论文悦读(1)——NVM文件系统之NOVA文件系统
NOVA文件系统
文章目录
- NOVA文件系统
-
- 1. 背景(Background)
-
- 1.1 NVM技术
- 1.2 NVM带来的挑战
- 1.3 常用的保证原子性/强一致性操作
- 1.4 当前基于NVM的文件系统
- 2. 动机(Motivation)
- 3. NOVA设计与实现(Design & Implementation)
-
- 3.1 观察(Observation)
- 3.2 设计原则(Overview)
- 3.3 NOVA实现(NOVA Implementation)
-
- 3.3.1 NOVA总体架构布局
- 3.3.2 NOVA原子性及写入顺序保证
- 3.3.3 目录操作
- 3.3.4 文件操作
- 3.3.5 原子mmap
- 3.3.6 垃圾回收
- 3.3.7 卸载与恢复
- 3.3.8 NVM保护
- 4. 评估(Evaluation)
-
- 4.1 Microbenchmarks
- 4.2 Macrobenchmarks
- 4.3 垃圾回收
- 4.4 挂载与恢复对比
- 总结
- Features
1. 背景(Background)
1.1 NVM技术
NOVA于2016年提出,当时的NVM设备包括:spin-torque transfer RAM (STT-RAM)、phase change memory(PCM)、resistive RAM(ReRAM)以及3D XPoint存储技术。
这些NVM普遍提供了比SSD更快的访问速度、非易失性以及字节级寻址能力。
NVM虽然比SSD快,但NVM都无法完全代替内存:要么因为访问延迟高于DRAM(PCM、ReRAM和3D XPoint),要么因为cell大小的限制(STT-RAM)。因为NVM的特性,因此NVM被部署在内存总线上,与DRAM并列,并且可以用内存访问指令对其读写。于是DRAM与NVM混合存储系统将无可厚非地变得普遍起来。
Tips 1: 值得一提的是,基本上所有文件系统都是DRAM与介质混合存储的系统。一般来说,为了加快访问速率,通常在DRAM里构建相应的索引数据结构,而在介质上保存元数据。
Tips 2: 有一篇文章专门介绍最近出来的Optane Memory介质特性,这将在后面补上。
1.2 NVM带来的挑战
主要有三点:性能、写入重排、原子性
-
性能
由于NVM在性能方面有着不俗于DRAM的表现,因此NVM的出现打破了软硬件协同之间的平衡。传统慢速存储设备,例如磁盘,他们在整个存储系统中占据了主要的访问延迟,此时我们可以暂时忽略软件开销。基于NVM的存储系统使得软件开销不得不被重视起来,不良的软件设计可能会浪费大量NVM所提供的性能优势。
由于NVM可以直接使用内存指令进行访问,因此,现有的基于NVM的文件系统常常绕过DRAM和缓存对NVM直接访问,避免从NVM到DRAM的拷贝。这种方式又被成为Direct Access(DAX)或eXecute In Place(XIP)。NOVA也是一个DAX文件系统。
-
写入重排
现代处理器和多级缓存结构为了提高性能,可能采取指令乱序方式。现有的一致性模型可以保证内存更新的一致性(可利用
mfence),但是不能保证这些更新何时到达NVM(由于缓存系统)。现有的方法是利用
clflush(理解为cache line flush)指令和mfence指令来强制将更新按照顺序刷回NVM,但是clflush每次刷回后,都会清除对应的cache line,这造成了巨大的性能开销。而内存屏障mfence也只能保证所有CPU能够看到一致的内存容貌,但不能保证更新从cache写回NVM的顺序。为了解决现有的问题,Intel提出
clflushopt、clwb等指令。其中clflushopt可以一次刷回多个cache line,是clflush的进阶版;clwb指令可以刷回一个cache line,而不去清除它。NOVA的设计要把这些指令时刻记在心里。 -
原子性
POSIX文件系统(传统Linux文件系统)要支持原子(All or Nothing) 操作。例如,
rename操作失败,那么要保证原来的文件不会被更改、新的文件不会被创建。存储设备只能提供最初级的原子性保证。例如,磁盘提供基于扇区的原子写入,而处理器只保证8字节的原子写入。
为了支持更复杂的原子更新,例如
rename对多个文件进行操作,那么就要用更复杂的机制来保证原子性。
1.3 常用的保证原子性/强一致性操作
传统的方法主要有三种:Journaling、Shadow pageing以及Log-structring
-
Journaling
很简单,更新之前先把更新先到Journal,然后再做更新。当系统崩溃后,重放Journal就能够恢复到系统一致的状态。但是Journaling常常需要两次数据写入,带来额外的开销。因此,常常只将元数据写到Journal中。
Back pointers和顺序解耦方法也能进一步减少Journaling的开销,我们拭目以待。
这两篇文章还没看,要准备看一下:
Back pointers:V. Chidambaram, T. Sharma, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. Consistency without ordering. In Proceedings of the 10th USENIX Conference on File and Storage Technologies, FAST ’12, pages 9–9, Berkeley, CA, USA, 2012. USENIX Association
顺序解耦:V. Chidambaram, T. S. Pillai, A. C. Arpaci-Dusseau, and R. H. Arpaci-Dusseau. Optimistic crash consistency. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles, SOSP ’13, pages 228–243, New York, NY, USA, 2013. ACM.
