UNIX网络编程卷一 学习笔记 第二十二章 高级UDP套接字编程
TCP是一个字节流协议,又使用滑动窗口,因此没有记录边界或发送者数据发送能力超过接收者接受能力之类的事情,但对于UDP,每个输入操作对应一个UDP数据报(一个记录),因此当收取的数据报大于引用的输入缓冲区时就有问题。
UDP是不可靠协议,但有些应用确实有理由使用UDP而非TCP,在这些UDP应用中,我们必须包含一些特性弥补UDP的不可靠性,如超时和重传(用于处理丢失的数据报)、序列号(用于匹配应答与请求)。
如果实现不支持IP_RECVDSTADDR套接字选项,那么确定外来UDP数据报目的IP地址的方法之一是绑定所有接口地址并使用select函数。
多数UDP服务器程序是迭代运行的,但有些应用系统在客户和服务器之间交换多个UDP数据报,因此需要某种形式的并发,如TFTP。我们将讨论有inetd和无inetd参与两种情况下如何做到这些。
历史上sendmsg和recvmsg函数一直用于通过Unix域套接字传递描述符,甚至这种用途也不多见,但因为以下原因,这两个函数用的变多:
1.随4.3 BSD Reno加到msghdr结构的msg_flags成员返回标志给应用进程。
2.辅助数据被用于在应用进程和内核之间传递越来越多的信息。
我们将编写一个recvfrom_flags函数,它类似recvfrom函数,但还返回:
1.msg_flags值。
2.所收取数据报的目的地址(通过IP_RECVDSTADDR套接字选项获取)。
3.所收取数据报接口的索引(通过IP_RECVIF套接字选项获取)。
为返回以上后两项,在unp.h头文件中定义如下结构:

我们的recvfrom_flags函数将接受指向某个in_pktinfo结构的指针作为参数,如果该指针不为空,本函数就通过该指针所指结构返回信息。
如果实现不支持IP_RECVDSTADDR套接字选项,则recvfrom_flags函数返回的接口索引为0(表示索引不可知),但IP地址的所有32位都是有效的,我们的做法是,当实际值不可得时,返回一个全0值作为目的地址,尽管它是一个有效IP地址,但不允许作为目的IP地址,它只有作为源IP地址才有效,且必须是在主机正在引导,还不知道自己IP地址时。
但源自Berkeley的内核接受目的地址为0.0.0.0的IP数据报,这样的数据报是由源自4.2 BSD的内核生成的过时广播。
以下是recvfrom_flags函数:
#include "unp.h"
#include 以上程序中,IP_RECVIF返回的辅助数据对象结构如下:
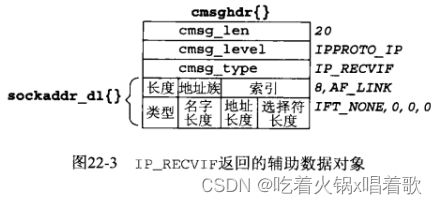
上图中,名字长度、地址长度、选择符(link-layer seletor,是在网络通信中选择和识别特定链路层的标识符或标志,某些情况下,需要选择特定的链路层或与特定链路层相关的协议、设备或功能。这时就可以使用link-layer selector来标识所需的链路层)长度都是0,因此选择符长度后面要跟的数据为空,所以整个sockaddr_dl结构(第十八章)长度为8,而非加上后面数据后的20字节。
为了测试recvfrom_flags函数,我们把回射服务器的dg_echo函数改为调用recvfrom_flags而非recvfrom的:
#include "unpifi.h"
#undef MAXLINE
// 减小MAXLINE,为了看收到一个比传递给读函数(本例中是recvmsg函数)的
// 缓冲区更大的UDP数据报时会发生什么
#define MAXLINE 20 /* to see datagram truncation */
void dg_echo(int sockfd, SA *pcliaddr, socklen_t clilen) {
int flags;
const int on = 1;
socklen_t len;
ssize_t n;
char mesg[MAXLINE], str[INET6_ADDRSTRLEN], ifname[IFNAMSIZ];
struct in_addr in_zero;
struct unp_in_pktinfo pktinfo;
#ifdef IP_RECVDSTADDR
if (setsockopt(sockfd, IPPROTO_IP, IP_RECVDSTADDR, &on, sizeof(on)) < 0) {
err_ret("setsockopt of IP_RECVDSTADDR");
}
#endif
#ifdef IP_RECVIF
if (setsockopt(sockfd, IPPROTO_IP, IP_RECVIF, &on, sizeof(on)) < 0) {
err_ret("setsockopt of IP_RECVIF");
}
#endif
bzero(&in_zero, sizeof(struct in_addr)); /* all 0 IPv4 address */
for (; ; ) {
len = clilen;
flags = 0;
n = Recvfrom_flags(sockfd, mesg, MAXLINE, &flags,
pcliaddr, &len, &pktinfo);
// 把收到的数据报的源IP和端口用sock_ntop函数转换为可读的形式
printf("%d-byte datagram from %s", n, Sock_ntop(pcliaddr, len));
// 如果返回了收到数据报的接口的本地IP,就用inet_ntop函数把它转换为可读形式
if (memcmp(&pktinfo.ipi_addr, &in_zero, sizeof(in_zero)) != 0) {
printf(", to %s", Inet_ntop(AF_INET, &pktinfo.ipi_addr,
str, sizeof(str)));
}
// 如果返回了收到数据报的接口的索引,就用if_indextoname函数获取接口名字
if (pktinfo.ipi_ifindex > 0) {
printf(", recv i/f = %s",
If_indextoname(pktinfo.ipi_ifindex, ifname));
}
#ifdef MSG_TRUNC
if (flags & MSG_TRUNC) {
printf(" (datagram truncated)");
}
#endif
#ifdef MAX_CTRUNC
if (flags & MSG_CTRUNC) {
printf(" (control info truncated)");
}
#endif
#ifdef MSG_BCAST
if (flags & MSG_BCAST) {
printf(" (broadcast)");
}
#endif
#ifdef MSG_MCAST
if (flags & MSG_MCAST) {
printf(" (multicast)");
}
#endif
printf("\n");
Sendto(sockfd, mesg, n, 0, pcliaddr, len);
}
}
