版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images
论文链接:https://arxiv.org/pdf/1704.01474.pdf
翻译版github自取:https://github.com/CHENG-EMMA1/DLA
页面分割是文档图像分析和理解的重要前提步骤。目标是将文档图像分割为感兴趣的区域。与机器打印文档图像的分割相比,历史文档图像的页面分割由于布局结构、装饰、书写风格、退化、噪音大、布局不受影响等多种变化而更具挑战性。因此,传统的页面分割方法不能直接应用于手写历史文档。手写历史文档的分割方法很多,主要分为基于规则的分割和基于机器学习的分割。
Ⅰ. 动机(Motivation)
- 手写历史文档的分割的传统方法依赖于精心制作的特征。或大量的先验知识。或将手工制作的特征与领域知识相结合的模型。
- 单词的笔划、句子中的单词、段落中的句子等元素具有从低到高的层次结构。因为这些模式在文档的不同部分重复。基于这些特性,特征学习算法可以用来学习文档图像的布局信息。
Ⅱ. 亮点(Highlights)
- 文章在不使用文档布局结构的任何先验知识的情况下创建通用的页面分割方法。
- 文章开发一种端到端方法。将特征学习和分类器训练结合在一起。
- 许多研究人员致力于开发深度CNN架构来解决不同的问题,但在所提出的方法中,仅训练了一个简单的单卷积层CNN。在公共历史文档图像数据集上的实验表明,尽管该方法结构简单,超参数调整少,但与其他CNN结构相比,该方法取得了相当的效果。
Ⅲ. 方法(METHODOLOGY)
为了创建一般的页面分割方法,而不使用文档的布局结构的任何先验知识,文章将页面分割问题视为像素标记问题。作者建议使用CNN进行像素标记任务。其主要思想是学习一组特征检测器,并根据特征检测器提取的特征训练非线性分类器。通过一组特征检测器和分类器,可以将未经过预习的文档图像上的像素划分为不同的类别。
A. 前处理(Preprocessing)
为了加快像素标注过程,对于给定的文档图像,首先应用超像素算法来生成超像素(由一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成的小区域)。超像素是包含属于同一对象的像素的图像块。
文章不标记所有像素,而是只标记每个超像素的中心像素,并将该超像素中的其余像素分配给相同的标签。应用简单线性迭代聚类(SLIC)算法作为预处理步骤,为给定的文档图像生成超像素。
- 种子像素初始化
SLIC利用了简单的聚类(贪婪)算法,初始时,每一个聚类的中心被平均的分布在图像中,而超像素的个数,可以基本由这些中心点来决定。每一步迭代,种子像素合并周围的像素,形成超像素。
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第1张图片](http://img.e-com-net.com/image/info8/a49ab1fa54444b60be9e8c0b4edc3ae0.jpg)
超像素算法以及SLIC(simple linear iterative clustering)即简单的线性迭代聚类算法,studyeboy作者介绍的很详细,详细见:https://blog.csdn.net/studyeboy/article/details/93981017
B. CNN架构(CNN Architecture )
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第2张图片](http://img.e-com-net.com/image/info8/6998ed16a3124134a0d3557bd6679869.jpg)
文章提出的CNN架构如图1所示。其结构可概括为28×28×1−26×26×4−100−M。M是类别的数量。输入是灰度图像块。图像块的大小为28×28像素。CNN架构只包含一个由4个内核组成的卷积层。每个内核的大小为3×3像素。与其他传统的CNN体系结构不同,文章的不使用池层。然后,100个神经元的完全连接层跟随卷积层。最后一层由逻辑回归和softmax组成,该回归输出每个类别的概率,例如:
其中,x是全连接层的输出, W i W_{i} Wi和 b i b_{i} bi是该层中第 i t h i^{th} ith个神经元的权重和偏差,M是类的数量。预测类 y ^ \hat{y} y^是具有最大概率的类,即
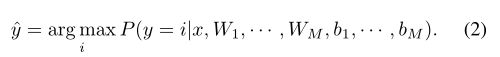
在CNN的卷积层和完全连接层中,整流线性单元(RELU)被用作神经元。ReLU的形式如下:
![]()
其中x是神经元的输入,在 CNN 中使用 ReLUs作为神经元优于传统的 sigmoid神经元。
C.训练(Training)
为了训练 CNN,对于每个超像素,文章生成一个以该超像素为中心的patch(块)。patch被认为是网络的输入。每个patch的大小为28×28像素。每个patch的标签是其中心像素的标签。训练图像的patch用于训练网络。
在CNN中,Loss function为交叉熵损失,即

其中,X为训练图像块的集合
![]()
Y为训练图像块对应的标签集:
![]()
n为训练图像patch的数量
对于每个 x ( i ) x^{(i)} x(i), a ( x ( i ) ) a(x^{(i)}) a(x(i))是等式1中定义的 CNN 的输出。CNN 使用随机梯度下降 (SGD) 和 dropout技术进行训练。 dropout 的目标是通过向训练样本引入随机噪声来避免过拟合。 在训练过程中,神经元的输出以 0.5 的概率被屏蔽。
Ⅳ. 实验(EXPERIMENT )
在六个公共手写历史文档图像数据集上进行了实验。
A.数据集(Datasets )
- G. Washington数据集:由纸上用墨水用英文书写的页面组成,图像为灰度。
- Parzival数据集:由羊皮纸上用墨水书写的手稿图像组成,图像是彩色的。Parzival数据集由13世纪三位作家所写的页面组成。
- St.Gall:由羊皮纸上用墨水书写的手稿图像组成,图像是彩色的。数据集由一份用拉丁文写成的中世纪手稿组成。 [1] 中介绍了以上三个数据集的ground true的详细信息。
- 三个布局更复杂的新数据集:
- CB55数据集由14世纪的手稿组成,由一位作者用意大利语和拉丁语撰写。
- CSG18和CSG863数据集由11世纪的手稿组成,这些手稿用拉丁语书写。未指定两个数据集的作者数量。三个数据集的详细信息在 [2] 中给出。
在实验中,所有图像都使用缩放因子 2 − 3 2^{-3} 2−3进行缩放。表Ⅰ给出了六个数据集的训练集、测试集和验证集的详细信息。
表Ⅰ. 训练、测试和验证集的详细信息。TR、TE和VA分别表示训练集、测试集和验证集。![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第3张图片](http://img.e-com-net.com/image/info8/8adbdc205f294bec8737d9e434dd11f4.jpg)
B. 指标(Metrics)
实验中使用的度量是:像素精度、平均像素精度、平均IU和频率加权IU(f.w.IU)。
C. 评估(Evaluation)
文章所提出的方法与作者以前的方法[3]、[4]进行了比较。与所提出的方法类似,超像素被认为是标记的基本单元。
在[3]中,利用堆叠的卷积自动编码器以无监督的方式在随机选择的灰度图像块上学习特征。然后利用超像素的特征和标签训练分类器。利用训练好的分类器,将超像素分类为不同的类别。
在[4]中,应用条件随机场(CRF)来为超像素标记任务联合建模局部和上下文信息。[3]中训练的分类器被认为是[2]中的局部分类器。然后利用局部分类器训练上下文分类器,将局部分类器的输出作为输入,输出给定标签的分数。利用局部分类器和上下文分类器,训练CRF来标记给定图像的超像素。
在实验中,作者使用一个多层感知器(MLP)作为[3]、[4]中的局部分类器,并使用另一个多层感知器(MLP)作为上下文分类器。采用简单线性迭代聚类算法(SLIC)生成超像素。SLIC算法相对于其他超像素算法的优越性在[1]中得到了证明。在实验中,每幅图像生成3000个超像素。
表II报告了三种方法中的像素精度、平均像素精度、平均IU和f.w.IU。结果表明,所提出的CNN方法比以往的方法具有更好的性能。图2给出了这三种方法的分割结果。我们可以看到,与其他方法相比,CNN在视觉上取得了更准确的分割结果。
表 II:仅使用局部 MLP、CRF 和提议的 CNN 进行超像素标记的性能(百分比)。
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第4张图片](http://img.e-com-net.com/image/info8/bc2dc7273a3243aa8e9839f2d7b2140b.jpg)
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第5张图片](http://img.e-com-net.com/image/info8/de91cc7cb84048529289451914531717.jpg)
图2. 从上到下分别对Parzival、CB55和CSG863数据集的分割结果。颜色:黑色、白色、蓝色、红色和粉色分别用于表示:外围、页面、文本、装饰和注释。从左到右的列分别是:输入、ground true、局部MLP、CRF和CNN的分割结果。
D. 最大池化(Max Pooling)
池化是CNN中广泛使用的技术。 最大池化是最常见的池化类型,用于减少表示的空间大小以减少网络参数的数量。 为了展示最大池化对分割任务的影响。 文章在卷积层之后添加了一个最大池化层。 池化大小为2×2像素。 表 II 报告了具有最大池化层的 CNN 的性能。 我们可以看到,仅在CB55数据集上,平均像素精度和平均IU略有提高。 一般来说,增加一个最大池化层并不能提高分割任务的性能。 原因是对于某些计算机视觉问题,例如自然图像中的对象识别和文本提取,特征的确切位置不如其相对于其他特征的粗略位置重要。 但是,对于给定的文档图像,要标记patch中心的像素,仅知道该patch中某处是否有文本是不够的,还要知道文本的位置。 因此,特征的准确位置有助于页面分割任务。
E. Kernels的数目(Number of Kernels)
为了展示卷积层的核数对分割任务的影响。 我们将内核数定义为 K。 在实验中,设置K∈{1,2,4,6,8,10,12,14}。 图 3 报告了具有不同核数的一个卷积层 CNN 的 f.w. IU。我们可以看到,除了在 CS18 数据集上,当 K≥4 时,性能没有提高。
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第6张图片](http://img.e-com-net.com/image/info8/8e30f89643db4e699212160f0202f35a.jpg)
