集成学习-非成对多样性度量-个人总结
一、引言
集成学习:通过构建并结合多个学习器来完成学习任务。一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。结合策略主要有平均法、投票法和学习法等。
在集成学习之中,个体学习器之间的差异被称为“集成多样性”。如何理解集成多样性,是该学习范式的圣杯问题,即难以捉摸的、具有重大意义的目标。现有的集成多样性度量方法主要包括两类:一类是成对个体学习器的多样性度量,另一类是非成对个体学习器的多样性度量。本文主要对后一类进行讨论和总结。
二、准备工作
这部分声明一些基本的术语,因为下面的度量方法都是基于个体学习器展开计算的。个体学习器集合:![]() ;数据集:
;数据集:![]() ,其中
,其中![]() 分别为样本和类别标记,且
分别为样本和类别标记,且![]() 。
。
三、非成对多样性度量方法
1、Kohavi-Wolpert方差,简称KW度量,该度量由Kohavi和Wolpert在1996年提出。具体的计算方法为
![]()
其中, 为样本的个数,
为样本的个数, 为个体学习器的个数,
为个体学习器的个数,![]() 为个个体学习器对于样本
为个个体学习器对于样本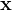 分类正确的个数且
分类正确的个数且![]() 。
。
由该等式可以看出,和视为常数,而最关键的地方在于![]() :当每个样本的
:当每个样本的![]() 都为的一半时,KW度量达到最大,此时多样性最大;而当每个样本的
都为的一半时,KW度量达到最大,此时多样性最大;而当每个样本的![]() 全为0或时,KW度量达到最小,此时多样性最小。这很好理解,每个样本的
全为0或时,KW度量达到最小,此时多样性最小。这很好理解,每个样本的![]() 如果都是0或的话,那么所有个体学习器的预测结果都是相同的;否则,如果每个样本的
如果都是0或的话,那么所有个体学习器的预测结果都是相同的;否则,如果每个样本的![]() 都是的一半的话,所有个体学习器的预测结果都有可能不一样,请注意,是有可能不一样,而不是绝对不一样。因此KW度量的多样性度量是存在一定的问题的。
都是的一半的话,所有个体学习器的预测结果都有可能不一样,请注意,是有可能不一样,而不是绝对不一样。因此KW度量的多样性度量是存在一定的问题的。
2、评分者间一致度(Interrater Agreement),即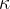 度量。度量用于分析一组分类器的一致性,它被定义为
度量。度量用于分析一组分类器的一致性,它被定义为
![]()
其中,![]() 为个体学习器的平均分类精度;而
为个体学习器的平均分类精度;而![]() 为指示函数,当括号中的条件为真时返回1,否则返回0。
为指示函数,当括号中的条件为真时返回1,否则返回0。
度量主要反映了个体学习器之间预测结果的一致性。当预测结果完全一致时,则的值为1;如果学习器之间的一致程度比随机的还差时(最极端的情况为:每个样本被正确分类的结果为个体学习器的一半且平均精度为0.5),则![]() 。因此,度量的值越大,说明个体学习器的预测结果越一致,但多样性就越小;反之则越大。
。因此,度量的值越大,说明个体学习器的预测结果越一致,但多样性就越小;反之则越大。
3、熵(Entropy)。Cunningham和Carney在2000年提出的熵度量计算方法为
![]()
其中,![]() 表示将
表示将![]() 预测为
预测为 的个体学习器占比 (占比的分母为)。显然,
的个体学习器占比 (占比的分母为)。显然,![]() 不需要知道个体学习器的正确率。
不需要知道个体学习器的正确率。
Shipp和Kuncheva在2002年提出的熵度量计算方法为
![]()
其中,![]() 为向上取整符号:如果
为向上取整符号:如果 为整数,则
为整数,则![]() ,如果不为整数,则
,如果不为整数,则![]() 的整数部分+1。
的整数部分+1。![]() 的取值范围是[0, 1],取为0时表示完全一致,取为1时表示多样性最大。值得注意的是,
的取值范围是[0, 1],取为0时表示完全一致,取为1时表示多样性最大。值得注意的是,![]() 没有使用对数函数,所以它不是经典的熵。尽管如此,该等式还是被用的更多,因为它更容易被实现而且计算速度也比较快。
没有使用对数函数,所以它不是经典的熵。尽管如此,该等式还是被用的更多,因为它更容易被实现而且计算速度也比较快。
4、困难度。假设对样本正确分类的个体学习器占比记为随机变量 ,那么困难度的计算方法为
,那么困难度的计算方法为
![]()
其中,随机变量的取值范围为![]() ,而的概率分布可以通过个分类器在数据集
,而的概率分布可以通过个分类器在数据集 上进行预测来估计。因此,随机变量的分布列为
上进行预测来估计。因此,随机变量的分布列为
|
 |
... |  |
|
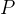 |
... |
 度量了样本的分类困难度,越小,则多样性越大。如果使用直方图对上述分布列进行可视化,当样本较难被分类时,直方图的分布区域将主要散落在左边,而当样本较易被分类时,直方图的分布区域将主要散落在右边。
度量了样本的分类困难度,越小,则多样性越大。如果使用直方图对上述分布列进行可视化,当样本较难被分类时,直方图的分布区域将主要散落在左边,而当样本较易被分类时,直方图的分布区域将主要散落在右边。
5、通用多样性。该度量的计算方法为
![]()
其中,![]() ,
,![]() ,而
,而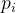 代表随机挑选的分类器在随机挑选的样本上预测失败的概率。
代表随机挑选的分类器在随机挑选的样本上预测失败的概率。![]() 度量的取值范围是[0, 1],当
度量的取值范围是[0, 1],当![]() =0时,多样性最小。该度量可以体现这样一个观点:当一个分类器预测错误伴随着另一个预测正确时、多样性最大。至于为什么能够做到这一点,我暂时还没有想明白,懂的同学请留言告诉我一下。
=0时,多样性最小。该度量可以体现这样一个观点:当一个分类器预测错误伴随着另一个预测正确时、多样性最大。至于为什么能够做到这一点,我暂时还没有想明白,懂的同学请留言告诉我一下。
6、同时失败度量。该度量是通用多样性的修改版本,计算方法为

当所有分类器同时给出相同的预测结果时cfd=0,如果每个分类器犯错的样本都不相同则cfd=1。抱歉,还是没看太明白。
四、小结
上边的多样性计算方法都是基于分类器实现的。其中,除了和评分者间一致度这两个,其它的度量指标都与集成多样性是正比的关系。
其实笔者也是刚刚入门集成学习这个领域,目前还有很多不懂的地方,如果有大佬看到请多多指教。各位如果有不太明白的地方,也欢迎在评论区中留言,共同探讨探讨这个集成学习的非成对多样性。
五、参考文献
1、百度百科: 集成学习
2、周志华. 集成学习: 基础与算法[M]. 电子工业出版社, 2020.