【youcans动手学模型】SENet 模型及 PyTorch 实现
欢迎关注『youcans动手学模型』系列
本专栏内容和资源同步到 GitHub/youcans
【youcans动手学模型】SENet 模型
- 【经典模型】SENet 模型-Cifar10图像分类
-
- 1. SENet 卷积神经网络模型
-
- 1.1 模型简介
- 1.2 论文介绍
- 1.3 分析与讨论
- 2. 在 PyTorch 中定义 SENet 模型类
-
- 2.1 定义 SE Block
- 2.2 堆叠 SEBlock 构造 SENet 模型类
- 2.4 定义 SE-ResNet18 模型类
- 3. 基于 SENet 模型的 CIFAR10 图像分类
-
- 3.1 PyTorch 建立神经网络模型的基本步骤
- 3.2 加载 CIFAR10 数据集
- 3.3 建立 SENet 网络模型
- 3.4 SENet 模型训练
- 3.5 SENet 模型的保存与加载
- 3.6 模型检验
- 3.7 模型推理
- 4. 基于 SE-ResNet18 模型的 CIFAR10 图像分类
- 参考文献
【经典模型】SENet 模型-Cifar10图像分类
本文用 PyTorch 实现 SENet 网络模型,使用 CIFAR10 数据集训练模型,进行图像分类。
1. SENet 卷积神经网络模型
胡杰团队(Momenta)在 2017 年发表论文 “Squeeze and Excitation Networks”,提出一种深度学习神经网络模型,称为 SENet。该论文获得最后一届 ImageNet 2017 竞赛图像分类任务的冠军,在 ImageNet 数据集上将Top-5 error 降低到 2.251%。

【论文下载地址】
SENet: Squeeze and Excitation Networks
【GitHub地址】:
[https://github.com/hujie-frank/SENet]
[https://github.com/miraclewkf/SENet-PyTorch]
1.1 模型简介
SENet 并不是一个完整的网络结构,而是一个结构模块,通过通道特征重新校准来提高网络的表示能力。
SE 模块的核心思想,是生成反映特征通道重要性的权重向量,对原始特征进行重构,实现强调重要特征,忽略不重要特征,以增强模型的表征能力,提高模型性能。
SE 模块不仅是一个网络结构,而且在图像处理任务中体现和引入了注意力机制(Attention Mechanism)。
SENet 轻量高效,易于集成。SE 块生成的特征重要度值还可以用于其他任务,例如网络剪枝。
1.2 论文介绍
【论文摘要】
近些年来,卷积神经网络在很多领域上都取得了巨大的突破。卷积核作为卷积神经网络的核心,通常被看做是在局部感受野上,将空间(spatial)信息和特征维度(channel-wise)信息进行聚合的特征提取器。卷积神经网络由一系列卷积层、非线性层和下采样层构成,从全局感受野上捕获图像特征来进行图像的描述。
近年来很多工作通过优化空间维度来提升网络的性能,例如: Inception 结构中嵌入了多尺度信息,聚合多种不同感受野上的特征;在 Inside-Outside 网络中考虑了空间中的上下文信息;还有将 Attention 机制引入到空间维度。这些工作都是在空间维度上来提升网络的性能,那么是否可以从特征通道之间的关系来优化网络性能?
我们基于这一思想,提出了 Squeeze-and-Excitation Networks( SENet),目的是希望使用全局信息对特征通道之间的关系进行显式地建模,以提高模型的表示能力。我们并不是引入新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定(Feature Recalibration)”策略。具体来说,就是通过学习的方式来获取每个特征通道的重要程度(权重),然后依照通道的权重来提升重要的特征、抑制不重要的特征。
【主要创新】
对于一个通道数为 C ′ C' C′ 的输入特征 X ∈ R H ∗ W ∗ C ′ X \in R^{H*W*C'} X∈RH∗W∗C′,通过卷积操作等一系列变换 F t r F_{tr} Ftr,得到特征通道数为 C 的特征图 U ∈ R H ∗ W ∗ C U \in R^{H*W*C} U∈RH∗W∗C。 F t r F_{tr} Ftr 可以表示卷积操作,也可以表示其它的变换。
该输入输出变换操作的定义如下:
F t r : X → U , X ∈ R H ∗ W ∗ C ′ , U ∈ R H ∗ W ∗ C F_{tr}: X \to U, X \in R^{H*W*C'}, U \in R^{H*W*C} Ftr:X→U,X∈RH∗W∗C′,U∈RH∗W∗C
由于输出 U 是对所有通道求和产生的,因此通道之间的相关性也隐含在变换操作中,但是与滤波器在局部空间的作用是相互纠缠、无法分离的。因此,卷积层对于通道之间的相关性的反映,本质上是隐含的和局部的。我们希望获取特征通道的全局信息,对通道间的相关性进行显式地建模。
SE 模块的示意图如下。

我们通过三个操作来重新标定特征图 U。
(1)挤压操作(Squeeze):嵌入全局信息
Squeeze 沿空间维度进行特征压缩,通过全局均值池化(也可以使用其它操作),将特征通道压缩为一个通道描述符。通道描述符具有某种程度的全局感受野,可以表征在某个通道上特征的全局分布,或称为全局信息。
由维度 ( H , W , C ) (H,W,C) (H,W,C) 的特征图 U 得到维度 ( 1 , 1 , C ) (1,1,C) (1,1,C)的通道描述符,每个通道 c 对应于一个实数的通道描述符 z c z_c zc。
z c = F s q ( u c ) = 1 H ∗ W ∑ i = 1 H ∑ j = 1 W u c ( i , j ) z_c = F_{sq}(u_c) = \frac{1}{H*W} \sum^H_{i=1} \sum^W_{j=1} u_c(i,j) zc=Fsq(uc)=H∗W1i=1∑Hj=1∑Wuc(i,j)
通过将特征图压缩为一个特征向量,可以更有效地学习和利用不同通道之间的关系 。
(2)激励操作(Excitation):自适应学习权值
激励操作基于通道描述符学习通道之间的非线性关系。
通过一种具有 S 型激活的简单门控机制,为每个特征通道生成权重 s,对通道之间的相关性建模。
s = F e x ( z , W ) = σ ( g ( z , w ) ) = σ ( W 2 ∗ δ ( W 1 z ) ) s = F_{ex}(z,W) = \sigma (g(z,w)) = \sigma (W_2 * \delta(W_1 z)) s=Fex(z,W)=σ(g(z,w))=σ(W2∗δ(W1z))
权重 s 的维度是 (1,1,C2), s c s_c sc 是通道 c 的权值系数。
激励操作实际上是 2层全连接网络 FC,将通道描述符 z 变换为通道权重 s,s 的维度是 ( 1 , 1 , C ) (1,1,C) (1,1,C) 与 z 相同。为了降低复杂度,全连接网络设计为瓶颈结构,r 是压缩比,中间层的维度压缩为 ( 1 , 1 , C / r ) (1,1,C/r) (1,1,C/r) 。

δ \delta δ 表示 ReLU 函数, σ \sigma σ 表示 S 型激活函数如 Sigmoid函数,将输出映射到 (0,1) 之间表示通道的重要度。
