LangChain + Embedding + Chromdb,关联使用ChatGLM的本地搭建训练平台教程
一.介绍
OpenAI 在国内用户注册会遇到各种阻力,目前可行的方法是使用本地数据集的功能实现联网搜索并给出回答,提炼出TXT、WORD 文档里的内容。
现在主流的技术是基于强大的第三方开源库:LangChain 。
文档地址:️ Langchain
这个库目前非常活跃,每天都在迭代,已经有 22k 的 star,更新速度飞快。
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。他主要拥有 2 个能力:
-
可以将 LLM 模型与外部数据源进行连接
-
允许与 LLM 模型进行交互
LLM 模型:Large Language Model,大型语言模型
1.1 基础功能
LLM 调用
-
支持多种模型接口,比如 OpenAI、Hugging Face、AzureOpenAI ...
-
Fake LLM,用于测试
-
缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
-
用量记录
-
支持流模式(就是一个字一个字的返回,类似打字效果)
Prompt管理,支持各种自定义模板
拥有大量的文档加载器,比如 Email、Markdown、PDF ...
对索引的支持
-
文档分割器
-
向量化
-
对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains
-
LLMChain
-
各种工具Chain
-
LangChainHub
1.2 必知概念
相信大家看完上面的介绍多半会一脸懵逼。不要担心,上面的概念其实在刚开始学的时候不是很重要,当我们讲完后面的例子之后,在回来看上面的内容会一下明白很多。
但是,这里有几个概念是必须知道的。
1.3 Text Spltters 文本分割
顾名思义,文本分割就是用来分割文本的。为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 Langchian ,embedding 功能都是有字符限制的。
比如 我们将一份300页的 pdf 发给 LangChian,让他进行总结,这里就需要使用文本分割器去分割我们 loader 进来的 Document。
1.4 Vectorstores 向量数据库
因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
官方也提供了很多的向量数据库供我们使用。
https://python.langchain.com/en/latest/modules/indexes/vectorstores.html
1.5 Chain 链
我们可以把 Chain 理解为任务。一个 Chain 就是一个任务,当然也可以像链条一样,一个一个的执行多个链。
1.6 Embedding
用于衡量文本的相关性。这个也是 LangChain 能实现构建自己知识库的关键所在。
他相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
二.实战
通过上面的必备概念大家应该已经可以对 LangChain 有了一定的了解,但是可能还有有些懵。
视频教程:
LangChain接入本地数据实操_哔哩哔哩_bilibiliLangChain接入本地数据实操, 视频播放量 8725、弹幕量 0、点赞数 288、投硬币枚数 109、收藏人数 974、转发人数 200, 视频作者 灵镜实验室, 作者简介 连接科技与生活 | 透过热闹看门道,相关视频:LangChain: 使用AI连接数据源的时代已经到来了!,langchain-chatglm:本地私有化部署企业专有大语言模型,建立企业的私有知识库,利用LangChain和国产大模型ChatGLM-6B实现基于本地知识库的自动问答,LangChain + OpenAI 5分钟实现自然语言SQL数据挖掘,LangChain + GLM =本地知识库,Streamlit + LangChain - 10分钟创建AI Web应用,PDF聊天机器人,LangChain03-九个经典用例:聊天、数据分析、评价系统等,OpenAI + LangChain + Spark - 基于自然语言的海量企业级数据查询与分析,13分钟解读LangChain(精译中字),5分钟学会搭建本地知识库聊天机器人(基于GPT4+Llamaindex+LangChain)https://www.bilibili.com/video/BV18X4y1t79H/?spm_id_from=333.337.search-card.all.click
注意:这个视频只是快速查看本次实战搭建本地知识库实操的demo,其中有很多细节是略过的,切记不能直接效仿。
2.1 搭建本地ChatGLM
项目地址:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model
官网介绍:
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
第一步,本地安装 Python
这一步暂略,可以自行下载安装 Python 环境。
Python 下载地址:Download Python | Python.org
注意:安装 >9 以上版本,建议安装 3.93.17。
安装手册:
CentOS 7 的 Python2 升级成 Python 3.9.17_python 3.9.17 下载_查里王的博客-CSDN博客
第二步,下载项目程序包
-
下载地址见附件,直接下载下来并解压。我这里解压到 :/root/chatgpt/ChatGLM-6B-main
ChatGLM-6B-main,下载附件包如下:


第三步,下载模型包 chatglm(14GB存储空间)
下载地址:GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型
备选地址:THUDM/chatglm-6b at main
注意:海外的huggingface针对国内的IP是封锁的,无法直接下载,可以使用我存放在百度企业网盘里的源码包;
注意:百度企业网盘不让上传14GB的数据集;百度网盘单次只能上传4GB,由于个人没有开通网盘,所以只能通过公网下载;
官网介绍:
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
注意:下载后放到第二步程序包下,自行创建目录 chatglm-6b,如下:
#cd /root/.cache/huggingface/hub/models--THUDM--chatglm-6b/
yum -y install gcc-c++
pip install --upgrade pip setuptools wheel
pip install hnswlib langchain chromadb urllib3==1.26.6 sentence_transformers unstructured tiktoken gradio mdtex2html sentencepiece accelerate torch cpm_kernels protobuf transformers注意:建议更新pip的源,别用阿里云,速度奇慢无比,推荐用中科大或者豆瓣的源地址作为PIP库;
Python pip更换升级源_更新pip的源_查里王的博客-CSDN博客
第四步,运行网页版 demo
vim 修改一下web_demo.py的配置
vim /root/chatgpt/ChatGLM-6B-main
模型默认是访问huggingface的在线库,必须更改为本地的chatglb-6b的离线库的路径;
-
如果本地有GPU,可以使用 half().cuda();
-
如果本地没有GPU,就需要修改成 float();
执行如下命令,运行网页版本的 demo,如下:
cd /root/chatgpt/ChatGLM-6B-main
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。最新版 Demo 实现了打字机效果,速度体验大大提升。注意,由于国内 Gradio 的网络访问较为缓慢,启用 demo.queue().launch(share=True, inbrowser=True) 时所有网络会经过 Gradio 服务器转发,导致打字机体验大幅下降,现在默认启动方式已经改为 share=False,如有需要公网访问的需求,可以重新修改为 share=True 启动。

第五步,测试网页版程序
浏览器打开地址 并访问,输入问题,可以看到 ChatGLM 会给予回复。
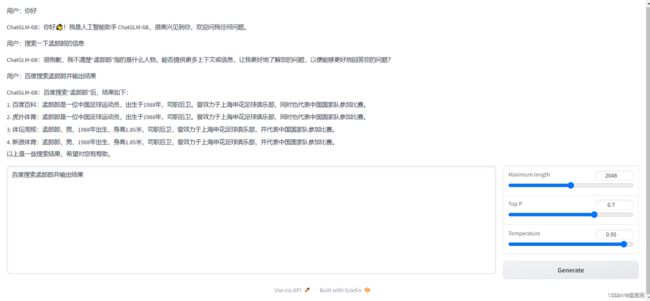
2.2 搭建本地数据切片向量化 Embeddings + ChromaDB

把Langchain和中文向量文本字符集下载到本地目录,并进行解压
unzip /root/db/LangChainTest-main.zip
unzip /text2vec-base-chinese.zip修改# vim docIndex.py的脚本
cd /root/db/LangChainTest-main
vim docIndex.py1.将model_name = 'xxxxxx'换成解压路径,例如:/root/db/text2vec-base-chinese
2.将embeddings_model_name = '/root/db/text2vec-base-chinese'
embeddings = HuggingFaceEmbeddings(model_name='/root/db/text2vec-base-chinese')也修改成解压的路径
执行 docIndex.py,将txt文本内容进行向量化入库到chromaDB中

最后,把main注释掉,取消以下的内容注释
if __name__ == "__main__":
#main()
embeddings_model_name = '/root/db/text2vec-base-chinese'
embeddings = HuggingFaceEmbeddings(model_name='/root/db/text2vec-base-chinese')
db = Chroma(persist_directory=persist_directory, embedding_function=embeddings, client_settings=CHROMA_SETTINGS)
print(db.similarity_search("产品线划分是什么样的?"))可以输出内容的即表示正确(由于客户提供的文档签署了保密协议,我这里就不贴图了)
三.LangChain 调用 ChatGLM
修改main.py中的embeddings的模型地址
vim /root/db/LangChainTest-main/main.py将model_name修改成/root/db/text2vec-base-chinese
if __name__ == '__main__':
embeddings = HuggingFaceEmbeddings(model_name='/root/db/text2vec-base-chinese')
db = Chroma(persist_directory=persist_directory, embedding_function=embeddings, client_settings=CHROMA_SETTINGS)
retriever = db.as_retriever(search_kwargs={"k": target_source_chunks})
#llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
llm = ChatGLM()
prompt_template = """基于以下已知信息,简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。
已知内容:
{context}
问题:
{question}"""
promptA = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain_type_kwargs = {"prompt": promptA}
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever, chain_type="stuff",
chain_type_kwargs=chain_type_kwargs, return_source_documents=True)
while True:
query = input("\n请输入问题: ")
if query == "exit":
break
res = qa(query)
answer, docs = res['result'], res['source_documents']
print("\n\n> 问题:")
print(query)
print("\n> 回答:")
print(answer)
for document in docs:
print("\n> " + document.metadata["source"] + ":")最后的结果,就会提示:请输入问题,表示搭建本地库成功!