
-
基本概念、调度流程:Master、Worker、Driver、Executor、Application、Job、Stage、Task
-
并行度
-
-
-
SparkSQL
-
基本设计
-
功能、特点、应用场景
-
基本使用
-
03:外部数据源:场景
-
目标:了解SparkCore读写外部数据源的应用场景
-
实施
-
原始数据
-
HDFS、Hbase
-
-
数据处理
-
SparkCore
-
-
结果存储
-
HDFS、Hbase、MySQL
-
-
SparkCore的数据源接口
-
parallelize / makeRDD:将一个Scala中的集合转换为一个RDD对象
-
textFile / wholeTextFiles:读取外部文件系统的数据转换为一个RDD对象
-
newAPIHadoopRDD / newAPIHadoopFile:调用Hadoop的InputFormat来读取数据转换为一个RDD对象
-
-
-
小结
-
了解SparkCore读写外部数据源的应用场景
-
04:外部数据源:写Hbase
-
目标:掌握SparkCore如何写入数据到Hbase
-
路径
-
step1:MR写Hbase的原理
-
step2:Spark写Hbase实现
-
-
实施
-
MR写Hbase的原理
-
MR:OutputFormat:TableOutputFormat
-
要求:输出的Value类型必须为Put类型
-
-
Spark写Hbase实现
-
需求:将Wordcount的结果写入hbase
-
表:htb_wordcount
-
列族:info
-
rowkey:单词
-
列名:cnt
-
值:单词出现的次数
-
-
启动HBASE
start-dfs.sh zookeeper-daemons.sh start start-hbase.sh hbase shell -
创建表
create 'htb_wordcount','info' -
开发
package bigdata.spark.core.hbase import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.io.ImmutableBytesWritable import org.apache.hadoop.hbase.mapreduce.TableOutputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreWriteToHbase * @Description TODO SparkCore 实现写入数据到Hbase */ object SparkCoreWriteToHbase { def main(args: Array[String]): Unit = { //todo:1-构建SparkContext对象 val sc:SparkContext = { //构建SparkConf配置管理对象,类似于Hadoop中的Configuration对象 val conf = new SparkConf() .setMaster("local[2]")//指定运行模式 .setAppName(this.getClass.getSimpleName.stripSuffix("$"))//指定运行程序名称 // .set("key","value") //指定额外的属性 //返回SparkContext对象 SparkContext.getOrCreate(conf) } //调整日志级别 sc.setLogLevel("WARN") //todo:2-实现数据的转换处理 //step1:读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(s"总行数=${inputRdd.count()}") // println(s"第一行=${inputRdd.first()}") //step2:处理数据 val wcRdd: RDD[(String, Int)] = inputRdd .filter(line => line != null && line.trim.length > 0)//过滤 .flatMap(line => line.trim.split("\\s+")) //将每个单词提取 .map(word => (word,1)) //构建二元组keyvalue .reduceByKey((tmp,item) => tmp+item) //按照key进行分组聚合 //step3:保存结果 wcRdd.foreach(println)//打印 // wcRdd.saveAsTextFile("datas")//写入HDFS //写入Hbase /** * def saveAsNewAPIHadoopFile( * path: String, 临时目录 * keyClass: Class[_], Key的类型 * valueClass: Class[_], Value的类型 * outputFormatClass: Class[_ <: NewOutputFormat[_, _]], 输出类 * conf: Configuration = self.context.hadoopConfiguration) Hadoop的配置对象 */ //构建一个写入Hbase的配置对象 val configuration = HBaseConfiguration.create() // 设置连接Zookeeper属性 