Mysql事务机制
目录
一:定义
二:事务的特质
三:检测ACID特性
1. 准备工作.
2. 测试原子性和持久性
case1: 模拟原子性的全部失败
case2:模拟原子性的全部成功
case3:检查 持久性。
3. 测试一致性
case1: 用户1 向用户2 ,转账 1块。
case 2: 开启两个事务
四、事务隔离性的等级
a.Read Uncommitted(读取未提交内容)
编辑b.Read Committed(读取提交内容)
编辑c.Repeatable Read(可重读)
d.Serializable(可串行化)
一:定义
并未有官方的统一定义
百度百科定义为:在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
我自己的理解:事务是一个抽象的,虚拟的概念,它是一系列的数据操作动作(SQL)集合(多条)。者一系列的操作,要么全部执行成功,要么全部失败。
他的开启方式:
-- 1. begin
begin ;
XXXXX1 ;
XXXXX2 ;
XXXXX3 ;
commit ;
-- 2. start transaction
start transaction ;
XXXXX1 ;
XXXXX2 ;
XXXXX3 ;
commit ;
二:事务的特质
关系型数据的事务是为了保证数据的一致性和安全性
一致性和安全性表现在他的四个特质ACID。
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 永久性(Durability)
- 原子性(Atomicity)
事务操作是最小的单元,不可再分,要么全部执行,要么全部不执行。如果有个操作出错,则回滚事务
- 一致性(Consistency)
事务不能破坏数据的完整性和一致性,一个事务在执行之前和之后,数据库必须处于一致性状态。
例如: 转账, A转账100 给B, 那么一致性要求 A 减去100, B增加100。两个步骤缺少一个就会导致数据库的数据不是一致的。
- 隔离性(Isolation)
指的是并发的事务(多个事务同时执行),相互是隔离的,有各自完整的数据空间,事务执行的执行不会相互干扰。
a.Read Uncommitted(读取未提交内容)
所有事务都可以看到其他未提交事务的执行结果。
b.Read Committed(读取提交内容)
一个事务只能看见已经提交事务所做的改变。oracle和sql server的默认级别。
c.Repeatable Read(可重读)
mysql的默认级别。它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行
d.Serializable(可串行化)
最高的隔离级别,它会将事务排序
- 永久性(Durability)
一旦事务被提交(commit),数据库的数据就将被永久的保留下来,不管后续服务器宕机还是数据库重启都能恢复到 事务成功后的状态。
四个特质是相辅相成的,不是相互独立的。
三:检测ACID特性
1. 准备工作.
-- 1. 创建测试表
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
-- 2. 插入测试数据
insert into employee values (1,'111',1),(2,'222',2),(3,'333',3),(4,'444',4);
2. 测试原子性和持久性
测试思路: 原子性要么全部成功,要么全部失败。则用多条更改sql组成的事务测试
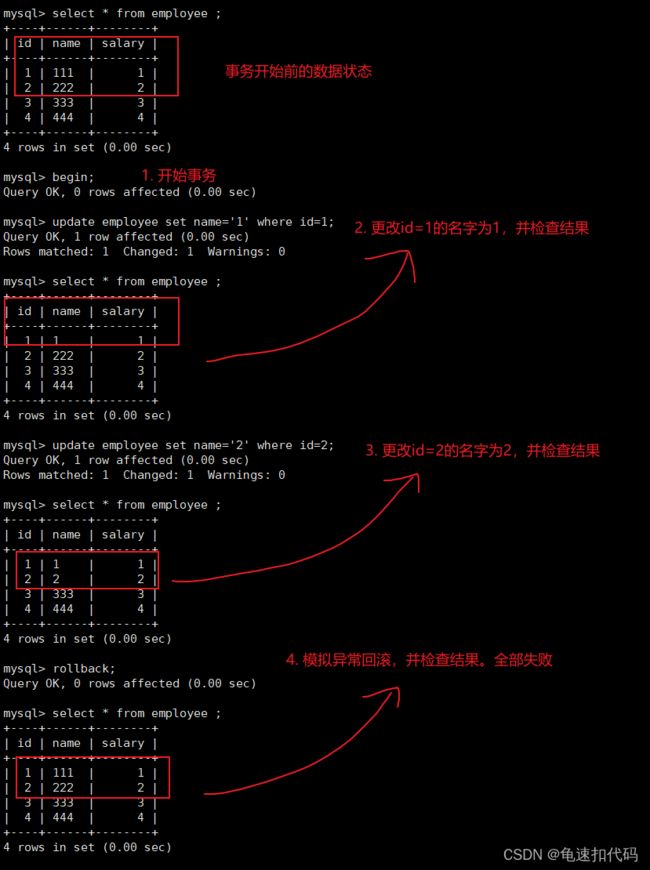
case1: 模拟原子性的全部失败