在源自Berkeley的系统上,当到达的UDP数据报超过应用进程提供的缓冲区容量时,recvmsg函数在其msghdr结构的msg_flags成员上设置MSG_TRUNC标志。
MSG_TRUNC是从内核返回到进程的标志之一,函数recv和recvfrom存在的一个设计问题是它们的flags参数是一个整数,因而只允许从进程到内核传递标志,而不能反方向返回标志。
但并非所有实现都像源自Berkeley的系统那样处理超过预期长度的UDP数据报,所有实现的可能的处理方式如下:
1.丢弃超出部分的字节并向应用进程返回MSG_TRUNC标志。本处理方式要求应用进程调用recvmsg以接收这个标志。
2.丢弃超出部分的字节但不告知应用进程这个事实。
3.保留超出部分的字节并在同一套接字的后续读操作中返回它们。
POSIX采纳第一种处理行为。早期的SVR 4版本采用的第三种处理行为。
既然不同的实现在处理超过应用进程接收缓冲区大小的数据报时存在以上差异,一个有效应对方法是:总是分配比应用进程预期接收的最大数据报还多1个字节的应用进程缓冲区,如果收到长度等于该缓冲区的数据报,就认定它是一个过长数据报。
以下是UDP的优势:
1.UDP支持广播和多播,如果应用要用广播或多播,就必须用UDP。
2.UDP没有连接建立和拆除,UDP只需两个分组就能交换一个请求和一个应答(假设两者长度都小于两个端系统之间的最小MTU),而TCP大约需要10个分组(假设每次请求-应答都要建立一个新TCP连接)。
单个UDP请求-应答的最小事务处理时间为RTT(Round-Trip Time,表示客户与服务器时间的往返时间)+SPT(Server Processing Time,服务器处理时间),对TCP而言,如果同样的请求-应答要用一个新TCP连接,那么最小事务处理时间为2*RTT+SPT,比UDP时间多一个RTT。
如果单个TCP连接用于多个请求-应答,那么连接的建立和拆除开销就由所有请求和应答分担,这样的设计通常比每个请求-应答都使用一个新连接要好。但有些应用系统还是为每个请求-应答使用一个新TCP连接(如较早版本的HTTP),而有些应用会在客户和服务器交换一个请求-应答后,可能数小时或数天不再通信(如DNS)。
以下是UDP无法提供的TCP特性,如果这些特性对于某些应用系统是必需的,那么该应用系统必须自行提供它们,但不是所有应用都需要TCP的所有这些特性,如对于实时音频应用程序而言,如果接收进程能通过插值弥补遗失数据,那么丢失的分节也许不必重传,同样,对于简单的请求-应答事务处理而言,如果两端事先协定最大的请求和应答大小,就不需要窗口式流量控制:
1.数据确认,丢失分组重传,重复分组检测,给被网络打乱次序的分组排序。TCP会确认所有数据,以便检测出丢失的分组。这些特性的实现要求每个TCP数据分节都包含一个能被对端确认的序列号。这些特性还要求TCP为每个连接估算重传超时值,该值会随两个端系统之间的分组流通的变化持续更新。
2.窗口式流量控制。接收端TCP告知发送端自己已为接收数据分配了多大的缓冲区空间,发送端不能发送超过这个大小的数据。即发送端的未确认数据量不能超过接收端告知的窗口。
3.慢启动和拥塞避免。这是由发送端实施的一种流量控制形式,它通过检测当前的网络容量来应对阵发的阻塞。所有TCP必须支持这两个特性,我们根据20世纪80年代后期这些算法实现之前的经验知道,那些面临拥塞而不back off的协议只会使拥塞变得更糟。
对于UDP的使用,有如下建议:
1.对于广播或多播应用必须使用UDP。任何形式的错误控制必须加到客户和服务器程序中,但这样的应用系统往往是在可以接受一定量的错误的前提下(如音频或视频分组丢失)使用多播和广播。要求可靠递送的多播应用系统(如多播文件传输)是有的,但我们必须衡量使用多播的性能收益(发送单个分组到N个目的地,对比跨N个TCP连接发送该分组的N歌副本),看为提供可靠通信而增添到应用程序中的复杂性是否值得。
2.对于简单的请求-应答应用可以使用UDP,但错误检测功能需要加到应用中。错误检测至少涉及确认、超时、重传。流量控制对于合理大小的请求和应答往往不成问题。这种情况下是否使用UDP要考虑的因素包括客户和服务器通信的频率(是否能在相继的通信之间保持所用的TCP连接)以及交换的数据量(如果通常要多个分组,那么TCP连接的建立和拆除开销将变得不大重要)。
3.对于海量数据传输(如文件传输)不应使用UDP,因为这除了需要2中所需的特性外,还要把窗口式流量控制、拥塞避免、慢启动这些特性也加到应用中,相当于我们在应用中再造TCP。我们应让厂商来关注更好的TCP性能,而自己应致力于提升应用程序本身。
以上建议存在例外,如TFTP用UDP传送海量数据,TFTP选用UDP的原因在于,在系统自举引导代码中使用UDP比使用TCP易于实现(TCPv2中使用UDP的C代码约800行,使用TCP的代码约4500行),而且TFTP只用于在局域网上引导系统,而不是跨广域网传送海量数据。但使用UDP就要求TFTP自含用于确认的序列号字段,并具备超时和重传能力。
NFS是以上建议的另一个例外,它也用UDP传送海量数据(但有人可能声称它实际上是请求-应答系统,只不过使用较大的请求和应答)。这样的选择部分出于历史原因,在20世纪80年代中期设计NFS时,UDP的实现要比TCP快,且NFS只用于局域网,分组丢失率往往比在广域网上少几个数量级。但随着NFS从20世纪90年代早期开始被用于跨广域网范围,且TCP实现在海量数据传送性能上开始超过UDP的实现,NFS第3版被设计成支持TCP,大多厂商已改为同时在UDP和TCP上提供NFS。同样的理由也导致DCE(Distributed Computing Environment)远程过程调用的前身软件包(Apollo NCS(Network Computing System)包,它是一种用于远程过程调用的软件包,提供了一种在分布式系统中进行通信和交互的机制)也选择UDP而非TCP,但如今的实现同时支持UDP和TCP。
如今良好的TCP实现能充分发挥网络的带宽容量,越来越少的应用系统设计人员愿意在自己的UDP应用中再造TCP,相比TCP,UDP的用途在递减。但多媒体应用领域的增长会促成UDP使用的增加,因为多媒体通常意味着需要UDP的多播。
如果想让请求-应答式应用使用UDP,需要在程序中增加以下特性:
1.超时和重传,用于处理丢失的数据报。
2.序列号,供客户验证一个应答是否匹配相应的请求。
这两个特性是使用简单的请求-应答范式的大多现有UDP应用的一部分,如DNS解析器、SNMP(Simple Network Management Protocol,它被设计用于监控和管理网络设备、服务器、路由器、交换机和其他网络设备)代理、TFTP、RPC。我们不打算使用UDP传送海量数据,而是要剖析发送一个请求并等待一个应答的应用程序。
数据报是不可靠的,因此我们不把增加了以上可靠性的UDP称为可靠的数据报服务。事实上,可靠的数据报是一个自相矛盾的说法,我们将展示的是在不可靠的数据报服务(UDP)之上加入可靠性的一个应用程序。
增加序列号比较简单,客户为每个请求冠以一个序列号,服务器必须在返回给客户的应答中回射这个序列号,这样客户就可以验证某个应答是否匹配早先发出的请求。
