视觉与多模态大模型前沿进展 | 2023智源大会精彩回顾
导读
6 月 9 日下午,智源大会「视觉与多模态大模型」专题论坛如期举行。随着 stable diffusion、midjourney、SAM 等爆火应用相继问世,AIGC 和计算机视觉与大模型的结合成为了新的「风口」。本次研讨会由智源研究院访问首席科学家颜水成和马尔奖获得者曹越共同担任论坛主席,由北京交通大学教授魏云超主持。本论坛邀请了来自南洋理工大学、NVIDIA、智源研究院等国内外知名研究机构的顶尖学者共聚一堂,报告的内容涵盖生成模型、3D 视觉、通用视觉模型设计。以下是核心内容整理:
Drag Your GAN: Interactive Point-based Manipulation
on the Generative Image Manifold
潘新钢 | 南洋理工大学计算机科学与工程系助理教授
图像编辑(Image Manipulation)一直以来火热的研究方向,而且具有很广泛的应用场景。现有的图像编辑主要有以下四类:
(1)基于全监督学习的模型,如InterfaceGAN;
(2)基于语义分割图的模型,如SPADE;
(3)基于人体关键点的模型,如HumanGAN;
(4)基于文本引导的模型,如Imagic。然而现有的这些模型缺乏对空间属性编辑的灵活性,准确性,通用性。以皮影戏为例,通过控制皮影人物的关键点,可以做出各种各样的动作。
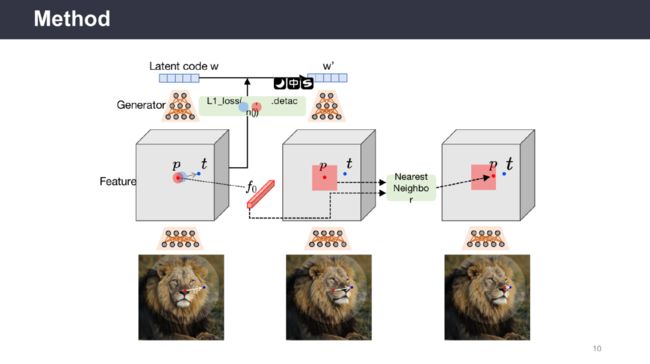
为了让模型在具有利用关键点能力的同时,并可以在编辑图像时推理出被遮挡的区域,潘新钢教授团队提出了一种基于生成对抗网络(Generative Adversarial Networks,GAN)的实时交互式图像编辑模型Drag Your GAN。用户在图像上确定抓取点(Handle Point)和目标点(Target Point),将图像与点信息一起输入到生成器中获取隐向量(Latent Code),该模型通过使用多步式迭代并在每一步迭代过程中使用动态监督损失函数,逐步优化隐向量,直至抓取点逐步移动到目标点。此外,用户可以选择修改区域,只编辑区域内的部分。通过在多个数据集上验证,展现了Drag Your GAN模型强大的图像编辑能力。

该报告介绍了通过交互式关键点拖拽的方式来编辑图像的生成式模型Drag Your GAN,改模型的核心为关键点动态监督和关键点跟踪。最后,潘新钢教授表示,通过文本引导和拖拽关键点相结合的方式将会引领图像编辑领域的未来。
将机器学习用于 3D 内容生成
高俊 | NVIDIA 研究科学家

人类生活在三维世界中,创作三维的虚拟数字世界,有助于人类更好地理解世界、解决现实生活中无法解决的问题。
生成的三维虚拟场景需要满足以下要求:
(1)物体数量足够多
(2)物体类型多样
(3)质量高,包含几何信息、纹理信息
