windows下搭建hadoop 搭建本地hadoop开发环境
一、下载所需文件
1.JDK下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2.Hadoop下载地址:https://pan.baidu.com/s/1fGclfAivPWVukRPDRfMUzA
3.Windows下安装Hadoop工具下载地址:https://pan.baidu.com/s/190xbt9E9ei_H727n4cvClg 提取码:4bjk || https://pan.baidu.com/s/1eGra7gKCDbvNubO8UO5rgw 提取码 yk9u
二、jdk安装
.不会进入网址https://jingyan.baidu.com/article/6dad5075d1dc40a123e36ea3.html
三、Hadoop环境配置
1.下载Hadoop,并解压到你的本地目录,我下载的是hadoop-2.7.0版本,解压在D:\hadoop\hadoop-2.7.0。(但是下面是以我安装好的版本为例子来进行演示安装过程)

四、配置Hadoop的环境变量
1.计算机 –>属性 –>高级系统设置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME

注意:路径到bin的上级目录即可。
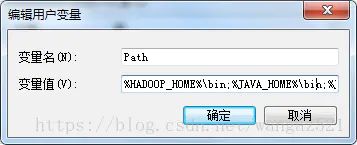
2.Path环境变量下配置【%HADOOP_HOME%\bin;】变量(可以直接在path路径下添加即可)
五、配置Hadoop文件
1.编辑“D:\hadoop\hadoop-2.5.2\etc\hadoop”下的core-site.xml文件,将下列文本粘贴进去,并保存。
2.编辑“D:\hadoop\hadoop-2.5.2\etc\hadoop”目录下的mapred-site.xml(如果不存在将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存。
3.编辑“D:\hadoop\hadoop-2.5.2\etc\hadoop”目录下的hdfs-site.xml文件,粘贴以下内容并保存。
4.编辑“D:\hadoop\hadoop-2.5.2\etc\hadoop”目录下的yarn-site.xml文件,粘贴以下内容并保存。
5.编辑“D:\hadoop\hadoop-2.5.2\etc\hadoop”目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存。
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=D:\java\jdk
六、替换文件
将1.3下载到的hadooponwindows-master.zip,解压,将全部bin目录文件替换至hadoop目录下的bin目录。
七、运行环境
1.运行cmd窗口,执行hdfs namenode -format。
2.运行cmd窗口,切换到hadoop的sbin目录,执行start-all.cmd,它将会启动以下4个进程窗口




八、上传测试
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。
1.创建输入目录
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\WINDOWS\system32>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
2.上传数据到目录
C:\WINDOWS\system32>hadoop fs -put D:\personal\debug.log hdfs://localhost:9000/user/wcinput
C:\WINDOWS\system32>hadoop fs -put D:\personal\waz.txt hdfs://localhost:9000/user/wcinput
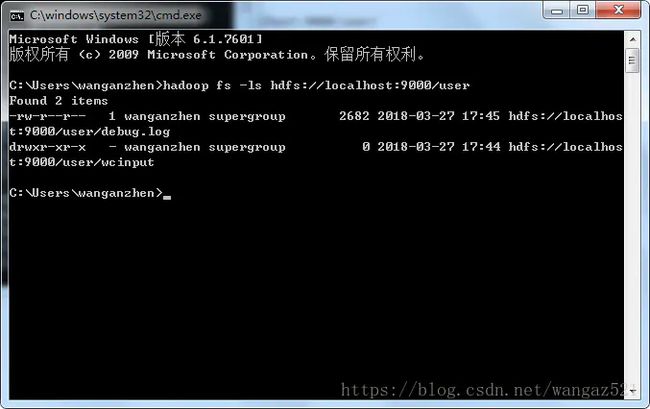
3.查看文件
常见问题:
1:启动hadoop可能提示找不到JAVA_HOME路径,是因为hadoop读取JAVA_HOME环境变量存在空格导致。
2:启动hadoop提示找不到HADOOP,是因为Hadoop环境变量没有配置好,请检查Hadoop环境变量配置
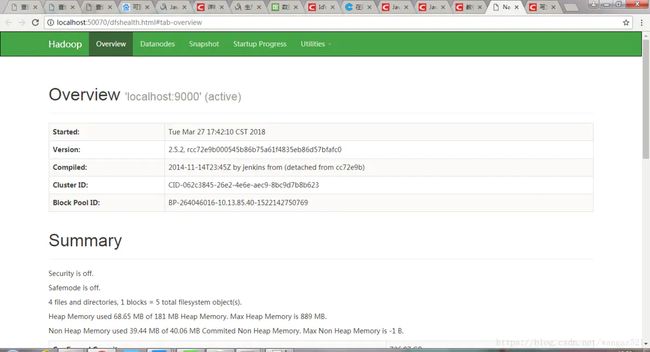
九、hadoop自带的web控制台GUI
1.资源管理GUI:http://localhost:8088/;

2.节点管理GUI:http://localhost:50070/