三十四章:Class Re-Activation Maps for Weakly-Supervised Semantic Segmentation ——弱监督语义分割中的类别重新激活图
0.摘要
提取类别激活图(CAM)可以说是生成弱监督语义分割(WSSS)伪掩码的最常用步骤。然而,我们发现导致伪掩码不理想的关键在于广泛使用的二元交叉熵损失(BCE)在CAM中的应用。具体而言,由于BCE的类别求和池化特性,CAM中的每个像素可能对同一感受野中出现的多个类别都有响应。结果就是,对于给定的类别,其热点CAM像素可能错误地侵占了属于其他类别的区域,或者非热点像素实际上可能是该类别的一部分。为此,我们引入了一种令人尴尬地简单但效果惊人的方法:通过使用softmax交叉熵损失(SCE)对已收敛的CAM进行重新激活,称为ReCAM。给定一张图像,我们使用CAM提取每个单独类别的特征像素,并将它们与类别标签一起使用,通过SCE学习另一个全连接层(在骨干网络之后)。一旦收敛,我们可以像在CAM中一样提取ReCAM。由于SCE的对比性质,像素响应被分解为不同的类别,因此预期的掩码模糊度较低。在PASCAL VOC和MS COCO上的评估结果显示,ReCAM不仅生成高质量的掩码,而且在任何带有很小额外开销的CAM变体中支持即插即用。我们的代码公开在https://github.com/zhaozhengChen/ReCAM。
1.引言
弱监督语义分割(WSSS)旨在通过使用“弱”标签(如涂鸦、边界框和图像级别的类别标签)而不是“强”像素级别的标签来降低注释“强”像素级别掩码的高成本。其中,图像级别的类别标签是最经济但也最具挑战性的预算,因此是我们本文的重点。该流程通常包括三个步骤:
1)使用图像级别的类别标签训练多标签分类模型;
2)提取每个类别的类别激活图(CAM),生成0-1的掩码,并进行一些细化操作,如腐蚀和膨胀;
3)将所有类别的掩码作为伪标签,以标准的全监督方式学习分割模型。
这个流程中有很多因素会影响最终分割模型的性能,但第一步中的分类模型是关键。我们经常观察到两个常见的缺陷:在对象类别A的CAM中,有
1)虚假阳性像素,它们被激活为类别A,但实际标签是类别B,其中B通常是类别A的混淆类别,而不是语义分割中的背景类别;
2)虚假阴性像素,它们属于类别A,但被错误地标记为背景。
研究结果:我们指出,在使用具有sigmoid激活函数的二元交叉熵(BCE)损失进行模型训练时,这些缺陷尤为明显。具体而言,sigmoid函数的公式为f(x) = 1 / (1 + e^(-x)),其中x表示任何单个类别的预测逻辑。输出被输入到BCE函数中计算损失值。该损失值表示对于x的错误分类的惩罚强度。因此,BCE损失不是类别互斥的,对于一个类别的错误分类并不会对其他类别的激活进行惩罚。这对于训练多标签分类器是必不可少的。然而,当通过这些分类器提取CAM时,我们观察到以下缺点:不同类别之间存在非独占性激活(导致CAM中的虚假阳性像素);而且总类别上的激活受限(导致虚假阴性像素),因为部分激活是共享的。
动机:我们进行了一些玩具实验,以实证地展示在使用BCE时CAM的质量较差。我们从MS COCO 2014数据集中选择了单标签的训练图像(约占训练集的20%),分别用于训练5类和80类分类器。对于5类,我们选择了5个有困惑激活问题的有蹄动物类别(例如马和牛)。我们分别使用两种损失进行模型训练:BCE损失和softmax交叉熵(SCE)损失,后者是分类任务中最常用的损失函数。我们使用验证集中的单标签图像来评估模型的分类性能,如图1 (a)所示,并使用训练集和验证集中的单标签图像来检查模型对对象上正确区域的激活能力,即CAM的质量,如图1 (b)所示。
我们对此感到好奇,
1)对于80类模型,BCE和SCE产生了相同质量的分类器,但CAM明显不同,
2)SCE模型的CAM具有更高的mIoU,并且在验证图像中这种优势几乎被保持。
一个小但关键的观察是,对于5个有蹄动物类别,BCE显示出较弱的分类能力。我们指出,这是因为BCE的sigmoid激活函数没有强制进行类别排他性学习,导致模型在相似类别之间产生混淆。然而,SCE不同。它的softmax激活函数是exp(x) / (exp(x) + Σexp(y)),其中y表示任何负类的预测,在分母中使用指数项明确地强制类别排他性。SCE鼓励改进真实类别的逻辑值并同时惩罚其他类别。这对于CAM有两个效果:
1)减少虚假阳性像素,减少不同类别之间的混淆;
2)鼓励模型探索类别特定的特征,减少虚假阴性像素。
我们在图1 (b)中展示了实证证据,SCE相对于BCE的mIoU改进在5个有蹄动物类别中尤为显著。请注意,BCE和SCE的函数是不同的。为了更具体地比较它们,我们在第4.2节中从理论和实证的角度详细比较了它们产生的梯度。