configuration.set("hbase.zookeeper.quorum", "node1.itcast.cn") configuration.set("hbase.zookeeper.property.clientPort", "2181") configuration.set("zookeeper.znode.parent", "/hbase") // 设置将数据保存的HBase表的名称 configuration.set(TableOutputFormat.OUTPUT_TABLE, "htb_wordcount") //将RDD的数据类型进行转换 val putRdd = wcRdd .map(tuple => { //指定返回的Key为rowkey【单词】:ImmutableBytesWritable val rowkey = new ImmutableBytesWritable(Bytes.toBytes(tuple._1)) //构建put对象 val put = new Put(rowkey.get()) //添加列 put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("cnt"),Bytes.toBytes(tuple._2.toString)) //返回KV (rowkey,put) }) putRdd.saveAsNewAPIHadoopFile( "datas/sparkcore/tmp",//设置一个程序的临时目录 classOf[ImmutableBytesWritable], classOf[Put], classOf[TableOutputFormat[ImmutableBytesWritable]], configuration ) //todo:3-释放SparkContext对象 Thread.sleep(1000000000000000L) sc.stop() } }
-
-
-
小结
-
掌握SparkCore如何写入数据到Hbase
-
05:外部数据源:读Hbase
-
目标:掌握SparkCore如何从Hbase中读取数据
-
路径
-
step1:MR读取Hbase原理
-
step2:Spark读Hbase实现
-
step3:序列化问题
-
-
实施
-
MR读取Hbase原理
-
MR:InputFormat:TableInputFormat
-
功能一:分片:一个Hbase的region对应一个分片
-
功能二:转换KV
-
K:Rowkey:ImmutableBytesWritable
-
V:Rowkey数据:Result
-
-
-
-
Spark读Hbase实现
// 设置连接Zookeeper属性 configuration.set("hbase.zookeeper.quorum", "node1") configuration.set("hbase.zookeeper.property.clientPort", "2181") configuration.set("zookeeper.znode.parent", "/hbase") // 设置读取哪张Hbase的表 configuration.set(TableInputFormat.INPUT_TABLE, "htb_wordcount") -

-
序列化问题
-
报错
-

-
原因:Spark中需要单独配置序列化机制
-
解决
// TODO: 设置使用Kryo 序列化方式 .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // TODO: 注册序列化的数据类型 .registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result]))
-
-
-
小结
-
掌握SparkCore如何从Hbase中读取数据
-
06:外部数据源:写MySQL
-
目标:掌握SparkCore如何将数据写入MySQL
-
路径
-
step1:需求
-
step2:实现
-
-
实施
-
需求
-
读MySQL:目前主要通过SparkSQL来实现
-
写MySQL:将分析的结果进行保存
-
-
实现
-
MySQL中建表
-
登录MySQL:node1
mysql -uroot -p -
建表
USE db_test ; drop table if exists `tb_wordcount`; CREATE TABLE `tb_wordcount` ( `word` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL, `count` varchar(100) NOT NULL, PRIMARY KEY (`word`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ; -
JDBC
jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true
-
-
代码实现
