深度学习的技术原理
目录
人工智能
深度学习的应用场景
神经网络
卷积神经网络(CNN)
一个神经网络运行的可视化展示
人工智能
信息技术是人类历史上的第三次工业革命, 计算机、 互联网、智能家居等技术的普及极大地方便了人们的日常生活。
通过编程的方式,人类可以将提前设计好的交互逻辑重复且快速地执行, 从而将人类从简单枯燥的重复劳动任务中解脱出来。 但是对于需要较高智能的任务,如人脸识别, 聊天机器人, 自动驾驶等任务, 很难设计明确的逻辑规则, 传统的编程方式显得力不从心,而人工智能技术是有望解决此问题的关键技术。
随着深度学习算法的崛起,人工智能在部分任务上取得了类人甚至超人的水平。
人工智能,机器学习,深度学习的概念以及它们之间的联系与区别。
人工智能是指让机器获得像人类一样的智能机制的技术,这一概念最早出现在 1956 年召开的达特茅斯会议上。 这是一项极具挑战性的任务。
1970 年代,科学家们尝试通过知识库+推理的方式解决人工智能,通过构建庞大复杂的专家系统来模拟人类专家的智能水平。 这些明确指定规则的方式存在一个最大的难题,就是很多复杂,抽象的概念无法用具体的代码实现。比如人类对图片的识别,对语言的理解过程,根本无法通过既定规则模拟。 为了解决这类问题,一门通过让机器自动从数据中学习规则的研究学科诞生了,称为机器学习,并在 1980 年代成为人工智能中的热门学科。
在机器学习中,有一门通过神经网络来学习复杂、抽象逻辑的方向,称为神经网络。神经网络方向的研究经历了 2 起 2 落, 并从 2012 年开始,由于效果极为显著,应用深层神经网络技术在计算机视觉、 自然语言处理、机器人等领域取得了重大突破,部分任务上甚至超越了人类智能水平, 开启了以深层神经网络为代表的人工智能的第 3 次复兴。深层神经网络有了一个新名字,叫做深度学习, 一般来讲, 神经网络和深度学习的本质区别并不大,深度学习特指基于深层神经网络实现的模型或算法。 人工智能,机器学习,神经网络,深度学习的相互之间的关系如图所示。

神经网络算法是一类通过神经网络从数据中学习的算法,它仍然属于机器学习的范畴。 受限于计算能力和数据量, 早期的神经网络层数较浅, 一般在 1~4 层左右, 网络表达能力有限。随着计算能力的提升和大数据时代的到来, 高度并行化的 GPU 和海量数据让大规模神经网络的训练成为可能。
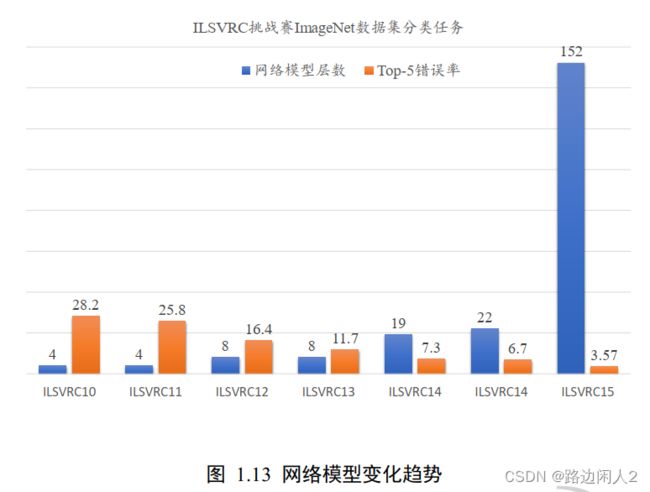
2006 年, Geoffrey Hinton 首次提出深度学习的概念, 2012 年, 8 层的深层神经网络AlexNet 发布,并在图片识别竞赛中取得了巨大的性能提升,此后数十层,数百层,甚至上千层的神经网络模型相继提出,展现出深层神经网络强大的学习能力。我们一般将利用深层神经网络实现的算法或模型称作深度学习,本质上神经网络和深度学习是相同的。
我们来比较一下深度学习算法与其他算法,如图 1.3 所示。基于规则的系统一般会编写显示的规则逻辑,这些逻辑一般是针对特定的任务设计的,并不适合其他任务。传统的机器学习算法一般会人为设计具有一定通用性的特征检测方法,如 SIFT, HOG 特征,这些特征能够适合某一类的任务,具有一定的通用性,但是如何设计特征方法,特征方法的好坏是问题的关键。神经网络的出现,使得人为设计特征这一部分工作可以通过神经网络让机器自动学习,不需要人类干预。 但是浅层的神经网络的特征提取能力较为有限,而深层的神经网络擅长提取深层,抽象的高层特征,因此具有更好的性能表现。

深度学习数据量非常大
随着神经网络的兴起,尤其是深度学习, 网络层数较深, 模型的参数量成百上千万个,为了防止过拟合,需要的数据集的规模通常也是巨大的。现代社交媒体的流行也让收集海量数据成为可能,如 2010 年的 ImageNet 数据集收录了 14,197,122 张图片, 整个数据集的压缩文件大小就有 154GB。

网络模型变化趋势
深度学习的应用场景
计算机视觉
图片识别、目标检测、语义分割

视频理解、图片生成

自然语言处理
机器翻译、聊天机器人
强化学习
虚拟游戏( AlaphGO) 、机器人、自动驾驶

通用的人工神经网络结构,同时,我们也可以构建另种结构的神经网络(这里的结构指的是两个神经元的连接方式),即含有多个隐藏层的神经网络。例如有一个有nl层的神经网络,那么第1层为输入层,第n层是输出层,中间的每个层l与H+1层紧密相联。在这种构造下,很容易计算神经网络的输出值,我们可以按照之前推出的式子,一步一步地进行前向传播,逐个单元地计算第L2层的每个激活值,依此类推,接着是第L3层的激活值,直到最后的第Ln层。这种联接图没有回路或者闭环,所以称这种神经网络为前馈网络。
除此之外,神经网络的输出单元还可以是多个。举个例子,图3的神经网络结构就有两层隐藏层:(L2和L3层),而输出层L4层包含两个输出单元。
神经网络模型是人工智能最基础的模型,它的创新是受益于神经科学家对大脑神经元的研究。神经网络通过我自学习的方式可以获得高度抽象的信息,以及手工特征无法获取到的特征,在计算机视觉领域取得了革命性的突破。而神经网络之所以最近几年在多个工业领域取得的这么大的成功,反向传播算法是一个很重要的原因。
神经网络
全连接神经网络(FCN)
全连接神经网络是深度学习最常见的网络结构,有三种基本类型的层: 输入层、隐藏层和输出层。当前层的每个神经元都会接入前一层每个神经元的输入信号。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个非线性激活函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射。


卷积神经网络(CNN)
图像具有非常高的维数,因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。卷积神经网络提供了一个解决方案,利用卷积和池化层,来降低图像的维度。由于卷积层是可训练的,但参数明显少于标准的隐藏层,它能够突出图像的重要部分,并向前传播每个重要部分。传统的CNNs中,最后几层是隐藏层,用来处理“压缩的图像信息”。

变分自动编码器(VAE)
自动编码器学习一个输入(可以是图像或文本序列)的压缩表示,例如,压缩输入,然后解压缩回来匹配原始输入,而变分自动编码器学习表示的数据的概率分布的参数。不仅仅是学习一个代表数据的函数,它还获得了更详细和细致的数据视图,从分布中抽样并生成新的输入数据样本。
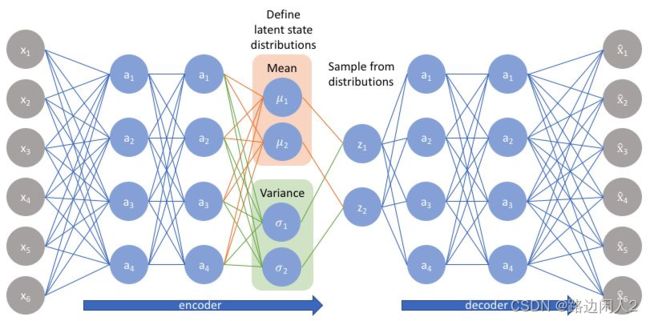
Transformer
Transformer是Google Brain提出的经典网络结构,由经典的Encoder-Decoder模型组成。在上图中,整个Encoder层由6个左边Nx部分的结构组成。整个Decoder由6个右边Nx部分的框架组成,Decoder输出的结果经过一个线性层变换后,经过softmax层计算,输出最终的预测结果。

一个神经网络运行的可视化展示
A Neural Network Playground
Google深度学习部门Google Brain的掌门人 Jeff Dean,在Google Plus上发布了Tensorflow游乐场:

界面组成:
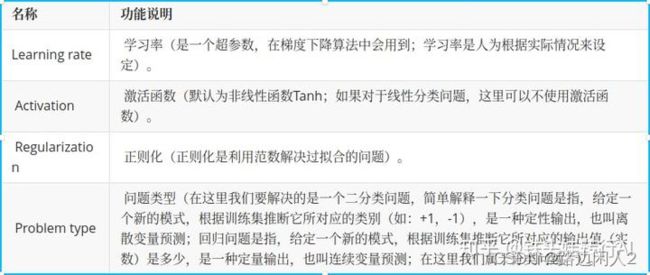
1.数据集
分为训练集和测试集。
2.特征 输入层
3.隐藏层
神经元的层数、个数都是可以定义的。神经元的连接是自动计算出来的。
4.采用的参数
学习率、激活函数、正则化函数
抽象来说,我们的机器学习classifier(分类器)其实是在试图画一条或多条线。如果我们能够100%正确地区分蓝色和橙色的点,蓝色的点会在线的一边,橙色的会在另一边。
上面这些图其实非常的直观。第一张图中,如果x1作为我们的唯一特征,我们其实就是在画一条和x1轴垂直的线。当我们改变参数时,其实就是在将这条线左右移动。其他的特征也是如此。
很容易可以看出,我们需要智能地结合这其中一种或多种的特征,才能够成功地将蓝色点和橙色点分类。这样的feature extraction,其实往往是机器学习应用中最难的部分。好在我们有神经网络,它能够帮我们完成大部分的任务。
如果我们选定x1和x2作为特征,我们神经网络的每一层的每个神经元,都会将它们进行组合,来算出结果:
而下一层神经网络的神经元,会把这一层的输出再进行组合。组合时,根据上一次预测的准确性,我们会通过back propogation给每个组合不同的weights(比重)。这里的线越粗,就表示比重越大:

神经网络最大的魔力,就在于我们根本不需要想出各种各样的特征,用来输入给机器学习的系统。我们只需要输入最基本的特征x1, x2, 只要给予足够多层的神经网络和神经元,神经网络会自己组合出最有用的特征。
我们只输入x1, x2,而选择1个6层的,每层有8个神经元的神经网络:

内容部分摘自《TensorFlow 2.0深度学习算法实战教材》