需要注意的是,激励操作将通道描述符 z 变换为通道权重 s,本质上是引入了通道域的视觉注意力机制,其关系不限于滤波器的局部感受野。因此,虽然可以使用不同的模型结构和激活函数实现建模(参见 ECA),但并不是任意的模型结构和激活函数都可以,而是需要符合注意力机制的一般要求 s = f ( x , g ( x ) ) s=f(x,g(x)) s=f(x,g(x))。
(3)重新标定(Scale):
将 Excitation 的输出的权重 s c s_c sc 视为每个特征通道的重要度,通过乘法逐通道加权到原始特征图上,作为 SE块的输出,就实现在通道维度上的对原始特征的重标定。
x c ~ = F s c a l e ( u c , s c ) = s c u c \tilde{x_c} = F_{scale} (u_c, s_c) = s_c u_c xc~=Fscale(uc,sc)=scuc
【模型结构】
SE 模块是一个通用的模版,结构简单。我们可以简单地堆叠 SE块来构建 SE网络模型,也可以将 SE 块与其它深度学习模型集成,构造如 SE-Inception,SE-ResNet,等等 。
例如,以 Inception Module 或 Residual Module 作为 F t r F_{tr} Ftr ,就可以构造如下的 SE-Inception Module 或 SE-Residual Module。将 SE 块与 ResNeXt、Inception ResNet、MobileNet 和 ShuffleNet 集成也可以通过类似的方案来构建。
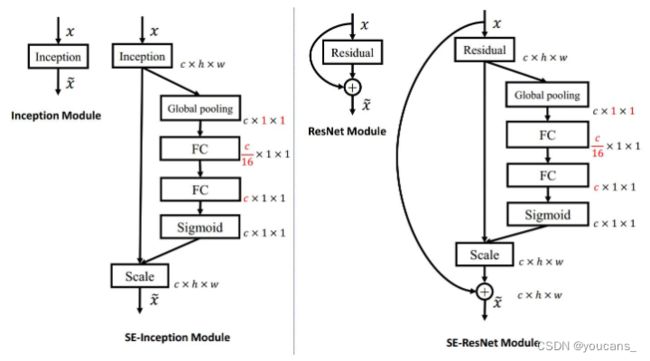
SE块在计算上是轻量级的,略微增加了模型复杂性和计算负担,但性能提升显著。
【模型性能】
SENet 构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。
以 ResNet-50 和 SE-ResNet-50 为例进行比较。对于 224* 224 的输入图像,ResNet50 正向推理的计算量 3.86 GFLOP。每个 SE块在 Squeeze 阶段使用全局平均池化操作,在 Excitation 阶段使用两个小 FC 层,然后按通道缩放。当压缩比 r=16时,SE-ResNet-50 正向推理的计算量为 3.87 GFLOP,计算量的增加可以忽略不计。ResNet-50 模型参数为 2500万,SE-ResNet-50模型参数增加了 250万,模型参数量增加了10%,但可以去除最后阶段的 SE块则模型参数只增加 4%。而 SE-ResNet-50 的准确率明显优于 ResNet-50,甚至优于 ResNet-101 网络的准确率,而 ResNet-101 网络计算量需要 7.58 GFLOP。
【讨论】
SE 模块在整个网络的不同深度具有不同的作用,不同层的 SE 在功能上是互补的,处在不同阶段的多个 SE 模块的组合可进一步提升模型性能。
在网络早期的层中,不同类别图像的权值分布差异不大,说明特征通道的重要性由不同类别的特征共享。在较深的层中,不同类别图像的权值分布的差异性增大,说明不同类别对特征表现出不同的偏好。这也说明,早期层特征通常更具一般性,而后期层特征表现出更高水平的特异性。
而在网络的最后阶段,大多数激活值接近于 1,这表明 SE 块的作用衰减。去除最后阶段的SE块,可以显著减少额外参数计数,而性能损失很小。
1.3 分析与讨论
SENet 模型的目的,是通过 SE块结构对原始特征进行重构,实现强调重要特征,忽略不重要特征,以增强模型的表征能力,提高模型性能。
2. 在 PyTorch 中定义 SENet 模型类
SENet 不是一个完整的网络结构,而是一个结构模块 SE Block。SE Block 可以插入各种深度学习模型,构造 SE 集成模型,例如 SE-Inception,SE-ResNet,等等。
本节面向 CIFAR10 数据集图像分类问题,先介绍 SE Block 模型类的定义,然后直接堆叠 SE Block 改造一个简单的 SENet 网络模型。另外,本节还以 ResNet18 为基础模型,构造 SE-ResNet18 模型。
2.1 定义 SE Block
SE Block 通过 2个线性层和激活函数得到通道权值,通过乘法逐通道加权到原始特征图上,作为 SE块的输出。
定义 SE Block 的例程如下。
# 定义 SE Block
class SEBlock(nn.Module):
def __init__(self, channel, ratio=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化层, [b,c,h,w] -> [b,c,1,1]
self.fc = nn.Sequential(
# 第 1 个线性层压缩通道数,维度是[ch, ch/r]
nn.Linear(channel, channel//ratio, bias=False),
nn.ReLU(inplace=True),
# 第 2 个线性层恢复通道数,维度是[ch/r, ch]
nn.Linear(channel//ratio, channel, bias=False),
# Sigmoid 激活函数
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# Squeeze 操作, [b,c,h,w] -> [b,c]
y = self.avg_pool(x).view(b, c)
# Excitation 操作, 获取通道注意力权值 s
y = self.fc(y).view(b,c,1,1)
# Scale 操作, X^ = Fscale(X, S) = X .* S
y = x * y.expand_as(x)
return y
2.2 堆叠 SEBlock 构造 SENet 模型类
简化的 SqueezeNet 模型类定义如下。该模型与 SqueezeNet 论文原文模型相比进行了简化,而且使用全连接层作为分类器。
对于不同的数据集,可能需要进行一些适应性的调整。例如 CIFAR10 数据集图像分类问题数据集规模较小,图片尺寸为 32*32,因此对 SqueezeNet 模型进行了简化。
# 定义 SENet (直接堆叠 SEBlock 模块)
class SENet1(nn.Module):
def __init__(self, num_classes=10, reduction=16):
super(SENet, self).__init__()
# 卷积池化层
self.conv_pool1 = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1), # C1: 输入 3,输出 64,卷积核 3x3,填充 1
nn.BatchNorm2d(64), # 批归一化
nn.ReLU(), # ReLU 激活函数
SEBlock(64, reduction) # SEBlock 模块
)
self.conv_pool2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1), # C2
nn.BatchNorm2d(128), # 批归一化
nn.ReLU(), # ReLU 激活函数
SEBlock(128, reduction), # SEBlock 模块
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 池化层
)
self.conv_pool3 = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1), # C3