package bigdata.spark.core.mysql import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName SparkCoreWriteToMySQL * @Description TODO SparkCore 实现词频统计,结果保存到MySQL中 */ object SparkCoreWriteToMySQL { /** * 实现将数据写入MySQL * @param part:每个分区 */ def saveToMySQL(part: Iterator[(String, Int)]): Unit = { //step1:申明驱动类,构建对象 Class.forName("com.mysql.jdbc.Driver") //连接对象 var conn:Connection = null //SQL对象 var pstm:PreparedStatement = null try{ //获取连接 conn = DriverManager.getConnection("jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", "root","123456") //构建SQL val sql = "replace into db_test.tb_wordcount values(?,?)" //构建SQL对象 pstm = conn.prepareStatement(sql) //赋值 part.foreach{ case (word,cnt) => { pstm.setString(1,word) pstm.setString(2,cnt.toString) //放入批次 pstm.addBatch() } } //执行批次 pstm.executeBatch() }catch { case e:Exception => e.printStackTrace() }finally { //资源释放 if(pstm!=null) pstm.close() if(conn!=null) conn.close() } } def main(args: Array[String]): Unit = { //todo:1-构建SparkContext对象 val sc:SparkContext = { //构建SparkConf配置管理对象,类似于Hadoop中的Configuration对象 val conf = new SparkConf() .setMaster("local[2]")//指定运行模式 .setAppName(this.getClass.getSimpleName.stripSuffix("$"))//指定运行程序名称 // .set("key","value") //指定额外的属性 //返回SparkContext对象 SparkContext.getOrCreate(conf) } //调整日志级别 sc.setLogLevel("WARN") //todo:2-实现数据的转换处理 //step1:读取数据 val inputRdd: RDD[String] = sc.textFile("datas/wordcount/wordcount.data") // println(s"总行数=${inputRdd.count()}") // println(s"第一行=${inputRdd.first()}") //step2:处理数据 val wcRdd: RDD[(String, Int)] = inputRdd .filter(line => line != null && line.trim.length > 0)//过滤 .flatMap(line => line.trim.split("\\s+")) //将每个单词提取 .map(word => (word,1)) //构建二元组keyvalue .reduceByKey((tmp,item) => tmp+item) //按照key进行分组聚合 //step3:保存结果 wcRdd.foreach(println) // wcRdd.saveAsTextFile("datas/output/wc-"+System.currentTimeMillis()) //将数据写入MySQL中 wcRdd .coalesce(1) //数据量小,降低为1个分区 .foreachPartition(part => saveToMySQL(part)) //每个分区调用一次写入MySQL //todo:3-释放SparkContext对象 Thread.sleep(1000000000L) sc.stop() } }
-
-
-
小结
-
掌握SparkCore如何将数据写入MySQL
-
07:广播变量:Broadcast Variables
-
目标:掌握SparkCore中广播变量的功能与应用
-
路径
-
step1:功能
-
step2:测试
-
-
实施
-
共享变量:share var
-
广播变量
-
-
累加器
-
功能
-
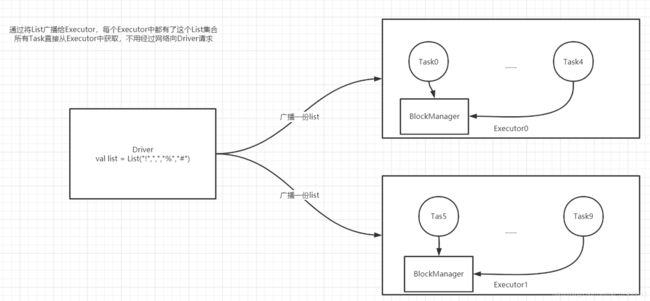
可以将Driver中的一个变量通过广播的形式发送给Executor,将这个变量放在Executor中
-
减少数据在网络中的IO,提高性能
-
-
测试
-
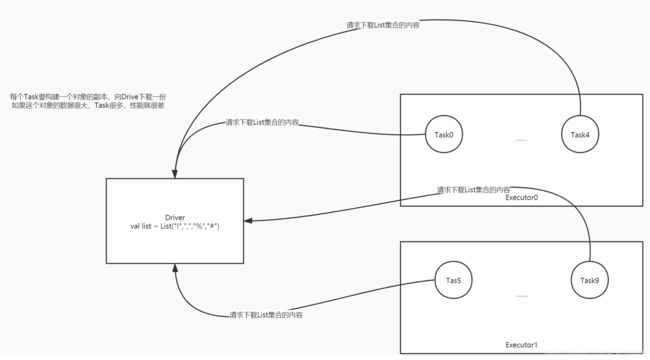
需求:做Wordcount,过滤符号,只保留单词,统计每个单词出现的次数
-
常规:直接定义一个符号的集合,在每个Task中做过滤
-
-
广播变量
-
-
代码
//符号的集合 val list = List("!",",","%","#") //实现广播:构建一个广播变量 val broad = sc.broadcast(list) val rsRdd: RDD[(String, Int)] = inputRdd //过滤空行 .filter(line => line != null && line.trim.length > 0) //取出每个单词 .flatMap(line => line.trim.split(" ")) //将符号过滤掉 .filter(word => { //从各自的广播变量中将数据获取出来 val value = broad.value !value.contains(word) && word.trim.length >0 }) //转换为二元组 .map(word => (word,1)) //分组聚合 .reduceByKey((temp,item) => temp+item)