工业界现有的依赖人工的三维世界创建方案要消耗大量人力物力,对操作者的能力要求较高,难以大规模扩展。Dreamfusion 等基于深度学习的三位视觉生成方法在几何和纹理细节生成方面仍有很大提升空间。
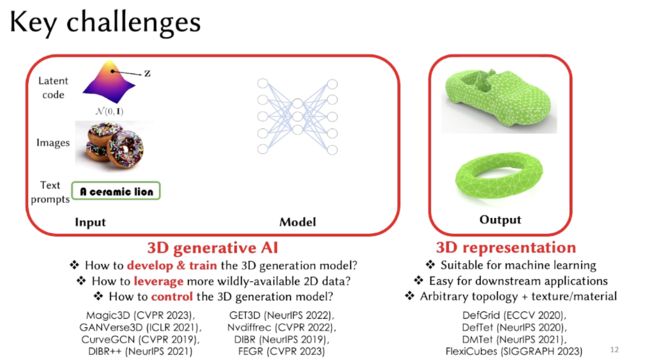
三维生成模型主要面临两点挑战:
(1)构建适用于机器学习的三维表征,易在下游任务中使用,具有灵活多样的拓扑结构、纹理、材质
(2)构建高效、高质量、可控的三维生成模型,能够广泛利用二维数据
「DMTet」提出了一种将神经场等隐函数与 mesh 网格表征相对应的方法,构建了可微的 iso surface,在利用 mesh 高精度、拓扑灵活、适合实时渲染等特性的同时,可以进行形状编辑,避免了离散化操作,利用深度学习生成方法得到了高质量 mesh 表征。
在 3D 生成模型方面,为了借鉴 2D GAN 的成功,「Get3D」实现了基于光栅化的可微渲染,构建了强大的判别器;通过 Tri-Plane 技术构建了高质量的 3D 表征;将 DMTet 与 Nvdiffrast 结合,实现了高效的训练。
「Magic3D」将文本 prompt 作为输入,构建了一个由粗到精的生成框架。粗生成阶段使用低分辨率扩散模型,通过 InstantNGP 生成初始化几何特征;精细生成阶段使用高分辨率扩散模型通过 DMTet 实现 Mesh 渲染。该模型利用预训练好的 2D 图像扩散模型的知识,将其评分函数用于引导图像生成,使用可微渲染构建了 3D 和 2D 之间的桥梁,实现了高效、高精度、局部可控的 3D 图像生成。
高俊博士指出,未来研究者们可以探究如何将单个类别的物体生成扩展到多类别、通用物体生成;从物体生成扩展到场景生成;从静态内容生成扩展到动态内容生成。
通用视觉模型初探
王鑫龙 | 智源研究院研究员
对通用视觉智能的探索可以分为两个部分:
(1)视觉表征。抽象出视觉信号,并学习通用表征。
(2)视觉通才模型。训练可以解决开放场景下各类任务(例如,分类、检测、分割)的视觉通才模型。
「EVA」 模型是目前具有 billion 级别参数的最好的预训练模型,它将 CLIP 与 MIM 方法相结合,遮盖输入图像的一部分,并重建被遮盖部分的 CLIP 特征,通过 CLIP 特征提供高级别语义,通过掩码建模提供结构空间信息。
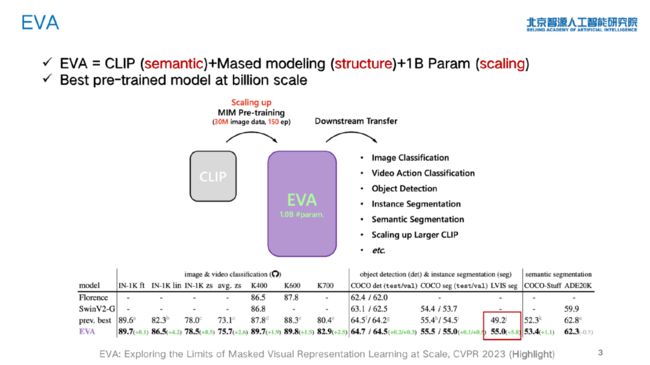
王鑫龙博士指出,扩展模型规模的目的在于使其具有以下三种能力:在经典任务(例如,ImageNet、ADE20k、COCO)上取得新的性能突破;解决以往难以解决的任务(例如,LVIS长尾识别);带来新的能力(例如,帮助 CLIP 更好地训练)。
「EVA-CLIP」使用 EVA 预训练模型初始化图像编码器,通过 LAMB 优化器使模型训练收敛更快,并通过 FLIP 提升了训练效率。EVA-CLIP 5B 在 ImageNet-1K 上取得了 82% 的零样本分类精度,是当前最强的开源CLIP模型。
