详解分类指标Precision,Recall,F1-Score
文章目录
- 1. Precision(精度)
- 2. Recall(召回率)
- 3. F1-Score
- 4. Accuracy(准确率)
- 5. P-R 曲线
- 6. TPR、FPR
-
- 6.1 TPR(真正率)
- 6.2 FPR(假正率)
- 7. ROC曲线
- 8. AUC曲线
- 参考资料
在使用机器学习算法的过程中,我们需要对建立的模型进行评估来辨别模型的优劣,下文中主要介绍常见的几种评估指标。以下指标都是对分类问题的评估指标。
在二分类任务中,假设只有正类(1)和负类(0)两个类别,True(1)和False(0)分别表示预测结果对或错;Positive(1)和Negative(0)表示预测为正类或负类。
将标有正负例的数据集喂给模型后,一般能够得到下面四种情况,可以用混淆矩阵来表示:
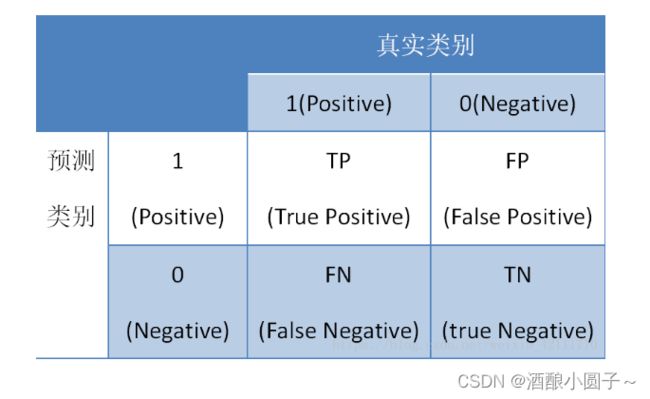
- True Positive (TP):模型将正实例判定为正类。(预测正确,预测类别为正类)
- True Negative (TN):模型将负实例判定位负类。(预测正确,预测类别为负类)
- False Negative (FN):模型将正实例判定为负类。(预测错误,预测类别为负类)
- False Positive (FP) :模型将负实例判定位正类。(预测错误,预测类别为正类)
这里:True/False代表判断结果是否正确,Positive/Negative代表预测类别结果。
1. Precision(精度)
Precision(精度):针对判定结果而言,预测为正类的样本(TP+FP)中真正是正实例(TP)所占的比率。
Precision = 被正确预测的Positive样本 / 被预测为Positive的样本总数
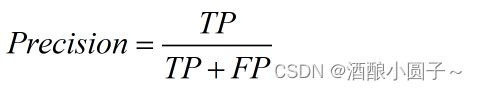
Precision(精度)又称为查准率。Precision越高越好,越高意味着模型对“预测为正”的判断越可信。
2. Recall(召回率)
Recall(召回率):针对样本而言,被正确判定的正实例(TP)在总的正实例中(TP+FN)所占的比率。
Recall = 被正确预测的Positive样本 / 实际为Positive的样本总数
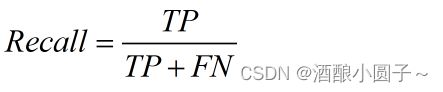
Recall(召回率)又称为查全率。Recall同样越高越好,越高意味着模型对“实际为正”的样本误判越少,漏判的概率越低。
注意: 精度和召回率虽然没有必然的关系,然而在大规模数据集合中,这两个指标却是相互制约的。一般情况下,召回率高时,精度低;精度高时,召回率低。
3. F1-Score
F1-Score:是精度(Precision)和召回率(Recall)的加权调和平均
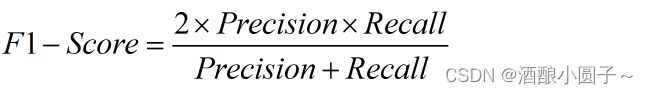
F1-Score值越接近1,则模型在查全率与查准率两方面的综合表现越好。而Precision或Recall中,一旦有一项非常拉跨(接近于0),F值就会很低。
4. Accuracy(准确率)
Accuracy(准确率):模型正确分类的样本数(正实例被判定为正类,负实例被判定为负例)在总样本中的比重。
Accuracy = 被正确预测的样本数 / 样本总数
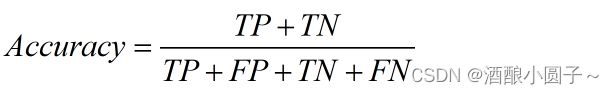
Accuracy(准确率)vs. Precision(精度)
模型A假设现有模型A对中国人的“恶性肿瘤发病率”进行预测,预测的准确率(Accuracy)为99.7%。请问这个模型效果如何?是否可用?