超时和重传的老式方法是先发送一个请求并等待N秒,如果期间没有收到应答,就重新发送同一个请求并再等待N秒,如此重复几次后放弃发送。这是线性重传定时器的例子,许多TFTP客户程序仍使用此方法。
这个方法的问题在于数据报在网络上的往返时间可以从局域网的远不到1秒变化到广域网的好几秒。影响往返时间的因素包括距离、网络速度、拥塞。客户和服务器之间的RTT也会因网络条件的变化而随时间快速变化。我们必须采用一个把实测到的RTT及其随时间的变化考虑在内的超时和重传算法。这个领域已有不少研究工作,大多涉及TCP,但同样的想法适用于所有网络应用。
我们想要计算用于每个分组的重传超时(RTO,Retransmission TimeOut),为此先测量每个分组的实际往返时间RTT,每测得一个RTT,我们就更新两个统计估算因子:srtt(Smoothed RTT estimator,平滑化RTT估算因子)和rttvar(平滑化平均偏差估算因子,smoothed mean deviation estimator),后者是标准偏差的一个不涉及开方而易于计算的较好近似。待用RTO的计算方法就是srtt加上4倍rttvar。[Jacobson 1988](它是Van Jacobson发表于1988年的一篇论文,题目为“Congestion Avoidance and Control“,这篇论文提出了TCP/IP协议中的拥塞控制算法,是计算机网络领域中的经典论文之一)给出了这些计算的细节,我们用以下方程加以总结:
delta是测得RTT和当前平滑化RTT估算因子(srtt)之差。g是施加在RTT估算因子上的增益,值为1/8。h是施加在平均偏差估算因子上的增益,值为1/4。
RTO计算中的两个增益和乘数4都特意选为2的指数,这样使用移位运算而非乘除运算就能计算相关值。事实上TCP内核实现为了速度起见通常使用定点算数运算进行计算,但为了简便,后续代码中使用浮点计算。
[Jacobson 1988]指出,当重传定时器期满时,必须对下一个RTO应用某个指数回退(exponential backoff),例如,如果第一个RTO是2秒,期间未收到应答,则下一个RTO是4秒,如果仍未收到应答,那么再下一个RTO是8秒、16秒,依此类推。
Jacobson的算法告诉我们测得一个RTT后如何计算RTO以及重传时如何增加RTO。但当我们不得不重传一个分组并随后收到一个应答时,重传二义性问题(retransmission ambiguity problem)出现了,下图是重传定时器期满时可能出现的3种情形:
当客户收到重传过的某个请求的一个应答时,它不能区分该应答对应哪次请求。上图中右侧例子中,该应答对应初始的请求;对于另两个例子,该应答对应重传的请求。
Karn算法[Karm and Partridge 1987]可以解决重传二义性问题,即一旦收到重传过的某个请求的一个应答,就应用以下规则:
1.即使测得一个RTT,也不用它更新估算因子,因为我们不知道其中的应答对应哪次重传的请求。
2.既然应答在重传定时器期满前到达,当前RTO(可能是指数退避过的)将继续用于下一个分组,直到我们收到未重传过的某个请求的一个应答时,我们才更新RTT估算因子并重新计算RTO。
在编写我们的RTT函数时采用Karn的算法并不困难,但还有更精妙的解决办法,这个办法来自TCP用于应对长胖管道(有较高带宽或有较长RTT,抑或两者都有的网络)的扩展(RFC 1323)。本方法除了为每个请求冠以一个服务器必须回射的序列号外,还在请求中加入发送时的时间戳,而服务器会像对待序列号一样,在应答中回射该时间戳值,当收到一个应答时,我们用当前时间减去由服务器在其应答中回射的时间戳(也是该应答对应的请求发出时的时间戳)就能算出RTT,这样我们可以计算出每个应答的RTT,从而不再有二义性。此外,既然服务器只是回射一下客户发来的时间戳,因此客户可以给时间戳使用任何想用的时间单位,且客户和服务器不需要为此拥有同步的时钟。
通过一个例子实现所有上述内容,首先把UDP回射客户程序的main函数所用端口号改为7(标准回射服务器),下图是该程序所用的dg_cli函数,仅有的改动是把sendto和recvfrom函数替换为调用我们的新函数dg_send_recv:
#include "unp.h"
ssize_t Dg_send_recv(int, const void *, size_t, void *, size_t,
const SA *, socklen_t);
void dg_cli(FILE *fp, int sockfd, const SA *pservaddr, socklen_t servlen) {
ssize_t n;
char sendline[MAXLINE], recvline[MAXLINE + 1];
while (Fgets(sendline, MAXLINE, fp) != NULL) {
n = Dg_send_recv(sockfd, sendline, strlen(sendline),
recvline, MAXLINE, pservaddr, servlen);
recvline[n] = 0; /* null terminate */
Fputs(recvline, stdout);
}
}
在给出dg_send_recv函数和它调用的RTT函数前,我们先通过以下伪代码给出如何给一个UDP客户程序增加可靠性的轮廓,所有以rtt_打头的函数随后给出:
static sigjmp_buf jmpbuf;
{
/* ... */
// 构造请求
signal(SIGALRM, sig_alrm); /* establish signal handler */
rtt_newpack(); /* initialize rexmt conter to 0 */
sendagain:
sendto();
alarm(rtt_start()); /* set alarm for RTO seconds */
if (sigsetjmp(jmpbuf, 1) != 0) {
if (rtt_timeout()) { /* double RTO, retransmitted enough? */
// 放弃
}
goto sendagain; /* retransmit */
}
do {
recvfrom();
} while (序列号错误);
alarm(0); /* turn off alarm */
rtt_stop(); /* calculate RTT and update estimators */
// 处理应答
/* ... */
}
void sig_alrm(int signo) {
siglongjmp(jmpbuf, 1);
}
当收到一个序列号非期望值的应答时,我们再次调用recvfrom,但不重传请求,也不重启运行中的重传定时器,这样在图22-5右侧的例子中,与重传的那个请求对应的最后一个应答将在客户下一次发送一个新请求时出现在套接字接收缓冲区中,它就不会引起问题,因为客户将读入这个应答,注意到它的序列号非期望值,于是丢弃它并再次调用recvfrom。
之后我们调用sigsetjmp和siglongjmp来避免第二十章中讨论过的由SIGALRM信号引起的竞争状态。
以下是dg_send_recv函数:
// unprtt.h稍后给出,其中定义了用于为客户维护RTT信息的rtt_info结构
#include "unprtt.h"
#include 以下是dg_send_recv函数使用的头文件unprtt.h:
#ifndef __unp_rtt_h
#define __unp_rtt_h
#include "unp.h"
// rtt_info结构用于在客户和服务器间计时,前4个变量是之前给出的方程式中的变量
struct rtt_info {
float rtt_rtt; /* most recent measured RTT, in seconds */
float rtt_srtt; /* smoothed RTT estimator, in seconds */
float rtt_rttvar; /* smoothed mean deviation, in seconds */
float rtt_rto; /* current RTO to use, in seconds */
int rtt_nrexmt; /* # times retransmitted: 0, 1, 2, ... */
uint32_t rtt_base; /* # sec since 1/1/1970 at start */
};
// 定义最小和最大重传超时值、最大重传次数
#define RTT_RXTMIN 2 /* min retransmit timeout value, in seconds */
#define RTT_RXTMAX 60 /* max retransmit timeout value, in seconds */
#define RTT_MAXNREXMT 3 /* max # times to retransmit */
/* function prototypes */
void rtt_debug(struct rtt_info *);
void rtt_init(struct rtt_info *);
void rtt_newpack(struct rtt_info *);
int rtt_start(struct rtt_info *);
void rtt_stop(struct rtt_info *, uint32_t);
int rtt_timeout(struct rtt_info *);
uint32_t rtt_ts(struct rtt_info *);
extern int rtt_d_flag; /* can be set to nonzero for addl info */
#endif /* __unp_rtt_h */
以下是以rtt_开头的函数的实现:
#include "unprtt.h"
int rtt_d_flag = 0; /* debug flag; can be set by caller */
/*
* Calculate the RTO value based on current estimators:
* smoothed RTT plus four times the deviation
*/
// RTT_RTOCALC宏用于计算RTO
#define RTT_RTOCALC(ptr) ((ptr)->rtt_srtt + (4.0 * (ptr)->rtt_rttvar))
// 确保RTO在unprtt.h头文件中定义的上下界之间
static float rtt_minmax(float rto) {
if (rto < RTT_RXTMIN) {
rto = RTT_RXTMIN;
} else if (rto > RTT_RXTMAX) {
rto = RTT_RXTMAX;
}
return rto;
}
// 在首次发送一个分组时调用
void rtt_init(struct rtt_info *ptr) {
struct timeval tv;
// 获取当前时间,存放在timeval结构中(此结构select函数也使用),只保留从1/1/1970(Unix纪元)以来的秒数
Gettimeofday(&tv, NULL);
ptr->rtt_base = tv.tv_sec; /* # sec since 1/1/1970 at start */
// RTT初始置为0
ptr->rtt_rtt = 0;
// 平滑化RTT估算因子初始置为0
ptr->rtt_srtt = 0;
// 平滑化平均偏差估算因子初始置为0.75
ptr->rtt_rttvar = 0.75;
// 初始RTO算出来会是3秒
ptr->rtt_rto = rtt_minmax(RTT_RTOCALC(ptr));
/* first RTO at (srtt + (4 * rttvar)) = 3 seconds */
}
// 返回当前时间戳,供调用者作为一个无符号32位整数存放在待发送数据报中
uint32_t rtt_ts(struct rtt_info *ptr) {
uint32_t ts;
struct timeval tv;
// 获取当前时间,从中减去rtt_init时的秒钟数,然后将这个差转换为毫秒数
// 再把gettimeofday函数返回的微秒值转换成毫秒数,时间戳就是这两个毫秒值之和
// 两次rtt_ts调用返回值之差就是这两次调用之间的毫秒数
Gettimeofday(&tv, NULL);
ts = ((tv.tv_sec - ptr->rtt_base) * 1000) + (tv.tv_usec / 1000);
return ts;
}
// 把重传计数器置为0,每当第一次发送一个新分组时,都要调用该函数
void rtt_newpack(struct rtt_info *ptr) {
ptr->rtt_nrexmt = 0;
}
// 返回以秒为单位的当前RTO,返回值随后会作为alarm函数的参数
int rtt_start(struct rtt_info *ptr) {
return (int)(ptr->rtt_rto + 0.5); /* round float to int */
/* return value can be used as: alarm(rtt_start(&foo)) */
}
// 本函数应用前面给出的方程式,在rtt_srtt、rtt_rttval、rtt_rto三个成员中存放新值
// 第二个参数是测得的RTT,由调用者通过从当前时间戳(rtt_ts函数获取)中减去收到的应答中的时间戳得到
void rtt_stop(struct rtt_info *ptr, uint32_t ms) {
double delta;
ptr->rtt_rtt = ms / 1000.0; /* measured RTT in seconds */
/*
* Update our estimators of RTT and mean deviation of RTT.
* See Jacobson's SIGCOMM '88 papre, Appendix A, for the details.
* We use floating point here for simplicity.
