Kaggle:树叶分类(使用Jupyter)
竞赛网址:https://www.kaggle.com/c/classify-leaves
# 首先导入包
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
import matplotlib.pyplot as plt
import torchvision.models as models
# This is for the progress bar.
from tqdm import tqdm
import seaborn as sns
import albumentations
from albumentations.pytorch.transforms import ToTensorV2
from torchvision.models import resnet50, ResNet50_Weights
# 看看label文件长啥样
labels_dataframe = pd.read_csv('../input/classify-leaves/train.csv')
labels_dataframe.head(5)

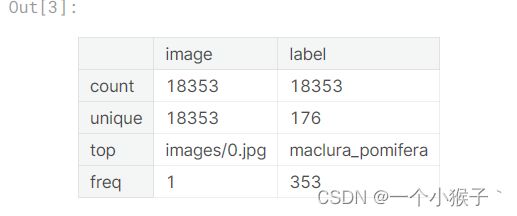
labels_dataframe.describe()
#function to show bar length
def barw(ax):
for p in ax.patches:
val = p.get_width() #height of the bar
x = p.get_x()+ p.get_width() # x- position
y = p.get_y() + p.get_height()/2 #y-position
ax.annotate(round(val,2),(x,y))
#finding top leaves
plt.figure(figsize = (15,30))
ax0 =sns.countplot(y=labels_dataframe['label'],order=labels_dataframe['label'].value_counts().index)
barw(ax0)
plt.show()

# 把label文件排个序
leaves_labels = sorted(list(set(labels_dataframe['label'])))
n_classes = len(leaves_labels)
print(n_classes)
leaves_labels[:10]

# 把label转成对应的数字
class_to_num = dict(zip(leaves_labels, range(n_classes)))
class_to_num

# 再转换回来,方便最后预测的时候使用
num_to_class = {v : k for k, v in class_to_num.items()}
# 继承pytorch的dataset,创建自己的
class LeavesData(Dataset):
def __init__(self, csv_path, file_path, mode='train', valid_ratio=0.2, resize_height=256, resize_width=256):
"""
Args:
csv_path (string): csv 文件路径
img_path (string): 图像文件所在路径
mode (string): 训练模式还是测试模式
valid_ratio (float): 验证集比例
"""
# 需要调整后的照片尺寸,我这里每张图片的大小尺寸不一致#
self.resize_height = resize_height
self.resize_width = resize_width
self.file_path = file_path
self.mode = mode
# 读取 csv 文件
# 利用pandas读取csv文件
self.data_info = pd.read_csv(csv_path, header=None) #header=None是去掉表头部分
# 计算 length
self.data_len = len(self.data_info.index) - 1
self.train_len = int(self.data_len * (1 - valid_ratio))
if mode == 'train':
# 第一列包含图像文件的名称
self.train_image = np.asarray(self.data_info.iloc[1:self.train_len, 0]) #self.data_info.iloc[1:,0]表示读取第一列,从第二行开始到train_len
# 第二列是图像的 label
self.train_label = np.asarray(self.data_info.iloc[1:self.train_len, 1])
self.image_arr = self.train_image
self.label_arr = self.train_label
elif mode == 'valid':
self.valid_image = np.asarray(self.data_info.iloc[self.train_len:, 0])
self.valid_label = np.asarray(self.data_info.iloc[self.train_len:, 1])
self.image_arr = self.valid_image
self.label_arr = self.valid_label
elif mode == 'test':
self.test_image = np.asarray(self.data_info.iloc[1:, 0])
self.image_arr = self.test_image
self.real_len = len(self.image_arr)
print('Finished reading the {} set of Leaves Dataset ({} samples found)'
.format(mode, self.real_len))
def __getitem__(self, index):
# 从 image_arr中得到索引对应的文件名
single_image_name = self.image_arr[index]
# 读取图像文件
img_as_img = Image.open(self.file_path + single_image_name)
#如果需要将RGB三通道的图片转换成灰度图片可参考下面两行
# if img_as_img.mode != 'L':
# img_as_img = img_as_img.convert('L')
#设置好需要转换的变量,还可以包括一系列的nomarlize等等操作
if self.mode == 'train':
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(p=0.5), #随机水平翻转 选择一个概率
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
else:
# valid和test不做数据增强
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_as_img = transform(img_as_img)
if self.mode == 'test':
return img_as_img
else:
# 得到图像的 string label
label = self.label_arr[index]
# number label
number_label = class_to_num[label]
return img_as_img, number_label #返回每一个index对应的图片数据和对应的label
def __len__(self):
return self.real_len
train_path = '../input/classify-leaves/train.csv'
test_path = '../input/classify-leaves/test.csv'
# csv文件中已经images的路径了,因此这里只到上一级目录
img_path = '../input/classify-leaves/'
train_dataset = LeavesData(train_path, img_path, mode='train')
val_dataset = LeavesData(train_path, img_path, mode='valid')
test_dataset = LeavesData(test_path, img_path, mode='test')
print(train_dataset)
print(val_dataset)
print(test_dataset)

