AlexNET
AlexNET
一、预备知识
1.网络可视化
pip install torchsummary
输入 :为模型、输入尺寸、批数量、设备
输出 : 模型的参数信息
from torchsummary import summary
def summary(model, input_size, batch_size=-1, device="cuda") # 函数默认是cuda,若是在cpu下就需要修改
测试:
import torch
from torchsummary import summary
from torchvision.models import vgg16 # 以 vgg16 为例
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
myNet = vgg16() # 实例化网络,可以换成自己的网络
# 将模型移动到gpu上
myNet = myNet.to(device)
summary(myNet, (3, 64, 64)) # 输出网络结构
输出:

2.数据集
百度网盘下载地址:
链接: https://pan.baidu.com/s/1Uro6RuEbRGGCQ8iXvF2SAQ 密码: hl31
ImageNet 数据集太大了1000类别,而且达到100多G的大小,因此换成Mini-ImageNet测试网络
Mini-ImageNet数据集大约3G左右,100个类别,每一个类别均有600张图片左右,共60000张图片,而且图片都是可变分辨率的(图片大小尺寸不固定)
数据集的结构:
├── mini-imagenet: 数据集根目录
├── images: 所有的图片都存在这个文件夹中
├── train.csv: 对应训练集的标签文件
├── val.csv: 对应验证集的标签文件
└── test.csv: 对应测试集的标签文件
Mini-Imagenet数据集中包含了train.csv、val.csv以及test.csv三个文件,但是提供的标签文件并不是从每个类别中进行采样的,因此无法直接用于训练分类,
train.csv 包含38400张图片,共64个类别
val.csv 包含9600张图片,共16个类别
test.csv 包含12000张图片,共20个类别
按照上述链接下载文件之后,对images进行解压,在使用panads对数据集进行分割,需要自己构建一个新的new_train.csv与new_val.csv以new_test.val,代码中imagenet_class_index.json的下载地址为:json
"""
1.将train.csv与val.csv以及test.csv 进行合并(乱序)之后再按照比例进行分割为
new_train.csv与new_val.csv以及new_test.csv
"""
import os
import json
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
"""
读取csv下的分类
"""
def read_csv_classes(csv_dir: str, csv_name: str):
# 读取mini-imagenet 下的csv文件
data = pd.read_csv(os.path.join(csv_dir, csv_name))
# 得到csv文件下的label列的元素 并对其进行去重 drop_duplicates()
label_set = set(data["label"].drop_duplicates().values)
print("{} have {} images and {} classes.".format(csv_name,
data.shape[0],
len(label_set)))
return data, label_set
"""
进行分割数据集 6:2:2
"""
def calculate_split_info(path: str, save_path:str,label_dict: dict, rate1: float = 0.2,rate2: float = 0.2):
# image_dir 为mini-imagenet 下的images路径 存放的是所有图片
image_dir = os.path.join(path, "images")
# 得到image_dir路径下以jpg为后缀的文件的列表
images_list = [i for i in os.listdir(image_dir) if i.endswith(".jpg")]
# 输出数据集中的图片数量
print("find {} images in dataset.".format(len(images_list)))
train_data, train_label = read_csv_classes(path, "train.csv")
val_data, val_label = read_csv_classes(path, "val.csv")
test_data, test_label = read_csv_classes(path, "test.csv")
# 得到 train test val 三个数据集中的标签 总共为 100类
labels = (train_label | val_label | test_label)
labels = list(labels)
labels.sort()
print("all classes: {}".format(len(labels)))
# 得到类似于 'n01532829': [0, 'house_finch'] 这样格式的字典
classes_label = dict([(label, [index, label_dict[label]]) for index, label in enumerate(labels)])
# 将得到的字典写入json文件中
json_str = json.dumps(classes_label, indent=4)
with open('./Data/classes_name.json', 'w') as json_file:
json_file.write(json_str)
# 将train.csv test.csv val.csv 三个文件的内容拼接到一起 (得到所有数据的csv文件 里面的样本数量总共为60000)
# pd.concat()函数可以沿着指定的轴将多个dataframe或者series拼接到一起
data = pd.concat([train_data, val_data, test_data], axis=0)
print("total data shape: {}".format(data.shape))
# 在每一个类别中分割数据集
num_every_classes = []
split_train_data = []
split_val_data = []
split_test_data = []
for label in labels:
# class_data 为每个类 对应的图片的图片的DataFrame
# 每个类别的图片数量为 600
class_data = data[data["label"] == label]
num_every_classes.append(class_data.shape[0])
# 乱序
# DataFrame.sample 可用来对DataFrame进行随机抽样
# frac 参数用于指定抽取的样本条数的比例(这里的代码表示全部进行抽取即乱序)
# random_state 参数 可以复现抽样结果 第二次与第一次抽取的结果一致
shuffle_data = class_data.sample(frac=1, random_state=1)
# 分割比例
num_train_sample = int(class_data.shape[0] * (1 - rate1 - rate2))
num_val_sample = int(class_data.shape[0] * rate1)
new_test_sample = int(class_data.shape[0] * rate2)
# 因为每个类别为600张 对每个类别求的分割的比例
split_train_data.append(shuffle_data[:num_train_sample])
split_val_data.append(shuffle_data[num_train_sample:(num_val_sample + num_train_sample)])
split_test_data.append(shuffle_data[(num_val_sample + num_train_sample):int(class_data.shape[0])])
# imshow
imshow_flag = False
if imshow_flag:
img_name, img_label = shuffle_data.iloc[0].values
img = Image.open(os.path.join(image_dir, img_name))
plt.imshow(img)
plt.title("class: " + classes_label[img_label][1])
plt.show()
# plot classes distribution
plot_flag = False
if plot_flag:
plt.bar(range(1, 101), num_every_classes, align='center')
plt.show()
# concatenate data 将分割的数据集 创建一个新的csv文件 并将其内容进行拼接
new_train_data = pd.concat(split_train_data, axis=0)
new_val_data = pd.concat(split_val_data, axis=0)
new_test_data = pd.concat(split_test_data, axis=0)
# save new csv data
new_train_data.to_csv(os.path.join(save_path, "new_train.csv"))
new_val_data.to_csv(os.path.join(save_path, "new_val.csv"))
new_test_data.to_csv(os.path.join(save_path, "new_test.csv"))
def main():
data_dir = "/media/zxz/新加卷/DataSET/mini-imagenet/" # 指向数据集的根目录
json_path = "./Data/imagenet_class_index.json" # 指向imagenet的索引标签文件
save_path = "./Data" # 创建的new_train.csv 与 ne_val.csv 需要保留的地址
# load imagenet labels
label_dict = json.load(open(json_path, "r"))
# 得到一个字典,其中键代表 label 而值代表label对应的事物的英语单词 如: 'n01440764': 'tench'
label_dict = dict([(v[0], v[1]) for k, v in label_dict.items()])
calculate_split_info(data_dir, save_path,label_dict)
if __name__ == '__main__':
main()
一般训练集、验证集、测试集按照6:2:2的比例进行分割,分割后得到的csv文件如下
new_train.csv 包含36000张图片,共100个类别
new_val.csv 包含12000张图片,共100个类别
new_test.csv 包含12000张图片,共100个类别
根据创建的csv文件划分为原始如下形式:
Mini-imageNet
new_train
class1_dir
class2_dir
...