-
Shadow paging
即COW(Copy-on-Write)。在Shadow paging模式下,我们修改一个数据时,首先将数据拷贝,然后再对拷贝后的数据进行修改。
修改后,还要对管理这些数据的索引进行修改,这很可能引起连锁的指针修改(介质上肯定维护着指针,修改这些指针又需要进行COW,于是便引起连锁反应),这种开销是非常大的。
-
Log-structuring
又称为LFS(Log structured file system),这种文件系统最初是为磁盘设计的,LFS将随机写入合并为一个大的顺序写入,目的是最大程度利用磁盘的连续访问带宽。
另外,LFS也经常被应用于Flash文件系统中,这主要是因为Flash设备的写入寿命有限。
LFS的实现比较复杂,因为LFS必须保证一段连续的空闲空间,因此为了保证有这样一段连续空间,LFS必须不断回收过期数据。
日志的回收常常带来新的开销和性能的降低。为了缓解这个问题,有些LFS设计了冷热数据分离的策略,并且针对不同的数据采用不同的回收方法。
冷热数据分离这个策略,我一直没搞明白它们为什么能够减少cleaning的开销,这篇文章还得看看:
冷热分离: J. Wang and Y. Hu. WOLF-A Novel Reordering Write Buffer to Boost the Performance of Log-Structured File Systems. In Proceedings of the 1st USENIX Conference on File and Storage Technologies, FAST ’02, pages 47–60, Monterey, CA, 2002. USENIX
SFS: C. Min, K. Kim, H. Cho, S.-W. Lee, and Y. I. Eom. SFS: Random Write Considered Harmful in Solid State Drives. In Proceedings of the 10th USENIX Conference on File and Storage Technologies, FAST ’12, page 12, 2012.
1.4 当前基于NVM的文件系统
这些文件系统被设计用于解决1.2节提到的挑战,其中一些文件系统采用了1.3节提到的方法。但这些文件系统都没有满足所有要求:
-
BPFS
BPFS是基于Shadow paging的文件系统。它提供了元数据和数据的一致性。BPFS使用短路(Short circuit)Shadow paging技术来减少Shadow paging的开销。但是涉及到跨越多级树的文件操作(例如:mv操作)仍然会带来巨大的开销。
-
PMFS
PMFS是一个轻量级的DAX文件系统,它绕过了块层和文件系统缓存层,从而提升文件系统性能。PMFS使用Journaling方法来记录元数据的更新。但是在写入数据时是采用write in place(即像更新内存那样,直接修改对应位置的数据)的方法,这导致非原子性,文件系统一旦崩溃就会出现不一致的情况。
-
Ext4-DAX
Ext4-DAX拓展了Ext4,使得Ext4具有直接访问NVM的能力,并且同样使用Journaling方法来保证元数据更新的原子性。但是Ext4-DAX不支持对数据的Journaling,因此,数据的更新仍然不是原子的。
-
SCMFS
SCMFS利用OS层的虚拟内存管理模型,将文件映射为一大段虚拟内存,使得文件的访问变得轻量且简单。但是SCMFS并不提供任何元数据和数据的一致性保证。
-
Aerie
Aerie是用户态文件系统。它不用经过VFS层,因此性能得到了提升。然而,由于Aerie文件系统通过与一个可信进程TFS通信,TFS将造成主要的性能瓶颈。此外,Aerie仅仅对元数据进行Journaling,因此其并不支持数据更新的原子性。
这些NVM文件系统都值得被学习:
BPFS: J. Condit, E. B. Nightingale, C. Frost, E. Ipek, B. Lee, D. Burger, and D. Coetzee. Better I/O through byteaddressable, persistent memory. In Proceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles, SOSP ’09, pages 133–146, New York, NY, USA, 2009. ACM
PMFS: S. R. Dulloor, S. Kumar, A. Keshavamurthy, P. Lantz, D. Reddy, R. Sankaran, and J. Jackson. System Software for Persistent Memory. In Proceedings of the Ninth European Conference on Computer Systems, EuroSys ’14, pages 15:1–15:15, New York, NY, USA, 2014. ACM. https://github.com/linux-pmfs/pmfs
SCMFS: X. Wu and A. L. N. Reddy. SCMFS: A File System for Storage Class Memory. In Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’11, pages 39:1–39:11, New York, NY, USA, 2011. ACM.
