9、Haclon图像中字符识别
目录
1、分类器原理
2、分类器实现图像分割
3、OCR字符识别
4、案例:车牌识别
5、案例:汉字识别
1、分类器原理
分类器属于木事识别的范畴,是通过给定的数据,根据实现的标签结果,来寻找合适的分界线以及分解规律,同时要使得这些规律对于类似的数据能够更大程序的适用。
举例:如下图,左侧代表类型1,右边代表类型2,那么y=ax+b就是他的分界线。
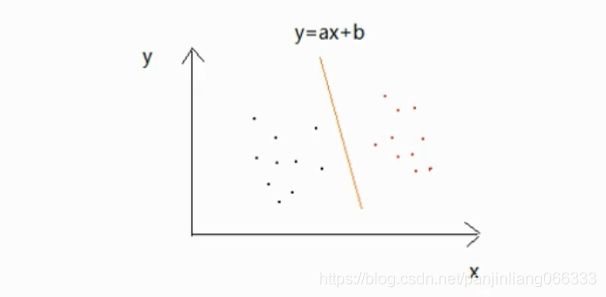
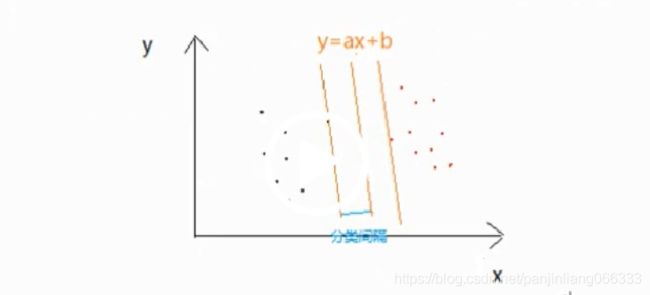
分类器的优化:分界线的位置以及分界线的形状、数据点的输入都是优化的主要方面。
(1)比如y=ax+b,其实他的位置取多个位置都能够满足要求,但是实际上,最优的只有一条。
再分了的原则中,蟾宫的一种方法就是保证类间方差最大,而类内方差最小。典型的代表就是svm分类器。svm分类器称为支撑向量机。
(2)分界线的形状:高斯混合分类器GMM,就是利用数据中出现的概率进行分类,理论上可以生成任何形状的线条。

(3)感知器mlp(类似bp神经网络)

多类型分类:
两种方法,一对多训练或者每一个都训练比较概率。

实际上,这些步骤,再halcon中指数两个算子创建分类器以及分类器训练,原理主要是用来帮助理解。
特征训练:分类器本质是对数据进行的训练,所以我们需要提取图像的特征,最简单的就是直接使用图像的所有灰度,但是这样相对耗费时间,使用的较多的是图像的灰度特征,比如平均灰度、灰度方差等等。
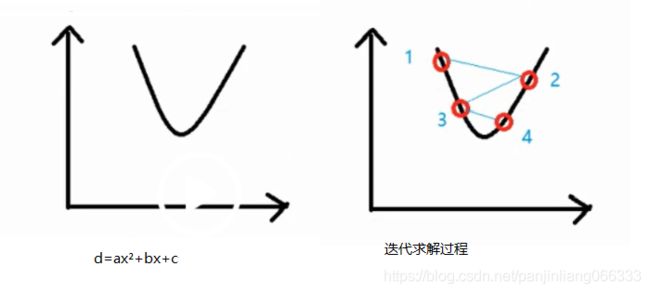
什么叫训练:其实训练就是数据迭代的过程。比如上面的分类器中,我们讲解的主要是其原理,而在实际中,既然存在一个最佳的优化结果,那么就可以根据数学理论得到优化目标函数,我们称其为损失函数,要想得到最佳的结果,那么久需要使得损失函数最小。比如说:d=ax²+bx+c是一个损失函数,如果按照我们的思维,可以直接求得最小值,但是在计算机初中,实际并不是这样,往往采用迭代的方式进行求解。
2、分类器实现图像分割
比如下面这幅图像,我们可以通过分类器实现白色、红色、黑色、和蓝色区域的一个阈值分割。首先要选定这些区域中的代表区域,然后进行训练,然后再识别。
算子说明:
create_class_svm :创建svm分类器
add_samples_image_class_svm:增加样本
train_class_svm :分类器训练