new_val
class1_dir
class2_dir
...
new_test
class1_dir
class2_dir
...
代码如下:
"""
根据split_dataset1 新创建的csv文件 对原始的数据集进行分割
1.根据new_train.csv 文件中的图片 创建new_train文件夹 将图片复制到 new_train文件夹的对应的label下的文件夹下
"""
import shutil
import pandas as pd
import os
import time
def copy_to_move(base_path:str,root_path:str,csv_path:str,move_to_dir:str):
# 读取csv文件 获取所有的img文件名称
handle_csv = os.path.join(base_path, csv_path)
data = pd.read_csv(handle_csv)
# 将csv文件中的图片名字 装入列表
handle_filename = list(data["filename"].values)
handle_label = list(data["label"].values) # classes = 100
print("the train_cav data num is {} classes is {}".format(len(handle_filename), len(set(handle_label))))
dst = move_to_dir # 提前创建一个new_train or new_test or new_val 文件夹,将CSV对应的img 复制到文件夹中
for i, name in enumerate(handle_filename):
imgx = os.path.join(root_path, name)
print(f"第{i}张图片已经copy完成")
print(imgx)
shutil.copy(imgx, dst)
files = os.listdir(dst) # 上一步创建的文件夹
pre = dst
for i, img in enumerate(files):
# 1. 首先遍历每个文件,创建文件夹
# n0153282900000138.jpg
dir_name = img.split(".")[0][:9] # 这里就是为了截取label,根据img name 前9个为label
dir_path = os.path.join(pre,dir_name)
if not os.path.exists(dir_path):
os.mkdir(dir_path) # 创建该类文件夹
# 直接判断该文件,归类
img_path = os.path.join(pre,img)
if not os.path.isdir(img_path):
if img[:9] == dir_name: # 由于每个类包含很多img文件,判断该文件是否属于该类
shutil.move(img_path, dir_path) # true的话,移动到该类目录
if __name__ == '__main__':
# 当前程序文件所在的目录
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
# mini-imagenet数据集原始的images文件下
root_path_images = "/media/zxz/新加卷/DataSET/mini-imagenet/images"
new_train_csv_path = "./Mini-ImageNet/new_train.csv"
new_val_csv_path = "./Mini-ImageNet/new_val.csv"
new_test_csv_path = "./Mini-ImageNet/new_test.csv"
new_train_dir = "./Mini-ImageNet/new_train"
new_val_dir = "./Mini-ImageNet/new_val"
new_test_dir = "./Mini-ImageNet/new_test"
print("创建new_train文件夹.....")
copy_to_move(BASE_DIR,root_path_images,new_train_csv_path,new_train_dir)
print()
time.sleep(5)
print("创建new_val文件夹.....")
copy_to_move(BASE_DIR, root_path_images, new_val_csv_path, new_val_dir)
print()
time.sleep(5)
print("创建new_test文件夹.....")
