代码随想录算法训练营第6天|Leetcode 1、两数之和、Leetcode 202 快乐数、 Leetcode 242 有效的字母异位词、 Leetcode 349 两个数组的交集
- Leetcode 1、两数之和
- Leetcode 202 快乐数
- Leetcode 242 有效的字母异位词
- Leetcode 349 两个数组的交集
242.有效的字母异位词
Java:调用charAt()方法得到一个字符,字符与字符相减,是两个字符的ASCII码相减,返回就是int。
class Solution {
public boolean isAnagram(String s, String t) {
int[] record = new int[26];//定义一个数组叫做record用来上记录字符串s里字符出现的次数。
for (int i = 0; i < s.length(); i++) {
record[s.charAt(i) - 'a']++; // 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
}
for (int i = 0; i < t.length(); i++) {
record[t.charAt(i) - 'a']--;
}
for (int count: record) {
if (count != 0) { // record数组如果有的元素不为零0,说明字符串s和t 一定是谁多了字符或者谁少了字符。
return false;
}
}
return true; // record数组所有元素都为零0,说明字符串s和t是字母异位词
}
}cr.代码随想录
数组其实就是一个简单哈希表,而且这道题目中字符串只有26个小写字符,那么就可以定义一个数组,来记录字符串s里字符出现的次数。
需要定义一个多大的数组呢,定一个数组叫做record,大小为26 就可以了,初始化为0,因为字符a到字符z的ASCII也是26个连续的数值。
为了方便举例,判断一下字符串s= "aee", t = "eae"。
定义一个数组叫做record用来上记录字符串s里字符出现的次数。
需要把字符映射到数组也就是哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25。
再遍历 字符串s的时候,只需要将 s[i] - ‘a’ 所在的元素做+1 操作即可,并不需要记住字符a的ASCII,只要求出一个相对数值就可以了。 这样就将字符串s中字符出现的次数,统计出来了。
那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作。
那么最后检查一下,record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true。
时间复杂度为O(n),空间上因为定义是的一个常量大小的辅助数组,所以空间复杂度为O(1)。
349. 两个数组的交集
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
此时就要使用另一种结构体了,set 。
import java.util.HashSet;
import java.util.Set;
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
if (nums1 == null || nums1.length == 0 ||
nums2 == null || nums2.length == 0) {
return new int[0];
}
Set set1 = new HashSet<>();
Set resSet = new HashSet<>();
//遍历数组1
for (int i : nums1) {
set1.add(i);
}
//遍历数组2的过程中判断哈希表中 是否存在该元素
for (int i : nums2) {
if (set1.contains(i)) {
resSet.add(i);
}
}
int[] arr = new int[resSet.size()];
int j = 0;
for(int i : resSet){
arr[j++] = i;
}
return arr;
}
}
202.快乐数
class Solution {
public boolean isHappy(int n) {-
Set record = new HashSet<>();
while (n != 1 && !record.contains(n)) {
record.add(n);
n = getNextNumber(n);
}
return n == 1;
}
private int getNextNumber(int n) {
int res = 0;
while (n > 0) {
int temp = n % 10;
res += temp * temp;
n = n / 10;
}
return res;
}
}
求和的过程中,sum会重复出现,这对解题很重要!为什么会循环呢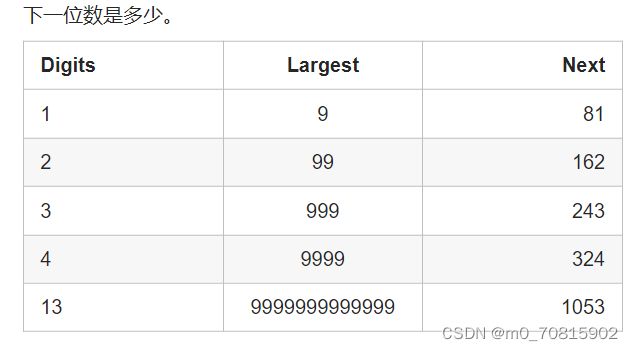
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
所以这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
还有一个难点就是求和的过程,如果对取数值各个位上的单数操作不熟悉的话,做这道题也会比较艰难。
1.两数之和
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
if(nums == null || nums.length == 0){
return res;
}
Map map = new HashMap<>();
for(int i = 0; i < nums.length; i++){
int temp = target - nums[i]; //temp=7 // 遍历当前元素,并在map中寻找是否有匹配的key
if(map.containsKey(temp)){
res[0] = map.get(temp);//返回temp的值
res[1] = i;
break;
}
map.put(nums[i], i); // 如果没找到匹配对,就把访问过的元素和下标加入到map中
}
return res;
}
} 当我们需要查询一个元素是否出现过,或者一个元素是否在集合里的时候,就要第一时间想到哈希法。
cr.代码随想录
本题呢,我就需要一个集合来存放我们遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
那么我们就应该想到使用哈希法了。
因为本地,我们不仅要知道元素有没有遍历过,还有知道这个元素对应的下标,需要使用 key value结构来存放,key来存元素,value来存下标,那么使用map正合适。
再来看一下使用数组和set来做哈希法的局限。
数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
此时就要选择另一种数据结构:map ,map是一种key value的存储结构,可以用key保存数值,用value在保存数值所在的下标。