一文包揽:大模型、AI大模型、GPT模型
目录
一、大模型
1.1大模型是什么?
1.2为什么模型越大也好
二、AI大模型
2.1 AI大模型到底是什么?
2.2 AI大模型的优势
2.2.1 上下文理解能力
2.2.2 语言生成能力
2.2.3 学习能力强
2.2.4 可迁移性高
2.3国内哪些公司有大模型
三、GPT模型
3.1 什么是GPT模型
3.2 应用领域

随着大众对ChatGPT的深入了解,大模型成为了大家研究和关注的焦点。但是许多从业者写的内容阅读门槛确实太高了以及信息分散,对于不太了解的人员来说,确实不太好理解,所以我在这里一项一项说明,希望能帮助想了解相关技术的读者对 大模型、AI大模型、ChatGPT 模型有个大致的理解。
*注:本人非专业人员,以下表述可能会有不严谨或缺漏的地方,欢迎评论区指正。
一、大模型
1.1大模型是什么?
大模型是大规模语言模型(Large Language Model)的简称。语言模型是一种人工智能模型,他被训练成理解和生成人类语言。“大”在“大语言模型”中的意思是指模型的参数量非常大。
大模型是指模型具有庞大的参数规模和复杂程度的机器学习模型。在深度学习领域,大模型通常是指具有数百万到数十亿参数的神经网络模型。这些模型需要大量的计算资源和存储空间来训练和存储,并且往往需要进行分布式计算和特殊的硬件加速技术。
大模型的设计和训练旨在提供更强大、更准确的模型性能,以应对更复杂、更庞大的数据集或任务。大模型通常能够学习到更细微的模式和规律,具有更强的泛化能力和表达能力。

简单来讲就是用大数据模型和算法进行训练的模型,能够捕捉到大规模数据中的复杂模式和规律,从而预测出更加准确的结果。如果还不能理解,就好比我们在海里(互联网上)捞鱼(数据),捞很多的鱼,然后把鱼都放进一个箱子里,逐渐形成规律,最后就能达到预测的可能,相当于一个概率性问题,当这个数据很大很大量时,并且具有规律性,我们就能预测可能性。
1.2为什么模型越大也好
语言模型是一种统计方法来预测句子或文档中一系列单词出现的可能性的机器学习模型。在机器学习模型中,参数是历史训练数据中机器学习模型的一部分。在早期学习模型比较简单,所以参数比较少。但是这些模型在捕捉词语之间的距离依赖关系和生成连贯的有意义的文本方面存在局限性。像GPT这样的大模型具有上千亿的参数,与早期的语言模型相比,“大”了很多。大量的参数可以让这些模型能够捕捉到他们所训练的数据中更复杂的模式,从而使他们能够生成更准确的。
二、AI大模型
2.1 AI大模型到底是什么?
AI大模型是“人工智能预训练大模型”的简称。AI大模型包括了两层含义,一层是“预训练”,另一层是“大模型”,两者相结合产生了一种新的人工智能模式,即模型在大规模数据集上完成了预训练后无需或仅需要少量数据的微调,就能直接支撑各类应用。
其中,预训练大模型,就像知道所有大量基础知识的学生,完成了通识教育,但是还缺少实践,需要去实践后得到反馈后再做出精细的调整,才能更好地完成任务。还是需要不断去训练它,才能更好地为我们所用。

2.2 AI大模型的优势
2.2.1 上下文理解能力
AI 大模型具有更强的上下文理解能力,能够理解更复杂的语意和语境。这使得它们能够产生更准确、更连贯的回答。
2.2.2 语言生成能力
AI大模型可以生成更自然、更流利的语言,减少了生成输出时呈现的错误或令人困惑的问题。
2.2.3 学习能力强
AI大模型可以从大量的数据中学习,并利用学到的知识和模式来提供更精准的答案和预测。这使得它们在解决复杂问题和应对新的场景时表现更加出色。
2.2.4 可迁移性高
学习到的知识和能力可以在不同的任务和领域中迁移和应用。这意味着一次训练就可以将模型应用于多种任务,无需重新训练。
2.3国内哪些公司有大模型

目前,国内百度、阿里巴巴、腾讯、华为等公司拥有AI大模型,但各自模型系列各有侧重。百度在AI方面布局多年,具有一定大模型先发优势。百度的文心一言API调用服务测试的企业已经上亿。在行业大模型上,已经与国网、浦发、人民网等有案例应用。
阿里通义大模型在逻辑运算、编码能力、语音处理方面见长,集团拥有丰富的生态和产品在线,在出行场景、办公场景、购物场景有广泛应用。
三、GPT模型
3.1 什么是GPT模型
生成式预训练Transformer模型,通常称为GPT,是一系列使用Transformer架构的神经网络模型,是为ChatGPT等生成式人工智能应用程序提供支持的人工智能(AI)的一项关键进展。GPT模型使应用程序能够创建类似人类的文本和内容(图像、音乐等),并以对话方式回答问题。各行各业的组织正在将GPT模型和生成式人工智能用于问答机器人、文本汇总、内容生成和搜索。
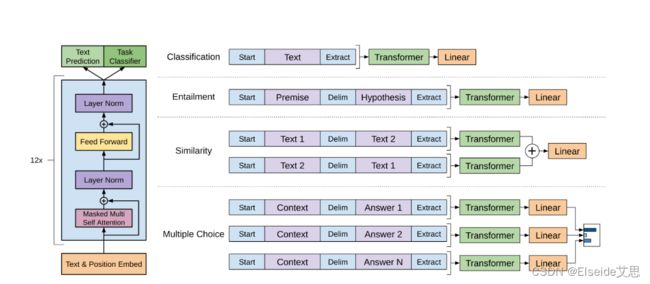
GPT模型是一种深度学习模型,采用了Transformer架构,可用于自然语言处理(NLP)任务。它通过大规模的预训练过程,从大量的互联网文本中学习语言的统计规律和语义关联。在预训练过程中,GPT能够通过多层自注意力机制捕捉长距离依赖关系,并且能够有效地建模上下文信息。
3.2 应用领域

自动文本生成:在自动文本生成方面表现出色。通过输入一段文本,可以生成与之连贯、合理的后续内容。这一特性使得它在自动写作、机器翻译和聊天机器人等任务上有着巨大的潜力。
语义理解:可以通过研究大量的语料库中的上下文信息,对文本进行深入的语义理解。它可以理解和解释复杂的问题,并能够作出有逻辑的回答。这一特点使得它在问答系统、智能助手和信息摘要等领域有着广泛的应用。
情感分析和舆情监测:可以分析文本中的情感色彩,并根据其情感倾向性进行分类。这种能力使得它成为了社交媒体舆情监测、用户评论分析和情感智能系统等领域的重要工具。
作为一种巨大的预训练语言模型,对于自然语言处理领域具有革命性的影响。其在自动文本生成、语义理解、情感分析和舆情监测等方面的应用已经初见成效。虽然还面临挑战和限制,但我们有充分的理由相信,未来的GPT模型将持续发展,在人工智能领域发挥着越来越重要的作用。