copy_to_move(BASE_DIR, root_path_images, new_test_csv_path, new_test_dir)
print()
time.sleep(5)
划分的数据集图片:

二、论文细节
1.ReLu与Tanh收敛速度的比较
在论文的3.1节中提到ReLu相较于Tanh收敛速度更快,且ReLu无需对输入数据进行归一化防止饱和,在不对数据进行归一化的情况下,比较如下:
(1)代码
"""
代码功能:
复现论文中3.1的部分比较
对于特定的四层卷积神经网络 达到25%的训练误差 所迭代的论轮数
没有对数据进行任何的正规化
每个网络的学习速率都是独立选择的,以使训练尽可能快
"""
"""
1.导入库
"""
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
"""
2.下载数据集
len(train_data) = 50000
len(test_data) = 10000
pic shape = [2,32,32]
classes = 10
"""
train_data = torchvision.datasets.CIFAR10(root="../Cifar-10",transform=torchvision.transforms.PILToTensor(),train=True,download=True)
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=128,shuffle=True)
"""
3.搭建四层卷积网络
"""
# 搭建神经网络
class Module(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# Layer1
nn.Conv2d(3,32,5,1,2), # 32 32 32
nn.MaxPool2d(kernel_size=(2,2),stride=2) , # 32 16 16
nn.ReLU(),
# Layer2
nn.Conv2d(32,64,5,1,2), # 64 16 16
nn.MaxPool2d(kernel_size=(2,2),stride=2), # 64 8 8
nn.ReLU(),
#Layer3
nn.Conv2d(64,64,5,1,2), # 64 8 8
nn.MaxPool2d(kernel_size=(2,2),stride=2), # 64 4 4
nn.ReLU(),
# # Layer4
nn.Conv2d(64, 128, 5, 1, 2), # 128 4 4
nn.MaxPool2d(kernel_size=(2, 2), stride=2), # 128 2 2
nn.ReLU(),
# Linear Layer
nn.Flatten(),
nn.Linear(128*2*2,64),
nn.ReLU(),
nn.Linear(64,10)
)
def forward(self,input):
input = self.model(input)
return input
class Module2(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
# Layer1
nn.Conv2d(3,32,5,1,2), # 32 32 32
nn.MaxPool2d(kernel_size=(2,2),stride=2) , # 32 16 16
nn.Tanh(),
# Layer2
nn.Conv2d(32,64,5,1,2), # 64 16 16
nn.MaxPool2d(kernel_size=(2,2),stride=2), # 64 8 8
nn.Tanh(),
#Layer3
nn.Conv2d(64,64,5,1,2), # 64 8 8
nn.MaxPool2d(kernel_size=(2,2),stride=2), # 64 4 4
nn.Tanh(),
# # Layer4
nn.Conv2d(64, 128, 5, 1, 2), # 128 4 4
nn.MaxPool2d(kernel_size=(2, 2), stride=2), # 128 2 2
nn.Tanh(),
# Linear Layer
nn.Flatten(),
nn.Linear(128*2*2,64),
nn.Tanh(),
nn.Linear(64,10)
)
def forward(self,input):
input = self.model(input)
return input
# if __name__ == '__main__':
# x = torch.rand([1, 3, 32, 32])
# model = Module()
# y = model(x)
# print(y.shape)
"""
4.训练模型
"""
# 定义程序运行设备,若无法使用GPU则在CPU上进行运算
device_1 = 'cuda:0' if torch.cuda.is_available() else 'cpu'
device = torch.device(device_1)
# 创建网络模型(Relu)
model1 = Module()
model1 = model1.to(device=device)
# (Tanh)
model2 = Module2()
model2 = model2.to(device=device)
# 定义损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device=device)
# 定义优化器
learn_rate = 0.01
optimizer1 = torch.optim.SGD(model1.parameters(),lr=learn_rate,momentum=0.9,weight_decay=0.0005)
optimizer2 = torch.optim.SGD(model2.parameters(),lr=learn_rate,momentum=0.9,weight_decay=0.0005)
def train(lun,dataloader,model,loss_fn,optimizer):
# 将模型转化为训练模式
model.train()
loss,acc,step,epoch_error_rate = 0.0,0.0,0,0.0
for data in dataloader:
imgs,targets = data
imgs = imgs.float()
# imgs = torch.tensor(np.array(imgs))
# targets = torch.tensor(np.array(targets))
# 对数据进行GPU加速
imgs = imgs.to(device)
targets = targets.to(device)
# 将数据传入网路模型
output = model(imgs) # 分别得到每一张图片为那一个target的概率值
# 求解当前损失值(当前批次的损失)
cur_loss = loss_fn(output,targets)
# 求解当前训练批次的正确率
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(targets == pred) / output.shape[0]
# 求解当前训练批次的错误率
batch_error = torch.sum(targets != pred) / output.shape[0]
# 反向传播
optimizer.zero_grad() # 优化前将梯度清0
cur_loss.backward() # 反向传播,求得每一个节点的梯度
optimizer.step() # 对模型的每一个参数进行优化
# 将训练集下的每一轮的每一个批次的的错误率累加(跳出for循环最后得到这一轮的总错误率)
epoch_error_rate += batch_error.item()
# step 该训练集目前训练到多少批次
step = step +1 # 本轮样本的训练次数
# 本轮训练的每一批次的平均损失
train_error_rate = epoch_error_rate / step # 本轮训练的平均损失
print("train_error_rate: {}".format(train_error_rate))
return train_error_rate
# 定义画图函数
def matplot_loss(train_error_relu, train_error_tanh):
plt.plot(train_error_relu, label='error_relu') # 画一个折线名字named = error_relu
plt.plot(train_error_tanh, label='error_tanh') # 画一个折线名字named = error_tanh
plt.legend(loc='best') # (说明那条曲线是什么的标签)指定图例的位置。默认为loc=best 左上方
plt.ylabel('train_error_rate') # 二维图形的y轴名称
plt.xlabel('epoch') # 二维图形的X轴名称
plt.title("train_error_relu vs train_error_tanh") # 图的标题
plt.show()
# 创建列表用于存储数据画图
relu_train_error_rate = []
tanh_train_error_rate = []
# 训练轮数实现
epoch = 20
if __name__ == '__main__':
for i in range(epoch):
print("\n")
print("-------Relu 第 {} 轮训练开始------".format(i + 1))