-
-
-
小结
-
掌握SparkCore中广播变量的功能与应用
-
08:累加器:Accumulators
-
目标:掌握SparkCore中累加器的功能与应用
-
路径
-
step1:功能
-
step2:测试
-
-
实施
-
功能
-
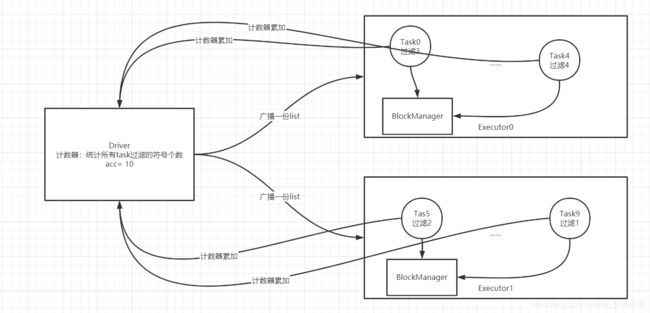
实现分布式计数:一般用于结果计数或者日志调试
-
每个分区内部计数
-
再将每个分区的结果进行累加
-
-
-
测试
-
做Wordcount,过滤符号,只保留单词,统计每个单词出现的次数,以及统计符号的个数
-
-
package bigdata.spark.core.share import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * @ClassName WordCountShareVariable * @Description TODO 实现自定义开发Wordcount程序,使用广播变量,过滤单词,并使用累加器统计符号的个数 * */ object WordCountShareVariable { def main(args: Array[String]): Unit = { /** * step1:初始化Driver对象,SparkContext */ //构建一个配置管理对象,类似于以前学的Configuration对象 val conf = new SparkConf() //以当前的类名作为程序的名称 .setAppName(this.getClass.getSimpleName.stripSuffix("$")) //配置本地模式运行 .setMaster("local[2]") // .set("fs.defaultFS","hdfs://node1:8020") //构建SparkContext对象 val sc = new SparkContext(conf) //调整日志级别 sc.setLogLevel("WARN") /** * step2:读取、转换、保存 */ //todo:1-读取数据 val inputRdd = sc.textFile("datas/filter/datas.input") // println(s"count = ${inputRdd.count()}") //符号的集合 val list = List("!",",","%","#") //实现广播:构建一个广播变量 val broad = sc.broadcast(list) //构建一个累加器,统计所有符号的个数 val acccnt = sc.longAccumulator("acccnt") //todo:2-处理数据 val rsRdd: RDD[(String, Int)] = inputRdd //过滤空行 .filter(line => line != null && line.trim.length > 0) //取出每个单词 .flatMap(line => line.trim.split(" ")) //将符号过滤掉 .filter(word => { //从各自的广播变量中将数据获取出来 val value = broad.value //符号出现一次,就累加计数一次 if(value.contains(word)) acccnt.add(1L) !value.contains(word) && word.trim.length >0 }) //转换为二元组 .map(word => (word,1)) //分组聚合 .reduceByKey((temp,item) => temp+item) //todo:3-保存结果 rsRdd.foreach(println) println(s"符号的个数:${acccnt.value}") /** * step3:释放资源 */ Thread.sleep(10000000L) sc.stop() } }
-
-
-
小结
-
掌握SparkCore中累加器的功能与应用
-
09:内核调度:宽窄依赖
-
目标:掌握SparkCore中的宽窄依赖的概念及设计
-
路径
-
step1:宽依赖
-
step2:窄依赖
-
step3:设计
-
-
实施
-
宽依赖
-
定义:如果父RDD的一个分区数据给了子RDD的多个分区,就是宽依赖
-
也叫作shuffle依赖,是划分stage的依据,每个Stage由独立的Task来完成
-
stage1:task0和task1负责计算,将计算的结果写入HDFS
-
stage2:task2和task3负责计算,从HDFS中读取上一步Task的结果
-

-
-
-
窄依赖
-
定义:如果父RDD的一个分区数据只给了子RDD的一个分区,就是窄依赖
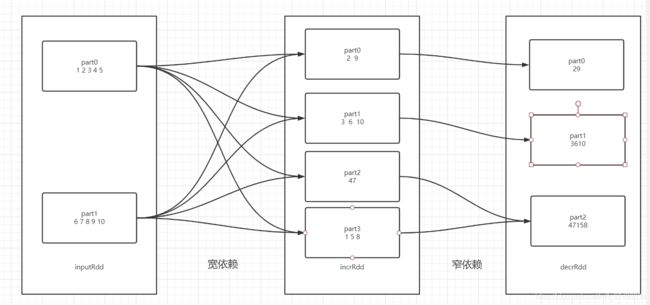
-
-
设计:为什么要有宽窄依赖之分?
-
从性能的角度来考虑:有些不得已需要经过shuffle就用宽依赖,如果不需要经过shuffle就能完成使用窄依赖
-
从数据血脉恢复角度来说
-
如果宽依赖:子RDD某个分区的数据丢失,必须重新计算整个父RDD的所有分区
-
如果窄依赖:子RDD某个分区的数据丢失,只需要计算父RDD对应分区的数据即可
-
-
-
-
小结
-
什么是宽窄依赖?