nn.BatchNorm2d(256), # 批归一化
nn.ReLU(), # ReLU 激活函数
SEBlock(256, reduction), # SEBlock 模块
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 池化层
)
self.conv_pool4 = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1), # C2
nn.BatchNorm2d(512), # 批归一化
nn.ReLU(), # ReLU 激活函数
SEBlock(512, reduction) # SEBlock 模块
)
# 特征分类器
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d(1), # 全局平均池化层
nn.Flatten(), # 展平为一维向量
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.conv_pool1(x) # (3,32,32) -> (64,32,32)
x = self.conv_pool2(x) # (64,32,32) -> (128,16,16)
x = self.conv_pool3(x) # (128,16,16) -> (256,8,8)
x = self.conv_pool4(x) # (256,,8,8) -> (512,8,8)
x = self.classifier(x) # (512,32,32) -> (10)
return x
Summary 网络结构如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 32, 32] 1,792
BatchNorm2d-2 [-1, 64, 32, 32] 128
ReLU-3 [-1, 64, 32, 32] 0
AdaptiveAvgPool2d-4 [-1, 64, 1, 1] 0
Linear-5 [-1, 4] 256
ReLU-6 [-1, 4] 0
Linear-7 [-1, 64] 256
Sigmoid-8 [-1, 64] 0
SEBlock-9 [-1, 64, 32, 32] 0
Conv2d-10 [-1, 128, 32, 32] 73,856
BatchNorm2d-11 [-1, 128, 32, 32] 256
ReLU-12 [-1, 128, 32, 32] 0
AdaptiveAvgPool2d-13 [-1, 128, 1, 1] 0
Linear-14 [-1, 8] 1,024
ReLU-15 [-1, 8] 0
Linear-16 [-1, 128] 1,024
Sigmoid-17 [-1, 128] 0
SEBlock-18 [-1, 128, 32, 32] 0
MaxPool2d-19 [-1, 128, 16, 16] 0
Conv2d-20 [-1, 256, 16, 16] 295,168
BatchNorm2d-21 [-1, 256, 16, 16] 512
ReLU-22 [-1, 256, 16, 16] 0
AdaptiveAvgPool2d-23 [-1, 256, 1, 1] 0
Linear-24 [-1, 16] 4,096
ReLU-25 [-1, 16] 0
Linear-26 [-1, 256] 4,096
Sigmoid-27 [-1, 256] 0
SEBlock-28 [-1, 256, 16, 16] 0
MaxPool2d-29 [-1, 256, 8, 8] 0
Conv2d-30 [-1, 512, 8, 8] 1,180,160
BatchNorm2d-31 [-1, 512, 8, 8] 1,024
ReLU-32 [-1, 512, 8, 8] 0
AdaptiveAvgPool2d-33 [-1, 512, 1, 1] 0
Linear-34 [-1, 32] 16,384
ReLU-35 [-1, 32] 0
Linear-36 [-1, 512] 16,384
Sigmoid-37 [-1, 512] 0
SEBlock-38 [-1, 512, 8, 8] 0
AdaptiveAvgPool2d-39 [-1, 512, 1, 1] 0
Flatten-40 [-1, 512] 0
Linear-41 [-1, 10] 5,130
================================================================
Total params: 1,601,546
Trainable params: 1,601,546
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 9.41
Params size (MB): 6.11
Estimated Total Size (MB): 15.53
----------------------------------------------------------------
2.4 定义 SE-ResNet18 模型类
首先定义一个带残差连接的 SE-Res 模块。
# 带残差连接的 SE-Res 模块
class SEResBlock(nn.Module):
def __init__(self, ch_in, reduction=16):
super(SEResBlock, self).__init__()
self.adaptive_avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化
self.fc = nn.Sequential( # 获取通道注意力权重
nn.Linear(ch_in, ch_in//reduction),
nn.ReLU(inplace=True),
nn.Linear(ch_in//reduction, ch_in),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.adaptive_avg_pool(x).view(b, c) # (b,c,h,w)->(b,c)
y = self.fc(y).view(b, c, 1, 1) # (b,c)->(b,c,1,1)
y = x * y.expand_as(x) # 通道注意力加权
return y
# return x+y # 残差连接
基于 ResNet18 网络定义的 SE-ResNet18 模型类如下。
# ResBlock 残差模块
class ResBlock(nn.Module):
def __init__(self, ch_in, ch_out, stride, ResFlag):
super(ResBlock, self).__init__()
self.ResFlag = ResFlag # 残差连接标志
# 第一层卷积,3*3 卷积核
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 第二层卷积,3*3 卷积核
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
# 逐点卷积,1*1 卷积核,调整通道维度
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride, padding=0),
nn.BatchNorm2d(ch_out)
)