我们的解决方案:我们的解决方案是使用SCE损失函数来训练CAM模型。然而,直接将BCE替换为SCE在多标签分类任务中是没有意义的,因为不同类别的概率不是独立的。相反,我们使用SCE作为额外的损失函数来重新激活模型并生成ReCAM。具体来说,当模型使用BCE收敛时,对于图像中标记的每个单独类别,我们提取以归一化的软掩码形式的CAM,即没有硬阈值。我们分别将所有掩码应用于特征(即由主干网络输出的特征图块),每个掩码“突出显示”对于特定类别的分类有贡献的特征像素。通过这种方式,我们将多标签特征分支成一组单标签特征。我们可以使用这些特征(和标签)来训练一个带有SCE的多类分类器,例如,在主干网络之后插入另一个全连接层。SCE损失惩罚由于特征不良或掩码不良而导致的任何错误分类。然后,反向传播其梯度改进两者。一旦收敛,我们以与CAM相同的方式提取ReCAM。
实证评估。为了评估ReCAM,在语义分割的两个流行基准数据集PASCAL VOC 2012和MS COCO 2014上进行了大量的WSSS实验。WSSS的标准流程是使用CAM作为种子,然后使用改进方法(如AdvCAM或IRN)扩展种子为伪掩码 - 用于训练分割模型的标签。我们设计了以下比较来展示ReCAM的普适性和优越性。
1)ReCAM作为种子。我们提取ReCAM并在之后使用改进方法,显示在强化步骤之后仍然保持对CAM的优越性。
2)ReCAM作为另一种改进方法。我们将ReCAM与现有的改进方法进行比较,考虑生成的掩码的质量以及对基准CAM增加的计算开销。在学习语义分割模型的阶段,我们使用基于ResNet的DeepLabV2,DeepLabV3+和基于Transformer的UperNet。
本文的贡献有两个方面。
1)一种简单而有效的方法ReCAM用于生成WSSS的伪掩码。
2)对两个流行的WSSS基准数据集上的ReCAM进行了广泛的评估,包括是否结合先进的改进方法。
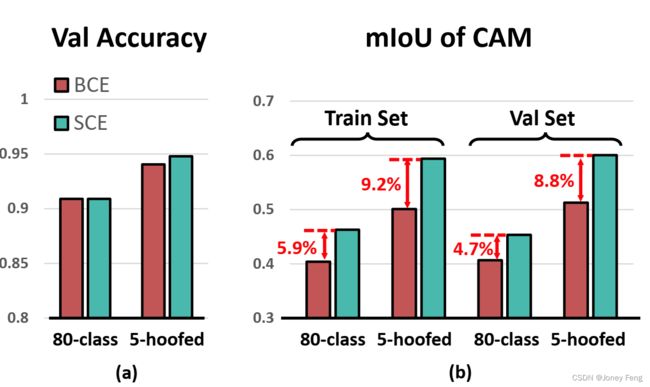
图1。我们分别使用二元交叉熵(BCE)和softmax交叉熵(SCE)损失训练了两个模型。我们的训练集和验证集仅包含MS COCO的单标签图像。“80-class”模型使用完整的标签集。“5-hoofed”模型仅在5种有蹄动物的样本上进行训练,每种动物都会导致对另一种动物的误报缺陷,例如,牛和马之间的误报。
2.相关工作
在WSSS的研究中,多标签分类和语义分割模型的训练几乎是一致的。以下,我们仅介绍种子生成和掩码细化的变体。
种子生成。Vanilla CAM [51]首先通过使用为每个单独类学习的FC权重来缩放特征图(例如,由最后一个残差块输出)。然后,通过通道平均、空间归一化和硬阈值化的方式生成种子掩码(详见第3节)。基于这个CAM,有一些改进的方法。GAIN [25]将CAM应用于原始图像上生成掩蔽图像,并在这些图像上最小化模型的预测分数,强制模型捕捉其他区域(不在当前CAM内)的特征。擦除法方法[14,20,39,49]中也使用了类似的思想。不同之处在于,擦除法直接扰动(擦除)了CAM内的区域,并将扰动后的图像输入模型生成下一轮的CAM,以期望捕捉新的区域。Score-CAM [37]是一种不同的CAM方法。它将在vanilla CAM中使用的FC权重替换为从通过通道级(而不是特定类别)激活图生成的新一组分数。EDAM [40]是一项最近使用基于CAM的扰动来优化额外分类器的工作。我们可以认为我们的ReCAM与EDAM类似。我们强调两个区别。
1)EDAM使用额外的层来生成类别特定的软掩码,而我们的软掩码仅来自CAM的副产品,无需任何参数。
2)EDAM仍然使用BCE损失进行扰动输入的训练,而我们检查了BCE的局限性,并提出了一种通过利用SCE的不同训练方法(详见第4.2节)。
掩码生成。由CAM或其变种生成的种子掩码可以经过细化步骤。一类细化方法[1,2,4,42]将种子中的对象区域传播到邻域中语义相似的像素。这是通过随机游走[33]在一个转移矩阵上实现的,其中每个元素是一个相似度分数。相关的方法对这个矩阵有不同的设计。PSA [2]是一个AffinityNet,用于预测相邻像素之间的语义相似度。IRN [1]是一个像素间关系网络,用于估计基于此计算相似度的类别边界图。另一种方法是BES [4],它通过使用CAM作为伪标签来学习预测边界图。所有这些方法都引入了额外的网络模块来改进vanilla CAM。另一类细化方法[15,17,22,26,44,48]利用显著性图[13,50]。