torchtext使用教程(文本预处理、数据集封装)
torchtext是一个用于文本预处理的库,使用起来也十分简便。
这是torchtext的github链接:https://github.com/pytorch/text
它主要包含了以下3大组件:
⭐Field对象:
指定要如何处理某个字段,比如指定分词方法,是否转成小写,起始字符,结束字符,补全字符以及词典等。
⭐Dataset类:
用于加载数据,torchtext的Dataset是继承自pytorch的Dataset,提供了一个可以下载压缩数据并解压的方法(支持.zip, .gz, .tgz)。splits方法可以同时读取训练集,验证集,测试集。TabularDataset可以很方便的读取CSV, TSV, or JSON格式的文件
⭐迭代器:
1.Iterator:普通的标准迭代器。
2.BucketIterator:相比于标准迭代器,会将类似长度的样本当做一批来处理,因为在文本处理中经常会需要将每一批样本长度补齐为当前批中最长序列的长度,因此当样本长度差别较大时,使用BucketIerator可以带来填充效率的提高。除此之外,我们还可以在Field中通过fix_length参数来对样本进行截断补齐操作。
3.BPTTIterator:基于BPTT(基于时间的反向传播算法)的迭代器,一般用于语言模型中。
⭐其他:
torchtext还提供了很多常用的文本数据集,可以直接加载使用。
导入相关库:
import pandas as pd
import torch
from torchtext import data
from torchtext.vocab import Vectors
from torchtext.data import TabularDataset,Dataset,BucketIterator,Iterator
from torchtext.data import Field, BucketIterator
from torch.nn import init
from tqdm import tqdm
import nltk
数据集准备:
如果我们有一份数据集,我们可以将其通过sklearn和pandas将其处理成3份csv:训练集、验证集、测试集。
这里我使用2份:即训练集和测试集。(当然csv、tsv、json格式torchtext的Dataset类也支持)
train_df = pd.read_csv('./train.csv')
test_df = pd.read_csv('./test.csv')
train_df.head(3)
数据集样子:

定义Field对象:
下面定义Field对象。我们对文本的处理,可以通过指定Field的参数来对我们的文本执行相关处理。
Field的参数:
squential:数据是否为序列数据,默认为Ture。如果为False,则不能使用分词。
use_vocab:是否使用词典,默认为True。如果为False,那么输入的数据类型必须是数值类型(即使用vocab转换后的)。
init_token:文本的其实字符,默认为None。 eos_token:文本的结束字符,默认为None。
fix_length:所有样本的长度,不够则使用pad_token补全。默认为None,表示灵活长度。
tensor_type:把数据转换成的tensor类型 默认值为torch.LongTensor。
preprocessing:预处理pipeline, 用于分词之后、数值化之前,默认值为None。
postprocessing:后处理pipeline,用于数值化之后、转换为tensor之前,默认为None。
lower:是否把数据转换为小写,默认为False;
tokenize:分词函数,默认为str.split
include_lengths:是否返回一个已经补全的最小batch的元组和和一个包含每条数据长度的列表,默认值为False。
batch_first:batch作为第一个维度;
pad_token:用于补全的字符,默认为。
unk_token:替换袋外词的字符,默认为。 pad_first:是否从句子的开头进行补全,默认为False;
truncate_first:是否从句子的开头截断句子,默认为False;
stop_words:停用词;
定义一个分词函数:
def tokenize_text(text):
#分词
token_list = nltk.word_tokenize(text)
#去停用词
filtered = [w for w in token_list if(w not in nltk.corpus.stopwords.words('my_english'))]
#词性标注,可以根据相应的词性进行过滤。这里不过滤先
rfiltered =nltk.pos_tag(filtered)
result = [i[0] for i in rfiltered]
return result
定义Field对象,TEXT用于处理文本,LABEL用于标签。csv里不需要的列,可以不用为其设置Field,直接设为None即可。
# 定义了两种Filed,分别用于处理文本和标签
# 因为不是机器翻译任务的话,就不设置init_token,eos_token了。pad_token默认为‘’
TEXT = Field(sequential=True,
tokenize=tokenize_text,
lower=True,
init_token = None,
eos_token = None)
LABEL = Field(sequential=False, use_vocab=False)
#csv里的每一列都要设置,不需要的类可以这样:(列名,None)
fields = [('review',TEXT),('label',LABEL)]
使用TabularDataset加载数据集并利用Field处理数据集:
使用TabularDataset处理,其能够很方便的读取csv、json或tsv格式的文件。当然如果我们有验证集的话,还可以传递validation参数。将上一步定义的Field传给fields参数即可对csv数据集进行处理。
train_data, test_data = TabularDataset.splits(