Aerie: H. Volos, S. Nalli, S. Panneerselvam, V. Varadarajan, P. Saxena, and M. M. Swift. Aerie: Flexible File-system Interfaces to Storage-class Memory. In Proceedings of the Ninth European Conference on Computer Systems, EuroSys ’14, pages 14:1–14:14, New York, NY, USA, 2014. ACM.
2. 动机(Motivation)
现有的基于SSD或者磁盘的文件系统的软件开销将大大浪费NVM能够提供的设备性能,但是现在提出的基于NVM的文件系统要么软件开销大,要么不能为应用提供强一致性保证,因此提出NOVA。
NOVA旨在:
- 最大程度的提高NVM文件系统的性能表现;
- 提供强一致性保证;
NOVA的贡献如下:
- 为每个Inode分配一个独立的Log,从而提升并行性;
- Log只记录元数据而不记录数据,从而最小化Log并且减少垃圾回收开销;
- 对于数据,NOVA采用Shadow paging模式来保证其原子性;
- 对于多文件操作,NOVA通过轻量级Journaling保证原子性;
- 各种奇技淫巧,包括:Per-CPU Free List;Fast GC和Thorough GC;Lazy Rebuild技术等;
3. NOVA设计与实现(Design & Implementation)
3.1 观察(Observation)
NOVA的设计基于三点观察:
- 支持原子更新的Log很容易实现,但是查找内容的效率却并不高(必须扫描Log)。另外,在NVM介质上实现高效查找数据结构比较难。(UBIFS在介质上维护了一颗B+树,但查找时间都是O(logN));
- 日志型文件系统的难点在于需要一段连续的存储空间,但这对于NVM设备并非必须,因为NVM设备具有较好的随机访问速率;
- Log structred文件系统对磁盘来说是很有好的,因为磁盘仅有单一磁头,但是对于NVM来说,单个Log限制了并行性,因此可以采用multi Log形式;
3.2 设计原则(Overview)
-
Log布局在NVM上而索引布局在DRAM中
这是由于Log查询效率不高,但在NVM上实现高效查找数据结构较难的原因;
-
每个Inode独有一个Log
单个Log影响并行,每个Inode一个Log大大增强了并行性。此外,NOVA保证了有效Log Entry(Log的每一项称为Log Entry,Log Entry可以是指针,也可以是具体内容)
-
使用Log和轻量级Journaling机制来保证复杂的一致性更新
NOVA首先将Log Entry追加写到Log中,接着利用8B原子更新日志尾来提交日志,这样就避免了前面提到的两次写入问题(两次写入:可以理解为原来日志的机制是先写Log再写真实位置,而写到真实位置后,就相当于提交了此次写入;而这里修改日志尾就相当于提交写入了)
针对目录操作操作,NOVA首先写入数据,然后把各个尾部更新操作写入Journal中。这种Journal是非常轻量的,因为POSIX中定义的文件操作涉及到的Inode数不超过4个,因此只需要在Journal中最多保存4次文件尾部更新信息即可。
-
使用链表结构来组织Log
NOVA采用4KB NVM页面链表来组织Log,每个页面在末尾保存了指向下一个页面的指针。这是因为NVM并不需要靠局部性来保证访问性能,NVM自身具有不俗的随机访问性能。这样做有三个好处:
- 分配Log时,不需要分配一大块NVM的连续区域;
- NOVA可以以4KB页面为粒度来回收日志;
- 回收日志页面只涉及到几个指针的操作,非常轻量;(但还是需要拷贝有效的Log Entry)
-
不Log文件的数据
NOVA采用COW机制来更新数据页面,而将数据更新的操作记录为一个元数据写入到Log中。这个元数据描述了数据的更新以及指向被更新后的页面;
采用这种COW更新数据页面的原因有如下四点:
- Log更短,加速恢复;
- 垃圾回收更简单有效,因为NOVA不需要拷贝文件数据,只需要拷贝Log Entry;
- 回收页面和分配数据页面比较简单,因为只需要更新DRAM中的free list即可(这里的free list主要用于管理整个NVM的空闲4KB页面,采用红黑树结构管理)。如果将数据写到Log中,还需要为过期数据打上标记,不能立即回收;
- NOVA可以立即回收过时的数据页面,从而在写入量很大的情况下也能够很好的利用NVM的带宽。