train_error_relu = train(i + 1, train_dataloader, model1, loss_fn, optimizer1)
relu_train_error_rate.append(train_error_relu)
for i in range(epoch):
print("\n")
print("-------Tanh 第 {} 轮训练开始------".format(i + 1))
train_error_tanh = train(i + 1, train_dataloader, model2, loss_fn, optimizer2)
tanh_train_error_rate.append(train_error_tanh)
print(relu_train_error_rate)
print(tanh_train_error_rate)
matplot_loss(relu_train_error_rate,tanh_train_error_rate)
(2)结果

对上面的结果进行比较可以得到,ReLu的收敛速度在17轮之前确实是优于tanh
2.LRN
论文的3.3接提到的局部响应标准化(LRN)有助于AlexNet泛化能力的提升,受真实的神经元侧抑制启发
侧抑制 : 细胞分化变为不同时,会对周围细胞产生抑制信号,组织他们像相同的方向分化,最终表现为细胞命运的不同


- a 表示卷积层(包括卷积操作和激活操作)后的输出结果。这个输出的结果是一个四维数组 [batch,height,width,channel]。这个输出结构中的一个位置 [a,b,c,d],可以理解成在某一张特征图中的某一个通道下的某个高度和某个宽度位置的点,即第 a 张特征图的第 d 个通道下的高度为 b 宽度为 c 的点。
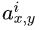 表示第 i 个通道的特征图在位置(x,y)运用激活函数 ReLU 后的输出。n 是同一位置上临近的 feature map 的数目,N 是特征图的总数。
表示第 i 个通道的特征图在位置(x,y)运用激活函数 ReLU 后的输出。n 是同一位置上临近的 feature map 的数目,N 是特征图的总数。

即公式中的分母,若此处的分母越大即表示对该处的像素值抑制程度越大。若![]() 周围的deepth_radius范围存在较大的像素值,那么对于
周围的deepth_radius范围存在较大的像素值,那么对于![]() 的输出存在较大的抑制
的输出存在较大的抑制
论文中提到使用LRN分别减少了top-1和top-5的1.4%与1.2%的错误率
(1)Pyotrch中LRN的实现
torch.nn.LocalResponseNorm(size, alpha=0.0001, beta=0.75, k=1.0)
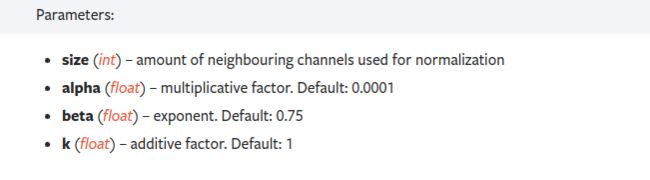
在2014年的《Very Deep Convolutional Networks for Large-Scale Image Recognition》提到LRN技术实际用处不大
3. Overall architecture

- 首先输入的是一张
224x224x3(因为是彩色`RGB三通道的图) - 第一层用的卷积核的大小是
11∗11∗3,卷积核的个数是48+48=96,从这一层开始两个GPU开始分开运行,现在定义处理上半层特征图的叫GPU_A,处理下半层特征图的叫GPU_B,每个GPU负责48个卷积核的运算,上半层GPU_A生成48张特征图,下半层GPU_B生成48张特征图。这一层卷积结束之后,还需要LRN(Local Response Normalization局部响应归一化)和Max_Pooling(最大池化) - 第二层和第一层同理,两个
GPU分别处理自己上一层传来的output(那48张特征图),卷积核的大小是5∗5∗48,然后一共有128+128=256个卷积核,所以两个GPU各自利用自己上一层的output生成128张特征图。这一层的卷积结束之后还需要LRN(Local Response Normalization局部响应归一化)和Max_Pooling(最大池化) - 第三层和前两层不同,这一层两个
GPU都要是将两个GPU的上一层的全部输出output作为输入input,所以这一层的卷积核大小是3∗3∗ (128[来自GPU_A]+128[来自GPU_B]),也就是这层的卷积核是3∗3∗256,而不是像前两层那样只是把自己上一层的输出当成输入,这层一共有192+192=384个卷积核,GPU_A负责前192个卷积核的生成的特征图,GPU_B负责后192个卷积核生成的特征图 - 第四层和第五层同第三层
- 第六层,接了一个全连接层
(FC),首先将128[来自GPU_A]和128[来自GPU_B]的一共256张特征图拉直成一个超长的向量,连接到一个大小为4096的全连接层中,其中4096个神经元的前2048个神经元由GPU_A运算,后2048个神经元由GPU_B来运算 - 第七层和第六层同理
- 第八层是再连接到一个大小为1000的全连接层中,用softmax,来算1000种分类的分布
(1)pytorch代码实现
AlexNet.py,需要注意的是,目前网络全是在一块GPU上进行加速运算的,因此与原来的架构不一样
"""
搭建AlexNet网络模型
"""
"""
1.导入库
"""
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
"""
2.搭建网络模型
# 输入为 224*224*3
"""
class AlexNet(nn.Module):
def __init__(self, num_classes: int = 100, dropout: float = 0.5) -> None:
super().__init__()
self.features = nn.Sequential(
# Layer1
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.LocalResponseNorm(size=5,alpha=10e-4,beta=0.75,k=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Layer2
nn.Conv2d(96, 256, kernel_size=5, stride=1,padding=2),
nn.LocalResponseNorm(size=5, alpha=10e-4, beta=0.75, k=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
# Layer3
nn.Conv2d(256, 384, kernel_size=3, stride=1,padding=1),
nn.ReLU(inplace=True),
# Layer4
nn.Conv2d(384, 384, kernel_size=3, stride=1,padding=1),
nn.ReLU(inplace=True),
# Layer5
nn.Conv2d(384, 256, kernel_size=3, stride=1,padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # 256*6*6
)
self.flatten = nn.Flatten()
self.classifier = nn.Sequential(
# Linear1
nn.Dropout(p=dropout),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
# Linear2
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
# Linear3
nn.Linear(4096, num_classes),
)
def forward(self,x):
x = self.features(x)
x= self.flatten(x)
x = self.classifier(x)
return x
# if __name__ == '__main__':
# x = torch.rand([1, 3, 224, 224])
# model = AlexNet()
# y = model(x)
# print(y.shape)
4. Data Augmentation(数据增强)
论文在训练阶段使用两种数据增强的方式减少数据的过拟合,都允许用很少的计算从原始图像生成转换,这样相当于将数据增加了2048倍(32x32x2)
(1)第一种
从256x256的图像中随机扣下224x224大小的图片,并进行随机的水平翻转
- (数据保证符合网络期望的输入数据)将短边减少到256,长边也保证高宽比往下降,长边多出来的以中心为界将两个边进行裁剪在第二节
2 The Dataset中提到过,ImageNet是一个可变分辨率的数据集因此,
实现代码:
import torchvision.transforms as transforms
# 标准化所求的数据集的均值与方差
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别 按照长宽比进行缩放
transforms.CenterCrop(256), # 将长边多余的地方进行裁剪
transforms.RandomCrop(224), # 随机裁剪224*224
transforms.RandomHorizontalFlip(p=0.5), # 以50%的概率进行水平翻转
transforms.ToTensor(), # 转变为tensor()数据
transforms.Normalize(norm_mean, norm_std), # 标准化
])
(2)第二种