-
宽依赖:父RDD的一个分区的数据给了子RDD的多个分区,一对多
-
产生Shuffle,如果子RDD的某个分区数据丢失,必须重构父RDD的所有分区
-
-
窄依赖:父RDD的一个分区的数据给了子RDD的一个分区,一对一
-
不产生Shuffle,如果子RDD的某个分区数据丢失,重构父RDD的对应分区
-
-
-
10:内核调度:Shuffle
-
目标:掌握SparkCore中的Shuffle设计
-
路径
-
step1:Shuffle的功能
-
step2:Spark Shuffle的发展
-
step3:Spark Shuffle的设计
-
-
实施
-
Shuffle的功能
-
实现全局排序、分组、分区
-
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。
-
Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等。

-
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步。
-
Stage划分为两种类型
-
ShuffleMapStage,在Spark 1个Job中,除了最后一个Stage之外,其他所有的Stage都是此类型-
将Shuffle数据写入到本地磁盘,ShuffleWriter
-
在此Stage中,所有的Task称为:ShuffleMapTask
-
-
ResultStage,在Spark的1个Job中,最后一个Stage,对结果RDD进行操作-
会读取前一个Stage中数据,ShuffleReader
-
在此Stage中,所有的Task任务称为ResultTask。
-

-
-
-
Spark Shuffle的发展
-
Spark在1.1以前的版本一直是采用Hash Shuffle的实现的方式
-
到1.1版本时参考HadoopMapReduce的实现开始引入Sort Shuffle
-
在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用
-
在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式
-
到的2.0版本,Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。
-
-
Spark Shuffle的设计
-
Sort Shuffle的过程与MR中的Shuffle过程一致
-
-
-
小结
-
掌握SparkCore中的Shuffle设计
-
11:内核调度:基本概念
-
目标:掌握SparkCore中内核调度的基本概念
-
实施

-
Application:用户开发的Spark应用程序,每个Spark程序包含了一个Driver进程和多个Executor进程在集群中
-
每个程序的Driver和Executor都是独立的,不是共享的
-
-
Application jar:将开发好的程序打成jar包,提交集群运行,jar包中不能包含hadoop和spark的依赖jar包
-
Job:触发真正执行程序的单元,由触发函数来触发job的构建
-
一个Application中可以有多个job
-
-
Stage:将一个Job中根据是否产生宽依赖来划分Stage【阶段:逻辑计划】
-
算法:回溯算法
-
对于整个程序来说,Stage是Application全局编号的每个阶段,为了实现不同job之间stage的结果共享
-
-
TaskSet:每个Stage会转换为一个TaskSet【物理计划】,Task的集合
-
每个TaskSet中可以多个Task:Stage中的RDD的最大分区数
-
-
Task:物理任务,每个分区对应一个Task任务来执行
-
Task由Driver中的组件进行分配运行在Executor中,使用Executor中的资源来源
-
每个Task使用1Core来完成运行
-
-
Driver:初始化进程,负责运行main方法,创建SparkContext对象
-
申请资源:启动Executor
-
解析、调度、监控Task
-
-
Executor:执行进程,运行在Worker节点上,使用Worker分配的资源负责执行Task
-
ClusterManager:分布式资源管理平台的主节点
-
Standalone:Master
-
YARN:RM
-
-
Worker Node:分布式资源管理平台的从节点
-
Standalone:Worker
-
YARN:NM
-
-
deploymode:决定了driver进程运行的位置,client【客户端】、cluster【Worker节点上】
-
-
小结
-
掌握SparkCore中内核调度的基本概念
-
12:内核调度:调度流程
-
目标:掌握SparkCore内核调度的调度流程
-
路径
-
step1:集群启动
-
step2:提交程序
-
step3:运行程序
-
-
实施
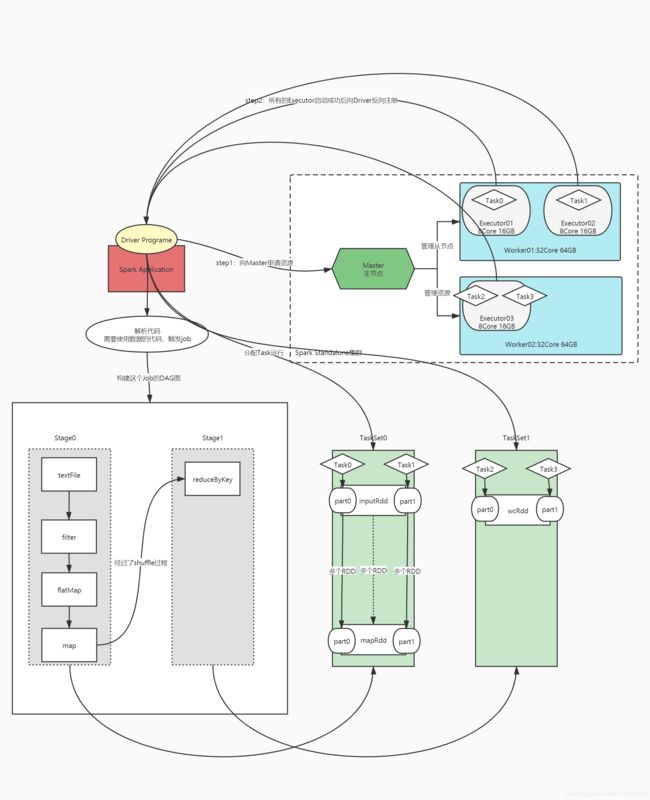
-
集群启动
-
主:Master:管理节点
-
接受客户端请求
-
管理从节点Worker节点
-
资源管理
-
-
从:Worker:计算节点
-
使用自己所在节点的资源运行Executor进程:给每个Executor分配一定的资源
-
-
-
提交程序
-
Driver进程
-
由spark-submit脚本客户端进行启动
-
向主节点申请Executor资源,让主节点在从节点上根据需求配置启动对应的Executor
-
解析代码逻辑:将代码中的逻辑转换为Task
-
如果遇到RDD中的数据的使用:构建一个Job,触发Task的运行
-
-
将Task分配给Executor去运行
-
监控每个Executor运行的Task状态
-
-
Executor进程
-
运行在Worker上,使用Worker分配的资源等待运行Task
-
所有Executor启动成功以后会向Driver进行注册
-
