G市疫情地图分布
G市疫情地图分布(上)–爬虫取数篇
【!!写在最前:本篇仅为个人学习记录, 源数据关键信息已脱敏, 若有雷同, 纯属巧合】
【!!代码为学习自用, 注释较多】
整体思路
爬虫取数, pandas清洗建库, tableau输出结果
数据源
取自G市_本地宝数据, 更新最新数据的网址是静态的, 使用windows 定时任务每天跑一边程序, 配合tableau实时数据, 即可自动更新输出图表
代码实现
1. 必要工具
import requests
from bs4 import BeautifulSoup
import re
import pandas as pd
2. 设定爬虫部分
部分操作和输出结果, 以图片形式记录(已脱敏)
2.1 heads 和解析器的设置
url = '静态网址' #网址不变,每日更新最新的前一天的数据
headers ={"User-Agent": "Mozilla...537.36"}
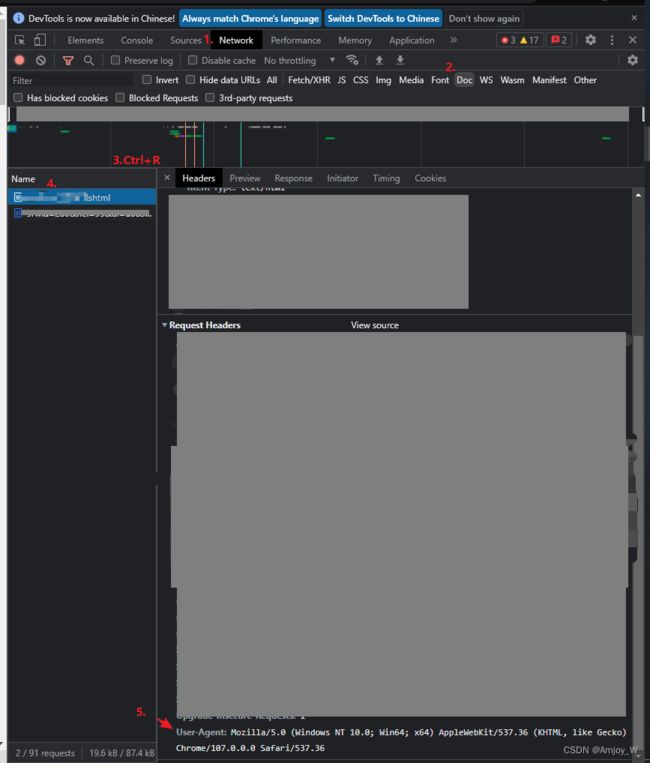
#设定chrome>F12>Network>Doc>最底下,具体操作Ctrl+F:'注释1'
#headers 是作为字典传入的,注意key和value要加引号
#爬取整个网页
resource= requests.get(url,headers = headers)
#更改编码格式
resource.encoding='utf-8'
#读取通报内容
#保留一份数据源,便于后期测试
result = resource
#设定解析器
soup =BeautifulSoup(result.text,'lxml')
soup = soup.find_all(class_='article-content') #如何找到这个标签,F12>Elements>找到然后逐个试标签,选中标签网页会有对应,找到目标即可,具体操作Ctrl+F:'注释2'
soup = soup[0].find_all('p')
2.2 万能的正则表达式获取通报内容
#设定装数据的几个容器
qz_begin=[] #装爬取的确诊
wzz_begin=[] #装爬取的无症状感染
re_time=[] #装通告发布时间
#分别录入本土确诊和无症状感染记录
#读取本土确诊病例
regex_str = "本土确诊病例[0-9-]*:[\u4e00-\u9fa5]" #表示'本土确诊病例'+若干个0-9 和 '-'符号+冒号+中文字符
#这个也可以 regex_str="本土确诊病例[0-9-]*:"
for x in range(len(soup)):
result = soup[x]
if (re.search(regex_str,result.text)):
qz_begin.append(result.text)
#读取无症状感染
regex_str = "本土无症状感染者[0-9-]*:[\u4e00-\u9fa5]" #命名错了,但也能用
for x in range(len(soup)):
result = soup[x]
if (re.search(regex_str,result.text)):
wzz_begin.append(result.text)
#读取更新时间
regex_str_time ="更新时间:"
for x in range(len(soup)):
result = soup[x]
if (re.search(regex_str_time,result.text)):
re_time.append(result.text)
3. 清洗爬取结果
3.1 发布的通告, 确诊/无症状感染的格式是这样的,
清洗的思路是, 先用strip()去掉首尾的字符, 标点等, 然后再用dataframe里的split()按","逗号分列

#清洗确诊
#先把"。"号后面的去掉,再把两端去掉不需要的字符 ,无症状和时间的清洗都是同理
qz_finl=[]
for x in qz_begin:
qz_finl.append(x.strip("。").strip())
#清洗无症状感染
wzz_finl=[]
for x in wzz_begin:
wzz_finl.append(x.strip("。").strip())
3.2 获取到的时间格式是这样的

#清洗发布时间
re_time_finl=[]
for x in re_time: #这里正常只有一个元素
re_time_finl.append(x.strip().lstrip('更新时间:')) #保留时间即可
初步清洗过后的结果如下, 因为strip()只能清洗首尾, 所以形如这种的, 没有处理掉
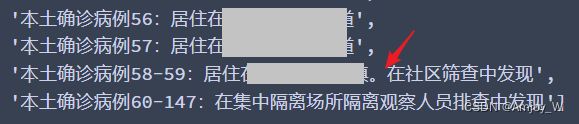
放在下一步split成多列, 然后只取前两列即可
4. 导入DataFrame里, 还是清洗
#列变表
qz_finl=pd.DataFrame(qz_finl,columns=['信息'])
wzz_finl=pd.DataFrame(wzz_finl,columns=['信息'])
#把病例 和 地址 分开
qz_finl=qz_finl['信息'].str.split(pat=':|。',expand=True)
wzz_finl=wzz_finl['信息'].str.split(pat=':|。',expand=True)
#清洗出行政区 街道
qz_finl[1]=qz_finl[1].str.replace('居住在','')
wzz_finl[1]=wzz_finl[1].str.replace('居住在','')
清洗结果如下, 取前两列即可
qz_finl=qz_finl[[0,1]]
wzz_finl=wzz_finl[[0,1]]