self.bn = nn.BatchNorm2d(ch_out)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.bn(self.conv1(x))
out = self.relu(out)
out = self.bn(self.conv2(out))
if self.ResFlag: # 残差连接
out = self.extra(x) + out
out = self.relu(out)
return out
# 构建 ResNet18 网络模型
class SE_Resnet18(nn.Module):
def __init__(self, num_classes=10):
super(SE_Resnet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.block1 = nn.Sequential(
ResBlock(ch_in=64, ch_out=64, stride=1, ResFlag=False),
SEBlock(64),
ResBlock(ch_in=64, ch_out=64, stride=1, ResFlag=False)
)
self.block2 = nn.Sequential(
ResBlock(ch_in=64, ch_out=128, stride=2, ResFlag=True),
SEBlock(128),
ResBlock(ch_in=128, ch_out=128, stride=1, ResFlag=False)
)
self.block3 = nn.Sequential(
ResBlock(ch_in=128, ch_out=256, stride=2, ResFlag=True),
SEBlock(256),
ResBlock(ch_in=256, ch_out=256, stride=1, ResFlag=False)
)
self.block4 = nn.Sequential(
ResBlock(ch_in=256, ch_out=512, stride=2, ResFlag=True),
SEBlock(512),
ResBlock(ch_in=512, ch_out=512, stride=1, ResFlag=False)
)
self.adaptive_avg_pool2d = nn.AdaptiveAvgPool2d((1, 1))
self.relu = nn.ReLU(inplace=True)
# 全连接层
self.FC_layer = nn.Sequential(
nn.Linear(512, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.25), # 随机删除部分连接
nn.Linear(128, num_classes)
)
def forward(self, x):
# ResNet18 特征提取
x = self.conv1(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
# ResNet18 特征分类
x = self.adaptive_avg_pool2d(x)
x = x.view(x.size(0), -1)
x = self.FC_layer(x)
return x
3. 基于 SENet 模型的 CIFAR10 图像分类
3.1 PyTorch 建立神经网络模型的基本步骤
使用 PyTorch 建立、训练和使用神经网络模型的基本步骤如下。
- 准备数据集(Prepare dataset):加载数据集,对数据进行预处理。
- 建立模型(Design the model):实例化模型类,定义损失函数和优化器,确定模型结构和训练方法。
- 模型训练(Model trainning):使用训练数据集对模型进行训练,确定模型参数。
- 模型推理(Model inferring):使用训练好的模型进行推理,对输入数据预测输出结果。
- 模型保存与加载(Model saving/loading):保存训练好的模型,以便以后使用或部署。
以下按此步骤讲解 SENet 模型的例程。
3.2 加载 CIFAR10 数据集
通用数据集的样本结构均衡、信息高效,而且组织规范、易于处理。使用通用的数据集训练神经网络,不仅可以提高工作效率,而且便于评估模型性能。
PyTorch 提供了一些常用的图像数据集,预加载在 torchvision.datasets 类中。torchvision 模块实现神经网络所需的核心类和方法, torchvision.datasets 包含流行的数据集、模型架构和常用的图像转换方法。
CIFAR 数据集是一个经典的图像分类小型数据集,有 CIFAR10 和 CIFAR100 两个版本。CIFAR10 有 10 个类别,CIFAR100 有 100 个类别。CIFAR10 每张图像大小为 32*32,包括飞机、小汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车 10 个类别。CIFAR10 共有 60000 张图像,其中训练集 50000张,测试集 10000张。每个类别有 6000张图片,数据集平衡。
加载和使用 CIFAR 数据集的方法为:
torchvision.datasets.CIFAR10()
torchvision.datasets.CIFAR100()
CIFAR 数据集可以从官网下载:http://www.cs.toronto.edu/~kriz/cifar.html 后使用,也可以使用 datasets 类自动加载(如果本地路径没有该文件则自动下载)。
下载数据集时,使用预定义的 transform 方法进行数据预处理,包括调整图像尺寸、标准化处理,将数据格式转换为张量。标准化处理所使用 CIFAR10 数据集的均值和方差为 (0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616)。transform_train在训练过程中,增加随机性,提高泛化能力。
大型训练数据集不能一次性加载全部样本来训练,可以使用 Dataloader 类自动加载数据。Dataloader 是一个迭代器,基本功能是传入一个 Dataset 对象,根据参数 batch_size 生成一个 batch 的数据。
使用 DataLoader 类加载 CIFAR-10 数据集的例程如下。
# (1) 将[0,1]的PILImage 转换为[-1,1]的Tensor
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.Resize(32), # 图像大小调整为 (w,h)=(32,32)
transforms.ToTensor(), # 将图像转换为张量 Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# 测试集不需要进行数据增强
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# (2) 加载 CIFAR10 数据集
batchsize = 128
# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载
# 加载 CIFAR10 训练数据集, 50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='../dataset', train=True,
download=True, transform=transform_train)