Tips:
NOVA的设计原则是新颖的,它通过减少Log大小来降低GC的开销以及实现的复杂度;此外,它通过对数据进行COW和追加Log Entry的方式来保证数据的一致性,而由于NOVA通过内存红黑树来管理空闲页面,因此NOVA可以迅速回收过时数据页面。
NOVA日志结构亮点在于它采用了链表形式。
3.3 NOVA实现(NOVA Implementation)
3.3.1 NOVA总体架构布局

NOVA的NVM布局主要由四大部分组成:Superblock和Recovery Inode、Inode Tables、Journals以及Log/Data Pages。
其中,Superblock保存文件系统元数据信息;而Recovery Inode包括了再次挂载所需要的信息;
Inode Tables包含了Inodes;Journals保证多Inode操作的原子性;最后,NVM剩下的区域都是Log或者Data页面。
出于可拓展性(Scalability)考虑,NOVA为每个CPU都划分了Inode Table、Journal以及Free List(这是一个在DRAM中的结构,用于空闲页面分配),这避免了全局锁带来的瓶颈问题。
具体实现如下:
-
Inode Table
每个CPU下都维护一个Inode Table。Inode Table的大小初始为2MB。每个Inode按照128字节对齐,因此,Inode Table就类似于一个数组,可以通过Inode号直接访问到对应Inode。
NOVA按照round-robin方式(时间片轮转)分配Inode,所以Inode被均匀地分配在每个CPU所管辖的区域。
如果Inode Table满后,NOVA就为该Inode Table再次创建一个2MB大小的Inode Table作为子Table,以链表形式连接。另外,每个Inode Table的每一个位置还维护着一个有效位,使得可以NOVA可以重用无效Inode的空间。
NOVA的Inode包含了其Log的头指针head和尾指针tail,如前文所说,Log是由4KB页面的链式结构组成,tail总是指向最近一次提交的Log Entry。NOVA通过扫描head到tail的Log Entry来重建文件结构(内存结构,不管是目录文件还是普通文件,都采用Radix Tree来管理),该结构的建立是Lazy的,也就是只有要访问该文件时才会去建立。
-
Journal
NOVA的Journal是一个4KB循环Buffer结构。每个Journal可以被描述为
- NOVA首先将Log Entry加入到各Inode的Log中;
- 接着将各Inode的Log tail的值和地址写入Journal中(移动
Enqueue指针) - 更新各Inode的Log tail指针;
- 更新完毕后,利用原子操作让dequeue等于enqueue,说明已完成提交;
-
空间管理
NOVA为每个CPU管辖的区域分配一个Free List,用于管理该区域内的空闲页面。如果当前CPU管辖的Free List中没有空闲页面了,那NOVA便向剩余最多页面的Free List发起请求。每个Free List都持有独立的锁,从而保证一致性。NOVA使用红黑树来管理Free List。
NOVA不会时刻保存Free List的状态,在正常umount文件系统的时候,它才会将状态写回Recovery Inode中。如果非正常umount,NOVA便通过扫描所有Inode的Logs来重构Free List。
在为Log分配页面的时候,NOVA的做法比较激进。初始,一个Inode的Log只有一个Log Page。当该页面被写完后,NOVA就通过翻倍Log页面来扩展Log空间。当Log的长度大于某个阈值时,NOVA就每次添加固定数量的页面。
3.3.2 NOVA原子性及写入顺序保证
-
8B原子更新
NOVA用8B原子更新来提交Log、Journal等保证原子性;
-
Log
NOVA用Log来记录对每个Inode的操作,例如
write、msync、chmod等,从而保证原子性; -
轻量级Journal
NOVA通过Journal保证多Inode操作的原子性,例如对目录进行操作。在任何时候,Journal中的数据量不会超过64B,因为最复杂的POSIX调用
rename最多涉及对4个Inode的操作,NOVA只需要16B来Journal每个尾部更新操作:8B的Log tail地址,8B的Log tail值; -
强制写入顺序
NOVA依靠三种写入顺序来保证一致性,因此NVM必须要保证这种写入顺序的一致性:
- 先写数据,后更新Log tail;
- 先提交Journal,再更新各Inode的Log tail;
- 先写入数据,再回收脏页;
强制写入顺序模型如下:
new_tail = append_to_log(inode->tail, entry); clwb(inode->tail, entry->length); // writes back the log entry cachelines sfence(); // orders subsequent PCOMMIT PCOMMIT(); // commits entry to NVMM sfence(); // orders subsequent store inode->tail = new_tail;clwb保证被影响的cache lines都被刷回,sfence和PCOMMIT保证之前的命令全部到达NVM controller,接着的sfence保证Inode tail的更新不会发生在PCOMMIT之前。
3.3.3 目录操作
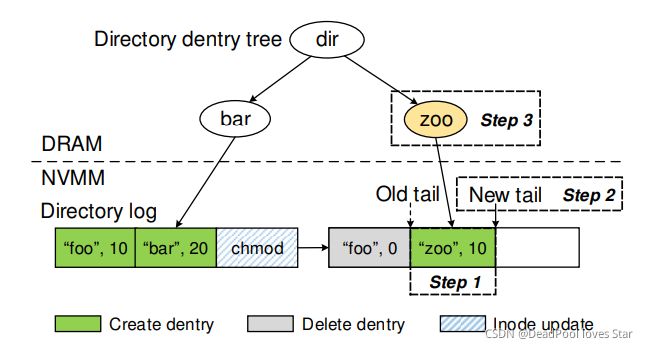
NOVA的目录结构如上图所示,其主要由两部分组成:NVM上的Log和DRAM中的Radix Tree,Radix Tree主要用于加速目录项的查找以及维护有效目录项。
目录文件的Log包含了两种Log Entry:Dentry和Inode update entry。
Dentry。包括所指目录/文件的名称、Inode号以及时间戳。NOVA创建、删除、重命名文件时都会向其Log添加一个Dentry。
Inode update entry。记录目录Inode的更改,包括chown、chmod等操作,它们需要修改Inode的多个字段,因此利用Inode update entry来记录能够保证原子性。
下面介绍创建、删除文件的目录操作:
-
创建文件zoo
Step 1: 在Inode table中为zoo分配一个Inode;
Step 2: 在当前目录的Inode Log中追加写入一个Dentry,该Dentry指向该Inode;(图中Step 1)
Step 3: NOVA在当前CPU的Journal中记录对该目录Inode的tail的更新以及将zoo对应的Inode标记为Valid的操作;(因为创建一个文件涉及到对两个Inode的操作)
Step 4: NOVA完成Step 3中记录的操作,并提交Journal;(图中Step 2)
Step 5: NOVA更新DRAM中的Radix Tree;(图中Step 3)
-
删除文件zoo(图中无显示)
Step 1: 在当前目录的Inode Log中追加写入一个Dentry,该Dentry的名字为zoo,但是Inode号指向0,表明删除zoo;
Step 2: 在zoo文件对应的Inode中追加写入一个Inode update entry(3.3.4节介绍);
Step 3: 利用Journal记录步骤1、2的操作;
Step 4: 完成各Inode的Log Tail更新;
Step 5: 更新DRAM中的Radix Tree;
3.3.4 文件操作
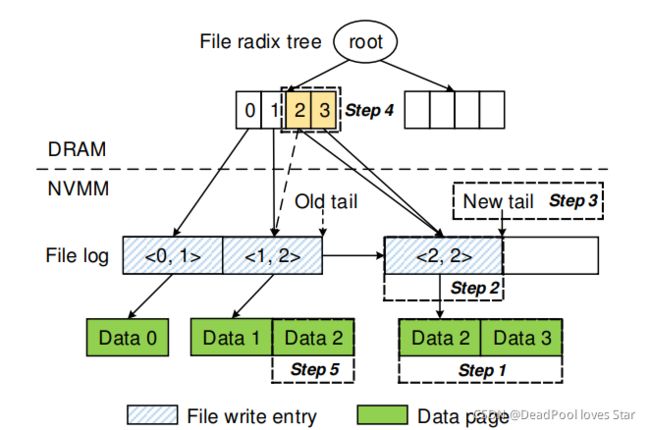
NOVA的普通文件结构如上,其结构与3.3.3节中的目录结构相似:DRAM中的Radix Tree用于索引Log中的数据,NVM上的Log记录着文件的组成。
普通文件的Log同样由两种Log Entry构成:Inode update entry和file write entry。
Inode update entry。记录了一些列对文件Inode的操作,包括3.3.3节中提到的将整个Inode标记为Invalid。
File Write entry。该Entry包含时间戳和文件大小,于是write操作能够在写入数据的同时原子地更新文件Inode的属性。DRAM中的Radix Tree的将文件的偏移映射到各个file write entry上,如上图所示。其中pgoff开始连续num pages个数据页面。
如果write 写入的数据过大,且NOVA不能找到连续的页面来表示,即不能用单一一个file write entry来表示此次写入,那么NOVA就将该次写入拆分为多次写入,并且通过将所有Entry都写入后再更新tail来保证此次写入的原子性。
对于read操作,NOVA直接通过Radix Tree定位到所需的Page,然后将数据从NVM上拷贝到用户Buffer中。(这里使用copy_to_user,这会不会带来性能瓶颈?)