EPS [24]提出了一种联合训练策略,将CAM和显著性图结合起来。EDAM [40]引入了一种后处理方法,将显著性图中的置信区域集成到CAM中。在实验中,我们将ReCAM插入其中,以评估其在使用额外显著性数据时的性能。一种更近期的方法利用迭代后处理来改进CAM。OOA [16]集成了多个训练迭代中生成的CAM。CONTA [45]通过整个WSSS过程进行迭代,包括一系列模型训练和推断。vCAM [23]使用相对于输入图像的梯度来扰动图像,并迭代地找到新激活的像素。总体而言,这些细化方法都是基于CAM [51]生成的种子。我们的ReCAM是一种利用SCE重新激活CAM中更多像素的方法,因此方便将其整合进去。我们在第5节进行了广泛的插入实验。
改进CAM的其他方法包括ICD [10],它在特征流形上学习了类内边界;SC CAM [3],它学习了细粒度分类模型(使用伪细粒度标签);以及SEAM [38],它强制了从图像的不同变换中提取的CAM的一致性。最近的一项工作RIB [21]根据信息瓶颈理论进行了仔细的分析,并提出了在不使用最后一个激活函数的情况下重新训练多标签分类模型。我们的ReCAM没有删除任何激活函数,而是添加了基于softmax激活的损失函数(SCE),如图3所示。另一个区别在于推理阶段。RIB需要对每个测试图像进行10次前向和后向传递,而ReCAM只需要一次前向传递。例如,在PASCAL VOC 2012 [9]数据集上,RIB的推理时间为8小时(训练时间与vanilla CAM相同),而我们相对于vanilla CAM的总计算时间只有0.6小时。
3.前提条件
CAM的第一步是使用全局平均池化(GAP)和预测层(例如,ResNet [12]的FC层)训练一个多标签分类模型。每个训练样本的预测损失通过以下公式中的BCE函数计算: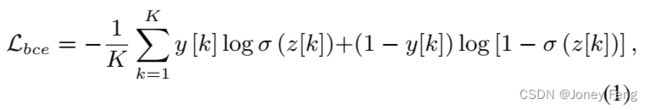
其中,z[k]表示第k类的预测logit,σ(·)是sigmoid函数,K是前景对象类别的总数(在数据集中)。y[k]∈{0,1}是第k类的图像级标签,其中1表示图像中存在该类别,0表示不存在。一旦模型收敛,我们将图像x输入模型中,提取出图像x中出现的第k类的CAM: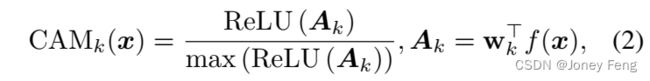
其中,wk表示与第k类对应的分类权重(例如,ResNet的FC层),f(x)表示在GAP之前的x的特征图。
请注意,为了简化起见,我们假设模型的分类头始终是一个单独的FC层,并在以下内容中使用w来表示其权重。
伪掩码。有几种方法可以从CAM生成伪掩码:
1)将CAM阈值化为0-1掩码;
2)使用IRN [1]进行细化——一种广泛使用的细化方法;
3)通过分类模型迭代地细化CAM,例如使用AdvCAM [23];
4)级联选项3和2。
在图2中,我们使用我们的ReCAM展示了这些选项。我们将在第4.1节详细介绍这些方法。
语义分割。这是WSSS的最后一步。我们使用伪掩码以全监督的方式训练语义分割模型。目标函数如下: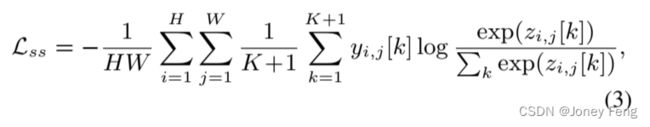
其中,yi;j和zi;j分别表示像素(i;j)处的标签和预测logit。yi;j[k]和zi;j[k]分别表示yi;j和zi;j的第k个元素。H和W分别是图像的高度和宽度,K是类别的总数,K+1表示包括背景类别。在实现上,我们使用了ResNet-101 [12]的DeepLab变体[5,6],遵循相关的工作[1,21,23,45]。此外,我们还使用了最近的模型UperNet [41],它采用了更强大的骨干网络——Swin Transformer [31]。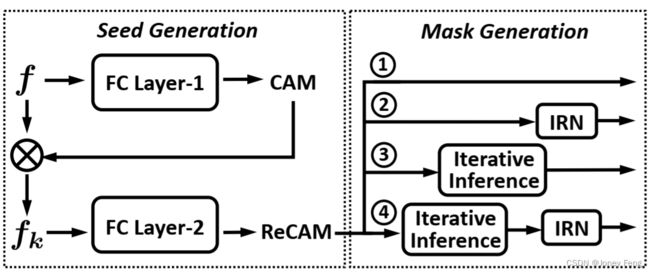
图2.使用ReCAM生成WSSS的伪掩码的流程。该流程包括两个步骤:种子生成和掩码生成。我们的ReCAM被作为一个模块插入到种子生成步骤中。掩码生成有几个选项:
1)直接使用ReCAM作为伪掩码;
2)使用最常见的细化方法IRN [1]对ReCAM进行细化;
3)通过ReCAM模型迭代地推断出更好的掩码;
4)级联选项3和2。
学习ReCAM模型的详细信息在图3中显示。表2显示了这些选项的整体比较结果。
4.类别重新激活图(ReCAM)
在第4.1节中,我们详细介绍了重新激活分类模型并从中提取ReCAM的方法。请注意,我们还使用“ReCAM”来命名我们的方法。在第4.2节中,通过理论和实证比较SCE和BCE的梯度,我们证明了在ReCAM中进行类别独占学习的优势。
4.1.ReCAM流程
骨干网络和多标签特征。我们使用标准的ResNet-50 [12]作为我们的骨干网络(即特征编码器)来提取特征,遵循相关的工作[1,21,23,45]。
给定输入图像x和其多热类标签y ∈ {0,1}^K,我们将特征编码器的输出表示为f(x) ∈ R^W×H×C。C表示通道的数量,H和W分别表示高度和宽度,K是数据集中前景类别的总数。请注意,在图3:
1)为简洁起见省略了特征提取过程;
2)特征f(x)在上方块中写为f,并且通常代表多个对象。
FC层-1和BCE损失:在传统的CAM模型中,特征f(x)首先通过一个GAP层,然后结果被馈送到一个FC层进行预测[51]。因此,预测的logits可以表示为:
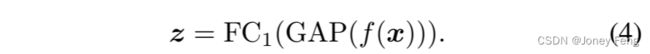
然后,使用z和图像级别标签y来计算BCE损失。其元素级的计算公式如式(1)所示。
提取CAM。给定特征f(x)和FC层对应的权重wk,我们根据公式(2)提取每个单独类别k的CAM。为简洁起见,我们将CAMk(x)表示为Mk ∈ R^W×H。
单标签特征。如图3所示,我们使用Mk作为软掩码,应用在f(x)上提取类别特定的特征fk(x)。我们计算Mk和f(x)的每个通道之间的逐元素乘法如下所示:
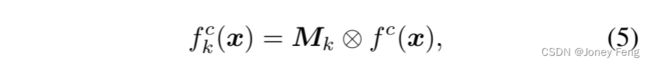
其中,fc(x)和fkc(x)表示乘法(使用Mk)之前和之后的单通道(c从1到C,C是特征图的数量,即通道数)。特征图块fk(x)(每个包含C个通道)对应于图3中的示例f1,f2,f3。
FC层-2和SCE损失。每个fk(x)都有一个单一的目标标签(即一个独热标签,其中第k个位置为1)。然后,我们将其输入到FC层-2(见图3)中,以学习多类分类器,因此我们对x有新的预测logits,如下所示:
其中,FC2具有与FC1相同的架构。通过这种方式,我们成功地将基于BCE的多标签图像模型转换为基于单标签特征的SCE模型。SCE损失的形式如下所示: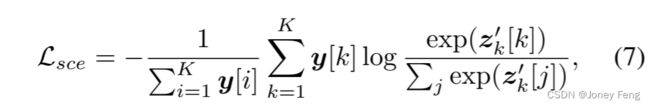
其中,y[k]和zk0[k]分别表示y和z0的第k个元素。我们使用Lsce的梯度来更新包括主干在内的模型。因此,我们重新激活BCE模型的总体目标函数如下所示:
其中,λ是平衡BCE和SCE之间的权重。请注意,由于我们需要在学习过程中使用FC1来生成更新的软掩码Mk,所以重新优化FC1与Lbce也被包括在内。
在重新激活之后,我们将图像x输入到其中,以提取每个类别k的ReCAM,如下所示: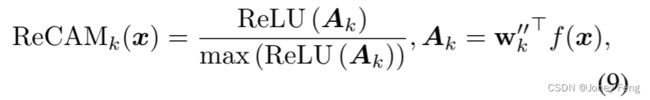
其中,w00k00k表示与第k个类别对应的分类权重。由于我们有两个FC层,我们的实现可以选择w00作为:1)w,2)w0,3)w ⊕ w0或4)w ⊗ w0,其中⊕和⊗分别表示逐元素加法和乘法。我们在第5.2节中展示了这些选项的性能。
优化ReCAM(可选)。如第3节介绍的那样,有几种方法可以优化ReCAM:1)AdvCAM [23]通过对图像x进行对抗攀爬来迭代地优化ReCAM
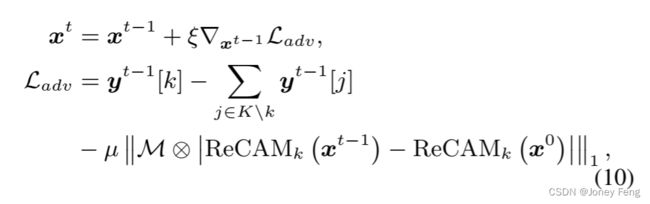
其中,t ∈ [1;T]是对抗步骤的索引,xt是第t步的扰动图像。k和j分别表示正类和负类。ξ和µ是超参数(与[23]中相同)。M =1 ReCAMk xt−1 >0.5是用于正则化的ReCAM的限制性掩码。最终经过精炼的激活图Mk0 =PT t=0 ReCAMk(xt) / PT t=0 ReCAMk(xt)max PT t=0 ReCAMk(xt),注意这里我们遵循AdvCAM [23],在公式(9)中使用未经过最大归一化的ReCAM。2)IRN [1]将ReCAM作为输入,并训练一个像素间关系网络(IR Net)来估计类别边界图B。为简洁起见,我们省略了IRNet的训练细节。然后,它使用B和转移概率矩阵T对ReCAM进行随机游走来进行精炼。
其中,t表示迭代次数,vec(·)表示向量化。最后,我们使用fMk0g作为图像的像素级标签,其中k表示图像中的每个正类,来训练语义分割模型。
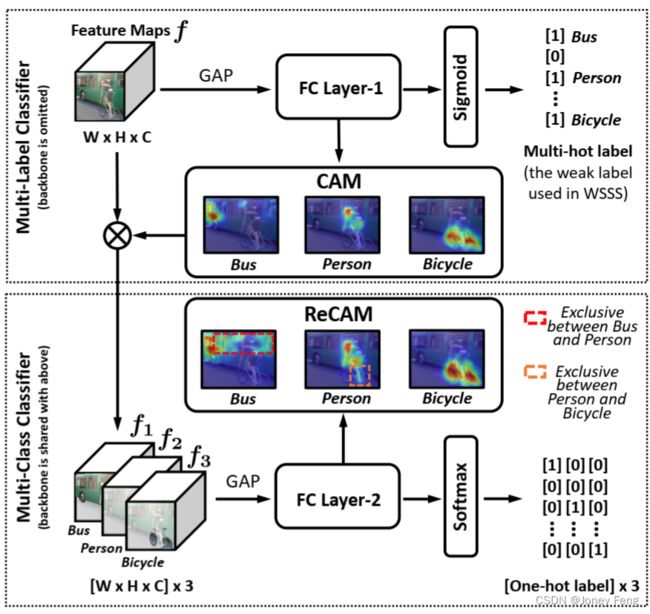
图3. ReCAM的训练框架。在上方的块中,是使用二元交叉熵(BCE)进行传统的多标签分类器训练。为了简洁起见,我们省略了通过主干网络提取特征。我们提取每个类别的CAM,然后将其应用于特征图f上(作为归一化的软掩码),以获得特定类别的特征fk。在下方的块中,我们使用fk及其单一标签,通过SCE损失学习多类别分类器。这个损失的梯度通过整个网络,包括主干网络,进行反向传播。
4.2.论据:二元交叉熵(BCE)与 softmax 交叉熵(CE)的比较
在本节中,我们将证明在ReCAM中引入SCE损失的优势。我们在理论和实证上比较了SCE和BCE在优化分类模型方面的效果。对于任何输入图像,令z表示预测的logits,y表示one-hot标签。基于导数链规则,可以推导出对于logits的BCE和SCE2损失的梯度:
其中,σsig表示sigmoid函数,σsof表示softmax函数。
从理论上讲,为了方便分析,我们考虑二分类(K=2)的情况,其中有一个正类p和一个负类q。公式(12)可以进一步推导为: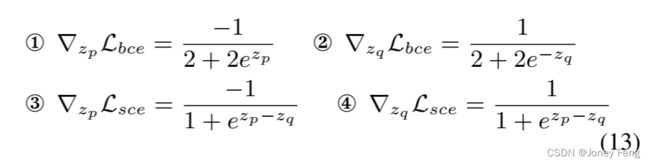
然后,我们考虑不同情况下zp和zq的情况,比较正类p(‹和fi)和负类q(›和fl)的梯度项的大小。 a) zp < zq:负类的logit远大于正类的logit。这种情况非常罕见,大多是由于错误标注导致的。在这种情况下,k‹k和k›k都小于0.5,但kfik和kflk趋近于1——SCE收敛更快。 b) zp > zq:这种情况出现在模型收敛时。所有四个梯度项都接近于0,无法区分任何差异。
接下来,我们考虑最后一种最令人困惑的情况:
c) zp ≈ zq。我们将其分为两个子情况:
c1) zp和zq都很大,例如约为10(我们在MS COCO的“5 hoofed”实验中观察到)。我们可以发现SCE损失梯度(即kfik和kflk)的大小都接近0.5,而k‹k≈0和k›k≈0.5。
c2) zp和zq都很小,例如约为-10。kfik和kflk保持不变(为0.5),但k‹k≈0.5和k›k≈0。 我们可以发现,在这两种令人困惑的情况下,SCE损失产生的梯度既鼓励预测正类,又惩罚预测负类。原因是softmax函数的分母中的指数项明确地涉及了两个类别。
基于这一点,SCE可以保证类别排他性学习——在面对困惑时同时提高正类和抑制负类的预测。相比之下,BCE每种情况都专注于正类或负类之一。它不能保证在惩罚负类时不降低正类的预测,或在鼓励正类时不提升负类的预测,导致学习效率低下,特别是对于令人困惑的类别。
经验上来看,有人可能会认为梯度的大小并不直接导致更强的优化,因为常见的优化器(如Adam [18])使用自适应学习率。为了验证SCE在实践中的有效性,我们监测了运行真实模型时的梯度。具体来说,我们回顾了“5 hoofed animals”的玩具实验,这些模型是使用Adam优化器训练的。我们计算了BCE和SCE损失的梯度(通过两个独立的模型产生),并与每个预测logit相关联。如图4所示,我们分别展示了对目标类别(即唯一的正类p)和混淆类别(即具有最高logit值的负类q)的logit的梯度。我们可以看到,SCE损失的梯度对于正类和负类的变化更加迅速,表明其模型学习更加积极和高效。

图4. 目标类别(即唯一的正类p)和混淆类别(即具有最高logit值的负类q)的logit的梯度。BCE和SCE模型都是在MS COCO训练集的“5 hoofed animal”类别上进行训练的。这些梯度是在验证集上计算的。
5.实验
5.1.数据集和设置
数据集包括常用的PASCAL VOC 2012 [9]和MS COCO 2014 [30]。VOC包含20个前景目标类别和1个背景类别。在训练集、验证集和测试集中分别有1,464、1,449和1,456个样本。参照相关工作[1,23,45],我们使用了由Hariharen等人提供的扩大的训练集,其中包含10,582个训练图像。MS COCO包含80个目标类别和1个背景类别。在其训练集和验证集中分别有80,000和40,000个样本。在这两个数据集上,我们在训练过程中仅使用它们的图像级别标签,这是WSSS中最具挑战性的设置。
评估指标。我们主要有两个评估步骤。
- Mask生成。我们为训练集中的图像生成伪造的掩码,并使用它们对应的真实掩码来计算mIoU(平均交并比)。
- 语义分割。我们训练分割模型,使用该模型对验证集或测试集中的图像进行掩码预测,并基于它们的真实掩码计算mIoU。我们还在附录中提供了F1和像素准确度的结果。
网络架构。对于掩码生成,我们遵循[1,23,45]的方法,使用ResNet-50作为主干网络,其生成的特征图大小为32×32×2048。对于语义分割,我们采用了ResNet-101(按照[1,23,45]的做法)和Swin Transformer [31](在WSSS领域首次使用)。这两个网络都是在ImageNet [8]上预训练的。我们将ResNet-101集成到DeepLabV2 [5]和DeepLabV3+ [6]中,后者的结果在附录中展示(由于空间限制)。我们将Swin集成到UperNet [41]中。
实现细节。对于掩码生成,我们使用与[1]相同的设置来训练FC Layer-1。我们通过以下方式训练FC Layer-2:在VOC数据集上将λ设置为1,在MS COCO数据集上将λ设置为0.1;在两个数据集上使用初始学习率为5e-4和多项式学习率衰减的设置进行4个epochs的训练。我们遵循IRN [1]的做法,在数据增强和权重衰减策略上保持一致。方程(10)和方程(11)中的所有超参数遵循原始的AdvCAM [23]和IRN [1]论文。对于语义分割中的DeepLabV2,我们使用与[1,21,23]相同的训练设置。具体细节请参考附录。对于UperNet,输入图像首先被统一调整为2,048×512的大小,纵横比范围从0.5到2.0,然后在馈送模型之前随机裁剪为512×512的大小。数据增强包括水平翻转和颜色抖动。我们在VOC和MS COCO数据集上分别进行了40,000和80,000次迭代的训练,批量大小为16。我们使用AdamW [32]求解器,初始学习率为6e-5,权重衰减为0.01。学习率按照多项式衰减的方式,以1.0的幂进行衰减。
5.2.结果和分析
对于FC Layer-1(FC1)或Layer-2(FC2)上的SCE。人们可能会认为,在额外的分类器FC2上应用SCE是不必要的。我们进行了在FC1上使用SCE的实验(即不使用FC2),并在表1的上半部分展示了结果。“Lbce only”是仅使用BCE损失的基准,“Lsce only”是仅在FC1上使用SCE,并将原始的多热标签修改为归一化的形式(总和为1)。例如,[1;1;0;1;0]被修改为[1/3;1/3;0;1/3;0]。“Lsce for single only”是在学习多标签图像时应用BCE,但在单标签图像(即包含一个对象类别的训练图像子集)上应用SCE。结果显示,“Lsce only”表现最差。这是因为SCE在多标签分类任务中没有意义,不同类别的概率不是独立的[47]。“Lsce for single only”将两种损失结合起来处理不同的图像,增加了方法的复杂性。此外,在实际应用中,它并没有获得很大的提升,特别是对于MS COCO数据集来说,其中单标签图像数量较少,并且是一个更一般的分割场景。
在方程(9)中使用FC1和FC2的权重。由于我们有两个FC层,我们在w00的实现中有几个选项:1)w,2)w0,3)w ⊕ w0,或4)w ⊗ w0,其中⊕和⊗分别是逐元素相加和相乘。我们在表1的下半部分展示了结果。我们可以看到,所有选项的结果都优于基准(即没有FC2的“Lbce only”)。在VOC上,使用w ⊗ w0的ReCAM获得了最佳性能。原因是逐元素相乘可以增强代表性特征图并抑制混淆的特征图。有趣的是,在MS COCO上,使用w的ReCAM比w ⊗ w0获得更好的性能。这可能是因为在这个困难的数据集上,输入到FC2的特征fk(x)较差,并且FC2训练不充分。基于这些结果,我们在VOC的所有实验中使用w ⊗ w0,在MS COCO上使用w。
值得强调的是,ReCAM的有效性在两个数据集上得到了验证。如果将第二个块中的任何一行与表1中的第一行进行比较,使用ReCAM的任何选项都会产生比基准更好的掩码。
不同λ值的影响。方程(8)中的λ控制了BCE和SCE之间的平衡。我们通过在VOC上遍历λ的值来研究ReCAM的伪掩码质量(mIoU),如图6(a)所示。我们可以观察到λ的最佳值为1,但在使用其他值时差异并不显著,即ReCAM对λ不敏感。请参考补充材料以获取更多的敏感性分析,例如学习率的分析。
ReCAM的普适性。我们以ReCAM为种子,并通过以下方式评估其普适性:
1)将其与经典的CAM进行比较-这是最常用的种子生成方法;
2)在它之后应用不同的改进方法。
从表2和表3的结果中,我们可以发现ReCAM在VOC和MS COCO上都显示出与CAM相比的一致优势。具体来说,在表2的第一行中,ReCAM在VOC上的性能比CAM高出6%。当将ReCAM作为伪掩码用于学习语义分割模型时,这个差距几乎保持不变,如表3的第一行所示。值得一提的是,在更强的分割模型UperNet-Swin上,这个差距更大,例如,在VOC验证集上,与DeepLabV2相比,使用ReCAM的差距为6.1%,而使用DeepLabV2的差距为4.7%。
关于对ReCAM的改进,我们有两个观察结果:
1)计算成本显著增加(表2),例如,通过IRN导致的增加约为4.5倍,通过AdvCAM导致的增加约为160倍(相对于基准的ResNet-50上的ReCAM);
2)在表3中有下划线数字所示,始终通过IRN的帮助获得WSSS的最佳性能。
图6(b)显示,ReCAM为单标签和多标签图像生成了更好的掩码。在添加IRN时,ReCAM的改进效果得以保持。图5展示了4个示例,在这些示例中,ReCAM缓解了我们在第1节中提到的两个问题:假阴性像素和假阳性像素。图5中最右侧的块显示了一个失败的案例:无论是CAM还是ReCAM都无法捕捉到具有遮挡或与周围环境颜色相似的对象部分,例如“dog”和“human hands”之间的区域。
ReCAM的优势。我们可以将ReCAM作为一种改进方法,并将其与相关方法(如IRN和AdvCAM)进行比较。在表2中,与AdvCAM(55.6%)相比,ReCAM在VOC上实现了可比较的结果(54.8%),但更高效-比AdvCAM快160倍(1.9秒对316.3秒)。通过添加IRN级联,ReCAM超过AdvCAM 1%(70.9%对69.9%),并且ReCAM更高效(只需8.2秒)。此外,从表4中我们可以看到,ReCAM支持不同的CAM变体,包括基于显著性的方法,实现即插即用的功能。
图5. 在VOC数据集上使用CAM和ReCAM生成的0-1掩码的可视化结果(在训练语义分割模型之前)。左侧的两个块(每个块有四列)展示了第1节中介绍的两个问题:假阴性像素和假阳性像素。红色虚线框标志着ReCAM改进的区域。最后一个块展示了一个失败案例。
表1. 上方块显示了使用不同损失函数(BCE、SCE及其混合)训练传统的多标签分类模型的mIoU结果(%)。下方块显示了使用不同权重提取ReCAM的结果:FC层1或FC层2的权重,或它们的混合变体(逐元素相加或相乘)。"rp."表示我们用于报告最终结果的选项(包括掩码改进和语义分割的mIoU)。请注意,使用其他选项(例如用于VOC的w0)的结果在补充材料中。
表2. 在VOC和MS COCO数据集上,通过伪掩码mIoU(%)和消耗时间将ReCAM与基准方法进行比较。"Time"表示从训练模型(使用预训练的ImageNet骨干网络)到生成所有训练图像的0-1掩码的总计算时间。单位时间(ut)在VOC上为0.7小时[9],在MS COCO上为5.4小时[30]。∗表示结果来自我们的重新实现(原始论文中没有MS COCO的结果)。下划线标记了我们的最佳结果。
表3. 在两个基准测试上,使用不同的分割模型进行WSSS(弱监督语义分割)的mIoU结果(%)。种子掩码可以通过CAM或ReCAM生成,掩码改进方法为行标题。我们在补充材料中提供了DeepLabV3+的结果。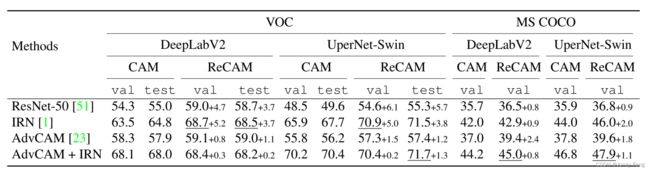
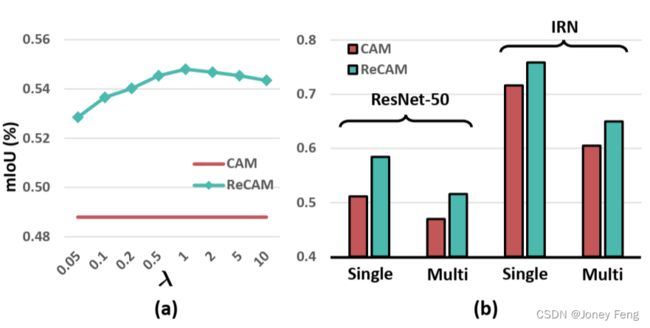
图6. (a) 在VOC上,ReCAM对方程(8)中λ值的敏感性。(b) 将表2中前两行的mIoU结果分解为单标签图像("Single")和多标签图像("Multi")的结果。
表4. 使用DeepLabV2在VOC上进行mIoU结果(%),带有或不带有显著性检测模型。在左侧,如果论文中报告了与IRN的组合,默认情况下方法包括IRN。在右侧,我们分别将ReCAM插入到EPS*(-E*)和EDAM*(-M*)中,或者等效地将它们的显著性编码模块分别添加到我们的框架中,其中*表示DeepLabV2在MS COCO上进行了预训练。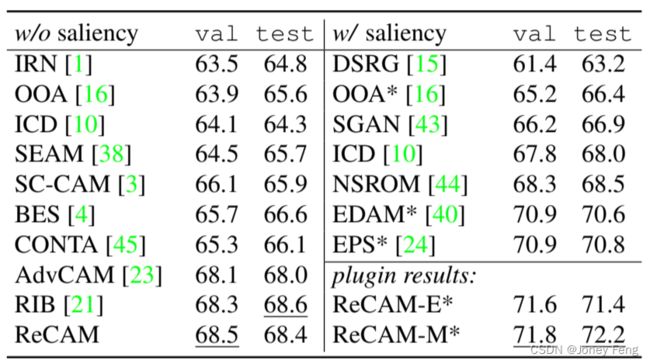
6.总结
我们从传统CAM的两个常见缺点开始。我们指出问题的关键在于广泛使用的BCE损失,并在理论上和实践中证明了SCE损失的优越性。我们提出了一种简单但有效的方法,名为ReCAM,通过将SCE插入基于BCE的模型中来重新激活模型。我们通过广泛的实验证明了它的普适性和优越性,并在两个流行的WSSS基准测试中进行了各种案例研究。
补充材料
A.关于玩具实验的更多结果
在MS COCO数据集中,有五个有蹄动物类别,包括马、羊、牛、大象和熊。我们选择只包含这些类别之一的图像,并忽略图像中出现的其他MS COCO类别(例如,包含人和马的图像将被选中,但标签为单热编码的马)。在MS COCO的训练集和验证集中,分别有6,340张和3,001张这样的图像。然后,我们使用BCE或SCE损失函数在6,430张训练图像上训练了这五类分类模型,并在3,001张验证图像上对模型进行评估(请注意,我们在主要论文中还展示了训练图像的类别激活结果(mIoU))。
B.更多WSSS结果(DeepLabV3+)
表S1呈现了在利用DeepLabV3+模型时,WSSS的mIoU(%)结果。它是对主要论文中表格3的补充。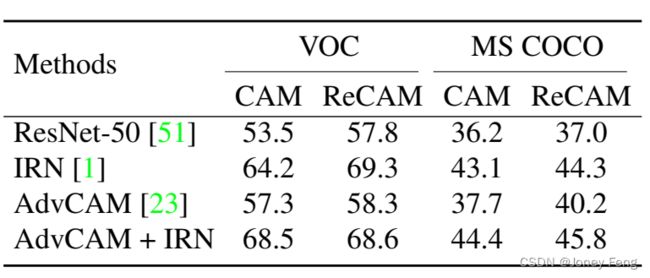