# train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize,
shuffle=True, num_workers=8)
# 加载 CIFAR10 验证数据集, 10000张验证图片
test_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000,
shuffle=True, num_workers=8)
# 创建生成器,用 next 获取一个批次的数据
valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象
valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,32,32], labels: [batch]
valid_size = valid_labels.size(0) # 验证数据集大小,batch
print(valid_images.shape, valid_labels.shape)
# 定义类别名称,CIFAR10 数据集的 10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
3.3 建立 SENet 网络模型
建立一个 SENet 网络模型进行训练,包括三个步骤:
- 实例化 SENet 模型对象;
- 设置训练的损失函数;
- 设置训练的优化器。
torch.nn.functional 模块提供了各种内置损失函数,本例使用交叉熵损失函数 CrossEntropyLoss。
torch.optim 模块提供了各种优化方法,本例使用 SGD 优化器。注意要将 model 的参数 model.parameters() 传给优化器对象,以便优化器扫描需要优化的参数。
# (3) 构造 SENet 网络模型 (直接堆叠 SEBlock 模块)
model = SENet1(num_classes=10, reduction=16) # 实例化 SENet 网络模型
model.to(device) # 将网络分配到指定的 device 中
# print(model)
from torchsummary import summary
summary(model, (3, 32, 32))
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropy
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01, weight_decay=5e-4) # 定义优化器 SGD
3.4 SENet 模型训练
PyTorch 模型训练的基本步骤是:
- 前馈计算模型的输出值;
- 计算损失函数值;
- 计算权重 weight 和偏差 bias 的梯度;
- 根据梯度值调整模型参数;
- 将梯度重置为 0(用于下一循环)。
在模型训练过程中,可以使用验证集数据评价训练过程中的模型精度,以便控制训练过程。模型验证就是用验证数据进行模型推理,前向计算得到模型输出,但不反向计算模型误差,因此需要设置 torch.no_grad()。
使用 PyTorch 进行模型训练的例程如下。
# (4) 训练 SENet 模型
epoch_list = [] # 记录训练轮次
loss_list = [] # 记录训练集的损失值
accu_list = [] # 记录验证集的准确率
num_epochs = 50 # 训练轮次
for epoch in range(num_epochs): # 训练轮次 epoch
running_loss = 0.0 # 每个轮次的累加损失值清零
for step, data in enumerate(train_loader, start=0): # 迭代器加载数据
optimizer.zero_grad() # 损失梯度清零
inputs, labels = data # inputs: [batch,3,32,32] labels: [batch]
outputs = model(inputs.to(device)) # 正向传播
loss = criterion(outputs, labels.to(device)) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 累加训练损失值
running_loss += loss.item()
# if step%100==99: # 每 100 个 step 打印一次训练信息
# print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))
# 计算每个轮次的验证集准确率
with torch.no_grad(): # 验证过程, 不计算损失函数梯度
outputs_valid = model(valid_images.to(device)) # 模型对验证集进行推理, [batch, 10]
pred_labels = torch.max(outputs_valid, dim=1)[1] # 预测类别, [batch]
accuracy = torch.eq(pred_labels, valid_labels.to(device)).sum().item() / valid_size * 100 # 计算准确率
print("Epoch {}: train loss={:.4f}, accuracy={:.2f}%".format(epoch, running_loss, accuracy))
# 记录训练过程的统计数据
epoch_list.append(epoch) # 记录迭代次数
loss_list.append(running_loss) # 记录训练集的损失函数
accu_list.append(accuracy) # 记录验证集的准确率
程序运行结果如下:
Epoch 0: train loss=625.6963, accuracy=46.09%
Epoch 1: train loss=488.5032, accuracy=58.98%
Epoch 2: train loss=432.1913, accuracy=64.06%
…
Epoch 48: train loss=148.6156, accuracy=83.98%
Epoch 49: train loss=148.0326, accuracy=83.98%
经过 20 轮左右的训练,训练损失不断,检验准确率逐渐增大到 80%左右。经过 50 轮的训练,验证集的准确率达到 85%左右。

3.5 SENet 模型的保存与加载
模型训练好以后,将模型保存起来,以便下次使用。PyTorch 中模型保存主要有两种方式,一是保存模型权值,二是保存整个模型。本例使用 model.state_dict() 方法以字典形式返回模型权值,torch.save() 方法将权值字典序列化到磁盘,将模型保存为 .pth 文件。
# (5) 保存 SENet 网络模型
save_path = "../models/SENet_Cifar1"
model_cpu = model.cpu() # 将模型移动到 CPU
model_path = save_path + ".pth" # 模型文件路径
torch.save(model.state_dict(), model_path) # 保存模型权值