classify_image_class_svm:分类识别算子
程序讲解:
读取一副图片
dev_close_window()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
read_image (Image, '素材-牌')
创建训练区域,创建4个不同颜色的区域
*创建一个空集合
gen_empty_obj (Union_Obj)
for Index := 1 to 4 by 1
draw_region (Region, WindowHandle)
concat_obj (Union_Obj, Region, Union_Obj)
endfor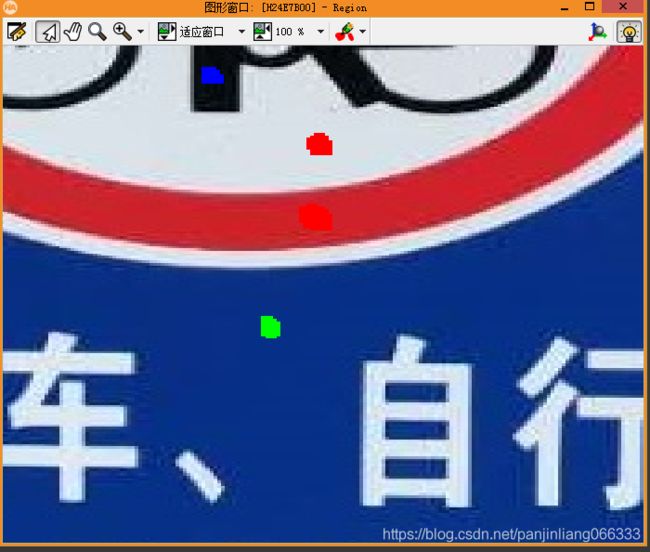
创建分类器
*创建分类器
*参数1:图像通道,彩色图3通道,黑白图1通道。
*参数2:向量积和,保持默认
*参数4:设置小一点
*参数5:分的类,和创建的训练区域数量相同。
create_class_svm (3, 'rbf', 0.02, 0.001, 4, 'one-versus-all', 'normalization', 10, SVMHandle)将样本添加到分类器中
*将样本添加到分类器中
add_samples_image_class_svm (Image, Union_Obj, SVMHandle)训练
*训练
*参数2:训练误差
train_class_svm (SVMHandle, 0.001, 'default')分类,分割
*分类
classify_image_class_svm (Image, ClassRegions, SVMHandle)
3、OCR字符识别
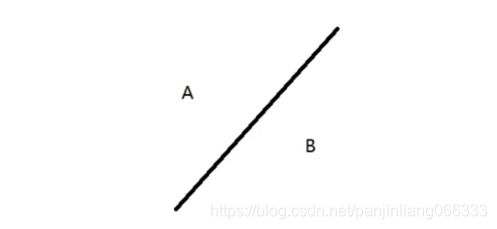
原理:其实字符识别的本质是利用分类器来实现的。比如下图,如何区别A与B呢,那么可以通过建立两者的分类器模型,然后对其进行分类。
而在halcon中其实已经训练好了一些标准的字符,我们可以直接拿过来使用。
*================字符识别过程================*
*1、字符区域的提取
*2、读取分类器训练结果(使用halcon提供的训练结果('A-Z'的字符库))
*3、字符识别
*注意:同一个字符必须是一个区域,才可以识别
程序讲解:
读取图片素材