path='./',
train='train.csv',
test='test.csv',
format='csv',
skip_header=True,
sort_within_batch=False,
sort=False,
fields=fields)
看一看处理效果:
print(vars(train_data.examples[0]))
{‘review’: [‘the’, ‘difficulty’, ‘i’, ‘musical’, ‘version’, ‘\les’, ‘miserables\’, “’’”, ‘applies’, ‘equally’, “’’”, ‘oliver.\’, “’’”, ‘instead’, ‘composers’, ‘writing’, ‘stylistic’, ‘period’,…], ‘label’: ‘0’}
构建词典:
前面预处理完毕,现在建立词典,即单词->索引:
#设置最小词频为2,当一个单词在数据集中出现次数小于2时会被转换为字符。
TEXT.build_vocab(train_data, min_freq = 2)
print('词典里一共有:', len(TEXT.vocab),'个单词')
# print(vars(SRC.vocab).keys()) #可以看看里面有啥属性
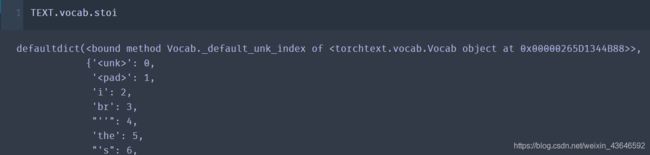
# TEXT.vocab.stoi #可以这样看词表
词典里一共有: 215 个单词
这个样子,词表(单词->索引):
当然torchtext也有现成的词向量:
通过下面vectors向量参数,可以生成为每个单词生成100维的向量。
下面下载glove词向量,第一次使用是会自动下载并保存在当前目录的 .vector_cache里面。
TEXT.build_vocab(train_data, vectors='glove.6B.100d', min_freq = 2)
看看词向量大小,可以看到词典里的215个单词都对应一个100维的glove向量:
TEXT.vocab.vectors.shape
torch.Size([215, 100])
这样就完成了单词->数字->词向量。不过不用这个现成的词向量也行,在模型里使用nn.embedding去训练也行。
torch.nn.embedding的使用方法可以参考:基于Pytorch的torch.nn.embedding()实现词嵌入层
使用BucketIterator迭代器封装数据:
使用BucketIterator迭代器处理数据集,使其按元素按batch的形式存储在迭代器中。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device,'能用')
train_iter, test_iter = BucketIterator.splits(
(train_data, test_data),
batch_sizes = (8,8),
device = device,
sort_within_batch=False)
batch = next(iter(train_iter))
查看一下batch里的属性:
#查看batch有什么属性,可以看到对应数据的列名就是它的属性
print(batch.__dict__.keys())
#可以这样取出数据和标签,即batch的属性
print(batch.review) #即每个单词对应一个字典里的索引
print(batch.label)
dict_keys([‘batch_size’, ‘dataset’, ‘fields’, ‘input_fields’, ‘target_fields’, ‘review’, ‘label’])
tensor([[ 0, 198, 5, …,
16, 121, 16],
[192, 0, 25, …, 66, 0, 11],
[ 0, 187, 0, …, 11, 0, 0],
…,
[ 1, 36, 1, …, 1, 1, 1],
[ 1, 0, 1, …, 1, 1, 1],
[ 1, 4, 1, …, 1, 1, 1]], device=‘cuda:0’)
tensor([0, 0, 0, 0, 0, 1, 0, 1], device=‘cuda:0’)
看一下batch的大小,可以看到,有8条数据,每条数据有462个单词(单词索引)
batch.review.shape
torch.Size([462, 8])
通过for循环读取BucketIterator迭代器封装的数据:
训练的时候可以通过for循环读出每个batch。并通过batch的属性取出数据和对应标签,传入模型训练:
#训练的时候可以通过for循环读出每个batch
#并通过batch的属性取出数据和对应标签,传入模型训练
for i, batch in enumerate(train_iter):
x = batch.review
y = batch.label
# optimizer.zero_grad()
# output = model(src, trg)
小小提醒:
比如在文本分类中,可以在embedding层即 nn.embedding() 里的参数:pading_idx = TEXT.vocab.stoi[’
在机器翻译中的话,可以不用设置padding_idx,可以在定义损失函数时设置 ignore_index = PAD_IDX 来忽略目标为
PAD_IDX = TRG.vocab.stoi['' ] #TRG即为机器翻译数据集的目标语言定义的Field对象。
criterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)
#使用交叉熵损失作为损失函数,由于Pytorch在计算交叉熵损失时在一个batch内求平均,
#因此需要忽略target为的值(在数据处理阶段,一个batch里的所有句子都padding到了相同的长度,不足的用补齐),否则将影响梯度的计算
这几个链接也可以参考:
【1】【Pytorch】【torchtext(一)】概述与基本操作
【2】[TorchText]使用
【3】Torchtext使用教程