Executor收到分配Task任务,运行Task
-
-
-
运行程序
-
Driver开始解析Main方法开始的代码
-
代码中出现RDD数据的使用,就会触发job
-
job触发后,DAGScheduler组件通过回溯算法对RDD的转换构建DAG图,以Shuffle划分Stage
-
-
DAGScheduler:专门负责构建DAG,对象封装在SparkContext
-
根据DAG从编号最小的Stage开始,转换为TaskSet
-
每一个Stage会转换为一个TaskSet集合,TaskSet集合中会有多个Task
-
TaskScheduler:负责调度TaskSet中Task,对象封装在SparkContext,将每个Task提交给TaskManager
-
TaskManager:负责将每个Task分配给Executor运行
-
-
Driver将TaskSet中的Task分配调度到Executor中执行
-
-
-
小结
-
掌握SparkCore内核调度的调度流程
-
13:内核调度:并行度
-
目标:了解SparkCore内核调度中的并行度
-
实施
-
资源并行度:Executor的个数怎么决定?
-
原则:充分利用当前机器所有资源
-
假设:机器10台,每台16core,32GB,现在只运行一个程序,让这个程序得到所有资源
-
CPU核数:每个Executor至少给定2Core,保证Executor中可以并行
-
内存大小:给CPU核数的2倍
-
-
数据并行度:Task的个数怎么决定?
-
原则:Task个数由分区数决定,建议Task个数为整个Executor使用的CPU核数的2 ~ 3倍
-
假设:启动了10个Executor,每个Executor2Core4GB
-
总CPU:20个
-
建议:Task和分区数 = 40 ~ 60
-
-
-
-
小结
-
了解SparkCore内核调度中的并行度
-
14:SparkCore中的问题
-
目标:了解SparkCore中的问题
-
实施
-
问题:在大数据业务场景中,经常处理结构化的数据,数据来源往往是一些结构化数据,结构化的文件,对于结构化的数据处理最方便的开发接口就是SQL接口
-
SparkCore类似于MapReduce的编程方式,写代码,打成jar包,提交运行
-
-
构建对象实例RDD,调用函数来处理
-
SparkCore处理结构化的数据非常不方便
-
举个栗子:有一个文件:员工信息
ename age sal deptno-
SparkCore计算方式
-
step1:读取数据
-
RDD【String】:分布式集合【数据】
-
每个员工的信息变成一个String对象
-
-
-
step2:处理数据:统计每个部门的人数
-
对RDD而言,只知道这一条数据的内容
-
每次操作都需要对每条数据分割
rdd.map(record => { val arr = record.split val ename = arr(0) …… Class(arr(0),arr(1),arr(2),arr(3)) })
-
-
如果能实现将数据读取到Spark程序中,变成一张表
-
step1:读取数据
-
分布式表:数据 + schema【字段名称、字段类型】
ename age sal deptno
-
-
step2:处理数据,使用SQL处理数据
select deptno,count(*) from table group by deptno;
-
-
-
-
小结
-
了解SparkCore中的问题
-
15:SparkSQL的诞生与发展
-
目标:了解SparkSQL的诞生与发展
-
实施
-
问题:Spark只能通过普通代码编程的方式来使用,对于统计分析的需求不是特别的友好
-
类似于当年MapReduce的使用,mapreduce使用不是很友好,出现Hive
-
-
解决:一群大数据开发者,将Hive源码直接独立出来,将底层解析成MapReduce的代码替换成解析变成SparkCore
-
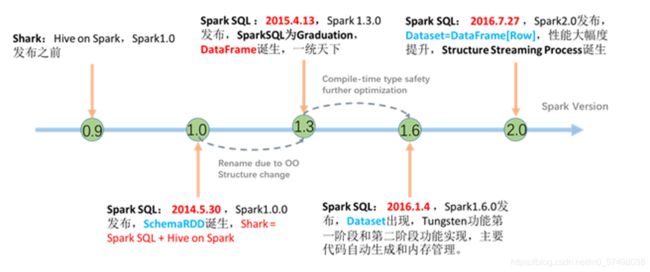
Shark:将SQL解析为SparkCore程序
-
-
Spark1.0:DB团队将Shark集成到了Spark软件中,更名为SparkSQL
-
SchemaRDD:RDD + Schema
-
-
Spark1.3:参考Python的数据结构实现
-
DataFrame
-
-
Spark1.6:参考FLink设计
-
DataSet
-
-
Spark2.0:将DF作为DS的一种特殊形式,只保留了DataSet数据结构
-
-
小结
-
了解SparkSQL的诞生与发展
-
16:功能特点与应用场景
-
目标:掌握SparkSQL的功能特点与应用场景
-
路径
-
step1:定义
-
step2:功能
-
step3:特点
-
step4:应用
-
-
实施
-
定义

-
SparkSQL是Spark中专门为结构化数据计算的模块,基于SparkCore之上
-
-
功能
-
提供SQL和DSL开发接口,将SQL或者DSL语句转换为SparkCore程序,实现结构化的数据处理
对比 SparkCore SparkSQL 开发接口 RDD的函数式编程 SQL / DSL【类似于函数式编程】 数据结构 RDD DataSet/DataFrame 理解 分布式数据集合【数据】 分布式表【数据 + Schema】 驱动接口Driver SparkContext SparkSession【SparkContext】
-
-
特点
-
Integrated:集成了大多数的开发接口
-
DSL:函数式编程【DSL函数+ RDD函数】
table .select("id","name") .filter .flatMap .where("id > 2") .groupBy .agg(count("id"),sum(""))-
将SQL关键字变成函数
-
-
SQL:结构查询语言
select name,id from table where id > 2
-
