Hive分区
目录
一、理论基础
1、Hive分区背景
2、Hive分区实质
3、Hive分区的意义
4、常见的分区技术
二、分区操作
(一)、静态分区
1、单分区
2、多分区
(二)、动态分区
1、启用hive动态分区
2、创建表
三、实战练习
1、需求描述
2、先设置动态分区
3、错误sql
4、正确sql
一、理论基础
1、Hive分区背景
在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、Hive分区实质
因为Hive实际是存储在HDFS上的抽象,Hive的一个分区名对应hdfs的一个目录名,并不是一个实际字段。
3、Hive分区的意义
辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
4、常见的分区技术
hive表中的数据一般按照时间、地域、类别等维度进行分区。
二、分区操作
(一)、静态分区
1、单分区
(1)创建表
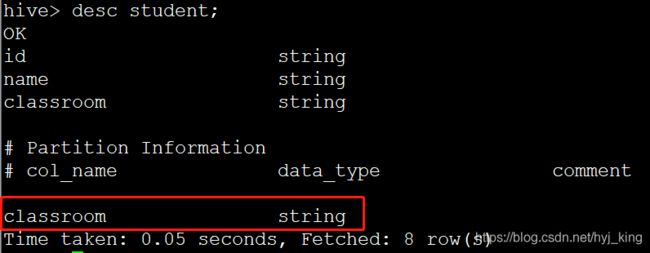
hive> create table student(id string,name string) partitioned by(classRoom string) row format delimited fields terminated by ',';
OK
Time taken: 0.259 seconds注意:partitioned by()要放在row format...的前面;partitioned by()里面的分区字段不能和表中的字段重复,否则报错;
(2)加载数据
hive> load data local inpath '/home/test/stu.txt' into table student partition(classroom='002');
Loading data to table default.student partition (classroom=002)
OK
Time taken: 1.102 seconds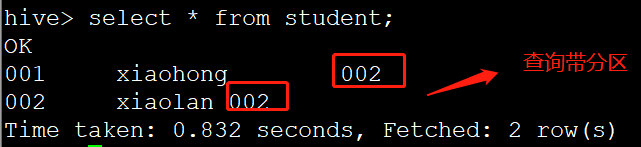
(3)查看分区
hive> show partitions student;
OK
classroom=002
Time taken: 0.071 seconds, Fetched: 1 row(s)(4)hdfs中分区展示


(5)再加载一组数据到新的分区
hive> load data local inpath '/home/test/stu.txt' into table student partition(classroom='003');
Loading data to table default.student partition (classroom=003)
OK
Time taken: 0.722 seconds
hive> select * from student;
OK
001 xiaohong 002
002 xiaolan 002
001 xiaohong 003
002 xiaolan 003
Time taken: 0.097 seconds, Fetched: 4 row(s)
hive> show partitions student;
OK
classroom=002
classroom=003
Time taken: 0.071 seconds, Fetched: 2 row(s)

2、多分区
(1)创建表
hive> create table stu(id string,name string) partitioned by(school string,classRoom string) row format delimited fields terminated by ',';
OK
Time taken: 0.074 secondshive> desc stu;
OK
id string
name string
school string
classroom string
# Partition Information
# col_name data_type comment
school string
classroom string
Time taken: 0.03 seconds, Fetched: 10 row(s)(2)加载数据
hive> load data local inpath '/home/test/stu.txt' into table stu partition(school='AA',classroom='005');
Loading data to table default.stu partition (school=AA, classroom=005)
OK
Time taken: 0.779 secondshive> select * from stu;
OK
001 xiaohong AA 005
002 xiaolan AA 005
Time taken: 0.087 seconds, Fetched: 2 row(s)(3)查看分区
hive> show partitions stu;
OK
school=AA/classroom=005
Time taken: 0.048 seconds, Fetched: 1 row(s)注意:这是个嵌套目录;
(4)hdfs中分区展示



(5)增加数据效果
hive> load data local inpath '/home/test/stu.txt' into table stu partition(school='BB',classroom='001');
Loading data to table default.stu partition (school=BB, classroom=001)
OK
Time taken: 0.272 seconds
hive> load data local inpath '/home/test/stu.txt' into table stu partition(school='AA',classroom='001');
Loading data to table default.stu partition (school=AA, classroom=001)
OK
Time taken: 0.268 seconds


(二)、动态分区
静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进行判断。详细来说,静态分区的列实在编译时期,通过用户传递来决定的;动态分区只有在SQL执行时才能决定。
1、启用hive动态分区
在hive会话中设置两个参数:
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;2、创建表
(1)首先准备一个带有静态分区的表
hive> select * from stu;
OK
001 xiaohong AA 001
002 xiaolan AA 001
001 xiaohong AA 005
002 xiaolan AA 005
001 xiaohong BB 001
002 xiaolan BB 001
Time taken: 0.105 seconds, Fetched: 6 row(s)(2)copy一张表结构相同的表
hive> create table stu01 like stu;
OK
Time taken: 0.068 seconds
hive> desc stu;
OK
id string
name string
school string
classroom string
# Partition Information
# col_name data_type comment
school string
classroom string
Time taken: 0.022 seconds, Fetched: 10 row(s)(3)加载数据,分区成功
不指定具体的学校和班级,让系统自动分配;
hive> insert overwrite table stu01 partition(school,classroom)
> select * from stu;
hive> select * from stu;
OK
001 xiaohong AA 001
002 xiaolan AA 001
001 xiaohong AA 005
002 xiaolan AA 005
001 xiaohong BB 001
002 xiaolan BB 001
Time taken: 0.091 seconds, Fetched: 6 row(s)
hive> select * from stu01;
OK
001 xiaohong AA 001
002 xiaolan AA 001
001 xiaohong AA 005
002 xiaolan AA 005
001 xiaohong BB 001
002 xiaolan BB 001
Time taken: 0.081 seconds, Fetched: 6 row(s)
三、实战练习
1、需求描述
将旧表stu(字段为name,age 分区为school)数据迁移到新表student(字段为name,age 分区为school、address)。地址都统一为shanghai;
2、先设置动态分区
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
3、错误sql
insert into student partition(address,school) select name,age,school,'shanghai' as address from stu;
这样容易将分区对应错误,因为partition括号中address在前school在后,后面select字段address却在school后面。所以会把address的数据插入school中,把school的数据插入address中。故分区插入顺序前后要保持一致。
4、正确sql
insert into student partition(address,school) select name,age,'shanghai' as address,school from stu;