# 优化结果写入数据文件
result_path = save_path + ".csv" # 优化结果文件路径
WriteDataFile(epoch_list, loss_list, accu_list, result_path)
使用训练好的模型,首先要实例化模型类,然后调用 load_state_dict() 方法加载模型的权值参数。
# 以下模型加载和模型推理,可以是另一个独立的程序
# (6) 加载 SENet 网络模型进行推理
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检测并指定设备
# 加载 SENet 预训练模型
model = SENet1(num_classes=10) # 实例化 SENet 网络模型
model.to(device) # 将网络分配到指定的device中
model_path = "../models/SENet_Cifar1.pth"
model.load_state_dict(torch.load(model_path))
model.eval() # 模型推理模式
需要特别注意的是:
(1)PyTorch 中的 .pth 文件只保存了模型的权值参数,而没有模型的结构信息,因此必须先实例化模型对象,再加载模型参数。
(2)模型对象必须与模型参数严格对应,才能正常使用。注意即使都是 SENet 模型,模型类的具体定义也可能有细微的区别。如果从一个来源获取模型类的定义,从另一个来源获取模型参数文件,就很容易造成模型结构与参数不能匹配。
(3)无论从 PyTorch 模型仓库加载的模型和参数,或从其它来源获取的预训练模型,或自己训练得到的模型,模型加载的方法都是相同的,也都要注意模型结构与参数的匹配问题。
3.6 模型检验
使用加载的 SENet 模型,输入新的图片进行模型推理,可以由模型输出结果确定输入图片所属的类别。
使用测试集数据进行模型推理,根据模型预测结果与图片标签进行比较,可以检验模型的准确率。模型验证集与模型检验集不能交叉使用,但为了简化例程在本程序中未做区分。
# (7) 模型检测
correct = 0
total = 0
for data in test_loader: # 迭代器加载测试数据集
imgs, labels = data # torch.Size([batch,3,32,32) torch.Size([batch])
# print(imgs.shape, labels.shape)
outputs = model(imgs.to(device)) # 正向传播, 模型推理, [batch, 10]
labels_pred = torch.max(outputs, dim=1)[1] # 模型预测的类别 [batch]
# _, labels_pred = torch.max(outputs.data, 1)
total += labels.size(0)
correct += torch.eq(labels_pred, labels.to(device)).sum().item()
accuracy = 100. * correct / total
print("Test samples: {}".format(total))
print("Test accuracy={:.2f}%".format(accuracy))
使用测试集进行模型推理,测试模型准确率为 84.83%。
Test samples: 10000
Test accuracy=84.83%
3.7 模型推理
使用加载的 SENet 模型,输入新的图片进行模型推理,可以由模型输出结果确定输入图片所属的类别。
从测试集中提取几张图片,或者读取图像文件,进行模型推理,获得图片的分类类别。在提取图片或读取文件时,要注意对图片格式和图片大小进行适当的转换。
# (8) 提取测试集图片进行模型推理
batch = 8 # 批次大小
data_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=False, transform=None)
plt.figure(figsize=(9, 6))
for i in range(batch):
imgPIL = data_set[i][0] # 提取 PIL 图片
label = data_set[i][1] # 提取 图片标签
# 预处理/模型推理/后处理
imgTrans = transform(imgPIL) # 预处理变换, torch.Size([3,32,32])
imgBatch = torch.unsqueeze(imgTrans, 0) # 转为批处理,torch.Size([batch=1,3,32,32])
outputs = model(imgBatch.to(device)) # 模型推理, 返回 [batch=1, 10]
indexes = torch.max(outputs, dim=1)[1] # 注意 [batch=1], device = 'device
index = indexes[0].item() # 预测类别,整数
# 绘制第 i 张图片
imgNP = np.array(imgPIL) # PIL -> Numpy
out_text = "label:{}/model:{}".format(classes[label], classes[index])
plt.subplot(2, 4, i+1)
plt.imshow(imgNP)
plt.title(out_text)
plt.axis('off')
plt.tight_layout()
plt.show()
结果如下。

# (9) 读取图像文件进行模型推理
from PIL import Image
filePath = "../images/img_car_01.jpg" # 数据文件的地址和文件名
imgPIL = Image.open(filePath) # PIL 读取图像文件, 结果如下。

4. 基于 SE-ResNet18 模型的 CIFAR10 图像分类
使用 SE-ResNet18 模型类,基于 CIFAR10 数据集进行训练,模型的准确率比 SE Block 而成的 SENet 更高。
SE-ResNet18 模型的完整例程如下。
# Begin_SENet_CIFAR_2.py
# SE-ResNet model for beginner with PyTorch
# 经典模型: SE-ResNet18 简化模型 CIFAR10 图像分类
# Copyright: [email protected]
# Crated: Huang Shan, 2023/06/25
# _*_coding:utf-8_*_
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from matplotlib import pyplot as plt
import numpy as np
# 定义 SE Block
class SEBlock(nn.Module):
def __init__(self, channel, ratio=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 平均池化层, [b,c,h,w] -> [b,c,1,1]
self.fc = nn.Sequential(
# 第 1 个线性层压缩通道数,维度是[ch, ch/r]
nn.Linear(channel, channel//ratio, bias=False),
nn.ReLU(inplace=True),