第二种方法改变训练图像中RGB通道的强度,对整个ImageNet训练集的RGB像素值集执行PCA主成分分析,然后对主成分上的数进行微小的扰动,以此图像色彩就会发生微小的变化,增加图像的丰富性多样性
暂时不清楚如何对其进行操作…,在AlexNet实现时候效果有限
同时在测试阶段也有对数据进行的操作:
(3)测试阶段数据处理
在测试时,网络通过提取5个224 × 224的patch(四个角斑和中心斑)及其水平反射(共10个patch)进行预测,并将网络的softmax层对这10个patch的预测取平均
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False),
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
5. Dropout
在网络架构的前两个全链接层后添加Dropout,防止了过拟合(论文作者最开始的理解是Dropout是做模型融合,实际上是在正则化,之后本文作者写了一篇JMLR文章说明Dropout实际等价一个L2的正则,使用Dopout
可以提高模型的泛化性
6. Details of learning
在论文中使用SGD随机梯度下降法作为优化函数进行权重参数优化,其中dataloader中的batch_size = 128,momentum = 0.9 ,weight decay = 0.0005
训练细节:
- 权重参数初始化,标准差=0.01 均值=0 的高斯正太分布
- 有关学习率的调整,所有层的学习率相同,但是在验证的正确率随着当前学习率停止提高时,将学习率除以10继续训练;学习率
learn_rate = 0.01初始值 - 训练拟合时,第一层卷积的可视化,也需要进行演示
三、实现
1.模型训练
模型使用Mini-ImageNet数据集对网络模型进行训练拟合
"""
对网络模型进行训练拟合,并且保存模型最好的验证正确率的参数权重
训练数据集 使用MINI-ImageNet
"""
"""
1.导入库
"""
import os
import numpy as np
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import torch.optim as optim
from matplotlib import pyplot as plt
from torchvision.datasets import ImageFolder
from AlexNet import AlexNet
from torch.optim import lr_scheduler
import logging
import colorlog
"""
2.定义相关全局变量
"""
# 当前Train.py文件所在的目录位置
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 得到数据集所在文件目录
data_dir = os.path.join(BASE_DIR,"../Mini-ImageNet/")
train_data_dir = os.path.join(data_dir,"./new_train")
test_data_dir = os.path.join(data_dir,"./new_test")
num_classes = 100
MAX_EPOCH = 1 # 最大训练epoch
BATCH_SIZE = 128
LR = 0.01
classes = 100
start_epoch = -1
log_interval = 1
val_interval = 1
# 设置log输出--控制台输出并保存到文件中
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
handler = logging.FileHandler("../Log/log.txt",mode='w+')
handler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)
log_colors_config = {
'INFO': 'white',
}
console_formatter = colorlog.ColoredFormatter(log_colors=log_colors_config)
console = logging.StreamHandler()
console.setFormatter(console_formatter)
console.setLevel(logging.INFO)
# 重复日志问题:
# 1、防止多次addHandler;
# 2、loggername 保证每次添加的时候不一样;
# 3、显示完log之后调用removeHandler
if not logger.handlers:
logger.addHandler(handler)
logger.addHandler(console)
handler.close()
console.close()
"""
3.加载训练以及验证数据集
"""
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
train_transform = transforms.Compose([
transforms.Resize((256)), # (256, 256) 区别
transforms.CenterCrop(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
normalizes = transforms.Normalize(norm_mean, norm_std)
valid_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.TenCrop(224, vertical_flip=False), # 一张图片会得到10张图片 10张图片会以list形式存储
# 将list中的图片依次去取出做normalizes() torch.stack就将10张图片进行拼接得到一个4D张量 [B C H W] B = 10
transforms.Lambda(lambda crops: torch.stack([normalizes(transforms.ToTensor()(crop)) for crop in crops])),
])
# 构建Dataset实例
train_dataset = ImageFolder(train_data_dir, transform=train_transform)
test_dataset = ImageFolder(test_data_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=test_dataset, batch_size=4,shuffle=True)
"""
4.导入网络模型
配置损失函数
配置优化器
"""
# 模型
alexnet_model = AlexNet(num_classes=100,dropout=0.5)
alexnet_model.to(device)
# 损失函数
criterion = nn.CrossEntropyLoss()
criterion = criterion.to(device)
# 优化器 (对最后一层使用了softmax)--- 卷积层的学习率可以小一些 在线性层学习率可以大一些 --- trick
flag = 0
# flag = 1
if flag:
# map() 会根据提供的函数对指定序列(可以迭代对象)做映射
# id() 函数返回指定对象的唯一 id id 是对象的内存地址
# 该模型有三个线性层 每个线性层对应 一个输入参数与权重的乘法 以及一个加法(偏置)对应六个id
fc_params_id = list(map(id, alexnet_model.classifier.parameters())) # 返回的是parameters的 内存地址
# 如 lambda x: x ** 2, [1, 2, 3, 4, 5] x**2 是函数表达式 x 参数 取值范围是 [1, 2, 3, 4, 5]
# lambda p: id(p) not in fc_params_id, alexnet_model.parameters()
# 得到的id是模型参数中 不属于 fc_params_id(线性层)列表中的id
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表 filter(function, iterable)
base_params = filter(lambda p: id(p) not in fc_params_id, alexnet_model.parameters())
optimizer = optim.SGD([
{'params': base_params, 'lr': LR * 0.1}, # 0
{'params': alexnet_model.classifier.parameters(), 'lr': LR}], momentum=0.9)
else:
optimizer = optim.SGD(alexnet_model.parameters(), lr=LR, momentum=0.9) # 选择优化器
# 学习率每隔10轮变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
if __name__ == '__main__':
train_curve = list()
train_ACC_curve = list()
valid_curve = list()
valid_ACC_curve = list()
min_acc = 0
for epoch in range(start_epoch + 1, MAX_EPOCH):
"""
5.训练网络
"""
loss_mean = 0.