4.2 清洗出行政区
方便分组分析, 以及清洗出具体地址, 方便导入api批量查询经纬
#取出行政区
qz_finl['区']=qz_finl[1].str[0:3]
wzz_finl['区'] =wzz_finl[1].str[0:3]
#规整一下列名
qz_finl.columns=['病例','地址','行政区']
wzz_finl.columns=['病例','地址','行政区']
#增加一列'状态'
qz_finl['状态']='确诊'
wzz_finl['状态'] ='无症状感染'
4.3 清洗序号
通报里有很多这种类似’1-8’ 的略写, 我的思路是把这种序列变运算。如果只是单独1例, 结果为正;如果是那种序列, 则为负, 取值的时候取正+1, 则为病例数
def p1_cnt(x):
#把本土确证病例,'病例'里的人数取出来
x=x.lstrip('本土确诊病例') #剔除文字
x=eval(x) #字符串转运算符
if (x) < 0: #人数的逻辑判断,负值则取正+1,正值则取1
return(-(x)+1)
else:
return(1)
def p2_cnt(x):
#把本土无症状感染者病例,'病例'里的人数取出来
x=x.lstrip('本土无症状感染者') #剔除文字
x=eval(x) #字符串转运算符
if (x) < 0: #人数的逻辑判断,负值则取正+1,正值则取1
return(-(x)+1)
else:
return(1)
qz_finl['人数']=qz_finl['病例'].apply(lambda x:p1_cnt(x))
wzz_finl['人数']=wzz_finl['病例'].apply(lambda x:p2_cnt(x))
#保留'病例'列作为原始数据

接下来稍微修整一下, 信息归归类, 就可以批量查经纬了
#两表并一表
finl = qz_finl.append(wzz_finl)
#增加取数时间列
finl['数据更新时间']=re_time_finl[0]
#以下为finl表的整理
#修改地址格式,方便查询gps
finl['地址2']='广东省广州市'
finl['详细地址']=finl['地址2']+finl['地址']
#清洗'集中隔离场所'
finl['行政区']=finl['行政区'].replace('在集中','集中隔离场所')
4.4 整理一下
可以得到这样的数据

5.批量查询经纬度
用的是高德地图api查询, 需要自己申请key, 详细教程, 参考如何调用高德api
5.1 定义函数
#引入地址查询函数
def gaode(addr):
#查询addr的经纬
para ={
'key':'*******************', #用自己的Key
'address':addr
}
url = 'https://restapi.amap.com/v3/geocode/geo?'
req = requests.get(url,para)
req = req.json()
if req['infocode']=='10000':
z = req['geocodes'][0]['location']
#输出成文本,再分列.
#如果输出成列表/元祖/字典,下一步取经纬会出现报错'cannot reindex on an axis with duplicate labels'
return str(z)
else:
return('查询不到')
#试用
#gaode(addr="北京市天安门广场")
5.2 调用
#finl查询经纬度
finl['经纬度']=finl['详细地址'].apply(gaode)
#拆分经纬度
finl[['经度','纬度']]=finl['经纬度'].str.split(pat=',',expand=True)
#以下对时间处理
import datetime as dt
from pandas.tseries.offsets import Day
#取统计日期,通报日期-1天,通报日期是str,转化成date后向前偏移1天
finl['日期']=finl['数据更新时间'].apply(lambda x:(dt.datetime.strptime(x,'%Y-%m-%d %H:%M').date()-Day(1)))
#加一列唯一识别,后面如果反复调试查询,方便去重
finl['唯一识别'] = finl['病例']+finl['数据更新时间']
#取需要的列
finl=finl[['病例','行政区','详细地址','状态','人数','经度','纬度','唯一识别','日期','数据更新时间']]

6.输出成可以反复迭代的文件
csv快一点,xlsx方便直接用excel编辑
6.1 第一次输出
finl.to_excel(r'D:/ggd_yb/结果表/gzcov_result.xlsx',index=False)
6.2 第2+次输出
#第2+次输出
#方法是,读取前一次的结果,把新的数加进去
#设置 输入文件
path_input ='D:/ggd_yb/结果表/'
in_filename ='gzcov_result'
filename_in = path_input + in_filename +'.xlsx'
#设置 输出文件
path_output ='D:/ggd_yb/结果表/'
out_filename = 'gzcov_result'
filename_out =path_output + out_filename +'.xlsx'
#读取旧的数
result_data =pd.read_excel(filename_in,dtype=object)
result = pd.DataFrame(result_data)
#写入新的数
#一定要改finl的日期格式,不然会输出格式会不同
finl['日期']=finl['日期'].astype(str)
result = pd.concat([result,finl])
#去重一次,防止多次取数
result.drop_duplicates(subset='唯一识别',keep='first',inplace=True)
#输出
result.to_excel(filename_out,index=False)
PS:
1.代码自用, 自定义了很多列,可自行取舍
2.下篇, 数据可视化,经纬度转地图分布相对简单,有空再更
- 注释1: 如何找到自己的headers
- 注释2 :如何找到通报内容的tag