学习记录——BiSeNetV1、BiSeNetV2、BiSeNetV3、PIDNet、CMNeXt
BiSeNetV1
BiSeNetV1为了在不影响速度的情况下,同时收集到空间信息和语义信息,设计了两条路:
Spatial Path: 用了三层stride为 2 的卷积,卷积+BN+RELU模块。最后提取了相当于原图像 1/8 的输出特征图。由于它利用了较大尺度的特征图,所以可以编码比较丰富的空间信息,并生成高分辨率特征图。
Contex Path: 上下文路径的backbone可以替换成任意的轻量网络,比如 Xception,ShuffleNet 系列,MobileNet 系列。可以看到,为了准确率考虑,Context Path 这边使用了类似 U-shape 结构的设计,最终进行了32倍下采样。不过,不同于普通的 U-shape,此处只结合了最后两个 Stage,这样设计的原因主要是考虑速度。值得注意的是,Context Path 依然在最后使用了 Global Average Pooling 来聚合特征、降维、减计算量,看下图中的ARM模块,通过全局池化+卷积+BN+sigmoid模块,设计了一个注意力机制(类似SENet),来学习每个通道特征的重要性。
Feature Fusion Module(特征融合) 在特征的不同层级给定的情况下,每层输出特征都有各自的重要性。特征融合模块首先连接 S p a t i a l P a t h Spatial PathSpatialPath 和 C o n t e x t P a t h Context PathContextPath 的输出特征,接着,通过批归一化平衡特征的尺度。下一步,像 SENet 一样,把相连接的特征池化为一个特征向量,并计算一个权重向量。这一权重向量可以重新加权特征,起到特征选择和结合的作用。
BiSeNetV2
双边引导聚合网络。重点在 Guided Aggregation上。
论文中重新简述了语义分割的的一些发展。
如下图a中,利用空洞卷积可以扩大感受野的能力,来替换下采样和上采样操作。
B图还是熟悉的Unet网络结构
C图就是BiSeNet中双端网络,一条路提取空间细节信息,另一条路提取语义抽象信息。

网络结构
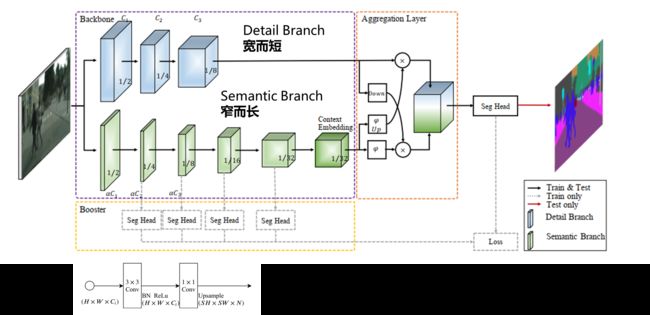
还是标准的双边网络,一条路负责细节信息,另一条路负责语义信息。
Detail Branch 三次下采样,最终下采用8倍,设计是遵循 宽而短 的原则。文中解释,这条路是为了获取细节信息,所有网络需要宽,也就意味着有更多的卷积核来提取细节特征。