-
Uniform Data Access:统一化的数据访问
-
SparkSQL中封装了大量结构化数据的读写接口
-
文件:csv/tsv/parquet/orc/json
-
表:MySQL、Hive
-
-
Hive Integration:Hive的集成
-
SparkSQL可以直接访问Hive数据仓库
-
对Hive中的表使用SparkSQL的程序进行分析处理
-
语法也基本一致
-
-
Standard Connectivity:标准的数据连接接口
-
SparkSQL Shell:类似于Hive shell
-
beeline
-
运行SQL文件
-
JDBC
-
打成jar包
-
-
-
应用
-
应用于离线数据仓库中数据计算:数据分析、分层转换
-
应用于实时数据流计算:StructStreaming:结构化流计算
-
-
-
小结
-
SparkSQL的功能、特点与应用场景是什么?
-
功能:实现结构化数据处理
-
特点
-
集成了多种开发接口:DSL【函数式编程:DSL函数 + RDD函数】、SQL
-
统一的数据访问接口:SparkSQL中封装了大量的数据源读写接口
-
与Hive的无缝集成:实现离线数据仓库的分布式计算
-
标准的数据连接接口:JDBC、Beeline、jar、SQL脚本
-
-
场景
-
离线:处理Hive数据仓库中的数据
-
实时:StructStreaming
-
-
-
17:DSL实现WordCount
-
目标:实现使用SparkSQL中的DSL开发WordCount
-
路径
-
step1:SparkSQL编程模板
-
step2:DSL的设计
-
step3:DSL开发实现
-
-
实施
-
SparkSQL编程模板
package bigdata.spark.sql.mode import org.apache.spark.sql.SparkSession /** * @ClassName SparkSQLMode * @Description TODO SparkSQL的开发模板 */ object SparkSQLMode { def main(args: Array[String]): Unit = { //todo:1-构建驱动对象:SparkSession val spark: SparkSession = SparkSession .builder() //构造一个建造器 .master("local[2]") //配置运行的模式 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置程序名称 // .config("key","valule") //配置其他属性 .getOrCreate() //返回一个SparkSession对象 //更改日志级别 spark.sparkContext.setLogLevel("WARN") //todo:2-实现处理的逻辑 //step1:读取数据 //step2:转换数据 //step3:保存结果 //todo:3-释放资源 spark.stop() } } -
DSL的设计
-
DSL:函数式编程方式去开发SparkSQL程序
-
优点:提供了SQL的关键字函数、兼容RDD的转换函数
-
select、where、groupBy
-
map、filter、flatMap
-
-
-
DSL开发实现
package bigdata.spark.sql.wordcount import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} /** * @ClassName SparkSQLWordCountDSL * @Description TODO SparkSQL使用DSL方式开发Wordcount程序 */ object SparkSQLWordCountDSL { def main(args: Array[String]): Unit = { //todo:1-构建驱动对象:SparkSession val spark: SparkSession = SparkSession .builder() //构造一个建造器 .master("local[2]") //配置运行的模式 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置程序名称 // .config("key","valule") //配置其他属性 .getOrCreate() //返回一个SparkSession对象 //更改日志级别 spark.sparkContext.setLogLevel("WARN") //引入隐式转换 import spark.implicits._ //todo:2-实现处理的逻辑 //step1:读取数据 val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") // inputData.printSchema() //打印Schema // //show(numRows, truncate = true):打印数据,numRows:打印行数,默认20行,truncate:如果字段的值过长,是否省略显示 // inputData.show(truncate = false) //输出数据 //step2:转换数据 val rsData = inputData //过滤空行 .filter(line => line != null && line.trim.length > 0) //得到每个单词 .flatMap(line => line.trim.split("\\s+")) //对value这一列进行分组 .groupBy($"value") //统计每组的个数 .count() //降序排序 .orderBy($"count".desc) //step3:保存结果 rsData.printSchema() rsData.show() //todo:3-释放资源 // Thread.sleep(100000000L) spark.stop() } }