*/
delta = ptr->rtt_rtt - ptr->rtt_srtt;
ptr->rtt_srtt += delta / 8; /* g = 1/8 */
if (delta < 0.0) {
delta = -delta; /* |delta| */
}
ptr->rtt_rttvar += (delta - ptr->rtt_rttvar) / 4; /* h = 1/4 */
ptr->rtt_rto = rtt_minmax(RTT_RTOCALC(ptr));
}
// 在重传定时器期满时调用
int rtt_timeout(struct rtt_info *ptr) {
// 当前RTO加倍,这就是指数回退
ptr->rtt_rto *= 2; /* next RTO */
// 如果已经达到了最大重传次数,就返回-1,告知调用者放弃
if (++ptr->rtt_nrexmt > RTT_MAXNREXMT) {
return -1; /* time to give up for this packet */
}
return 0;
}
测试以上程序的一个例子:我们的客户程序在某个工作日早上针对2个跨因特网的不同echo服务器各发送一次,每次发送给服务器的都是500行文本。去往第一个服务器的分组有8个丢失,去往第二个服务器的分组有16个丢失。去往第二个服务器的丢失分组中,有一个连续丢失两次,即在收到该分组的某个应答前,客户重传了该分组两次。其他所有丢失分组都只需要一次重传处理。我们可以通过打印每个收到分组的序列号来验证这些分组确实丢失了,如果一个分组仅被延迟而没有丢失,那么重传后客户会收到两个应答。当重传分组时,我们无法区分被丢弃的分组时客户的请求还是服务器的应答。
为测试本客户程序,本书第一版中作者编写了一个随机丢弃分组的UDP服务器程序,我们不再需要该程序,我们只需要针对一个跨因特网的服务器执行客户程序就行,几乎可以保证总有些分组会丢失。
我们编写的get_ifi_info函数的常见用途之一是监视本地主机所有接口以便获悉某个数据报在何时及哪个接口上到达的UDP程序(通过获取每个接口的地址,对每个接口都创建一个监听套接字)。这允许接收程序获悉该UDP数据报的目的地址,即使主机不支持IP_RECVDSTADDR套接字选项。
如果主机使用普通的弱端系统模型,那么目的IP地址可能不同于接收接口的IP地址,此时为每个接口创建一个接收套接字的方法只能确定数据报的目的地址,它可能不是接收该数据报接口的某个地址。为确定接收接口,需要IP_RECVIF(使用原始套接字编程时,启用该套接字选项后可从recvmsg函数的控制信息中获取通过该套接字接收到的数据包的接口信息)或IPV6_PKTINFO(用于在IPv6套接字编程中获取接收到的数据包的接口信息)这两个套接字选项之一。
以下是为每个接口捆绑一个地址的例子,它捆绑所有单播地址、广播地址、通配地址:
#include "unpifi.h"
void mydg_echo(int, SA *, socklen_t, SA *);
int main(int argc, char **argv) {
int sockfd;
const int on = 1;
pid_t pid;
struct ifi_info *ifi, *ifihead;
struct sockaddr_in *sa, cliaddr, wiladdr;
// 调用get_ifi_info获取所有接口的所有IPv4地址,第2个参数为1表示也返回别名地址
for (ifihead = ifi = Get_ifi_info(AF_INET, 1);
ifi != NULL; ifi = ifi->ifi_next) {
/* bind unicast address(绑定单播地址) */
sockfd = Socket(AF_INET, SOCK_DGRAM, 0);
// 设置SO_REUSEADDR套接字选项,因为我们要给所有IP地址捆绑同一个端口
// 并非所有实现都要设置此套接字选项,源自Berkeley的实现不需要该选项就允许重新bind
// 一个已经绑定的端口,只要新绑定的IP地址:不是通配地址、不同于已经绑定在该端口上任何一个地址
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
sa = (struct sockaddr_in *)ifi->ifi_addr;
sa->sin_family = AF_INET;
sa->sin_port = htons(SERV_PORT);
Bind(sockfd, (SA *)sa, sizeof(*sa));
printf("bound %s\n", Sock_ntop((SA *)sa, sizeof(*sa)));
if ((pid = Fork()) == 0) { /* child */
// mydg_echo函数等待任意数据报到达这个套接字,然后把它回射给发送者
mydg_echo(sockfd, (SA *)&cliaddr, sizeof(cliaddr), (SA *)sa);
exit(0); /* never executed */
}
// 如果当前接口支持广播
if (ifi->ifi_flags & IFF_BROADCAST) {
/* try to bind broadcast address */
sockfd = Socket(AF_INET, SOCK_DGRAM, 0);
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
// 在刚创建的UDP套接字上绑定广播地址
sa = (struct sockaddr_in *)ifi->ifi_brdaddr;
sa->sin_family = AF_INET;
if (bind(sockfd, (SA *)sa, sizeof(*sa)) < 0) {
// 我们允许bind函数返回EADDRINUSE错误,因为如果某个接口由多个处于同一子网
// 的地址(别名),那么这些单播地址会对应同一广播地址,此时只有第一次bind调用能成功
if (errno == EADDRINUSE) {
printf("EADDRINUSE: %s\n", Sock_ntop((SA *)sa, sizeof(*sa)));
Close(sockfd);
continue;
} else {
err_sys("bind error for %s", Sock_ntop((SA *)sa, sizeof(*sa)));
}
}
printf("bound %s\n", Sock_ntop((SA *)sa, sizeof(sa)));
if ((pid = Fork()) == 0) { /* child */
mydg_echo(sockfd, (SA *)&cliaddr, sizeof(cliaddr), (SA *)sa);
exit(0); /* never executed */
}
}
}
/* bind wildcard address */
sockfd = Socket(AF_INET, SOCK_DGRAM, 0);
// 设置SO_REUSEADDR套接字选项,以绑定通配IP地址
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
// bind通配地址,以处理除已经绑定的单播和广播地址外的任何目的地址