# 第 2 个线性层恢复通道数,维度是[ch/r, ch]
nn.Linear(channel//ratio, channel, bias=False),
# Sigmoid 激活函数
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
# Squeeze 操作, [b,c,h,w] -> [b,c]
y = self.avg_pool(x).view(b, c)
# Excitation 操作, 获取通道注意力权值 s
y = self.fc(y).view(b,c,1,1)
# Scale 操作, X^ = Fscale(X, S) = X .* S
y = x * y.expand_as(x)
return y
# ResBlock 残差模块
class ResBlock(nn.Module):
def __init__(self, ch_in, ch_out, stride, ResFlag):
super(ResBlock, self).__init__()
self.ResFlag = ResFlag # 残差连接标志
# 第一层卷积,3*3 卷积核
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
# 第二层卷积,3*3 卷积核
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
# 逐点卷积,1*1 卷积核,调整通道维度
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride, padding=0),
nn.BatchNorm2d(ch_out)
)
self.bn = nn.BatchNorm2d(ch_out)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.bn(self.conv1(x))
out = self.relu(out)
out = self.bn(self.conv2(out))
if self.ResFlag: # 残差连接
out = self.extra(x) + out
out = self.relu(out)
return out
# 构建 ResNet18 网络模型
class SE_Resnet18(nn.Module):
def __init__(self, num_classes=10):
super(SE_Resnet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.block1 = nn.Sequential(
ResBlock(ch_in=64, ch_out=64, stride=1, ResFlag=False),
SEBlock(64),
ResBlock(ch_in=64, ch_out=64, stride=1, ResFlag=False)
)
self.block2 = nn.Sequential(
ResBlock(ch_in=64, ch_out=128, stride=2, ResFlag=True),
SEBlock(128),
ResBlock(ch_in=128, ch_out=128, stride=1, ResFlag=False)
)
self.block3 = nn.Sequential(
ResBlock(ch_in=128, ch_out=256, stride=2, ResFlag=True),
SEBlock(256),
ResBlock(ch_in=256, ch_out=256, stride=1, ResFlag=False)
)
self.block4 = nn.Sequential(
ResBlock(ch_in=256, ch_out=512, stride=2, ResFlag=True),
SEBlock(512),
ResBlock(ch_in=512, ch_out=512, stride=1, ResFlag=False)
)
self.adaptive_avg_pool2d = nn.AdaptiveAvgPool2d((1, 1))
self.relu = nn.ReLU(inplace=True)
# 全连接层
self.FC_layer = nn.Sequential(
nn.Linear(512, 128),
nn.ReLU(inplace=True),
nn.Dropout(0.25), # 随机删除部分连接
nn.Linear(128, num_classes)
)
def forward(self, x):
# ResNet18 特征提取
x = self.conv1(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
# ResNet18 特征分类
x = self.adaptive_avg_pool2d(x)
x = x.view(x.size(0), -1)
x = self.FC_layer(x)
return x
# 优化结果写入数据文件
import pandas as pd
def WriteDataFile(epoch_list, loss_list, accu_list, filepath):
# print("def WriteDataFile()")
optRecord = {
"epoch": epoch_list,
"train_loss": loss_list,
"accuracy": accu_list}
dfRecord = pd.DataFrame(optRecord)
dfRecord.to_csv(filepath, index=False, encoding="utf_8_sig")
print("写入数据文件: %s 完成。" % filepath)
return
if __name__ == '__main__':
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# (1) 将 [0,1] 的 PILImage 转换为[-1,1]的Tensor
transform_train = transforms.Compose([
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.RandomRotation(10), # 随机旋转
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),
transforms.Resize((32, 32)), # 图像大小调整为 (w,h)=(32,32)
transforms.ToTensor(), # 将图像转换为张量 Tensor
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# 测试集不需要进行数据增强
transform = transforms.Compose([
transforms.Resize(32),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
# (2) 加载 CIFAR10 数据集
batchsize = 128
# 加载 CIFAR10 数据集, 如果 root 路径加载失败, 则自动在线下载
# 加载 CIFAR10 训练数据集, 50000张训练图片
train_set = torchvision.datasets.CIFAR10(root='../dataset', train=True,