Semantic Branch 4次下采样,最终下采样 16倍, 设计是遵循 窄而长的原则。原因是这条路为了提取深层次的语义特征,对网络深度有要求,为了效率速度,可以牺牲网络的宽度。

Stem和GE以及CE模块

CE 模块:从命名上看,是一个上下文编码模块。从网络结构上看,是为了融合 输入特征图中不同通道,可以看作对同一层不同通道间增加了一个注意力机制,全局池化提取全局信息,接1 ∗ 1 卷积后,与输入特征图相加,最后3*3卷积输出
Detailed design of Bilateral Guided Aggregation Layer

BiSeNetV3
2021
BiSeNetV3主要是在之前两个版本的BiSeNet模型的基础上进行思考与优化,考虑旧有模型的两个不足:1)主干网络简单借鉴分类任务缺乏对分割任务的针对性;2)多加一条额外通路用于编码空间信息增加了计算量。为此论文的解决方案是:1)提出一个短时密集连接网络STDCNet作为主干逐步对特征图进行降维聚合;2)提出一个细节聚合模块,以单一流的方式将空间信息的学习聚合到浅层网络中。
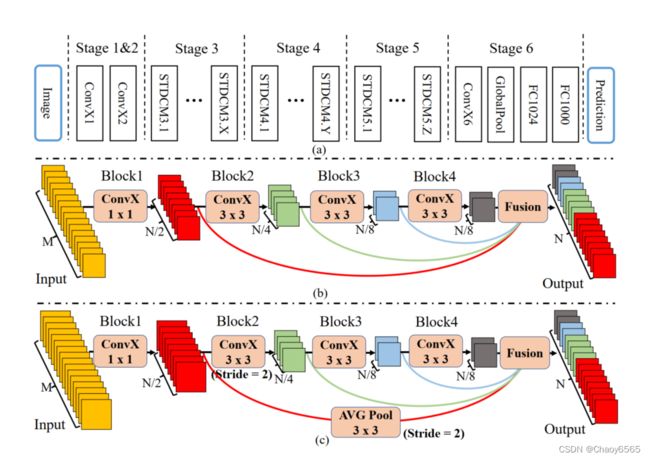
模型整体架构如下图所示,主干网络为STDCNet,Stage3、4、5输出的特征图下采样率分别为8、16、32,然后对大感受野的特征图应用全局平均池化,并应用ARM模块将两个不同阶段的特征图融合后,再与来自Stage3的特征图进行融合,输出8x下采样的特征图,最终分割头使用3×3CBR模块、1×1卷积和一个8x上采样来获得最终分割结果。

STDCNet短时密集聚合模块
如下图所示,单个stdc模块由多个CBR Blocks组成,除第一个Block的卷积核尺寸为1×1外,其余均为3×3,给定输入该模块的特征图通道数为N,前三个Block不断将其降为前一个Block的1/2,Block4则保持不变(快速通道降维然后多尺度融合以升维),下图©和下图(b)的区别在于前者在Block2阶段发生了下采样,然后应用3×3平均池化后参与融合。最后总是通过多个不同感受野的特征图concat实现多尺度信息的融合。
PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers
PIDNet:一个由PID控制器启发的实时语义分割网络
CVPR 2023
本文介绍了一种名为PIDNet的实时语义分割网络架构。虽然传统的双分支网络结构例如大家最熟悉的BiSeNet,其在实时语义分割任务中已经被证明有效。但是,作者认为直接融合高分辨率的空间细节信息和低频的上下文信息的方法存在缺陷,容易使得细节特征被周围的上下文信息淹没。这种现象被称为overshoot,限制了现有两分支模型的分割准确性的提高。