dev_close_window()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
read_image (Image, '素材')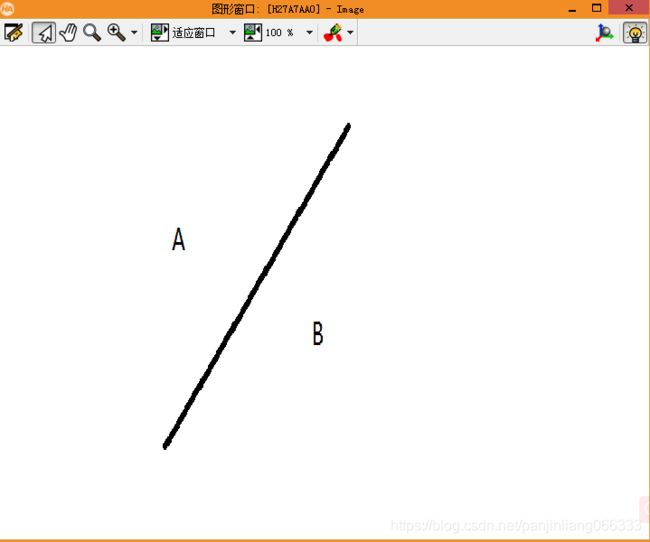
进行阈值分割
*全局阈值分割。提取黑色的部分。黑色的为0,白色的是255
threshold (Image, Region, 0, 10)
*连通域操作
connection (Region, ConnectedRegions)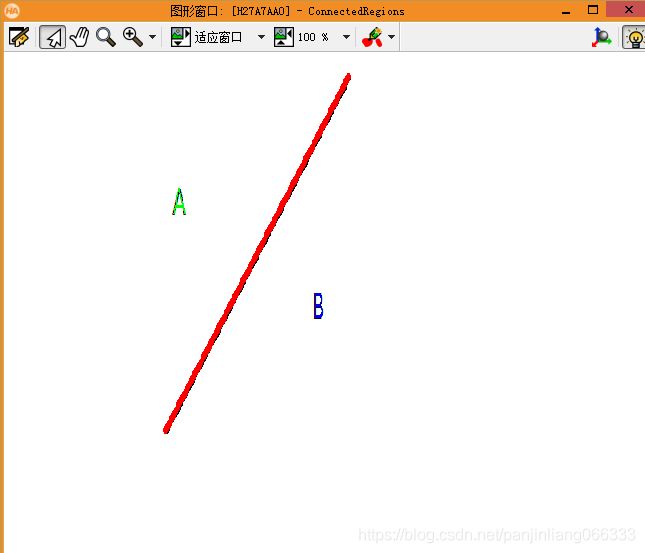
进行字符区域筛选
*区域提取。按照面积大小来提取。(工具栏特征检测,可以看每个区域面积大小)
select_shape (ConnectedRegions, SelectedRegions, 'area', 'and', 30, 200)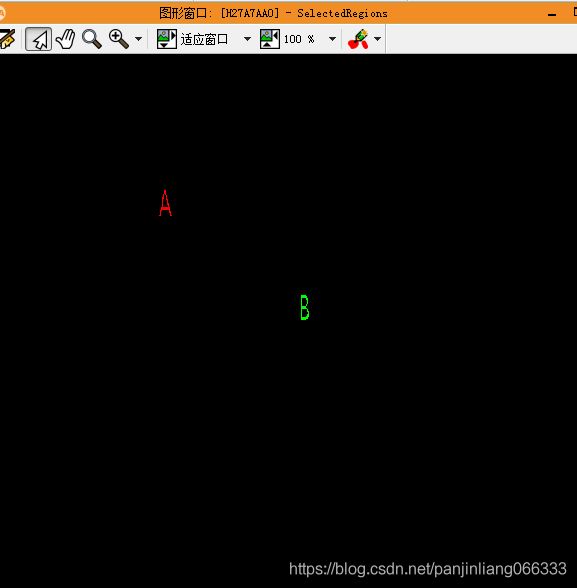
读取halcon自带的字符训练库
*读取训练结果。(读取halcon自带库)
*参数1:字符库的选择
read_ocr_class_mlp ('Industrial_A-Z+_Rej.omc', OCRHandle)字符识别并输出显示
*字符识别
do_ocr_multi_class_mlp (SelectedRegions, Image, OCRHandle, Class, Confidence)
*字符数组,保存识别到的字符
A:=Class
*在窗口上显示
disp_message (WindowHandle, A, 'window', 12, 12, 'black', 'true')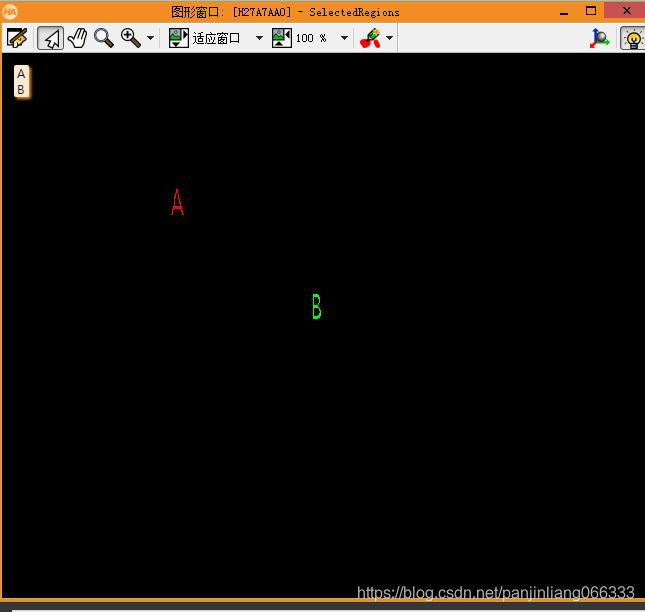
4、案例:车牌识别
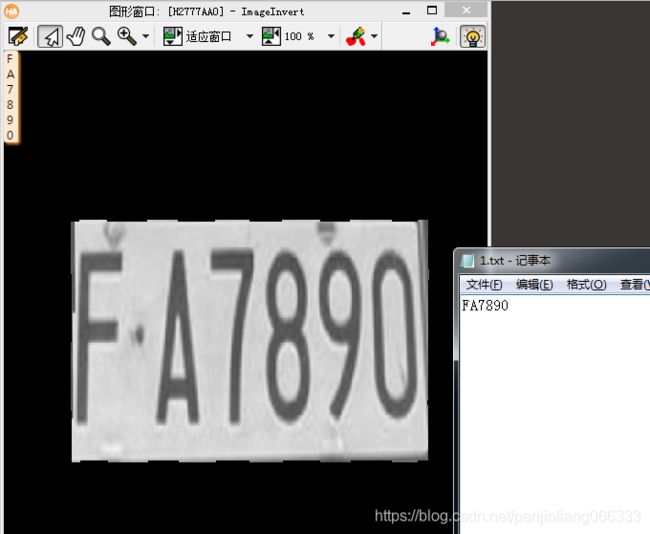
需求:识别图中车牌号码。并保存到本地txt文本文档中。

分析:利用颜色信息,提取车牌号,然后将图像旋转至水平,再去提取字符,并利用halcon中的ocr库,进行识别。(注意:把字符旋转至水平,识别率会更好。)
程序讲解:
读取图片
dev_close_window ()
dev_open_window (0, 0, 512, 512, 'black', WindowHandle)
*读取图片
read_image (Image, '素材')
将图片转成R、G、B、H、S、V等通道
*将图像转换成3通道图片