// 能够到达此套接字的数据报应该只有目的地为受限广播地址(255.255.255.255)的数据报
bzero(&wildaddr, sizeof(wildaddr));
wildaddr.sin_family = AF_INET;
wildaddr.sin_addr.s_addr = htonl(INADDR_ANY);
wildaddr.sin_port = htons(SERV_PORT);
Bind(sockfd, (SA *)&wildaddr, sizeof(wildaddr));
printf("bound %s\n", Sock_ntop((SA *)&wildaddr, sizeof(wildaddr)));
if ((pid = Fork()) == 0) { /* child */
mydg_echo(sockfd, (SA *)&cliaddr, sizeof(cliaddr), (SA *)sa);
exit(0); /* never executed */
}
// main函数终止,服务器父进程结束,但已派生的所有子进程继续运行
exit(0);
}
以上代码是IPv4协议相关的,将其改成协议无关的版本,要求指定一个或两个命令行参数,第一个是可选的IP地址(用于指定IPv4还是IPv6),第二个是必需的端口号:
#include "unpifi.h"
void mydg_echo(int, SA *, socklen_t);
int main(int argc, char **argv) {
int sockfd, family, port;
const int on = 1;
pid_t pid;
socklen_t salen;
struct sockaddr *sa, *wild;
struct ifi_info *ifi, *ifihead;
if (argc == 2) {
// udp_client函数没有给getaddrinfo函数指定AI_PASSIVE,这种情况下
// 如果不给出主机IP,会导致getaddrinfo函数获取本地主机地址0::1(IPv6)或127.0.0.1(IPv4)
// 此时,如果是双栈主机,getaddrinfo函数会先于IPv4套接字地址结构返回IPv6套接字地址结构
// 然后udp_client函数将先尝试地址族为AF_INET6的socket调用并成功,然后返回一个IPv6的套接字
sockfd = Udp_client(NULL, argv[1], (void **)&sa, &salen);
} else if (argc == 3) {
// 如果指定了主机IP,如果指定的是IPv4地址,则返回一个IPv4套接字,IPv6地址同理
sockfd = Udp_client(argv[1], argv[2], (void **)&sa, &salen);
} else {
err_quit("usage: udpserv04 [ ] " );
}
family = sa->sa_family;
// 协议无关地获取套接字地址结构sa中的端口号,sock_get_port函数中处理各个协议差异
port = sock_get_port(sa, salen);
Close(sockfd); /* we just want family, port, salen */
for (ifihead = ifi = Get_ifi_info(family, 1);
ifi != NULL; ifi = ifi->ifi_next) {
/* bind unicast address */
sockfd = Socket(family, SOCK_DGRAM, 0);
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
sock_set_port(ifi->ifi_addr, salen, port);
Bind(sockfd, ifi->ifi_addr, salen);
printf("bound %s\n", Sock_ntop(ifi->ifi_addr, salen));
if ((pid = Fork()) == 0) { /* child */
mydg_echo(sockfd, ifi->ifi_addr, salen);
exit(0); /* never executed */
}
if (ifi->ifi_flags & IFF_BROADCAST) {
/* try to bind broadcast address */
sockfd = Socket(family, SOCK_DGRAM, 0);
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
sock_set_port(ifi->ifi_brdaddr, salen, port);
if (bind(sockfd, ifi->ifi_brdaddr, salen) < 0) {
if (errno == EADDRINUSE) {
printf("EADDRINUSE: %s\n", Sock_ntop(ifi->ifi_brdaddr, salen));
Close(sockfd);
continue;
} else {
err_sys("bind error for %s", Sock_ntop(ifi->ifi_brdaddr, salen));
}
}
printf("bound %s\n", Sock_ntop(ifi->ifi_brdaddr, salen));
if ((pid = Fork()) == 0) { /* child */
mydg_echo(sockfd, ifi->ifi_brdaddr, salen);
exit(0); /* never executed */
}
}
}
/* bind wildcard address */
sockfd = Socket(family, SOCK_DGRAM, 0);
Setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
wild = Malloc(salen);
memcpy(wild, sa, salen); /* copy family and port */
// 协议无关地设置套接字地址结构wild中的地址为通配地址,Sock_set_wild函数中处理各个协议差异
Sock_set_wild(wild, salen);
Bind(sockfd, wild, salen);
printf("bound %s\n", Sock_ntop(wild, salen));
if ((pid = Fork()) == 0) { /* child */
mydg_echo(sockfd, wild, salen);
exit(0); /* never execuuted */
}
exit(0);
}
以下是所有子进程都执行的mydg_echo函数:
// 第4个参数是绑定在sockfd参数指定的套接字上的IP地址,本套接字应该只接收目的地址为该IP地址的数据报
// 如果该IP地址是通配地址,则它应该只接收与绑定到同一端口的其他套接字都不匹配的数据报
void mydg_echo(int sockfd, SA *pcliaddr, socklen_t clilen, SA *myaddr) {
int n;
char mesg[MAXLINE];
socklen_t len;
for (; ; ) {