overshoot 即超调,是控制系统中一种普遍的现象,指的是系统在达到稳态之前或之后,输出变量会超过其最终稳态值的情况。在PID(即比例积分微分)控制器中,当反馈信号与期望值不同时,PID 控制器会根据比例、积分、微分三个部分计算出一个控制量来调整输出,从而使反馈信号逐渐接近期望值。但是在比例系数过大或系统响应过快时,控制器可能会产生超调现象,使得输出超过期望值一段时间,这可能导致系统出现震荡、不稳定等问题。
本文提出了一种新的三分支网络架构:PIDNet,其包含三个分支,分别用于解析:空间细节信息、上下文信息、边界信息。同时,采用边界注意力机制来指导空间细节信息分支和上下文信息分支的融合。
一个 PID 控制器包含三个组件:
比例(P)控制器 关注当前信号
积分(I)控制器 累加所有过去信号
微分(D)控制器
由于积分的惯性效应,当信号变化相反时,简单的 PI 控制器的输出会出现超调现象。因此通常会引入了 D控制器进行调节,当信号变小时,D分量将变为负数,并作为阻尼器减少超调现象。类似地,TBN,即双分支网络也是通过不同的卷积层来解析上下文和空间细节信息。
相比于空间细节信息分支,上下文信息分支对局部信息的变化不太敏感。换个角度理解,便是细节信息和上下文信息分支在空间域中的行为类似于时间域中的P(当前)和I(所有先前)控制器。
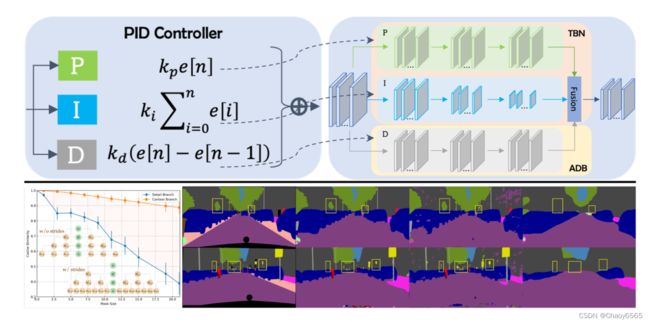
现有的双分支结构可以类比于 PI 控制器,这类控制器容易出现 overshoot 的问题。因此,为了缓解这个问题,本文在 TBN 上增加了一个辅助的导数分支 ADB,即在空间上模拟 PID 控制器,并突出高频语义信息。其中,考虑到每个 object 内部像素的语义是一致的,只有在相邻对象的边界处才会出现语义不一致,因此语义的差异仅在对象边界处为非零,所以 ADB 的目标是边界检测。遂本文建立了一种新的三分支实时语义分割体系结构,即比例-积分-微分网络——PIDNet,如下图所示。
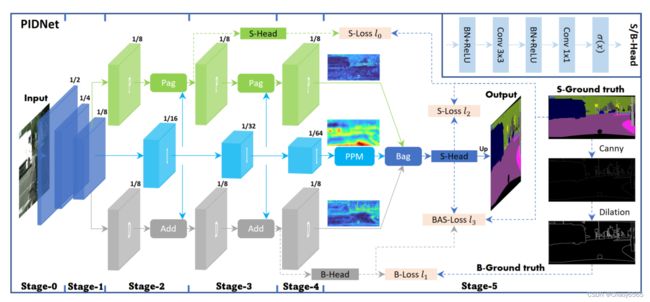
PIDNet 拥有三个分支,具有互补的职责:
比例分支负责解析和保留高分辨率特征图中的详细信息;
积分分支负责聚合局部和全局的上下文信息以捕获远距离依赖;
微分分支负责提取高频特征以预测边界区域。
同DDRNet一样,本文也采用级联残差块作为骨干网络,以更好地移植到硬件部署。此外,为了实现更加高效,作者将 P、I 和 D 分支的深度设置为适中、较深和较浅。因此,通过加深和加宽模型可以生成一系列 PIDNet 模型,即PIDNet-S、PIDNet-M和PIDNet-L,也就是做对网络架构进行缩放。
Pag: Learning High-level Semantics Selectively
即像素注意力引导模块,很好理解,就是将比例和积分分支的特征利用一个注意力机制进行交互增强。
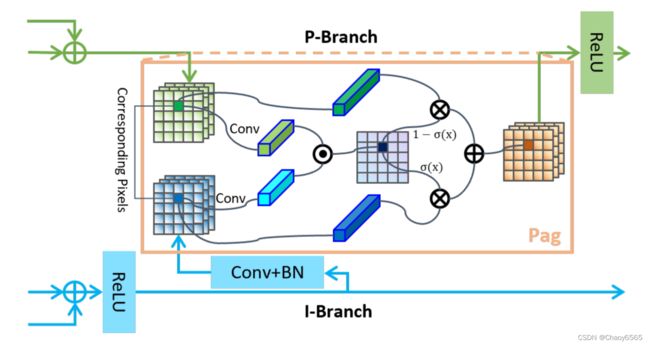
首先,作者提到了在其他语义分割网络中常用的横向连接lateral connection技术,该技术可以加强不同尺度的特征图之间的信息传递,提高模型的表达能力。而在 PIDNet 中,I 分支提供了丰富准确的语义信息,对于 P 和 D 分支的细节解析和边界检测至关重要。因此,作者将 I 分支视为其他两个分支的备用支持,并使其能够为它们提供所需的信息。此外,与 D 分支直接添加提供的特征图不同,作者为 P 分支引入了Pag 来选择性地学习 I 分支中有用的语义特征。
PAPPM: Fast Aggregation of Contexts
PPM,主要用于构建全局场景的先验信息。其主要对不同尺度的特征图进行池化操作,然后将不同尺度的池化特征图进行拼接,形成本地和全局上下文的表示。说白了就是个多尺度融合。
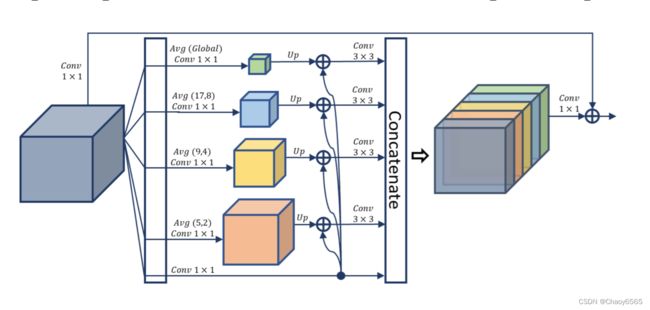
作者认为 PPM 虽然能够很好地嵌入上下文信息,但它的计算过程无法并行化,非常耗时,而且对于轻量级模型来说,PPM 包含的每个尺度的通道数太多,可能会超过这些模型的表示能力。因此,作者对 PPM 进行了修改,提出了一种可并行化的新的 PPM,叫做 Parallel Aggregation PPM, PAPPM,并将其应用于PIDNet-M 和 PIDNet-S 以保证它们的速度。对于深度模型 PIDNet-L,作者仍然选择 PPM,但减少了每个尺度的通道数,以减少计算量并提高速度。
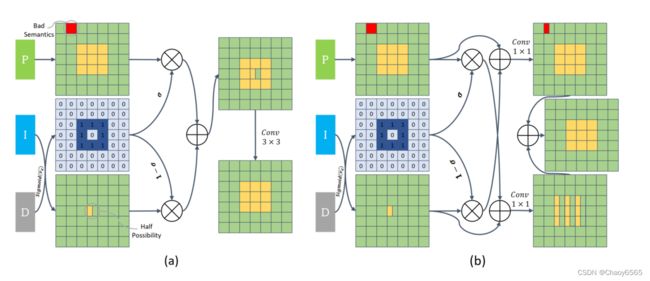
Bag: Balancing the Details and Context
边界注意力引导 Bag 模块的作用是利用边界特征来指导细节(P)和上下文(I)表示的融合,以实现更好的语义分割效果。作者指出,尽管上下文分支具有语义精度,但它在边界区域和小物体上丢失了太多的空间和几何细节,因此,PIDNet 利用细节分支来提供更好的空间细节,并强制模型在边界区域更加信任细节分支,同时利用上下文特征来填充其他区域。
Delivering Arbitrary-Modal Semantic Segmentation
CVPR 2023 任意模态语义分割
多模态融合可以让语义分割更加鲁棒,然而,融合任意模态的特征的方法目前还没有人探索。
因此,本文提出了DELIVER ,任意模态分割基准数据集, 覆盖了 Depth, LiDAR, multiple Views, Events, and RGB,该基准算在四种恶劣天气条件下以及五种传感器故障情况下提供的,以利用模态互补性并解决部分中断。
- 模态越多,性能应该是单调上升的。 但是以前的方法因为他们模态组合设计的缺陷没有展示出这一点
- 多个传感器同时运作有希望有效对抗单个传感器的损坏。大多数方法都假设每个传感器都精确运行。在现实机器人系统中常见的部分传感器故障(例如LiDAR抖动)下,融合不对齐的感知数据甚至可能会降低分割性能。
3种不同范式:
图2a的范式:单独分支,计算成本高
图2b的范式:单个联合分支,会丢弃有价值的信息
图2c的范式(CMNeXt):两个分支的非对称架构,一个用于RGB,另一个用于各种辅助模态(毕竟rgb信息往往更全面且广泛)。
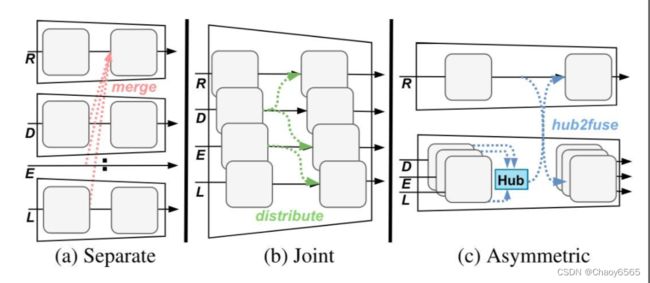
CMNeXt结构:
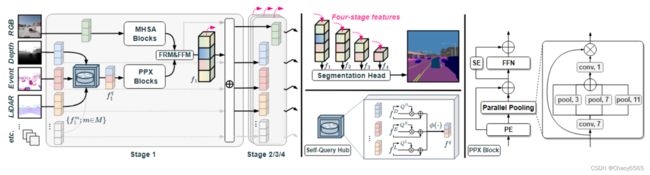
主要贡献:
本文为任意模态语义分割(Arbitrary-Modal Semantic Segmentation)(AMSS)创建了新的基准DELIVER,包含四种模态,四种恶劣天气条件,五种传感器故障模式。
本文回顾和比较了不同的多模态融合范式,并提出了采用非对称架构的Hub2Fuse范式来实现AMSS。
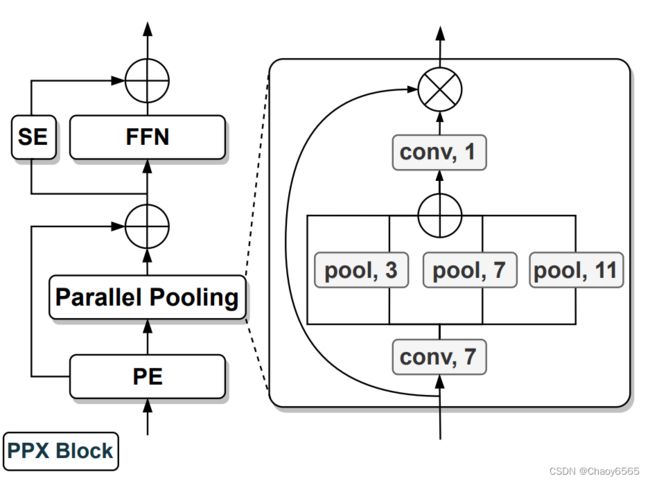
提出的了通用的任意跨模态融合模型(arbitrary cross-modal fusion model)CMNeXt,该模型具有用于选择信息特征的Self-Query Hub(SQ-Hub)和用于获取判别线索的Parallel Pooling Mixer(PPX)。
CMNeXt是两个分支的非对称架构,一个用于RGB,另一个用于各种辅助模态,其中的创新性结构为自查询中心SQ-Hub,它作用于与RGB分支融合之前,从所有模态中动态选择信息量大的特征,沿着Attention取最大值,可以减少计算量。
Self-Query Hub
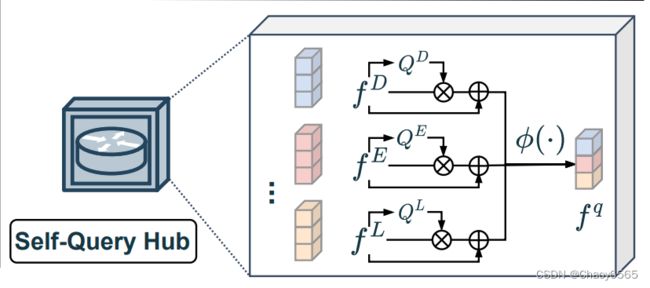
首先,对于每个模态的特征 fm ∈H×W ×C,先做一个dwconv、conv和sigmoid,得到代表informative score mask维度为H×W的 Qm

随后,将 Qm 与dwconv后的 fm 相乘,在与 fm 相加,最后沿着m(H×W×C×M)维度取最大值,就可以得到 fq ∈H×W×C。
整体上比较简单,因为每加一个模态,反应在计算量上也就是m维度上多了一维,所以计算量加的很少,最后选取最有用的信息的方式是取最大值,也是比较清晰简单的。
Parallel Pooling Mixer
End
以上仅作个人学习记录使用