decompose3 (Image, R, G, B)
*转换成颜色通道。运行观察发现,效果在S通道效果最好
trans_from_rgb (R, G, B, H, S, V, 'hsv')
对S通道进行阈值分割
*对S通道提取-全局阈值分割
threshold (S, Region, 128, 255)
对分割出来的区域进行填充、旋转灯处理,最后在S通道图上,将该区域裁剪下来
*填充
fill_up (Region, RegionFillUp)
*最小外接矩形
smallest_rectangle2 (RegionFillUp, Row, Column, Phi, Length1, Length2)
*生成最小外接矩形2
gen_rectangle2 (Rectangle, Row, Column, Phi, Length1, Length2)
*旋转-图片旋转水平
vector_angle_to_rigid (Row, Column, Phi, Row, Column, 0, HomMat2D)
*将区域中心进行旋转
affine_trans_region (Rectangle, RegionAffineTrans, HomMat2D, 'nearest_neighbor')
*对R通道图像也进行区域中心旋转
affine_trans_image (R, ImageAffineTrans, HomMat2D, 'constant', 'false')
*对图像裁剪(粗定位)
reduce_domain (ImageAffineTrans, RegionAffineTrans, ImageReduced)
对裁剪出来的,进行区域分割
*提取白色区域
threshold (ImageReduced, Region1, 100, 255)
*连通域分割
connection (Region1, ConnectedRegions)

将字符区域筛选出来,再进行排序
*区域选择。(将字符的区域筛选出来)根据区域外接矩形1、外接矩形2进行选择
select_shape (ConnectedRegions, SelectedRegions, ['rect2_len1','rect2_len2'], 'and', [45,20], [55,30])
*判断筛选出来的字符区域是不是6个
count_obj (SelectedRegions, Number)
if(Number!=6)
stop()
endif
*对筛选出来的区域进行排序。按照列排序
sort_region (SelectedRegions, SortedRegions, 'first_point', 'true', 'column')
读取halcon提供训练好的的OCR字符库
*读取OCR
read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle)进行识别前,一定要主要图片上的字符是白底黑字
*对图像进行黑白反转
invert_image (ImageReduced, ImageInvert)
*OCR的识别。
*==>>特别注意:Halcon对字符的识别要求是白底黑子,否则不能识别。
do_ocr_multi_class_mlp (SortedRegions, ImageInvert, OCRHandle, Class, Confidence)
将识别到的字符,在窗口中显示
*在窗口(0,0)位置显示OCR识别结果Class
disp_message (WindowHandle, Class, 'window', 0, 0, 'black', 'true')
将识别的字符,保存到txt中
*将识别的车牌结果,另存在txt文本中
open_file ('1.txt', 'output', FileHandle)
fwrite_string (FileHandle, Class)
close_file (FileHandle)
工程代码下载链接:
https://download.csdn.net/download/panjinliang066333/12234724
5、案例:汉字识别
汉字识别跟字符识别原理上是一样的,区别在于汉字识别,halcon没有现存的字库,需要自己先训练汉字库。然后再进行识别。
项目要求:使用图1中的汉字训练字库,然后识别图像2中的汉字,识别结果保存到本地txt文件中。

图1

图2
程序实现讲解:
(1)、训练汉字库
读取要训练的图像
read_image (Image, '素材.png')
rgb1_to_gray (Image, Image) 
创建要训练的汉字数组
*要训练的字库
txtName:=['大','家','好','欢','迎','收','看']创建OCR字符分类器
*创建分类器
*字符大小8*10