-
-
小结
-
实现使用SparkSQL中的DSL开发WordCount
-
18:SQL实现WordCount
-
目标:实现使用SparkSQL中的SQL开发WordCount
-
路径
-
step1:SQL的开发流程
-
step2:SQL的开发实现
-
-
实施
-
SQL的开发流程
-
step1:将DF或者DS注册为一个只读表:视图
-
step2:通过SQL对视图进行处理,返回一个新的DF或者DS
-
-
SQL的开发实现
package bigdata.spark.sql.wordcount import org.apache.spark.sql.{Dataset, SparkSession} /** * @ClassName SparkSQLWordCountSQL * @Description TODO SparkSQL使用SQL方式开发Wordcount程序 */ object SparkSQLWordCountSQL { def main(args: Array[String]): Unit = { //todo:1-构建驱动对象:SparkSession val spark: SparkSession = SparkSession .builder() //构造一个建造器 .master("local[2]") //配置运行的模式 .appName(this.getClass.getSimpleName.stripSuffix("$")) //设置程序名称 // .config("key","valule") //配置其他属性 .getOrCreate() //返回一个SparkSession对象 //更改日志级别 spark.sparkContext.setLogLevel("WARN") //todo:2-实现处理的逻辑 //step1:读取数据 val inputData: Dataset[String] = spark.read.textFile("datas/wordcount/wordcount.data") //step2:转换数据 //注册视图 inputData.createOrReplaceTempView("tmp_view_input") //SQL转换:将一行多个单词转换为一行一个单词 val wordData = spark.sql( """ | select | explode(split(value," ")) as word | from tmp_view_input """.stripMargin) //注册视图 wordData.createOrReplaceTempView("tmp_view_word") //SQL转换:统计每个单词的个数 val rsData = spark.sql( """ |select | word, | count(*) as cnt |from tmp_view_word |where length(word) > 0 |group by word |order by cnt desc """.stripMargin) //step3:保存结果 // inputData.show(truncate = false) // wordData.show() rsData.printSchema() rsData.show() //todo:3-释放资源 spark.stop() } }
-
-
小结
-
实现使用SparkSQL中的SQL开发WordCount
-
附录一:Spark Maven依赖
aliyun
http://maven.aliyun.com/nexus/content/groups/public/
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
jboss
http://repository.jboss.com/nexus/content/groups/public
2.11.12
2.11
2.4.5
2.6.0-cdh5.16.2
1.2.0-cdh5.16.2
8.0.19
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql_${scala.binary.version}
${spark.version}
org.apache.spark
spark-hive_${scala.binary.version}
${spark.version}
org.apache.spark
spark-hive-thriftserver_${scala.binary.version}
${spark.version}
org.apache.spark
spark-sql-kafka-0-10_${scala.binary.version}
${spark.version}
org.apache.spark
spark-avro_${scala.binary.version}
${spark.version}
org.apache.spark
spark-mllib_${scala.binary.version}
${spark.version}
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.hbase
hbase-server
${hbase.version}
org.apache.hbase
hbase-hadoop2-compat
${hbase.version}
org.apache.hbase
hbase-client
${hbase.version}
mysql
mysql-connector-java
${mysql.version}
target/classes
target/test-classes
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile