【自用】选择题 刷题总结
文章目录
- 【代码阅读题】
-
- 一、循环
-
- 1. && 左右两边的条件
- 2. 判断条件为 赋值
- 二、完成逻辑
- 【细节题】
-
- 一、格式
-
- 1. printf() %s 格式 总结
- 2. 转义字符
- 3. 八进制、十进制、十六进制
- 二、类型
-
- 1. 类型提升
- 2. 大小端、函数压栈
- 三、指针 和 数组
- 0.
-
- 1. 函数指针数组
- 2. 指针数组,数组指针
- 3. 数组初始化大小
- 4. 二维数组 的 数组名
- 四、字符串 strlen 和 sizeof
- 0.
-
- 1. 字符串、“” 和 {} 的初始化
- 2. strlen 和 sizeof 对 \0 的处理
- 3. 字符串的初始化
-
-
-
- 待总结
-
-
- 五、结构体 位段
-
- 1. 位段
- 2. 结构体的内存对齐
- 【文字概念题】
-
-
- 1. 宏
- 2. 程序执行过程
-
【代码阅读题】
一、循环
1. && 左右两边的条件
以下for循环的执行次数是()
for(int x = 0, y = 0; (y = 123) && (x < 4); x++);
A. 是无限循环
B. 循环次数不定
C. 4次 √
D. 3次
&&:
左边为真,继续判断右边,都为真,整体为真
左边为假,整体为假,不再往右走
2. 判断条件为 赋值
下列main()函数执行后的结果为()
int func(){
int i, j, k = 0;
for(i = 0, j = -1;j = 0;i++, j++)
{k++;}
return k;}
int main(){
cout << (func());
return 0;}A. -1
B. 0 √
C. 1
D. 2
判断条件是赋值时,可以理解成,此时的 bool 值就是赋给常量的值,0 为假,非 0 为真。
二、完成逻辑
以下 C++ 函数的功能是统计给定输入中每个大写字母的出现次数(不需要检查输入合法性,所有字母都为大
写),则应在横线处填入的代码为()void AlphabetCounting(char a[], int n) {
int count[26] = {}, i, kind = 10;
for (i = 0; i < n; ++i)
_________________;
for (i = 0; i < 26; ++i) {
printf(“%c=%d”, _____, _____);
}
}A ++count[a[i]-‘Z’]
‘Z’-i
count[‘Z’-i]
B ++count[‘A’-a[i]]
‘A’+i
count[i]
C ++count[i]
i
count[i]
D ++count[‘Z’-a[i]] √
‘Z’-i
count[i]
【细节题】
一、格式
1. printf() %s 格式 总结
#include
int main(void) {
printf(“%s , %5.3s\n”, “computer”, “computer”);
return 0;
}
A. computer , puter
B. computer , com √
C. computer , computer
D. computer , compu.ter
-
s格式:
- 遇到 \0 停下
- 用来输出一个串。有几中用法。
-
- %ms: 输出的字符串占 m 列,如字符串本身长度大于 m,则突破获 m 的限制,将字符串全部输出。若串长小于 m,则在 左侧 补空格。
-
- %-ms: 如果串长小于 m,则在 m 列范围内,字符串向左靠,右侧 补空格。
-
- %m.ns: 输出占 m 列,但 只取 字符串中 左端 n 个字符。这 n 个字符输出在 m 列的右侧,左补空格。
注意:如果 n 未指定,默认为 0。
- %m.ns: 输出占 m 列,但 只取 字符串中 左端 n 个字符。这 n 个字符输出在 m 列的右侧,左补空格。
使用printf函数打印一个double类型的数据,要求:输出为10进制,输出左对齐30个字符,4位精度。以下哪个选项是正确的?
A %-30.4e
B %4.30e
C %-30.4f √
D %-4.30f
以下程序的输出结果是()
#include
main() {
char a[10] = {‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, 0}, *p;
int i;
i = 8;
p = a + i;
printf(“%s\n”, p - 3);
}A 6
B 6789 √
C ‘6’
D 789
2. 转义字符
执行下面语句后的输出为
int I=1;
if(I<=0)
printf(“****\n”) ;
else
printf(“%%%%\n”);A %% √
B ****
C 有语法错,不能正确执行
D %%%%
3. 八进制、十进制、十六进制
有以下程序
#include
#include
using namespace std;
int main(){
int m=0123, n=123;
printf(“%o %o\n”, m, n);
return 0;
}程序运行后的输出结果是()
A 0123 0173
B 0123 173
C 123 173 √
D 173 173
-
不同进制 数字的定义:
-
八进制:数字前加 0 ,如
int Octal = 0144; -
十进制:如
int Decimal = 100; -
十六进制:数字前加 0x,如
int Hexadecimal = 0x64; 不同进制 数字的打印:
-
八进制:
o% -
十进制:
d% -
十六进制:
h%
二、类型
1. 类型提升
若有定义语句: int a=10 ; double b=3.14 ; 则表达式 ‘A’+a+b 值的类型是()
A. char
B. int
C. double √
D. float
C 规定表达式中基本类型运算时,将“短类型”变量自动提升为 “最长类型” 参与运算,结果也是此“最长类型”。
2. 大小端、函数压栈
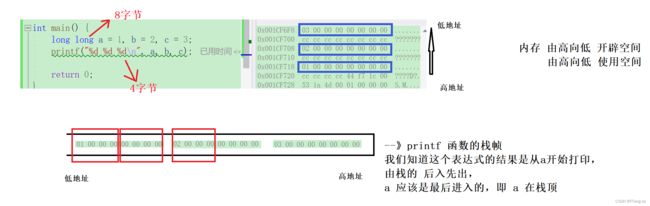
假设在一个 32 位 little endian 的机器上运行下面的程序,结果是多少?
#include
int main(){
long long a = 1, b = 2, c = 3;
printf(“%d %d %d\n”, a, b, c);
return 0;
}A. 1,2,3
B. 1,0,2 √
C. 1,3,2
D. 3,2,1
-
大端:
- 低位 存在 高地址 小端:
- 低位 存在 低地址
三、指针 和 数组
0.
-
数组名 通常是 首元素地址 有两个例外
· sizeof(数组名)
· &数组名
此时数组名代表整个数组 -
[ ] 比 * 的优先级高,判断类型的时候,注意步骤分析
-
- 指针类型 决定了,指针被 解引用 的时候访问了几个字节
-
- 如果是int*的指针,解引用访问4个字节
-
- 如果是char*的指针,解引用访问1个字节
- 指针的类型决定了,指针±1操作时,跳过几个字节,即决定了 步长
- 不同指针类型即使访问大小一样也不能通用(存入内存的东西完全不相同,以为整型和浮点型的存储方式完全不相同的)
-
指针 - 指针,得到的结果的绝对值,是 两个指针之间的元素的个数
注意:不是所有的指针都能相减,指向同一块空间的2个指针才能相减,才有意义 -
标准规定:允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较。但是不允许指针指向第一个元素之前的那个位置的指针进行比较。
-
数组下标的本质:arr[i] -> *(arr + i)
1. 函数指针数组
用变量a给出下面的定义:一个有10个指针的数组,该指针指向一个函数,该函数有一个整形参数并返回一个整型数()
A int *a[10];
B int (*a)[10];
C int (*a)(int);
D int (*a[10])(int); √
D. a 首先与 [10] 结合,是个数组,再往前看,数组里面放的是指针,每个指针指向的都是一个返回值为 int ,参数为 int 的函数
2. 指针数组,数组指针
int *p[4] 与选择项中的() 等价
A. int p[4]
B. int *p
C. int *(p[4]) √
D. int (*p)[4]
- 指针数组:
- 这个变量是一个 数组
- 这个数组的所有元素都是指针类型 数组指针:
- 这个变量是一个 指针
- 这个指针指向一个数组的首地址
- +1 跨越指向数组的大小
指针数组:是个数组,这个指针,指向一个数组
数组指针:是个指针,指针里面存的每个元素是一个数组
总之:看变量名先跟什么结合,后面直接接[]就是一个数组;后面没有反倒是前面有一个*,就是指针。
-
int*p[4]
- 指针数组
- 因为 [ ] 比 * 的优先级高,所以p先于[ ]结合,是一个数组,然后再与*结合,所以这个数组p[4]的类型是int *,就是指向int的指针,就是“元素是指向整形数据的指针的数组”。每个元素都是一个指针,一共有4个元素。指针就是地址本身,而指针变量是用来存放地址的变量。 int(*p)[4]
- 数组指针
- p先和 结合,意味着p是一个指针,他指向int [10],即p是一个指向一个数组的指针,比如a[4][10],它包括a[0][10],a[1][10],a[2][10],a[3][10],a[0],a[1],a[2],a[3],可以表示成a[i]==(a+i);所以(*P)[10],p可以等于a+i,p是指向大小为10的数组,p的增一减一是以一行为单位的(比如4行10列)。
- 实际int(*p)[4]就是一个二维数组,代表n行4列的数组,
3. 数组初始化大小
32位系统中,定义**a[3][4],则变量占用内存空间为()。
A. 4
B. 48 √
C. 192
D. 12
- sizeof(a),a 代表整个数组
- 初始化数组空间:就是看里面元素大小是多少 * 元素个数

4. 二维数组 的 数组名
. 数组定义为”int a[4][5];”, 引用”*(a+1)+2″表示()(从第0行开始)
A a[1][0]+2
B a数组第1行第2列元素的地址 √
C a[0][1]+2
D a数组第1行第2列元素的值
分析 *(a+1)+2:
a 是二维数组的数组名,即二维数组第 0 行的数组的地址;
+1 跳过的步长就是指针类型的大小,即跳过第 0 行,a+1 便是二维数组第 1 行的地址;
*(a+1) 是对第 1 行的地址解引用,拿到的是第 1 行首元素的地址;
+2 跳过两个元素地址,此时指针指向第 1 行,第 2 列元素的地址。
四、字符串 strlen 和 sizeof
0.
-
strlen
- 是一个库函数(单位是字符串个数,只针对字符串)
- 专门求字符串长度,从参数给定的地址向后,统计 \0 之前出现的字符的个数,即 不统计 \0
- ps:%s 也是遇到 \0 为止 sizeof
- 是一个操作符(单位是字节)
- sizeof(数组名),可以统计数组的大小(=元素个数*每个元素的大小),数组大小包括 \0,即 统计 \0 字符串
- “xx” 初始化的数组,末尾最后有 \0
- {‘x’,‘x’}初始化的数组,末尾没有 \0
- 不完全初始化,剩余的位置用 0 填满

1. 字符串、“” 和 {} 的初始化
下面叙述错误的是()
char acX[]=“abc”;
char acY[]={‘a’,‘b’,‘c’};
char *szX=“abc”;
char *szY=“abc”;A acX与acY的内容可以修改
B szX与szY指向同一个地址
C acX占用的内存空间比acY占用的大
D szX的内容修改后,szY的内容也会被更改 ×
分析:
A. acX 和 acY 都是数组,当然可以修改。
B. 因为 “abc” 是常量字符串,根据其写时复制机制,szX 和 szY 所指内容是一样的,没必要分配两个空间。只有当我们要修改其中一个时,系统才为我们复制一份,此时一个指针会指向新拷贝的那一份,这样对一个的修改就不会影响到另一个实体。
C. 因为acX是字符串数组,字符串的尾部有一个结束符 ‘\0’,所以 acX 有四个元素,内存空间比 acY 大。
D. 字符指针指向的是常量字符串,常量字符串不能修改
2. strlen 和 sizeof 对 \0 的处理
定义char dog[]=“wang\0miao”;那么sizeof(dog)与strlen(dog)分别是多少()
A. 10,4 √
B. 4,4
C. 9,9
D. 9,4
3. 字符串的初始化
下列程序的打印结果是()
char p1[15] = “abcd”, *p2 = “ABCD”, str[50] = “xyz”;
strcpy(str + 2, strcat(p1 + 2, p2 + 1));
printf(“%s”, str);A. xyabcAB
B. abcABz
C. ABabcz
D. xycdBCD √
待总结
-
- 复制 source 字符串内容(包括 \0),从数组 destination 指向的位置开始覆盖。
-
- 在 destination 的原数据上完成的修改
-
- 最后缝合成的新 destination 的元素个数,超过原数组长度时,会产生越界。
-
- 在 destination 开始的数组位置,向后追加 source 数组内容(包括 \0)
-
- 在 destination 的原数据上完成的修改
-
- destination 和 source 数据内容不能交叠
char * strcpy ( char * destination, const char * source );
char * strcat ( char * destination, const char * source );
五、结构体 位段
1. 位段
在32位cpu上选择缺省对齐的情况下,有如下结构体定义:
struct A{
unsigned a : 19;
unsigned b : 11;
unsigned c : 4;
unsigned d : 29;
char index;
};则sizeof(struct A)的值为()
A 9
B 12
C 16 √
D 20

2. 结构体的内存对齐
下面两个结构体
在#pragma pack(4)和#pragma pack(8)的情况下,结构体的大小分别是()struct One{
double d;
char c;
int i;
}
struct Two{
char c;
double d;
int i;
}A. 16 24,16 24
B. 16 20,16 20
C. 16 16,16 24 √
D. 16 16,24 24
-
内存对齐:
- 每个成员 的 对齐数:min(成员类型大小,默认对齐数)
- 整个结构体 的 对齐数:max(各个成员对齐数)
- (VS 环境下默认对齐数为 8;Linux 环境默认不设对齐数,对齐数就是结构体成员类型自身大小)
分析:
#pragma pack(4)
struct One {
double d; // min(8,4)--> 4 --> 0~7
char c; // min(1,4)--> 1 --> 8
int i; // min(4,4)--> 4 --> 9~12(至此占了13字节)
}; // max(4,1,4)--> 最后的结果为4的倍数:16
struct Two {
char c; // min(1,4)--> 1 --> 0
double d; // min(8,4)--> 4 --> 4~11
int i; // min(4,4)--> 4 --> 12~15(至此占了16字节)
}; // max(1,4,4)--> 最后的结果为4的倍数:16
#pragma pack(8)
struct One {
double d; // min(8,8)--> 4 --> 0~7
char c; // min(1,8)--> 1 --> 8
int i; // min(4,8)--> 4 --> 9~12(至此占了13字节)
}; // max(4,1,4)--> 最后的结果为 8 的倍数:16
struct Two {
char c; // min(1,8)--> 1 --> 0
double d; // min(8,8)--> 8 --> 8~15
int i; // min(4,8)--> 4 --> 16~19(至此占了20字节)
}; // max(1,8,4)--> 最后的结果为 8 的倍数:24
【文字概念题】
1. 宏
下列关于C/C++的宏定义,不正确的是()
A 宏定义不检查参数正确性,会有安全隐患
B 宏定义的常量更容易理解,如果可以使用宏定义常量的话,要避免使用const常量 ×
C 宏的嵌套定义过多会影响程序的可读性,而且很容易出错
D 相对于函数调用,宏定义可以提高程序的运行效率
2. 程序执行过程
由多个源文件组成的C程序,经过编辑、预处理、编译、链接等阶段会生成最终的可执行程序。下面哪个阶段可以发现被调用的函数未定义()
A. 预处理
B. 编译
C. 链接 √
D. 执行