begin;
--1. 更改 id=1 的名字为1 , 并查看更改结果
update employee set name='1' where id=1;
select * from employee ;
--2. 更改 id=2 的名字为2 , 并查看更改结果
update employee set name='2' where id=2;
select * from employee ;
--3. 测试全部失败,这里直接使用rollback模拟。 结果是和事务执行前一直。 即事务的所有操作失败
-- 正式开发可能是用 try catch逻辑来实现 有异常则回滚, 无异常则提交
rollback;
select * from employee ;
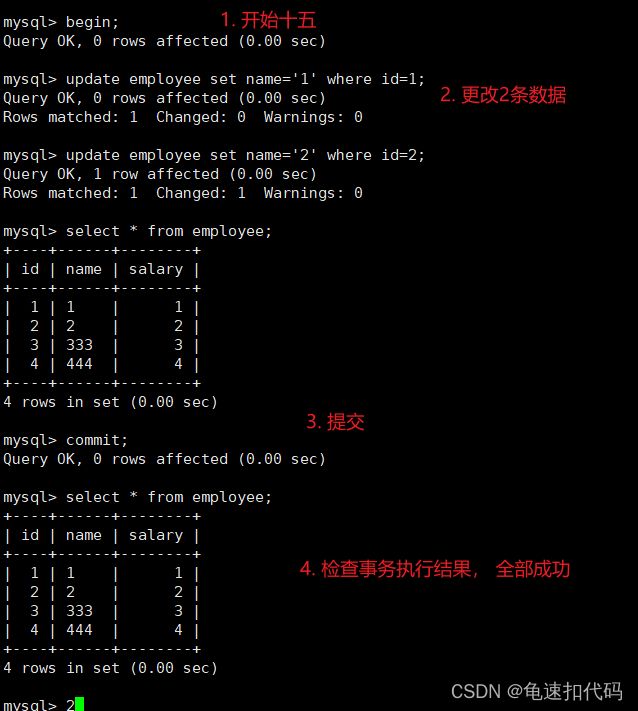
case2:模拟原子性的全部成功
begin;
--1. 更改 id=1 的名字为1 , 并查看更改结果
update employee set name='1' where id=1;
select * from employee ;
--2. 更改 id=2 的名字为2 , 并查看更改结果
update employee set name='2' where id=2;
select * from employee ;
--3. 测试全部成功,commit。
-- 正式开发可能是用 try catch逻辑来实现 有异常则回滚, 无异常则提交
commit;
select * from employee ;
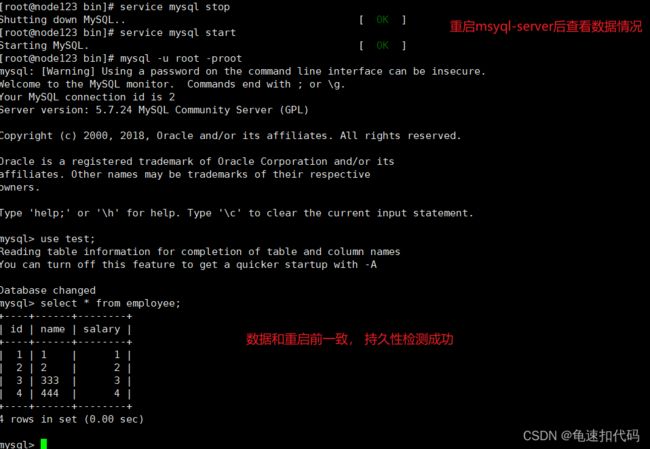
case3:检查 持久性。
重启mysql 和 服务器(虚拟机)后,数据是否恢复到 id=1 name=‘1’,id=2 name=’2‘
3. 测试一致性
case1: 用户1 向用户2 ,转账 1块。
预期结果是: 用户1 的salary 为0, 用户2 的salary为3。 (忽视字段名的含义,哈哈哈)
-- 1- 开启事务
begin ;
-- 2- 用户1 转账1 快给 用户2
-- 用户1 先扣去1块
update employee set salary=salary-1 where name='1' ;
-- 用户2 增加1块
update employee set salary=salary+1 where name='2' ;
-- 成功后提交
commit ;
-- 检查事务前后, 用户1和用户2 的总金额是 没变的。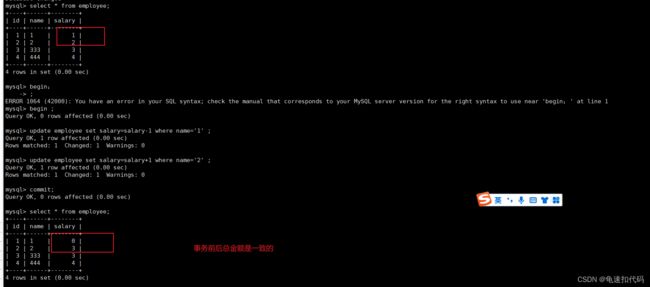
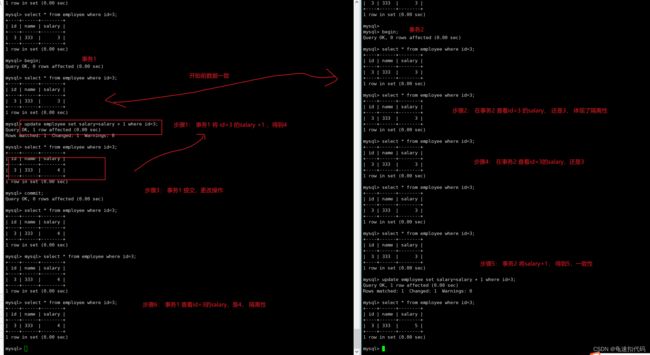
case 2: 开启两个事务
事务1 将 id=3 的salary 增加1, 并查看执行结果, 结果应该是4
事务2 查看id=3 的salary, 结果是3 。 体现了隔离性(两个事务有各自的数据空间)
事务1 将增加后的结果提交。
事务2 查看id=3 的salary, 结果还是3。 隔离性
事务2 将 id=3 的salary 增加1, 结果是 5 。 一致性,事务开始前后的数据一致。事务2更新前会再查询一次,保证数据一致。
四、事务隔离性的等级
它有四个隔离等级:
a.Read Uncommitted(读取未提交内容)
所有事务都可以看到其他未提交事务的执行结果。
这个会导致脏读
事务1读取一份数据
事务2改写这个数据
事务1再读取时是事务2更改后的
最后事务2在回滚。那么事务1读取的是事务修改未成功的数据。就是脏读
-- 将隔离等级改为 读取未提交