len = clilen;
n = Recvfrom(sockfd, mesg, MAXLINE, 0, pcliaddr, &len);
// 此处的输出要分成两个printf调用,因为sock_ntop函数使用静态缓冲区存放结果
// 如果我们在同一个printf函数中调用它两次,第二次会覆写第一次的结果
printf("child %d, datagram from %s", getpid(), Sock_ntop(pcliaddr, len));
printf(", to %s\n", Sock_ntop(myaddr, clilen));
Sendto(sockfd, mesg, n, 0, pcliaddr, len);
}
}
在主机solaris上为hme0以太网接口设置一个别名地址,再运行本程序,该别名地址为10.0.0.200/24:

用netstat命令检查所有套接字确实绑定了对应的IP地址和端口号:

上例中我们为每个套接字派生一个子进程的设计只是为简单起见,也可采用其他设计,例如,为减少进程数目,程序可用select函数管理所有描述符,而不必调用fork,该设计的代码复杂性高,尽管使用select函数可以容易地检测所有描述符的可访问条件,我们还要维护从每个描述符到它的绑定IP地址的映射,这样从某个套接字读入一个数据报时,我们能显示它的目的地址。
大多UDP服务器是迭代运行的,服务器等待一个客户请求,读入并处理这个请求,送回其应答,接着等待下一个客户请求,但当客户请求的处理需耗用过长时间时,我们期望UDP服务器程序具有某种形式的并发性。
过长时间指的是另一个客户因服务器正在服务当前客户而被迫等待的被认为是太长的时间,如两个客户请求在10ms内相继到达,且每个客户平均服务时间为5秒,那第二个客户不得不等待约10秒才能收到应答,而非请求一到达就处理情形下的约5秒。
对于TCP服务器,并发处理只是简单地fork一个新进程或创建一个新线程,并让子进程处理新客户,使用TCP时服务器的并发处理简单的原因在于每个客户连接都是唯一的(标识每个客户连接的是唯一的TCP套接字对),但对于UDP,我们需要应对两种不同服务器:
1.第一种UDP服务器比较简单,读入一个客户请求并发送一个应答后,与这个客户就不再相关了,此时,读入客户请求的服务器可以fork一个子进程并让子进程去处理该请求。该请求通过fork函数复制的内存映像传递给子进程,然后子进程把它的应答发送给客户。
2.第二种UDP服务器与客户交换多个数据报,问题是客户知道的端口只有服务器的一个众所周知端口,一个客户发送一个数据报到这个端口,但服务器应如何区分这是来自该客户的同一个请求的后续数据报还是来自其他客户请求的数据报呢?这个问题的典型解决方法是让服务器为每个客户创建一个新套接字,在其上bind一个临时端口,然后使用该套接字发送对该客户的所有应答,这个方法要求客户查看服务器第一个应答中的源端口号,并把本请求的后续数据报发送到该端口。
第二种类型UDP服务器的一个例子是TFTP,使用TFTP传送一个文件通常需要许多数据报,因为该协议每个数据报的大小是512字节,客户往服务器的众所周知端口(69)发送一个数据报,指定要发送或接收的文件,服务器读入该请求,但是从另一个由服务器创建并绑定某个临时端口的套接字发送它的应答,客户与服务器之间传送该文件的所有后续数据报都使用这个新的套接字,这样允许主TFTP服务器在文件传送发生时继续处理到达端口69的其他客户请求。
对于一个独立的TFTP服务器(不是由inetd调用的),有下图情形,我们假设子进程捆绑到新套接字上的临时端口是2134:

对于由inetd调用的TFTP服务器,我们知道大多UDP服务器把inetd配置文本行中的wait-flag字段指定为wait,该值导致inetd停止在相应套接字继续接收请求,直到相应子进程终止为止,从而允许该子进程读入到达该套接字的数据报:

作为inetd子进程的TFTP服务器调用recvfrom读入客户请求,然后fork一个自己的进程,并由该子进程处理该客户请求,TFTP服务器然后调用exit,以便给inetd发送SIGCHLD信号,告知inetd重新在绑定UDP端口69的套接字上接收请求。
IPv6允许应用为每个外出数据报指定最多5条信息:
1.源IPv6地址。
2.外出接口索引。
3.外出跳限。
4.下一跳地址。
5.外出流通类别。流通类别由两个字段组成:
(1)6位的区分服务码点(Differentiated Services Code Point,DSCP)。用于区分不同类型的服务。这些服务可以是网络提供商或应用程序定义的,它们的优先级和延迟要求不同。DSCP字段用于指定不同的数据包优先级,以便网络根据这些优先级为它们提供不同的服务。
(2)2位的显式拥塞通知(Explicit Congestion Notification,ECN)。用于指示网络是否出现拥塞。ECN允许端到端的通信在不丢失数据包的情况下,通知源主机网络拥塞的传送容量是否饱和,让源主机根据拥塞情况适当地调整自己的传输速率。
这些信息会作为辅助数据使用sendmsg函数发送,它们还有对应的套接字粘附选项,用于对所发送的每个分组隐式指定这些信息。IPv6还会为每个接收分组返回4条类似信息,它们同样作为辅助数据由recvmsg函数返回:
1.目的IPv6地址。
2.到达接口索引。
3.到达跳限。
4.到达流通类别。
以下是这些辅助数据:
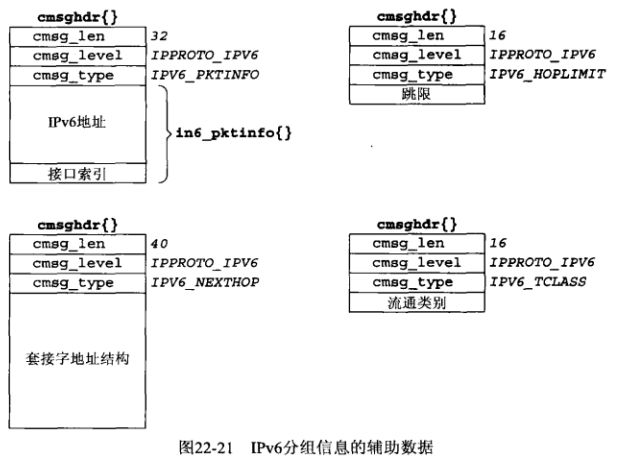
in6_pktinfo结构对于外出数据报含有源IPv6地址和外出接口索引,对接收数据报含有目的IPv6地址和到达接口索引:
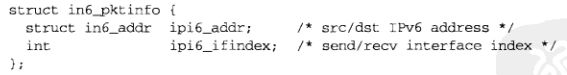
in6_pktinfo结构定义在头文件netinet/in.h中,包含本辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_PKTINFO,数据的第一个字节是in6_pktinfo结构的第一个字节,在图22-21中,对于in6_pktinfo辅助数据,我们假定cmsghdr结构与数据之间没有填充字节,且整数大小为4字节。
in6_pktinfo辅助数据有两个指定途径:如果针对单个数据报,就作为辅助数据调用sendmsg;如果针对通过某套接字发送的所有数据报,就设置IPV6_PKTINFO套接字选项,该套接字选项对应的值的类型为in6_pktinfo。该辅助数据只有在开启IPV6_RECVPKTINFO套接字选项的时候才会作为recvmsg函数的辅助数据返回。
IPv6节点的接口由正整数标识,任何接口都不会被赋予0值索引。指定外出接口时,如果ipi6_ifndex成员值为0,就由内核选择外出接口。如果应用为某多播数据报指定了外出接口,但就这个数据报而言,由辅助数据指定的接口将覆写由IPV6_MULTICAST_IF套接字选项指定的接口。
源IPv6地址通常通过调用bind指定,但连同数据一起指定源地址可能并不需要多少开销,后者还允许服务器确保所发送应答的源地址等于相应客户请求的目的地址,这是某些客户需要且IPv4难以提供的特性。
当作为辅助数据指定源IPv6地址时,如果in6_pktinfo结构的ipi6_addr成员是IN6ADDR_ANY_INIT,那么:
1.如果该套接字上已经绑定某个地址,就把它用作源地址。
2.如果该套接字上没有绑定任何地址,就由内核选择源地址。
如果ipi6_addr成员非IN6ADDR_ANY_INIT,且该套接字上已经绑定某个源地址,那么就本次输出而言,ipi_addr值将覆写已经绑定的源地址。内核将验证所请求的源地址是否是本机上某个单播地址。