correct = 0.
total = 0.
train_ACC = 0.
logger.info("----------------Train: Epoch {}----------------------".format(epoch+1))
alexnet_model.train()
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = alexnet_model(inputs)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
# 统计分类情况
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0) # 累加这一轮 每一批次的样本数量 = 这一轮的总样本数量
correct += (predicted == labels).squeeze().cpu().sum().numpy() # 将该轮中每一个批次预测正确的样本数量进行累加
# 打印训练信息
loss_mean += loss.item() # 将该轮中每一批次的损失进行累积 得到本轮的总损失
train_curve.append(loss.item())
train_ACC = correct / total
train_ACC_curve.append(train_ACC)
if (i + 1) % log_interval == 0: # 在本轮训练中 当训练了log_interval的批次时名就打印一次训练信息
loss_mean = loss_mean / log_interval
logger.info(
"Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Train_Loss: {:.4f} Train_Acc:{:.2%}".format(
epoch + 1, MAX_EPOCH, i + 1, len(train_loader), loss_mean, train_ACC)
)
loss_mean = 0.
lr_scheduler.step() # 更新学习率
"""
6.验证网络
"""
if (epoch + 1) % val_interval == 0:
correct_val = 0.
total_val = 0.
loss_val = 0.
Valid_Acc = 0.
logger.info("----------------Valid: Epoch {}----------------------".format(epoch + 1))
alexnet_model.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
bs, ncrops, c, h, w = inputs.size() # [4, 10, 3, 224, 224]
outputs = alexnet_model(inputs.view(-1, c, h, w)) # [40,3,224,224]
# 论文中对于验证的相关操作 --- 对于网络的softmax层输出的10个patch 预测取平均
# outputs.view(bs, ncrops, -1) [4,10,100]
# torch.mean(x,dim) dim表示对于输入x的那一个维度求平均 [bs,ncrops,100].mean(1) 对dim=1求平均
outputs_avg = outputs.view(bs, ncrops, -1).mean(1) # outputs_avg.shape = [4,100]
loss = criterion(outputs_avg, labels)
_, predicted = torch.max(outputs_avg.data, 1) # 该批次验证预测的结果
total_val += labels.size(0) # 本轮累积批次验证的样本总数
correct_val += (predicted == labels).squeeze().cpu().sum().numpy() # 本轮累积批次验证正确的样本数
loss_val += loss.item()
loss_val_mean = loss_val / len(valid_loader) # 本轮验证 每一个批次的平均损失
valid_curve.append(loss_val_mean)
Valid_Acc = correct_val/total_val # 本轮的平均正确率
valid_ACC_curve.append(Valid_Acc)
logger.info(
"Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Valid_Loss: {:.4f} Valid_Acc:{:.2%}".format(
epoch+1, MAX_EPOCH, j + 1, len(valid_loader), loss_val_mean, Valid_Acc)
)
"""
7.保存网络模型
"""
if Valid_Acc > min_acc:
folder = '../Models'
if not os.path.exists(folder): # 当前目录不存在则进行创建
os.mkdir(folder)
min_acc = Valid_Acc
logger.info("save best model Epoch : {}".format(epoch + 1))
# 保存权重文件
torch.save(alexnet_model.state_dict(), '../Models/best_model_AlexNet.pth')
# 保存最后一轮的权重文件
if epoch+1 == MAX_EPOCH:
torch.save(alexnet_model.state_dict(), '../Models/last_model_AlexNet.pth')
alexnet_model.train()
logger.info("\n")
"""
7.结果可视化
"""
train_x = range(len(train_curve))
train_y = train_curve
train_acc_x = range(len(train_ACC_curve))
train_acc_y = train_ACC_curve
train_iters = len(train_loader)
# 由于valid中记录的是epoch_loss,需要对记录点进行转换到iterations
valid_x = np.arange(1, len(valid_curve) + 1) * train_iters * val_interval
valid_y = valid_curve
valid_acc_x = np.arange(1, len(valid_ACC_curve) + 1) * train_iters * val_interval
valid_acc_y = valid_ACC_curve
plt.subplot(1, 2, 1)
plt.plot(train_x, train_y, label='Train_loss')
plt.plot(valid_x, valid_y, label='Valid_loss')
plt.ylabel('loss value')
plt.xlabel('Iteration')
plt.title('Training and Validation Loss')
plt.legend(loc='upper right')
plt.subplot(1, 2, 2)
plt.plot(train_acc_x, train_acc_y, label='Train_acc')
plt.plot(valid_acc_x, valid_acc_y, label='Valid_acc')
plt.ylabel('acc value')
plt.xlabel('Iteration')
plt.title('Training and Validation acc')
plt.legend(loc='upper right')
plt.show()
logger.info('End....')
训练结束之后,会将最优以及最后训练的模型进行保存,此外还会将训练的日志在控制台输出以及存储至log.txt文件中
最后会得到训练损失vs验证损失 以及 训练正确率vs验证正确率的可视化曲线
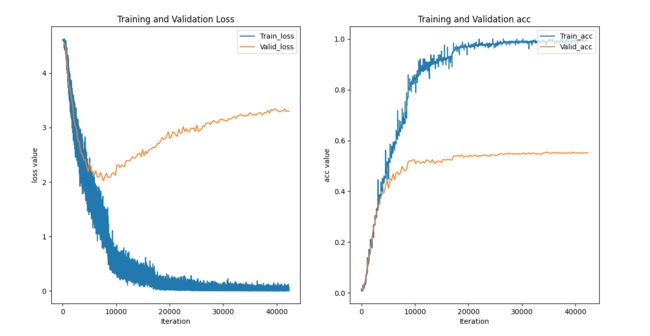
训练得到的结果出现过拟合的现象,大概在迭代的10000次(10000/282=35)轮左右出现过拟合…
训练损失在降低,但是验证损失在增加,而且此时的测试正确率不再有变化…
(1)过拟合解决方法
过拟合出现的主要原因是因为:数据太少+模型太复杂
- 增加数据量
- 多收集数据集,扩大数据集的量
- 数据增强(通过图片的旋转、平移、亮度、切割),增加数据的多样性
- 正则化方法
L1正则、L2正则(使得某些权重w不会过大)- Dropout
- 多模型组合
- 贝叶斯方法
(2)Pytorch实现正则化
在pytorch中进行L2正则化,最直接的方式可以直接用优化器自带的weight_decay选项指定权值衰减率,相当于L2正则化中的λ
optimizer = optim.SGD(alexnet_model.parameters(), lr=LR, momentum=0.9,weight_decay=1e-5)
对上述模型加入L2的正则,并加载之前过拟合的训练的权重参数,发现其训练正确率在下降…
2.模型测试
测试集数据与验证集数据的数量是一致的均为12000张
"""
用于测试模型的正确率
"""
"""
1.导入库
"""
import os
import numpy as np
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
from AlexNet import AlexNet
import json
"""
2.得到有关100分类标签的列表(按照正确的顺序)
参数 class_name.json的路径
"""
def get_classes_name(json_path):
classes_name_list = list()
with open(json_path, "r") as f:
class_names_dict = json.load(f)
for k,v in class_names_dict.items():
classes_name_list.append(v[1])
return classes_name_list
"""
3.定义相关全局变量
"""
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data_dir = os.path.join(BASE_DIR,"../Mini-ImageNet/")
test_data_dir = os.path.join(data_dir,"./new_test")
path_state_dict = os.path.join(BASE_DIR, "../Models/best_model_AlexNet.pth")
num_classes=100
classes_name = list() # 用于存储 Mini-ImageNet 100分类名字的列表
classes_name_json_path = os.path.join(BASE_DIR, "../Mini-ImageNet/classes_name.json") # 模型参数路径
classes_name = get_classes_name(classes_name_json_path)
"""
4.测试数据集
"""
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
test_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.CenterCrop(224), # 一张图片会得到10张图片 10张图片会以list形式存储
transforms.ToTensor(),
transforms.Normalize(norm_mean,norm_std),
])
test_dataset = ImageFolder(test_data_dir, transform=test_transform)
test_loader = DataLoader(dataset=test_dataset, batch_size=1,shuffle=True) # batch_size = 1
"""
5.导入网络模型
加载模型参数
"""
alexnet_model = AlexNet(num_classes=100,dropout=0.5)
pretrained_state_dict = torch.load(path_state_dict)
alexnet_model.load_state_dict(pretrained_state_dict)
alexnet_model.to(device)
"""
6.验证
"""
alexnet_model.eval()
with torch.no_grad():
sum = len(test_dataset)
right = 0
for data in test_loader:
imgs, targets = data
imgs,targets = imgs.to(device),targets.to(device)
output = alexnet_model(imgs)
_, pred = torch.max(output, axis=1)
predicted_point = pred[0].item()
if predicted_point == int(targets.item()):
right += 1
predicted = classes_name[predicted_point]
actual = classes_name[int(targets.item())]
print(f'the predicted_point is "{predicted_point} "predicted:"{predicted}", Actual:"{actual}"')
print(f"the Number of samples is {sum}")
print(f"the Accuracy is {float(right/sum)*100} %")
测试结果与训练输出的曲线结果类似,测试正确率与验证正确率都是在 50% 左右(这是用过拟合的模型进行测试的)---- 第一次过拟合的模型放在My_Proj/Models/model_overfitting目录下

3.卷积核的可视化
在论文第五节中提到,将第一层的卷积核提取出来可以看到第一层96个卷积核(GPU0 GPU1)分别48个卷积核
"""
训练拟合后对第一层的卷积核进行可视化
Web端 可视化的结果存储在 Visualization_Log目录下
"""
"""
1.导入库
"""
import os
import torch
import torch.nn as nn
from PIL import Image
import torchvision.transforms as transforms
from torch.utils.tensorboard import SummaryWriter
import torchvision.models as models
import torchvision.utils as vutils
from AlexNet import AlexNet
"""
2.定义相关全局变量
"""
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if __name__ == "__main__":
log_dir = os.path.join(BASE_DIR, "../Visualization_Log") # 用于存储 web 可视化结果的目录