create_ocr_class_svm (8, 10, 'constant', 'default', txtName, 'rbf', 0.02, 0.05, 'one-versus-all', 'normalization', 10, OCRHandle)
对图像进行处理,阈值分割、膨胀,再进行求交接得到分割后的每个字符区域
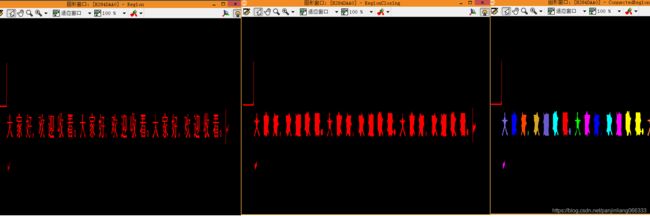
对选择出来的区域进行筛选只保留字符区域,再对字符区域进行排序
*通过外接矩形筛选,去掉干扰项,只保留字符区域
select_shape (RegionIntersection, SelectedRegions, ['rect2_len1','rect2_len2'], 'and', [6,6], [12,12])
*对筛选出来的字符进行排序
sort_region (SelectedRegions, SortedRegions, 'first_point', 'true', 'column')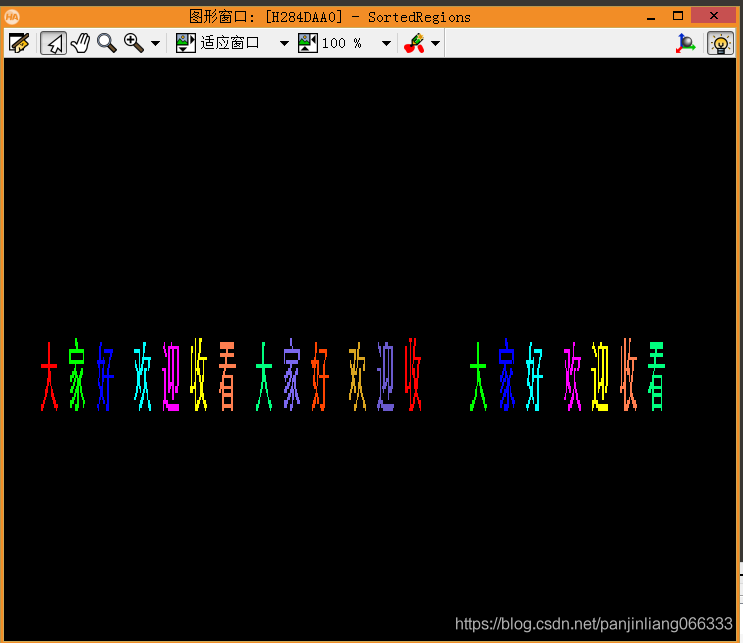
将要训练的样本保存到本地
*循环保存样本
for i := 1 to |txtName| by 1
select_obj (SortedRegions, obj, i)
*写入样本,第一次需要先创建样本,然后就可以往样本里面添加了
if(i==1)
write_ocr_trainf (obj, Image, txtName[i-1], 'train_ocr')
else
append_ocr_trainf (obj, Image, txtName[i-1], 'train_ocr')
endif
stop()
endfor![]()
对样本进行训练
*训练样本
*参数2:训练样本文件名,和前面创建的样本名一致。
*参数3:偏差,达不到的话会一致训练
trainf_ocr_class_svm (OCRHandle, 'train_ocr', 0.001, 'default')将训练的结果,汉字库,保存到本地
*保存训练结果
write_ocr_class_svm (OCRHandle, '1.osc')![]()
(2)、使用自己训练的汉字库,对图像中的汉字进行识别,并将识别的汉字保存到本地。
读取图片
read_image (Image, '素材2.png')
rgb1_to_gray (Image, Image)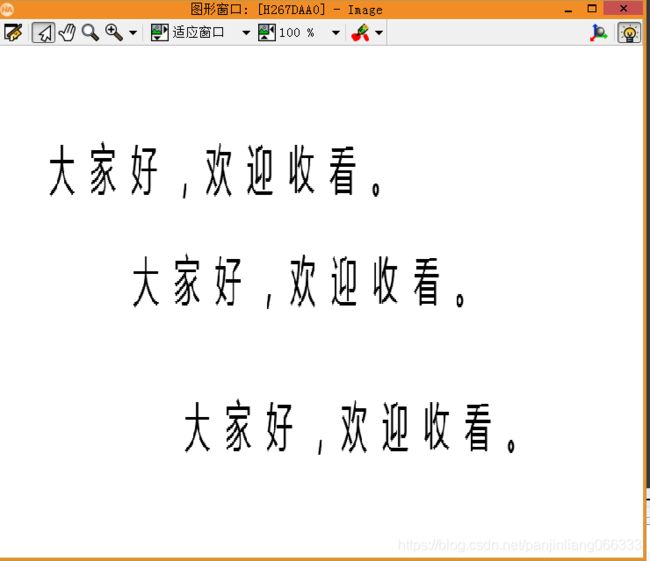
对图像处理,阈值分割、膨胀,再求交集得到分割后的区域