上图表明,已经在文件第0位置写入了1个数据页面且在文件第1位置写入了2个数据页面,相当于该文件此时有12KB的数据(1个页面4KB、2个页面8KB)。最后,上图正在进行第三次写入——希望在文件第2位置写入2个数据页面,也就是8KB数据。整个流程如下:
Step 1: NOVA分配Data Page并且将数据填充进去;
Step 2: 在文件Log中添加<2,2> file write entry;
Step 3: 更新tail以提交写入;
Step 4: 更新内存中的Radix Tree指针;
Step 5: NOVA立即回收原来的Data 2;(直接将Data 2所在页面加入当前CPU的Free List即可)
3.3.5 原子mmap
mmap为上层应用提供了直接访问NVM的能力,但是程序员难以通过简单的原子操作在NVN上维护健壮的结构。因此,NOVA提出atomic-mmap,其主要思想为拷贝,把拷贝后的数据映射到用户空间供用户使用。
一旦用户调用msync(即将mmap的内容刷回文件),那么就通过3.3.4节介绍的方法把数据写回文件,保证原子性。
这样的mmap机制会带来更大的性能开销,不过带来了强一致性保证。
Tips:
那么,其实很容易想到这种方式存在的问题:
要mmap的空间过大。没有足够的空间供atomic-mmap复制拷贝;
性能开销大。
NOVA-Fortis一文中讲到单用mmap是不可能完成原子性保证的,为此,作者给出两个办法:
- caveat DAXor(let the DAXer beware)。使用mmap的人要自己维护数据一致性;
- snapshot。通过为文件系统建立快照来回滚到上一个状态;
3.3.6 垃圾回收
NOVA回收Data page是立即回收,另外的垃圾回收工作主要是回收Inode Log中的Log Entry。满足如下条件的Log Entry即被认为是过期的:
- File Write Entry不指向任一有效的Data page;
- Dentry被标记为Invalid;
- Inode Update Entry修改的元数据后来被另一个Inode Update Entry修改;
有两种垃圾回收机制来回收过期的Log Entry:

-
Fast GC
Fast GC强调回收速度,因此在Fast GC阶段不需要任何拷贝工作。Fast GC在NOVA即将拓展Log的时候被触发。
Fast GC主要工作为:如果一个Log Page的所有Entry都是Invalid的,那么Fast GC就将这个Log Page移除Log。
如上图(a)所示。发现Log Page 2全是Invalid Log Entry,Fast GC就立即回收该页面。
-
Thorough GC
在做Fast GC的时候,NOVA会计算有效Log Entry占用的空间。如果有效Log Entry占用的空间少于整个Log占用空间的50%,那么NOVA在Fast GC后机会做Thorough GC。
Thorough GC将有效Entry拷贝合并起来,写到全新的Log Page中,将新的Log Page原子地加入到Log中,最后回收原来的Page。
Thorough GC的模式如上图(b)所示。首先分配一个新的页面Log Page 5,然后将Page 1、3的有效Entry拷贝到Page 5中,更新Page 5的尾指针,使之连接到Page 4,最后原子地更新Log head指针,释放Page 1、Page 3(将他俩放到Free List里),从而保证整个过程的原子性。
3.3.7 卸载与恢复
正如我们在3.3.1节Inode Table部分讲到的一样,在挂载的时候,NOVA并不会将每一个Inode的Radix Tree结构都建立起来,而是采用Lazy的方式去建立,这样大大加速了挂载速率。
因此,挂载NOVA只需要重构内存中的Free List(还记得吗?这个结构被用于管理NVM上的空闲页面)结构即可。
为此,NOVA在卸载的时候,会将Free List的状态放到Recovery Inode中,从而加速挂载速率。效果是显著的,NOVA挂载50GB的文件系统只需要1.2ms。
如果系统没有正常卸载,即系统提前崩溃(NOVA大概率可以从Recovery Inode中检查到这个事实)。此时,NOVA必须扫描每个Inode的Log,然后重建所有Free List。这时,得益于Log的设计理念,NOVA只需要扫描整个NVM的少部分就能够完成恢复(因为每个Log只保存Entry,比较短小)。
NOVA的恢复流程具体如下:
-
NOVA检查Journal,并且回滚每一个没有提交(
Enqueue != Dequeue)的Journal,以此恢复文件系统的一致性; -
NOVA并行地扫描每个Inode Table,并且通过扫描Valid Inode的Log来重建Free List。对于不同的Inode恢复策略不同:
对于目录Inode。 NOVA仅需要记录其Log Page数量;
对于文件Inode。 NOVA不仅记录Log Page的数量,还得扫描每个File Write Entry,来获取Data Page的数量;
Tips:
这里是否存在BUG?目前论文里并没有提及被回收的Data Page是否有另外的标记来表明其被回收,因此,如果在恢复过程中,不能发现这一点,那么Free List中就会少一些空闲页面,可以参考3.3.4节,即讨论Page 2所在的页面是否应该被纳入考虑。
事实上,NOVA采用位图机制来记录NVM每一页的情况。因此计算的页数不可能多余NVM的总页数。但是这种做法可能会导致一些本来是空闲的页面在上层来看是非空闲页面。当访问该页面所在的文件时,该BUG才可能被修复。
上面是个人理解,还是要Show me code才行。
3.3.8 NVM保护
内核会将NVM的地址空间映射到内核自身的地址空间中,因此,NVM可能受scribble的影响(即一些错误的向NVM的写入,这可能会将NOVA的布局毁坏)。为了避免这种情况发生,NOVA采用了CR0.WP写保护机制。
一开始,NVM被映射为只读模式。当NOVA要写入的时候,NOVA禁用CR0.WP,执行写入完成后开启CR0.WP,并且在这个过程中保持中断关闭状态。从而保护NVM。
Tips:
事实上,NOVA-Fortis一文中,作者提到misdirected writes,这种错误来自于硬件故障,这会导致NOVA自身写入到错误的地址。因此CR0.WP并不能完美避免scribble。
NOVA-Fortis通过replica备份的方法来降低scribble带来的风险,并通过BAR(Bytes At Risk)指标来评估各种scribble带来的风险。
4. 评估(Evaluation)
NOVA的评估分为Microbenchmarks和Macrobenchmarks,这也是FAST会议上比较常见的评估方式。另外,NOVA还对垃圾回收、挂载与恢复速度做了评估,评估结果一致说明NOVA的各方面性能表现对比当时的NVM文件系统都是NO.1。
4.1 Microbenchmarks
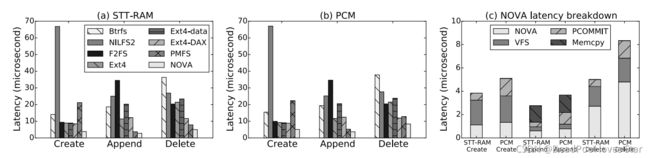
该Microbenchmarks的测试方法为:创建10000个文件,然后为每个文件追加写16个4KB数据,最后调用fsync来持久化文件,最终删除它们。
可以看到,作者这里评估的是文件系统的文件创建(Create)、追加写(Append)以及删除(Delete) 操作。NOVA在STT-RAM、PCM上的性能都远超其他文件系统。
这里Delete延迟明显大于Create和Append,这是因为Delete需要一次性回收文件里的所有数据页面,需要遍历整个文件Log。
这里没有进行目录操作对比。
Questions:
为什么PMFS的Create这么慢?