表S1:使用DeepLabV3+进行语义分割的结果(mIoU%),在VOC和MS COCO数据集上。种子掩膜是通过CAM或ReCAM生成的,然后输入到掩膜细化算法中(列标题列出)。经过细化的掩膜被用作伪标签来训练语义分割模型。最后,在验证集上评估该模型。
表S2:使用DeepLabV2在VOC和MS COCO数据集上进行语义分割的结果(mIoU%)。它用于展示使用不同的FC权重来计算ReCAM时的差异。伪蒙版(用于训练模型)可以是第一个块中的ReCAM,也可以是第二个块中使用IRN细化的ReCAM的细化蒙版。
C.ReCAM的不同权重
表S2展示了WSSS(使用DeepLabV2)应用不同的FC权重提取ReCAM时的mIoU结果(%)。我们展示了两个WSSS结果块:一个是使用ReCAM生成种子(并直接使用种子掩膜来训练WSSS模型),另一个是使用IRN进一步细化种子掩膜(然后使用细化掩膜来训练WSSS模型)。
D.两个缺陷的统计数据
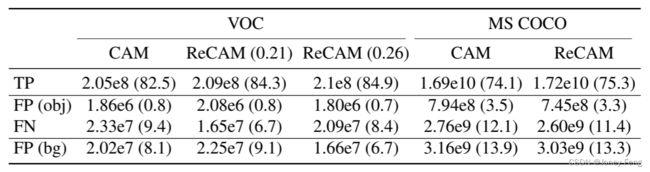
在表S3中,我们展示了主要论文中分析的两个缺陷的详细统计数据。我们还提供了TP和FP(bg)的数量作为额外的参考。值得注意的是,在将CAM阈值设置为0-1掩膜时,FP和FN之间存在权衡关系-较高的阈值会导致较少的FP和较多的FN。请注意,我们遵循AdvCAM [23]的做法,对阈值的值进行细粒度的网格搜索。表S3呈现了在VOC数据集上使用两个不同阈值的结果(主要论文中使用了阈值0.21)。我们可以看到,当将ReCAM(0.21)与CAM进行比较时,FN像素显著减少,但FP像素略微增加(包括obj和bg)。当将阈值增加到0.26时,FN和FP像素都减少了。然而,与CAM相比,整体改进有所下降(阈值0.21的mIoU为54.8%,而阈值0.26的mIoU为53.8%)。我们很高兴看到,当ReCAM在更具挑战性的数据集MS COCO上取得最佳性能时,它明显减少了FP和FN。
表S3:种子掩膜中不同像素的像素数量和百分比(%)。"TP"表示真正例。"FP (obj)"表示实际标签为其他对象类别的假正例。"FP (bg)"表示实际标签为背景的假正例。"FN"表示被错误分类为背景的假负例。每列中"TP"、"FN"和"FP (bg)"的百分比之和为100%。
E.在MS COCO数据集上的λ值
超参数λ平衡了损失函数中BCE和SCE项的影响(见主要论文中的方程(8))。我们在图S1中展示了在MS COCO上遍历λ值对结果的影响。这是对主要论文中图6(a)的补充。在MS COCO上,λ的最佳值为0.1,当使用较大的λ值(例如2)时,模型性能会大幅下降。我们在第5.2节的段落中解释了原因,该段落标题为“在方程(9)中使用FC1和FC2的权重”。
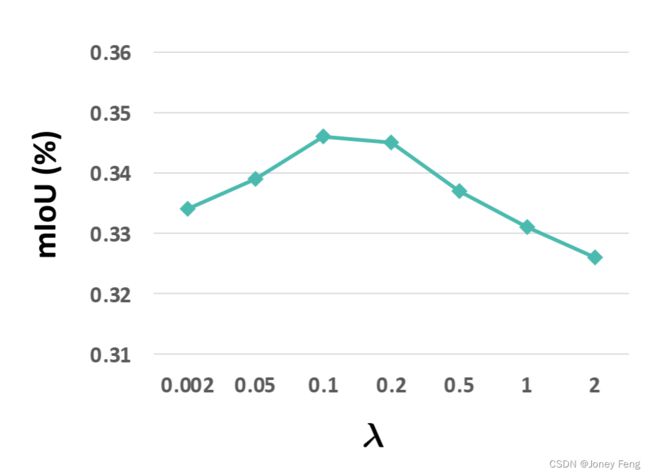
图S1:ReCAM对于MS COCO上λ值的敏感性。
F.对学习的敏感性
图S2:在不同学习率(LR)下运行实验的结果。我们通过在论文中使用的默认LR值上应用不同的缩放因子(在图S2中称为学习率比率)来实现这一点。请注意,我们对基线CAM的LR设置完全遵循了IRN [1]的设置。从图S2中可以看出,较大的LR值会使CAM的训练不稳定,并以NaN损失结束。相反,我们的ReCAM不太敏感。我们认为这是因为ReCAM中的两个FC层不是从头开始训练,而是从预训练的基线BCE模型的权重开始训练(这就是为什么我们称之为“重新激活CAM”)。我们在第5.2节的段落中强调了这个原因,该段落的标题是“在方程(9)中使用FC1和FC2的权重”。
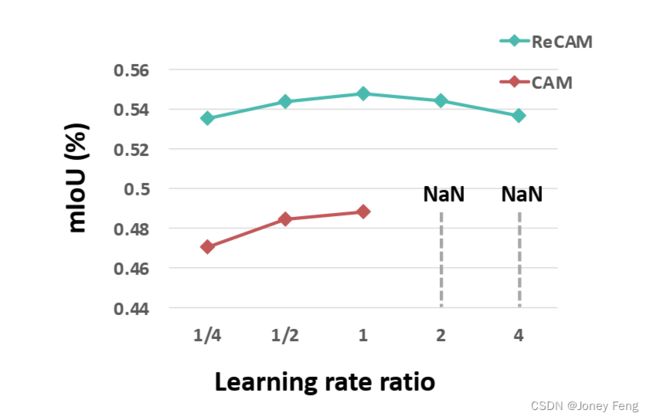
图S2:在VOC上使用不同学习率训练的CAM和ReCAM的mIoU结果。学习率比率表示应用在论文中使用的默认学习率上的标量。
G.1.BCE


G.2.CE

H.算法
ReCAM 的训练流程在算法1中,如下所示:

I.DeepLabV2的训练细节
我们在 DeepLabV2 的训练过程中补充了一些细节。参考文献 [21,23],我们将每个训练图像裁剪为大小为321×321。在 VOC 数据集和 MS COCO 数据集上分别进行了20k和100k次迭代的模型训练,批量大小分别为5和10。学习率设置为2.5e-4,权重衰减设置为5e-4。为了进行数据增强,我们使用了水平翻转和随机裁剪的方法。
J.更多定性结果
图S3展示了在VOC训练集上由CAM和ReCAM生成的热图和0-1掩码的更多定性结果。这是对主文中图5的补充。图S4展示了在VOC和MS COCO训练集上使用IRN [1]进行细化的掩码。图S5展示了在VOC和MS COCO验证集上使用语义分割(使用DeepLabV2)生成的结果掩码。