口罩检测——数据准备(2)
文章目录
- 前言
- 一、数据介绍
- 二、数据标注
- 三、数据转换
- 总结
前言
上一篇文章中小编讲解了口罩检测的环境要求,在这一篇文章中我们就正式进入项目的讲解。我们从数据准备开始,数据是模型快乐的源泉,没有高质量的数据,再好的模型也白搭。
一、数据介绍
目录结构
----mask
----images
----mask_00133.jpg
----mask_00134.jpg
.
.
.
----labels
----mask_00133.txt
----mask_00134.txt
.
.
.
图片数量有2076张,人脸数据较多,口罩数据较少。图片大致如下所示:
数据来自一些公开的数据集,为了让模型训练得更好,自己也收集了一些数据,并使用labelimg对数据进行标注。
二、数据标注
激活安装过labelimg工具的虚拟环境
启动labelimg
指定要标注的图片文件夹,我们的文件夹是images。指定labels文件夹,被标注的图片生成的.txt标签文件会自动保存到labels文件夹下。
数据格式选用yolo,因为公开数据集是yolo格式,所以统一用yolo。图片中是没有戴口罩的人脸,所以数据标注为nomask。
因为图片中是戴口罩人脸,所以标注为mask。
生成的标签txt文件。除了根据图片名字生成相应的标签txt,还有一个classes.txt,可以将其移除该文件夹,注意是移除,不是删除。

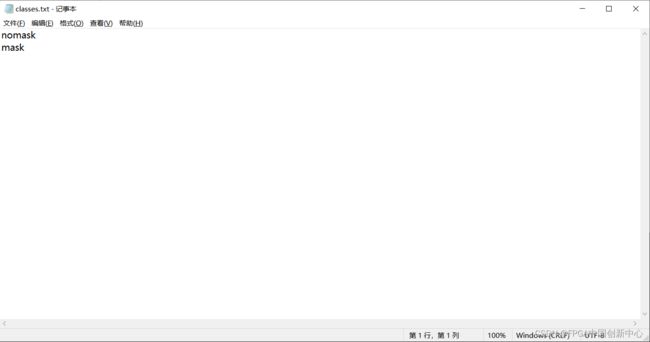
因为只有两个标签mask和nomask,所以classes.txt如下所示:
我们看看生成的标签txt文件。
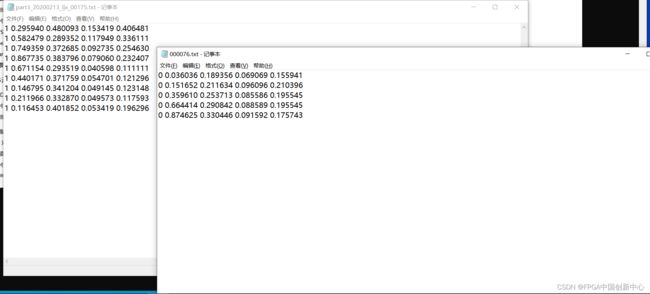
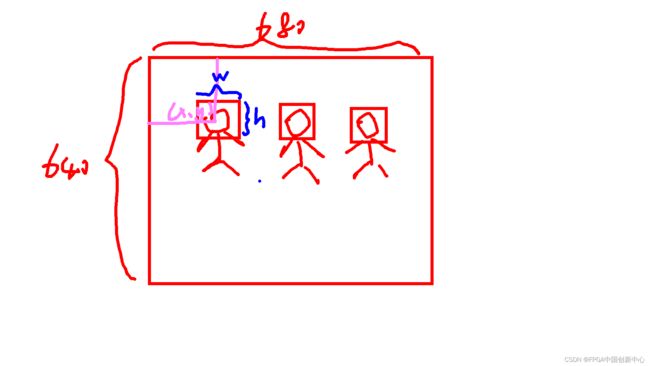
0表示nomask,1表示mask,图片中标注了多少个框,相应的生成几排数据。如下魔性图中,假如图片是680x640,0或者1后面的几个小数分别代表框的中心坐标x,y,框的宽w,框的高h。为什么是小数?是因为x/680,y/640,w/680,h/640。
三、数据转换
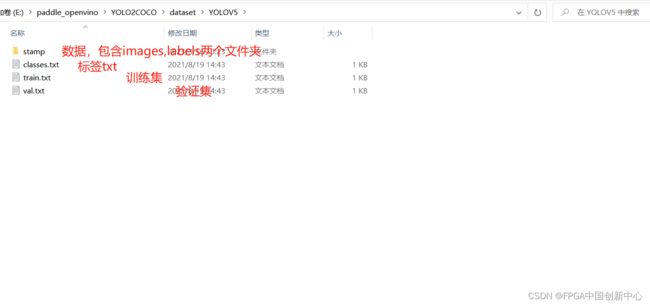
数据集拆分,严格意义上讲,应该把数据拆成训练集、测试集、验证集,我们为了方便,就只需要拆分成训练集和验证集就可以了。在YOLO2COCO\dataset文件下建立一个yolo_mask文件夹,然后将mask移动到此文件夹下。点击YOLO2COCO获取工具。

我们先看看YOLO2COCO给的模板
打开train.txt看一下内容,其实就是从dataset开始的图像的相对路径,val.txt里面的内容类似。

先把第二章数据标注中产生的classes.txt移动至yolo_mask文件夹下面,形如这样。

现在编写一个python生产我们需要的train.txt,val.txt。
import os
def train_val(labels_path, data_path, ratio=0.3):
nomask_num = 0#计数nomask的数量
mask_num = 0#计数mask的数量
image_dir = "\\".join(data_path.split("\\")[-3:]) + "\\images"#根据yolo2coco要求制定路径
txt_files = os.listdir(labels_path)
f_train = open("train.txt", "w")
f_val = open("val.txt", "w")
m = 0
n = 0
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')#打开txt文件
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
nomask_num += 1#不戴口罩加1
else:
mask_num += 1#戴口罩加1
f_txt.close()
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
n += 1
if n >= int(nomask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
m += 1
if m >= int(mask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
f_txt.close()
f_train.close()
f_val.close()
if __name__ == "__main__":
data_path = os.path.join(os.getcwd(), 'mask')#获取文件夹mask的绝对路径
labels_path = os.path.join(data_path, "labels")#获取labels文件夹的绝对路径
train_val(labels_path=labels_path, data_path=data_path, ratio=0.3)
生成的train.txt,val.txt如下,train_val_split是上述源代码文件,放置位置如下图所示,因为使用的jupyter notebook编写,所以是.ipynb,可以转成.py文件并在该文件夹下运行。

接下来可以转换数据了,clean.ipynb和train_val_split.ipynb不会影响转换过程,所以不用删除,毕竟是自己写的,删掉可惜了。在YOLO2COCO文件夹下启动cmd

根据自己的目录情况执行以下命令。
python yolov5_2_coco.py --dir_path E:\paddle_openvino\YOLO2COCO\dataset\yolo_mask

如果你看到输出成功标志,那你就可以今晚给自己奖励一个鸡腿。最后打包好数据,准备上传AI Studio把。
总结
到此,你的数据就准备好了,在下一次课程当中,我们将开启炼丹之旅——模型训练,敬请期待。