4.2 Macrobenchmarks
Macrobenchmarks采用下面的工作负载进行测设:
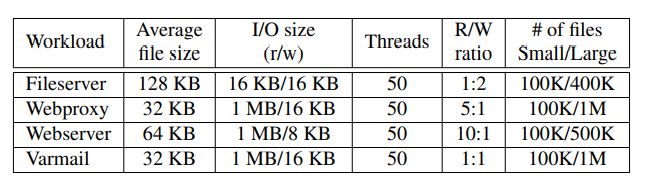
包括Fileserver、Webproxy、Webserver以及Varmail。测试结果如下所示:
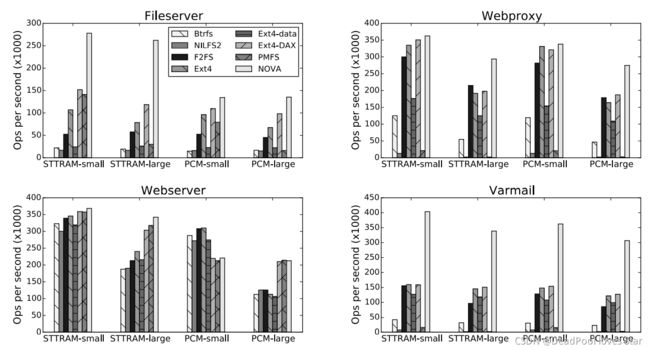
这里评测环境是基于STT-RAM和PCM。其中STT-RAM的读速率比PCM快很多。
其中,可以看到在Webserver途中,在PCM-small中,NOVA性能不及非DAX文件系统,这是因为非DAX文件系统会利用DRAM中的页面缓存,而Webserver是以读主导的工作环境,PCM的读速度不及DRAM,因此对于小数据的读取(PCM-small,small代表小文件),非DAX文件系统更具优势。
Tips:
这里再次讲一讲DAX文件系统与非DAX文件系统。DAX代表Direct Access,表明绕过DRAM page cache,直接操作设备。传统SSD、磁盘文件系统都是非DAX的,这是因为SSD、磁盘的速度远低于DRAM,将数据缓存在DRAM中,比直接访问设备的性能要快很多。而由于NVM设备的特性(性能远超SSD,接近于DRAM),利用DAX方式对其访问的效果要更加理想。
4.3 垃圾回收

垃圾回收测试是这样设计的:在95%占用率的NVM上(60.8GB?),运行30GB的fileserver工作负载,记录不同运行时间下的IOPS数。
上图是垃圾回收结果。其中,表的底部# GC pages代表NOVA文件系统Fast GC和Thorough GC回收的页面数。
Tips:
这里fileserver的配置应该和4.2节一致。平均文件大小为128KB,也就是每个文件平均只有128KB / 4KB = 32个数据页面,每个Entry最大为64B,那么只需要2048B,一个Log Page(4KB = 4096B)可能都占不满。
4.4 挂载与恢复对比

测试工作负载如上所示。测试结果如下,其中normal代表正常卸载与正常挂载,failure代表异常卸载 + 重新挂载。
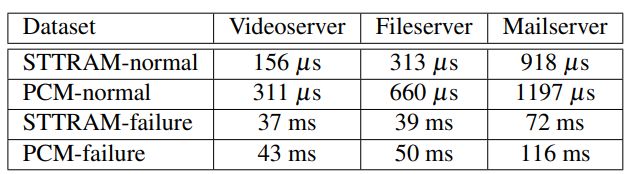
STT-RAM的读性能比PCM高很多,因此STT-RAM的挂载与恢复性能都高于PCM。另外,从上图可以看出,NOVA在116ms内恢复了50GB的负载,恢复带宽高于400GB/s。
总结
NVM带来的挑战主要是性能保证与强一致性保证。
NOVA采用Per-inode Log、CoW、Lightweight Journal等机制来保证强一致性。
针对NVM的特点,NOVA做了如下设计:
- 随机访问快。针对这一点,设计了Linked Log,而不是为Log分配一大段连续空间;
- 与DRAM速度接近。针对这一点,NOVA采用DAX访问模式;
- 8B原子更新。Lightweight Journal和Log的commit机制,GC的更新机制都是借助8B原子更新。
- 并行访问。Per-Inode Log结构,Per-CPU Free List、Inode Table、Journal结构,都是利用了NVM的并行访问特性来最大化NOVA的系统性能;
那么,NOVA到底优于PMFS在何处?为什么NOVA在保证了Data的原子性的同时(利用COW),却还能在写入性能上比PMFS的性能更好?也许是因为测试工作负载的线程数为50,而NOVA的设计很好地利用了并发性,因此在写入负载较大的环境下,NOVA性能远高于PMFS。
这或许在告诉我们一个事实:现如今,由于各种硬件性能的上升,使得文件系统的部分结构、策略设计对其性能影响已经不是那么显著,而去设计一个支持高并发的文件系统,这或许是突破瓶颈的关键。FAST 21有一篇KucoFS,这个文件系统暴打NOVA和其他文件系统,因为它进一步开拓了文件系统并行化的能力。KucoFS我们将在后面去讲到。
Features
- Per-Inode Log.
- Small log. Log one-inode metadata changes.
- Linked log. The log pages are linked by link list.
- Lightweight Journal. Journal for multiple inode changes.
- Atomic commit by update log tail.
- Per-CPU free-list, maximum concurrency.
- Fast GC and Thorough GC.
- Use Radix Tree to Manage file and dentries.