set session transaction isolation level READ UNCOMMITTED ;
-- 1. 事务1 修改 id=3 的salay + 1 , 并查看结果
-- 结果是 4
update employee set salary=salary+1 where id = 3;
select * from employee where id=3 ;
-- 2. 在事务2中 查看 id=3 的值
-- 结果是 4. 说明 1个事务没有提交的数据, 其他事务也能查看到
select * from employee where id=3 ;
b.Read Committed(读取提交内容)
一个事务只能看见已经提交事务所做的改变。oracle和sql server的默认级别。
事务1读取一份数据
事务2更改这份数据,并提交
事务1再次读取这份数据
这时事务1 第二次读取的数据 和 第1次读取的数据不一致,这现象好像是 不可以重复读取同一份数据一样(一个人不可能两次踏入同一条河)。 就是 不可重复读
-- 1. 事务1 修改 id=3 的salay + 1 , 并查看结果
-- 结果是 4
begin ;
update employee set salary=salary+1 where id = 3;
select * from employee where id=3 ;
-- 2. 将事务2 隔离等级改为 读取未提交
set session transaction isolation level READ COMMITTED;
-- 3. 在事务2中 查看 id=3 的值
-- 结果是 3
select * from employee where id=3 ;
-- 4. 事务1 提交操作
commit;
-- 5. 事务2 查看 id=3 的值, 结果是 4
-- 说明读取提交的隔离级别, 一个事务的操作数据,要提交后,其他事务才能查看
select * from employee where id=3 ;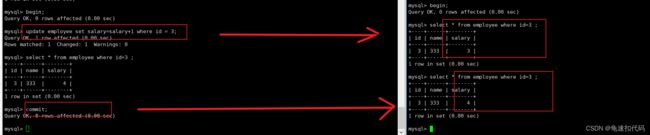
c.Repeatable Read(可重读)
mysql的默认级别。它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行

d.Serializable(可串行化)
最高的隔离级别,它会将事务排序, 串行执行事务
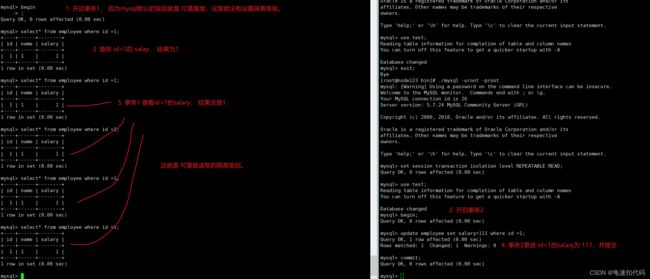
-- 1. 更改隔离等级为 串行化
-- 事务1 修改 id=3 的salay + 1 , 并查看结果
-- 结果是 3
set session transaction isolation level SERIALIZABLE;
begin ;
update employee set salary=salary+1 where id = 3;
select * from employee where id=3 ;
-- 2. 将事务2 隔离等级改为 串行化
set session transaction isolation level SERIALIZABLE;
-- 3. 在事务2中 查看 id=3 的值
-- 会发现 事务2 卡主 (即等待 事务1 执行完毕)
select * from employee where id=3 ;
-- 4. 事务1 提交操作
commit;
-- 5. 查看事务2的 窗口, 更新操作执行完毕
select * from employee where id=3 ; 事务2 在等待 事务1 借宿
事务2 等待超时

事务2 在事务1 提交后执行