图3. 一个卷积层 CNN 在不同数量的滤波器上的f.w. IU
F. 层数(Number of Layers)
为了展示卷积层数对页面分割任务的影响。 我们逐步添加卷积层,这样当前层上的内核比前一层多两个。 图 4 报告了具有不同卷积层数的 CNN 的 f.w. IU。 结果表明,层数不影响分割任务的性能。 但是,在 G. Washington 数据集上,层数越多,性能略有下降。 原因是与其他数据集相比,G. Washington数据集的训练图像较少。
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第7张图片](http://img.e-com-net.com/image/info8/b486f0ebf5a64238afc8fdfb9a8069d5.jpg)
图4. CNN 在不同卷积层数上的 f.w. IU
G. 训练图像数量(Numbers of Training Images)
为了展示不同数量的训练图像下的性能。 对于每个数据集,我们在训练集中选择 N 个图像来训练 CNN。 对于每个实验,批次数设置为5000。图 5 报告了 不同N值下的f.w. IU,使得N∈{1,2,4,8,10,12,14,16,18,20}。我们可以看到,一般来说,当 N > 2 时,性能并没有提高。 然而,在G. Washington数据集,训练图像越多,性能略有下降。原因是与其他数据集相比,在G. Washington数据集页面更加多样化,ground true不太固定。
![版面分析:[ICDAR2017] Convolutional Neural Networks for Page Segmentation of Historical Document Images_第8张图片](http://img.e-com-net.com/image/info8/8889a014b9d54e53ad2649215f1de190.jpg)
图5. CNN 在不同数量的训练图像上的 f.w. IU
H. 运行时间(Run Time)
提出的CNN是用python的Theano库实现的[30]。这些实验是在一台采用Intel Core i7-3770 的PC上进行的。4GHz处理器和16GB RAM。平均而言,对于每幅图像,CNN需要大约1秒的处理时间。超级像素标记法[17]和CRF模型[18]分别需要2秒和5秒。
Ⅴ. 结论(CONCLUSION)
在本文中,我们提出了一种用于手写历史文档图像的页面分割的卷积神经网络 (CNN)。 与依赖于使用手工特征训练的现成分类器的传统页面分割方法相比,所提出的方法直接从图像块中学习特征。 此外,特征学习和分类器训练合二为一。 在公共数据集上的实验表明,所提出的方法优于以前的方法。 虽然许多研究人员专注于将非常深的 CNN 架构应用于不同的任务,但我们表明,与其他网络架构相比,通过简单的一个卷积层 CNN,我们实现了可比的性能。
REFERENCES
[1]K. Chen, M. Seuret, H. Wei, M. Liwicki, J. Hennebert, and R. Ingold, “Ground truth model, tool, and dataset for layout analysis of historical documents,” inIS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, 2015, pp. 940 204–940 204.
[2]F. Simistira, M. Seuret, N. Eichenberger, A. Garz, M. Liwicki, and R. Ingold, “Diva-hisdb: A precisely annotated large dataset of challenging medieval manuscripts,” inFrontiers in Handwriting Recognition (ICFHR), 2016 15th International Conference on. IEEE, 2016, pp. 471–476.
[3]K. Chen, C.-L. Liu, M. Seuret, M. Liwicki, J. Hennebert, and R. Ingold, “Page segmentation for historical document images based on superpixel classification with unsupervised feature learning,” inDocument Analysis System (DAS), 2016 12th IAPR International Workshop on. IEEE, 2016, pp. 299–304.
[4]K. Chen, M. Seuret, M. Liwicki, J. Hennebert, C.-L. Liu, and R. Ingold, “Page segmentation for historical handwritten document images using conditional random fields,” inFrontiers in Handwriting Recognition (ICFHR), 2016 15th International Conference on. IEEE, 2016, pp. 90–95.