当in6_pktinfo结构由recvmsg函数作为辅助数据返回时,其ipi6_addr成员含有取自所接收分组的目的IPv6地址,这类似于IPv4的IP_RECVDSTADDR套接字选项(该选项开启时,将目标IP地址作为控制信息返回应用)。
对于单播数据报,外出跳限通常使用IPV6_UNICAST_HOPS套接字选项指定,对于多播数据报,外出跳限通常使用IPV6_MULTICAST_HOPS套接字选项指定。不论目的地址为单播还是多播地址,作为辅助数据指定跳限允许我们单就某次输出操作覆写内核的默认值或早先指定的普适值。对于如traceroute之类的程序以及需验证接收跳限为255(表示分组未被转发过)的一类IPv6应用来说,返回接收跳限是有用的。
只有开启了IPV6_RECVHOPLIMIT套接字选项,接收跳限才能由recvmsg函数作为辅助数据返回。包含跳限的辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_HOPLIMIT,数据的第一个字节是4字节整数跳限的第一个字节。作为辅助数据返回的值是来自所接收数据报的真实值,而由getsockopt函数返回的IPV6_UNICAST_HOPS套接字选项值是内核将用于该套接字上外出数据报的默认跳限值。
要控制某分组的外出跳限,只要把控制信息指定为sendmsg函数的辅助数据。跳限的正常值为0~255(含),若为-1则告知内核使用默认值。
跳限没有包含在in6_pktinfo结构中原因在于,一些UDP服务器希望使用以下方式响应客户请求:从请求的接收接口发送应答,且所用IPv6源地址就是相应请求的IPv6目的地址。为了做到这一点,应用可以只开启IPV6_RECVPKTINFO套接字选项,然后把recvmsg函数接收到的控制信息用作sendmsg函数的外出控制信息,这样应用就不必检查或修改in6_pktinfo结构,如果把跳限包含在该结构中,那么应用需要分析接收到的控制信息,并修改跳限成员,因为接收跳限不是外出分组期望的跳限值。
IPV6_NEXTHOP辅助数据对象将数据报的下一跳指定为一个套接字地址结构。在包含下一跳辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_NEXTHOP,数据的第一字节是套接字地址结构的第一个字节。
图22-21中展示了下一跳辅助数据对象的一个例子,其中假设套接字地址结构是28字节的sockaddr_in6结构。下一跳地址标识的必须是发送主机的一个邻居。如果该地址等于数据报的目的IPv6地址,那么相当于已有的SO_DONTROUTE套接字选项。下一条地址也可对通过某套接字发送的所有数据报设置,方法是以一个sockaddr_in6结构设置IPV6_NEXTHOP套接字选项,设置该套接字选项需要超级用户权限。
IPV6_TCLASS辅助数据对象指定数据报的流通类别,包含流通类别辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_TCLASS,数据的第一个字节是4字节整数流通类别的第一个字节。流通类别由DSCP和ECN两个字段构成,它们必须一起设置,如果内核有必要控制这些值,它就屏蔽或忽略用户指定的值(如内核实现了ECN,它可能就不顾应用进程通过IPV6_TCLASS套接字选项设置的ECN值而自行设置ECN)。流通类别的正常值范围为0~255(含),若为-1则告知内核使用默认值。
如果为某一个给定分组指定流通类别,那么只需包含辅助数据;如果为通过某套接字的所有分组指定流通类别,就以一个整数选项值设置IPV6_TCLASS套接字选项。只有应用进程已开启IPV6_RECVTCLASS套接字选项时,流通类别才作为辅助数据由recvmsg函数返回。
IPv6为应用提供了若干路径MTU发现控制手段,默认设置对于大多数应用是合适的,但特殊目的程序可能想修改路径MTU发现行为,IPv6为此提供了4个套接字选项。
执行路径MTU发现时,IP数据报通常按照外出接口的MTU或路径MTU二者中较小值进行分片,IPv6定义了值为1280字节的最小MTU,该值必须被所有的链路支持。按照这个最小MTU进行分片可能丧失一些发送较大分组的机会,但避免了路径MTU发现的缺点(MTU发现期间的分组丢失和数据发送延迟)。
有两类应用可能会想使用最小MTU:使用多播的应用(为避免ICMP packet too big消息的爆发),以及向许多目的地执行短事务的应用(如DNS)。了解多播会话的MTU成本过高,还不如直接接收和处理数百万个ICMP packet too big消息,而DNS等应用通常不会经常与同一服务器通信,因此为了不经常出现的通信的丢包而去了解路径MTU也不值得。
使用最小MTU由IPV6_USE_MIN_MTU套接字选项控制。该选型有3个已定义的值:默认值-1表示对多播目的地使用最小MTU,对单播目的地执行路径MTU发现;0表示对所有目的地都执行路径MTU发现;1表示对所有目的地都使用最小MTU。
IPV6_USER_MIN_MTU选项值也可作为辅助数据发送,包含本辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_USE_MIN_MTU,数据的第一个字节是4字节整数的本选项值的第一个字节。
应用可开启IPV6_RECVPATHMTU套接字选项以接收路径MTU变动通知,本选项使路径MTU发生变化时,作为辅助数据由recvmsg函数返回变动后的路径MTU,此时recvmsg函数可能会返回0长度的数据报,但含有指示路径MTU的辅助数据,包含本辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_PATHMTU,数据的第一个字节是ip6_mtuinfo结构的第一个字节,该结构含有路径MTU发生变动的目的地和以字节为单位的新路径MTU值,它定义在头文件netinet/in.h中:

如果应用没有使用IPV6_RECVPATHMTU套接字选项跟踪路径MTU的变化,可用IPV6_PATHMTU套接字选项确定某个已连接套接字的当前路径MTU。该选项只能获取,选项值为ip6_mtuinfo结构。如果未能确定路径MTU,就返回外出接口的MTU。该选项返回的地址值没有定义。
默认IPv6协议栈将按照路径MTU对外出IP数据报执行分片,诸如traceroute之类程序可能不希望有自动分片特性,而是自行发现路径MTU。IPV6_DONTFRAG套接字选项用于关闭自动分片特性:默认0值表示允许自动分片,1值关闭自动分片。
关闭自动分片后,发送需要分片的分组时会返回EMSGSIZE错误,但实现并非必须有错误提示。确定某分组是否需要分片的唯一有效方式是使用IPV6_RECVPATHMTU套接字选项。
IPV6_DONTFRAG选项的值也可作为辅助数据发送,发送本辅助数据的cmsghdr结构中,cmsg_level成员值为IPPROTO_IPV6,cmsg_type成员值为IPV6_DONTFRAG,数据的第1个字节是4字节整数选项值的第一个字节。
有些应用需要知道某个UDP数据报的目的IPv4地址和接收接口,开启IP_RECVDSTADDR和IP_RECVIF套接字选项可以作为辅助数据随每个数据报返回这些信息。
尽管UDP无法提供TCP提供的众多特性,需要使用UDP的场合仍很多,广播或多播应用必须使用UDP。简单的请求-应答情形也可使用UDP,但需要在应用中增加某种形式的可靠性。UDP不应用于海量数据的传送。