writer = SummaryWriter(log_dir=log_dir, filename_suffix="_kernel") # 创建对象 filename_suffix文件名后缀
"""
3.导入模型以及预训练参数
"""
path_state_dict = os.path.join(BASE_DIR, "../Models/best_model_AlexNet.pth" )
# alexnet = models.alexnet()
alexnet = AlexNet()
pretrained_state_dict = torch.load(path_state_dict)
alexnet.load_state_dict(pretrained_state_dict)
"""
4.卷积核可视化
"""
kernel_num = -1
vis_max = 1
for sub_module in alexnet.modules(): # model.modules()迭代遍历模型的所有子层
if not isinstance(sub_module, nn.Conv2d): # 判断当前迭代的层是否是卷积层
continue
kernel_num += 1 # 当前迭代的子层是卷积层
if kernel_num > vis_max: # 大于需要可视化最大层数量时 break
break
kernels = sub_module.weight
c_out, c_int, k_h, k_w = tuple(kernels.shape) # c_out与下一层的特征映射图数量一致(卷积核的数量) c_int卷积核的通道数
# 拆分channel---将单个卷积核心的每一个通道的图像可视化
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :] # 获得(C, h, w)
# make_grid需要 BCHW,这里拓展C维度变为(C,1, h, w) unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
# 这样一个卷积核的 多个通道就被拆开了
kernel_idx = kernel_idx.unsqueeze(1)
kernel_grid = vutils.make_grid(kernel_idx,normalize=True, scale_each=True, nrow=8) # normalize=True 将值缩放值 [0-1] 之间
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
# 将单个卷积核 进行可视化 第一层卷积核 有64个
kernel_all = kernels.view(-1, 3, k_h, k_w)
kernel_grid = vutils.make_grid(kernel_all, normalize=False, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=620)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
"""
5.可视化第一层卷积后的特征映射图
"""
writer = SummaryWriter(log_dir=log_dir, filename_suffix="_feature map")
# 输入数据
path_img = os.path.join(BASE_DIR, "../../deep_eyes/A_alexnet/data/tiger cat.jpg")
normMean = [0.49139968, 0.48215827, 0.44653124]
normStd = [0.24703233, 0.24348505, 0.26158768]
norm_transform = transforms.Normalize(normMean, normStd)
img_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
norm_transform
])
img_pil = Image.open(path_img).convert('RGB')
img_tensor = img_transforms(img_pil)
img_tensor.unsqueeze_(0) # chw --> bchw
# 前向传播
convlayer1 = alexnet.features[0] # 拿到模型的第一层卷积
fmap_1 = convlayer1(img_tensor) # 得到特征映射图 shape = [1,64,55,55]
# 预处理 transpose方法的作用是交换矩阵的两个维度
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=False, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=620)
writer.close()
在pycharm控制台的终端,进入存放web可视化文件的目录下My_Proj/Visualization_Log目录下
终端输入:
tensorboard --logdir=./
终端输出一个主机host
![]()
点击,会在web端的0_all出现可视化的第一层卷积核:

可以发现第一层卷积核,学习了图像数据的
后面几层卷积核,特征相对高级,很抽象。而且卷积核尺寸小,看不懂卷积学习的内容是什么
第一层卷积最为低级,而且卷积核尺寸为11x11,可以看到第一层卷积学习了图片数据的颜色、纹理、边缘这些较为低级的特征。
神经网络对数据的特征进行提取符合由低级至高级特征提取的过程
四、结论
1.重点
AlexNet本质是一个更大更深的LeNet,主要改进有,Dropout丢弃法、ReLu激活函数、maxpooling重叠池化;ReLu与sigmoid相比梯度更大,且ReLu在零点处一阶导更好(减缓梯度消失),maxpooling取最大池化,取最大值,输出梯度更大- 局部响应标准化(
LRN)有助于AlexNet泛化能力的提升,受真实的神经元侧抑制启发;但是在论文VGG说该方法作用不大,而且有更好的Batch Normalization PCA对数据集图片的颜色进行扰动,对于模型的性能提升并不大,而且实现相对复杂,目前就不实现了…
2.启发性
- 初始的
224x224x3的图片经过五层卷积之后,最后会被展平成一个256x6x6的向量进入线性层,直到最后一个分类层(输出层)之前,向量长度为4096,则一张图片会表示为4096的维度,这个长度为4096的向量非常好的抓住了输入图片的语义信息。若两个图片最后的4096的向量的距离(欧几里德距离非常相近的话,那么这两张图片很有可能是同一个物体的图片)-------------深度学习设计的网络可以通过中间的各种隐含层的操作将一张图片最后压缩为一个特征向量(知识的压缩),而这个向量可以很好的将中间的语义信息表示出来(变成了一个机器可以理解的东西) (论文的6.1 Qualitative Evaluations 中提及) - 将神经网络在倒数第二层的输出拿出来,得到一个长向量。然后将每个图片均拿出来,然后给定一张图片看一下和我这个向量最近的图片是谁(欧几里德距离),如果两幅图像产生的特征激活向量具有小的欧几里德距离,我们可以说神经网络认为它们是相似的(注意原始的图像之间的距离是不相近的,但是通过神经网络提取得到的高级特征向量之后,欧几里德距离是相近的)—深度神经网络的图片训练出来的最后那个向量,在语义空间的表示特别好(非常好的特征),相似的图片会将其放在一起
6.1 Qualitative Evaluations最后提出可以使用AlexNet做图像检索、图像聚类、图像编码,利用两个4096维实值向量之间的欧氏距离来计算相似度是低效的,但通过训练自动编码器将这些向量压缩成简短的二进制码可以提高效率。这将产生一种比对原始像素应用自动编码器好得多的图像检索方法,后者不使用图像标签,因此倾向于检索具有相似边缘模式的图像,无论它们在语义上是否相似。