download=True, transform=transform_train)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=batchsize,
shuffle=True, num_workers=8)
# 加载 CIFAR10 验证数据集, 10000张验证图片
test_set = torchvision.datasets.CIFAR10(root='../dataset', train=False,
download=True, transform=transform)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=256,
shuffle=True, num_workers=8)
# 创建生成器,用 next 获取一个批次的数据
valid_data_iter = iter(test_loader) # _SingleProcessDataLoaderIter 对象
valid_images, valid_labels = next(valid_data_iter) # images: [batch,3,32,32], labels: [batch]
valid_size = valid_labels.size(0) # 验证数据集大小,batch
print(valid_images.shape, valid_labels.shape)
# 定义类别名称,CIFAR10 数据集的 10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck')
# (3) 构造 SE_ResNet 网络模型
model = SE_Resnet18(num_classes=10) # 实例化 SE-ResNet18 网络模型
model.to(device) # 将网络分配到指定的device中
# print(model)
from torchsummary import summary
summary(model, (3, 32, 32))
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 定义损失函数 CrossEntropy
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01, weight_decay=5e-4) # 定义优化器 SGD
# (4) 训练 SE-ResNet 模型
epoch_list = [] # 记录训练轮次
loss_list = [] # 记录训练集的损失值
accu_list = [] # 记录验证集的准确率
num_epochs = 50 # 训练轮次
for epoch in range(num_epochs): # 训练轮次 epoch
running_loss = 0.0 # 每个轮次的累加损失值清零
for step, data in enumerate(train_loader, start=0): # 迭代器加载数据
optimizer.zero_grad() # 损失梯度清零
inputs, labels = data # inputs: [batch,3,32,32] labels: [batch]
outputs = model(inputs.to(device)) # 正向传播
loss = criterion(outputs, labels.to(device)) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 累加训练损失值
running_loss += loss.item()
# if step%100==99: # 每 100 个 step 打印一次训练信息
# print("\t epoch {}, step {}: loss = {:.4f}".format(epoch, step, loss.item()))
# 计算每个轮次的验证集准确率
with torch.no_grad(): # 验证过程, 不计算损失函数梯度
outputs_valid = model(valid_images.to(device)) # 模型对验证集进行推理, [batch, 10]
pred_labels = torch.max(outputs_valid, dim=1)[1] # 预测类别, [batch]
accuracy = torch.eq(pred_labels, valid_labels.to(device)).sum().item() / valid_size * 100 # 计算准确率
print("Epoch {}: train loss={:.4f}, accuracy={:.2f}%".format(epoch, running_loss, accuracy))
# 记录训练过程的统计数据
epoch_list.append(epoch) # 记录迭代次数
loss_list.append(running_loss) # 记录训练集的损失函数
accu_list.append(accuracy) # 记录验证集的准确率
# (5) 保存 SE-ResNet 网络模型
save_path = "../models/SEResNet18_Cifar2"
model_cpu = model.cpu() # 将模型移动到 CPU
model_path = save_path + ".pth" # 模型文件路径
torch.save(model.state_dict(), model_path) # 保存模型权值
# 优化结果写入数据文件
result_path = save_path + ".csv" # 优化结果文件路径
WriteDataFile(epoch_list, loss_list, accu_list, result_path)
程序运行结果如下:
Epoch 0: train loss=626.2509, accuracy=58.59%
Epoch 1: train loss=439.1957, accuracy=72.27%
Epoch 2: train loss=353.0309, accuracy=75.39%
…
Epoch 48: train loss=66.4574, accuracy=90.23%
Epoch 49: train loss=64.4416, accuracy=91.01%
经过 20 轮左右的训练,训练损失不断,检验准确率已经接近 90%。经过 50 轮的训练,验证集的准确率达到 90~92%。

参考文献
- Jie Hu, Li Shen, Samuel Albanie, et al.Squeeze-and-Excitation Networks (CVPR 2018) (https://arxiv.org/abs/1709.01507)
- 胡杰, Momenta 详解 ImageNet 2017 夺冠架构 SENet, https://www.sohu.com/a/161633191_465975
- https://github.com/MenghaoGuo/Awesome-Vision-Attentions
【本节完】
版权声明:
欢迎关注『youcans动手学模型』系列
转发请注明原文链接:
【youcans动手学模型】SENet 模型及 PyTorch 实现
Copyright 2023 youcans, XUPT
Crated:2023-07-02