*阈值分割
threshold (Image, Region, 0, 200)
*进行膨胀
closing_circle (Region, RegionClosing, 2.5)
connection (RegionClosing, ConnectedRegions)
*膨胀后的和阈值分割后的区域,求交接。(提取出每个字符分割后的完整区域)
intersection (ConnectedRegions, Region, RegionIntersection)
筛选,只保留字符的区域,再进行排序
*通过外接矩形筛选,去掉干扰项,只保留字符区域
select_shape (RegionIntersection, SelectedRegions, ['rect2_len1','rect2_len2'], 'and', [12,12], [18,18])
*对筛选出来的字符进行排序
sort_region (SelectedRegions, SortedRegions, 'first_point', 'true', 'column')
*统计字符区域数量
count_obj (SortedRegions, Number)
if(Number!=21)
stop()
endif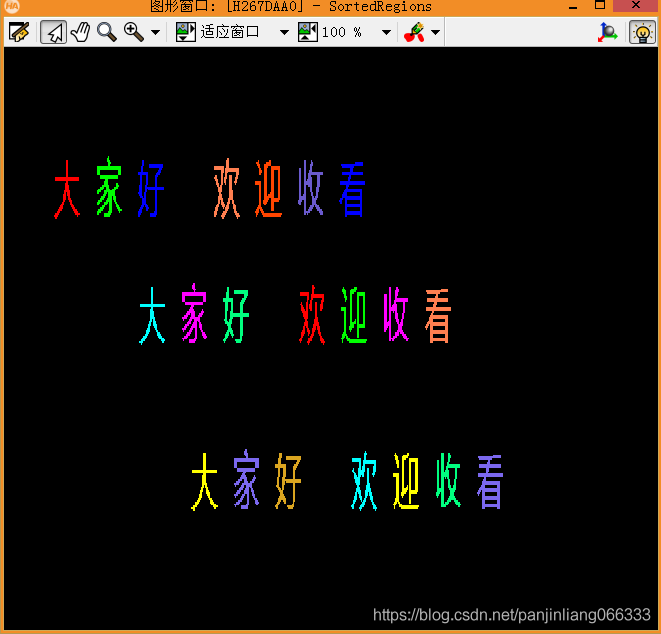
加载训练的汉字样本库
*读取自己训练的样本库
read_ocr_class_svm ('1.osc', OCRHandle)对汉字进行识别(必须白底黑子才能识别,如果是黑底白字的话,需要对图像进行取反操作,图像取反函数invert_image )
*识别
do_ocr_multi_class_svm (SortedRegions, Image, OCRHandle, Class)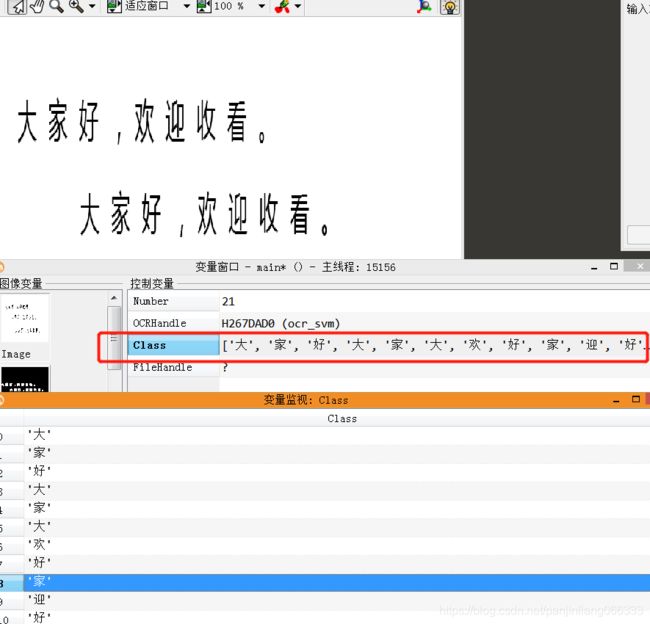
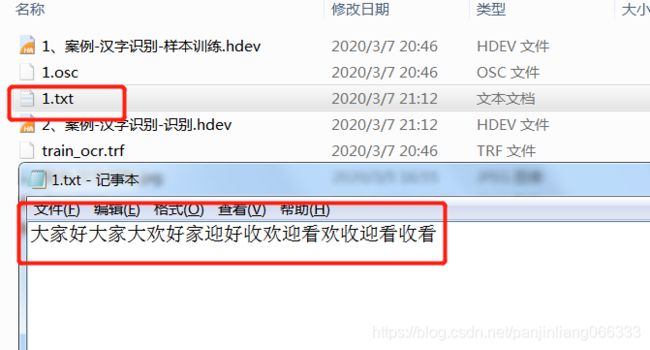
将识别的结果保存到本地txt中
*将识别的结果,写入本地txt
open_file ('1.txt', 'output', FileHandle)
fwrite_string (FileHandle, Class)
close_file (FileHandle)
工程代码下载链接:
https://download.csdn.net/download/panjinliang066333/12234731