「Painter」旨在将分类、检测、分割、关键点检测、底层视觉等任务统一为输入图像输出图像的任务,在无需模型微调的情况下自动完成任务,并展现出新的能力,探索了一种通用的视觉任务借口,具备上下文视觉学习能力。该模型的架构为 ViT,通过回归损失监督训练。
「SegGPT」基于 Painter 实现了「分割一切」的能力,是对通用分割模型的探索。王鑫龙博士团队将语义分割、实例分割等各种分割数据汇聚起来,统一成小样本提示的上下文视觉训练样例。
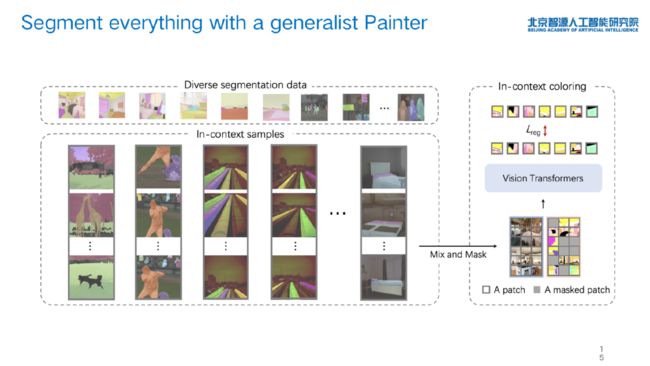
王鑫龙博士指出,上述工作背后的思想是「统一的学习方法+可扩展的数据+大模型」。其中,最困难的是构建可扩展的数据。
「Emu」是一个能接收多模态输入、产生多模态输出的大模型,进行统一的多模态上下文学习。王鑫龙博士团队将图像、文本、交错图文、交错视频文本等数据统一成相同形式,进行多模态上下文学习,完成感知、推理、生成等任务。
Image, Video, and 3D Content Creation with Diffusion Models
Karsten Kreis | NVIDIA 高级研究科学家
Huan Ling | NVIDIA 研究科学家
扩散模型是一类基于评分的生成模型,近年来取得了令人瞩目的效果。目前,已有研究人员将扩散模型用于「文-图」、「文-3D」、「文-视频」生成,「3D 形状合成」、「3D 场景生成」等任务。
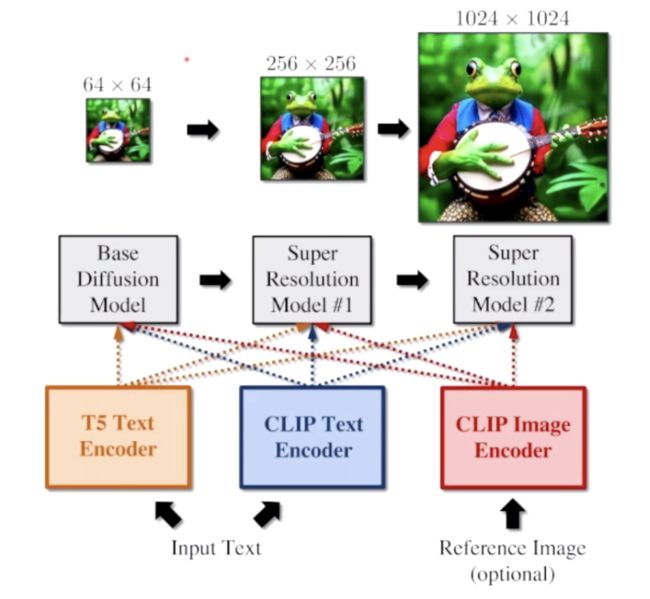
「eDiff-I」使用集成的专家去噪器实现「文-图」生成扩散模型,它利用 T5 和 CLIP 作为文本编码器、利用 CLIP 作为图像编码器,并且在基础扩散模型之上添加了 2 个超分辨率模型,包含 9.1B 的参数。该模型在不同的合成阶段使用专家去噪器。
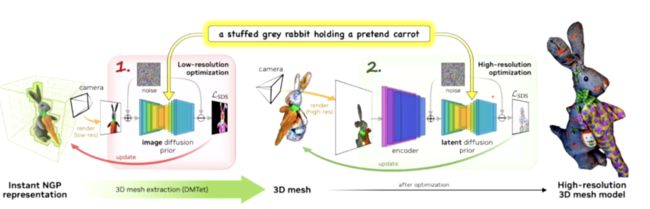
「Magic3D」实现了高分辨率的「文-3D」内容生成。该模型使用Instant NGP 根据 2D 扩散模型实现了由粗到精的 3D 形状蒸馏。在第一个阶段,模型首先低分辨率先验优化神经场表征,从而得到粗模型。在第二阶段,模型进一步可微地根据强度和颜色场提取纹理 3D mesh,使用高分辨率潜扩散模型进行微调。
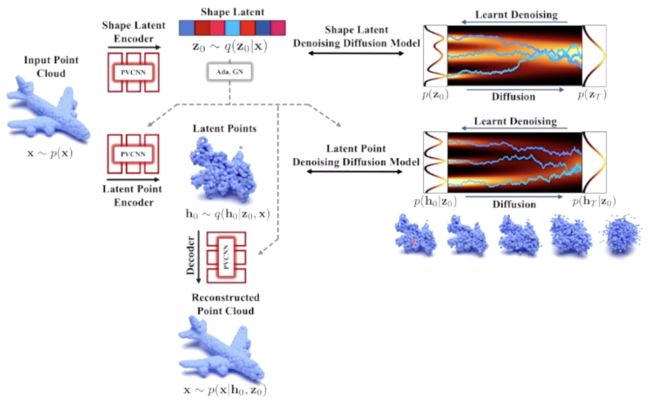
「LION」是一种层次化的基于点云的 3D 形状生成隐式点扩散模型。它首先通过扩散模型生成形状隐变量,再使用另一个以形状为条件的扩散模型生成隐式的点,进而将隐式点解码为点云,还可以通过将点构成形状重建平滑 mesh。
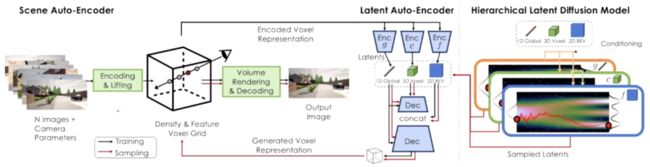
「NeuralDield-LDM」使用层次化的隐扩散模型生成场景,它训练了一个场景的自编码器,通过使用强度和特征 voxel 在神经场中考虑相机姿态、深度编码场景的 RGB 图像。该模型训练了一个层次化的隐自编器,可以将神经场的 voxel 表征压缩到更小的隐空间,在隐自编码器的隐空间中拟合了一个层次化的隐扩散模型。
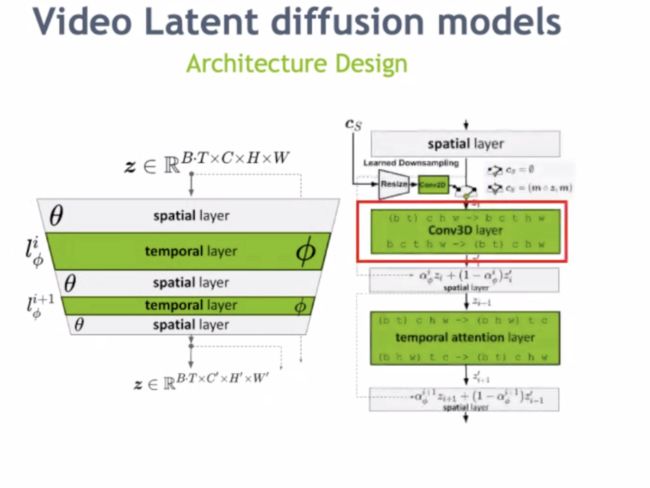
「Align Your Latents」介绍了使用隐扩散模型生成高分辨率视频。在扩散模型中,去噪是一个随机过程。该工作通过视频微调在时序上对齐了图像 LDM,并降低了计算开销。在模型方面,该工作在空间层后加入了时序层。
圆桌论坛

魏云超 | 北京交通大学教授
王鑫龙 | 智源研究院研究员
潘新钢 | 南洋理工大学计算机科学与工程系助理教授
夏威 | 摩尔线程AI副总裁
高俊 | NVIDIA 研究科学家(连线)
魏云超:针对当前的生成模型,Diffusion Model和GAN哪个模型表现更好?
潘新钢教授认为,两个模型各有优劣,但是Diffusion Model的上限更高,随着算力,硬件性能的提高,Diffusion Model的重要性会越来越大。
两个模型主要有以下三点不同:
1. 在计算需求方面,Diffusion Model需要很大的计算量,GAN虽然在生成质量上可能不比Diffusion Model,但是不要特别大的计算量,可以在硬件部署上达到实时生成。
2. 在图像分布连续性方面,由于Diffusion Model的迭代式计算带来的高度非线性,所以在一些任务上,如视频编辑,会出现跳变和抖动。但是GAN是通过单步计算,生成的图像会表现得更加连续。
3. 在可编辑性方面,基于GAN所得到的隐空间表现出更具有上下文语义的特征。通过对该空间进行编辑,使得图像具有很强的可编辑性。但是Diffusion Model是从耦合了空间信息的随机噪声图生成图像, 因此在可编辑性上相对不易控制。
高俊博士认为,GAN目前最大的局限是难以扩展到大数据训练,相比之下,Diffusion Model对大数据训练更加友好。另外,相比于Diffusion Model这种去噪的训练过程,GAN通过对抗学习的训练方式,可以更好地捕获单视角(2D)图像生成多视角(3D)图像中的空间关系。
夏威博士认为,GAN由于可以在特征隐空间进行操作,具有更好地可编辑性,但是限制了其更加通用的生成能力。是否能将GAN的对抗学习方式和特征空间的对齐特性用到Diffusion Model的训练过程中,提高其训练速度和可编辑性。
目前像ChatGPT等大语言模型已呈现出百花齐放的状态,在绘图方面Stable Diffusion也表现惊人。但是目前在计算机视觉任务,还没有看到类似ChatGPT这样现象级应用,视觉模型在未来有没有可预见的破圈的应用方式?