答:很难说。因为仅通过准确率,我们不知道假正(FP)和假负(FN)的样本量有多少,以及占比如何。实际上,2017年,全国恶性肿瘤发病率为0.3%。我们只要猜测所有中国人都不会患病,就可以达到99.7%的准确率。但这个预测,对于我们而言,并没有带来任何的增量信息。
-
Accuracy(准确率)从全部数据的角度去计算分类正确的样本数所占的比例,是对分类器整体上的正确率的评价。当数据中存在类别不均衡等问题时,使用准确率无法得出具有信息量的判断结果。
-
而Precision(精度)在分类中对应的是某个类别(分子是预测该类别正确的数量,分母是预测为该类别的全部数据的数量)。Precision是分类器预测为某一个类别的正确率的评价。
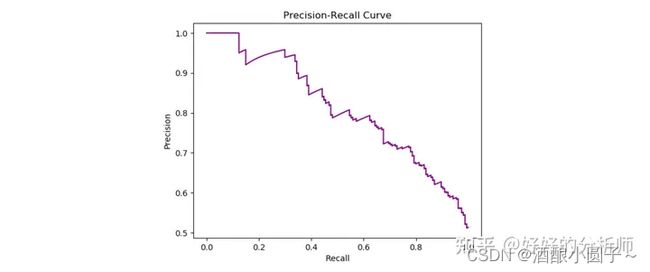
5. P-R 曲线
P-R Curve(全准曲线):是由P值与R值构成的曲线。将模型不同参数对应的(R值,P值)绘制成曲线,就得到了全准曲线。
6. TPR、FPR
上面讲了这么多评价指标,我们发现一个问题:目前的评价体系当中,并没有用上所有的可用信息。上述指标中,考虑了P值和R值,但是都没有考虑TN(True Negative)样本的影响。
那么,有没有什么度量可以考虑到整个混沌矩阵的信息呢?
这里,可以引入真正率(True Positive Rate)和假正率(False Positive Rate)两个指标来解决上述信息缺失的问题。
6.1 TPR(真正率)
TPR(True Positive Rate,真正率):统计“实际为正的样本”中,有多少预测是正确的。

“真正率”就是“查准率”,只不过对同一个事物,有两个不同的称呼。真正率越高越好,越高意味着模型对“正样本”的误判越少。
6.2 FPR(假正率)
FPR(False Positive Rate,假正率):统计“实际为负的样本”中,有多少预测是错误的。

假正率越低越好,越低意味着模型对“负样本”的误判越少。
TPR和FPR有一个好处:不会受样本的均衡程度的影响。
TPR和FPR的条件概率都是基于真实样本的,而且TPR只基于正样本,而FPR只基于负样本。这就使得TPR和FPR不会受样本均衡程度的影响。
而ROC曲线与AUC面积,就是在TPR和FPR的基础上衍生出来的概念。
7. ROC曲线
ROC曲线(Receiver Operating Characteristic Curve),是以假正率(FPR)为横轴,真正率(TPR)为纵轴所组成的坐标图,和受试者在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。ROC曲线在测试集中的正负样本的分布变化时,能够保持不变。
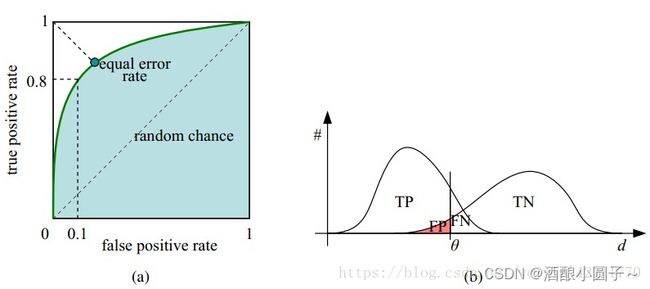
在整个ROC曲线上,约靠近左上角(0,1)的点,对应的模型参数越好。
ROC曲线上的每个点对是在某个阈值threshold下得到的(FPR, TPR)。设定一个阈值,大于这个阈值的实例被划分为正实例,小于这个值的实例则被划分为负实例,运行模型,得出结果,计算FPR和TPR值,更换阈值,循环操作,就得到不同阈值下的(FPR, TPR)对,即能绘制成ROC曲线。
8. AUC曲线
AUC曲线(Area Under Curve)是ROC曲线下的面积值,在0.5到1.0区间内。之所以使用AUC值作为评价标准是因为很多时候并不能从ROC曲线中判别模型的好坏,AUC值能量化模型的性能效果。AUC值越接近于1,说明模型性能越好,模型预测的准确率越高;如果多个模型进行性能比较,一般以AUC值大的模型比AUC值小的模型的性能好。
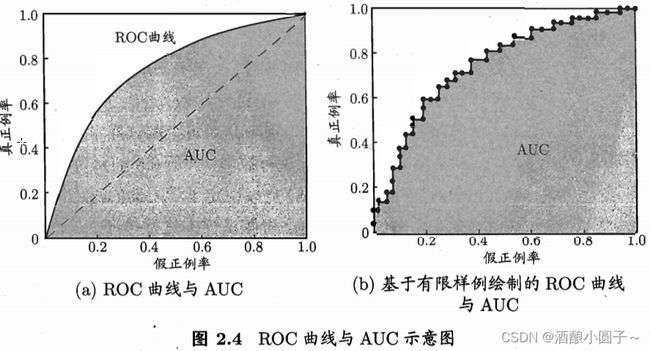
当AUC等于0.5时,整个模型等价于一个随机分类器。AUC的面积越大,模型的整体表现越好。
参考资料
- 机器学习中常见的评估指标:https://blog.csdn.net/weixin_42111770/article/details/81015809
- accuracy 和 precision 的区别是什么?:https://www.zhihu.com/question/321998017/answer/2303096310