# 定义data loader
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=64,
shuffle=True,
num_workers=4
)
val_loader = torch.utils.data.DataLoader(
dataset=val_dataset,
batch_size=64,
shuffle=True,
num_workers=4
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset,
batch_size=64,
shuffle=False,
num_workers=4
)
# 看一下是在cpu还是GPU上
def get_device():
return 'cuda' if torch.cuda.is_available() else 'cpu'
device = get_device()
print(device)
# 是否要冻住模型的前面一些层
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
model = model
for param in model.parameters():
param.requires_grad = False
# resnet34模型
def res_model(num_classes, feature_extract = False, use_pretrained=True):
model_ft = models.resnet34(pretrained=True, progress=True)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(num_ftrs, num_classes))
return model_ft
# 超参数
learning_rate = 1e-4
weight_decay = 1e-3
num_epoch = 20
model_path = './pre_res_model.ckpt'
# Initialize a model, and put it on the device specified.
model = res_model(176)
model = model.to(device)
model.device = device
# For the classification task, we use cross-entropy as the measurement of performance.
criterion = nn.CrossEntropyLoss()
# Initialize optimizer, you may fine-tune some hyperparameters such as learning rate on your own.
optimizer = torch.optim.Adam(model.parameters(), lr = learning_rate,weight_decay=weight_decay)
# The number of training epochs.
n_epochs = num_epoch
best_acc = 0.0
for epoch in range(n_epochs):
# ---------- Training ----------
# Make sure the model is in train mode before training.
model.train()
# These are used to record information in training.
train_loss = []
train_accs = []
# Iterate the training set by batches.
for batch in tqdm(train_loader):
# A batch consists of image data and corresponding labels.
imgs, labels = batch
imgs = imgs.to(device)
labels = labels.to(device)
# Forward the data. (Make sure data and model are on the same device.)
logits = model(imgs)
# Calculate the cross-entropy loss.
# We don't need to apply softmax before computing cross-entropy as it is done automatically.
loss = criterion(logits, labels)
# Gradients stored in the parameters in the previous step should be cleared out first.
optimizer.zero_grad()
# Compute the gradients for parameters.
loss.backward()
# Update the parameters with computed gradients.
optimizer.step()
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels).float().mean()
# Record the loss and accuracy.
train_loss.append(loss.item())
train_accs.append(acc)
# The average loss and accuracy of the training set is the average of the recorded values.
train_loss = sum(train_loss) / len(train_loss)
train_acc = sum(train_accs) / len(train_accs)
# Print the information.
print(f"[ Train | {epoch + 1:03d}/{n_epochs:03d} ] loss = {train_loss:.5f}, acc = {train_acc:.5f}")
# ---------- Validation ----------
# Make sure the model is in eval mode so that some modules like dropout are disabled and work normally.
model.eval()
# These are used to record information in validation.
valid_loss = []
valid_accs = []
# Iterate the validation set by batches.
for batch in tqdm(val_loader):
imgs, labels = batch
# We don't need gradient in validation.
# Using torch.no_grad() accelerates the forward process.
with torch.no_grad():
logits = model(imgs.to(device))
# We can still compute the loss (but not the gradient).
loss = criterion(logits, labels.to(device))
# Compute the accuracy for current batch.
acc = (logits.argmax(dim=-1) == labels.to(device)).float().mean()
# Record the loss and accuracy.
valid_loss.append(loss.item())
valid_accs.append(acc)
# The average loss and accuracy for entire validation set is the average of the recorded values.
valid_loss = sum(valid_loss) / len(valid_loss)
valid_acc = sum(valid_accs) / len(valid_accs)
# Print the information.
print(f"[ Valid | {epoch + 1:03d}/{n_epochs:03d} ] loss = {valid_loss:.5f}, acc = {valid_acc:.5f}")
# if the model improves, save a checkpoint at this epoch
if valid_acc > best_acc:
best_acc = valid_acc
torch.save(model.state_dict(), model_path)
print('saving model with acc {:.3f}'.format(best_acc))

## predict
saveFileName = './submission.csv'
model = res_model(176)
# create model and load weights from checkpoint
model = model.to(device)
model.load_state_dict(torch.load(model_path))
# Make sure the model is in eval mode.
# Some modules like Dropout or BatchNorm affect if the model is in training mode.
model.eval()
# Initialize a list to store the predictions.
predictions = []
# Iterate the testing set by batches.
for batch in tqdm(test_loader):
imgs = batch
with torch.no_grad():
logits = model(imgs.to(device))
# Take the class with greatest logit as prediction and record it.
predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist())
preds = []
for i in predictions:
preds.append(num_to_class[i])
test_data = pd.read_csv(test_path)
test_data['label'] = pd.Series(preds)
submission = pd.concat([test_data['image'], test_data['label']], axis=1)
submission.to_csv(saveFileName, index=False)
print("Done!!!!!!!!!!!!!!!!!!!!!!!!!!!")