目前在视觉模型没有出现现象级应用,与会专家认为主要在以下几个原因:
(1)目前的视觉任务(如分割、检测、分类等)往往是一些实际应用(如机器人、自动驾驶等)的中间任务,普通人不太在意在这些视觉任务上模型性能的提升。
(2)从算法到应用落地还有很长的过程,要用应用层面去思考如何让视觉模型出圈。
(3)移动互联网火起来归功于智能手机的发展,而目前视觉模型缺乏像智能手机这样的硬件接入模式。
对于基于视觉模型破圈的应用,与会专家认为未来可能会在以下几个方向:
(1)修图软件,利用类似“Drag Your GAN”模型编辑照片;
(2)元宇宙,在元宇宙中人、场景、内容等几个要素之间的交互;
(3)3D内容的生成,如动画、电影、游戏等;
(4)与大语言模型结合,视觉语言交互。
我们目前似乎没有看到通用大模型的大量的涌现,大家觉得通用视觉模型现在发展的瓶颈在哪里?以及未来的突破方向可能在哪?
针对目前通用视觉模型的发展瓶颈,与会专家认为主要有以下几点:
(1)如何获取更有价值的数据,十分重要;
(2)现有的视觉模型评价指标需要更新,仅仅靠在基准数据集上刷点已不足以让模型获取新的能力;
(3)相较于语言数据,视觉数据的信息密度很低。在相同的训练数据量下,语言模型可能回更快地看到涌现的效果。
针对通用视觉模型未来的突破方向,与会专家认为会在以下几个方面:
(1)跟大语言模型进行结合,构建多模态大模型;
(2)探究不同的视觉任务(如分割、检测、分类等)之间的联系,构建任务间统一的范式;
(3)将视觉模型拓展到一个开放世界(Open World),构建起一个世界模型(World Model),每个个体小模型通过蒸馏的方式与世界模型进行交互学习;
(4)探究视觉模型在长尾分布问题上的解决方案。

模型在学习过程中不可避免地会遇到灾难性遗忘的问题,面向模型演化连续学习传统的连续学习任务一般会让模型0开始不断积累知识,但是在有了视觉或多模态大模型之后,模型本身已经囊括了互联网上非常非常多的知识,在这个背景下,以大模型为基础的模型演化有哪些值得研究的方向?
针对以大模型为基础的模型演化,与会专家认为有以下几个值得研究的方向:
(1)在模型参数量(模型容量)固定的情况下,如何让模型容纳更多的信息;
(2)探究使用较少的数据达到与使用全部数据训练相当的性能,即数据集蒸馏;
(3)在模型数据足够大的前提下,设计更好的路径选取方式已适用于特定任务。
(4)大模型的稀疏优化。
在当今计算资源消耗越来越大,未来几年在学术界,特别是针对大部分高校的老师和学生缺乏计算资源,他们研究重心应该是什么?
潘新钢教授认为,(1)方法在大部分情况下是通用的,可以在负担得起的计算资源上验证方法的有效性;(2)有些任务并不依赖大模型,而且并不是所有的问题都要从头开始训练模型;(3)在未来,校企合作可能会成为更广泛的研究方式。
夏威博士认为,(1)把一些优化算法(如分布式训练、节约显存操作等)集成到研究当中;(2)在模型设计中减少冗余计算。
高俊博士除了赞同目前还有很多任务不依赖大模型这一观点外,还认为可以把一个大的研究问题分解成多个易于解决的小问题,这些小问题可以用有限的计算资源去解决。另外一个方面要提升代码的高效性。
- 点击“查看原文” ,观看完整大会视频回放 -

具身智能与强化学习前沿进展丨2023智源大会精彩回顾

大模型与人类的未来丨基于认知神经科学的大模型论坛精彩回顾