Python open()函数之buffering缓冲区策略
文章目录
-
- 一、buffering 缓冲策略
- 二、示例
-
- 1. 可交互文本文件
-
- 1.1 buffering=-1,行缓冲(默认)
- 1.2 buffering=0,文本模式不支持关闭缓冲区
- 1.3 buffering=1,行缓冲,同 buffering=-1
- 1.4 buffering>1,io.DEFAULT_BUFFER_SIZE
- 2. 普通文本文件
-
- 2.1 buffering=-1, io.DEFAULT_BUFFER_SIZE
- 2.2 buffering=0,文本模式不支持关闭缓冲区
- 2.3 buffering=1,行缓冲
- 2.4 buffering>1,io.DEFAULT_BUFFER_SIZE
- 3. 二进制文件
-
- 3.1 buffering=-1,io.DEFAULT_BUFFER_SIZE
- 3.2 buffering=0,关闭缓冲区
- 3.3 buffering=1,io.DEFAULT_BUFFER_SIZE
- 3.4 buffering>1,指定的大小的缓冲区
一、buffering 缓冲策略
Python中,open() 内建函数,是用来打开文件, 根据设定的参数来创造一个文件对象.
完整的格式:
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
其中 buffering参数,用来指定访问文件所采用的缓冲方式。open()函数操作的文件主要有三类:可交互文本文件、普通文本文件、二进制文件,根据文件类型的不同,缓冲策略又有差别,具体如下:
| buffering | 可交互文本文件 | 普通文本文件 | 二进制文件 |
|---|---|---|---|
-1 |
表示行缓冲,即遇到换行符就flush | io.DEFAULT_BUFFER_SIZE |
io.DEFAULT_BUFFER_SIZE |
0 |
文本模式不支持 | 文本模式不支持 | 表示关闭buffer,即不缓冲 |
1 |
表示行缓冲,即遇到换行符就flush | 表示行缓冲,即遇到换行符就flush | io.DEFAULT_BUFFER_SIZE 网上有说buffering=1时,表示1字节缓冲区??? 从测试结果看是 io.DEFAULT_BUFFER_SIZE |
>1 |
io.DEFAULT_BUFFER_SIZE |
io.DEFAULT_BUFFER_SIZE |
使用buffering设置的值作为缓冲区大小,这个值可以>io.DEFAULT_BUFFER_SIZE |
- 怎么理解可交互式文本文件?就是连接到终端设备的文件,即
fileObject.isatty()返回值为True的文件。例如:控制台的标准输出流你就可以简单的理解为一个可交互文本文件; open()函数声明中,buffering=None,表示默认缺省,等效于buffering=-1;- 在大多数系统中,
io.DEFAULT_BUFFER_SIZE默认是4096或8192字节长度。可以通过下面的代码来获取这个值
import io
print(io.DEFAULT_BUFFER_SIZE)
引用
builtins.py中open()函数注释原文:
When no buffering argument is given, the default buffering policy works as follows:
- Binary files are buffered in fixed-size chunks; the size of the buffer
is chosen using a heuristic trying to determine the underlying device’s
“block size” and falling back onio.DEFAULT_BUFFER_SIZE.
On many systems, the buffer will typically be 4096 or 8192 bytes long.- “Interactive” text files (files for which
isatty()returns True)
use line buffering. Other text files use the policy described above
for binary files.
二、示例
下面举几个示例,帮助你理解可交互文本文件、普通文本文件的buffering如何控制缓存策略的。
1. 可交互文本文件
# -*- coding:utf-8 -*-
# test.py
import datetime,time
import sys
with open(sys.stdout.fileno(),"w",buffering=-1) as f:
print(datetime.datetime.now())
for i in range(10):
time.sleep(1)
f.write("{}".format(i)*10+"\n")
print(datetime.datetime.now())
print(str(f.isatty()))
在命令行终端执行python test.py,输出结果:
1.1 buffering=-1,行缓冲(默认)
行缓冲,缓冲区内容每满一行(即遇到换行符),就刷新缓冲区,将内容转储到终端设备。
1.2 buffering=0,文本模式不支持关闭缓冲区
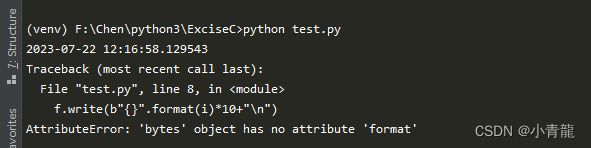
1.3 buffering=1,行缓冲,同 buffering=-1
演示效果同1.1
1.4 buffering>1,io.DEFAULT_BUFFER_SIZE
系统默认缓冲区大小 io.DEFAULT_BUFFER_SIZE
为什么最后两个
print()语句打印的结果在上面???
这是因为print()函数本身在往控制台输出内容时,有自己的缓冲策略,它有两个参数file,flush,其中默认file=sys.stdout、flush=False,也就是说它是直接连接的sys.stdout,并不经过open()函数创建的f类文件对象,因此它默认缓冲策略是sys.stdout的默认策略:行缓冲
1)可以修改上述代码中的最后两个print()语句,做验证:
print(datetime.datetime.now(),end="")
print(str(f.isatty()),file=f)
输出结果如下:
print(datetime.datetime.now(),end="")语句的数据结果在最后了,这是因为end=""去掉了换行符,没有换行符,它就一直在缓冲区待着,直到程序运行结束也没有等到换行符,于是程序结束时就自动刷新了缓冲区;
print(str(f.isatty()),file=f)语句,指定了使用open()函数创建的f类文件对象,所以它的输出同上边的for循环里的f.write(xxx)的输出,一同在with语句结束后刷新到了sys.stdout(因为内容没有达到io.DEFAULT_BUFFER_SIZE大小,所以没有立即刷新,而是with语句结束后,关闭了f文件对象,自动刷新到了sys.stdout)
2)如果你将print()的flush设置为True,如下:
print(datetime.datetime.now(),end="",flush=True)
然后再运行,你会发现,即使该条输出内容中没有换行符,但还是在该语句结束后,立刻刷新了缓冲区。也就是说,flush=True会使缓冲策略失效,变为强制刷新。无论什么缓冲策略,当程序被中断或文件对象关闭时,都会自动刷新缓冲区,这也是一种保护机制。
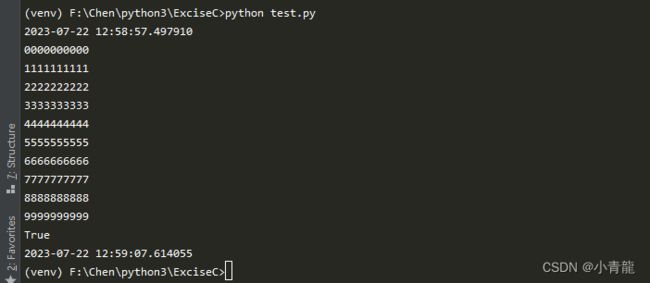
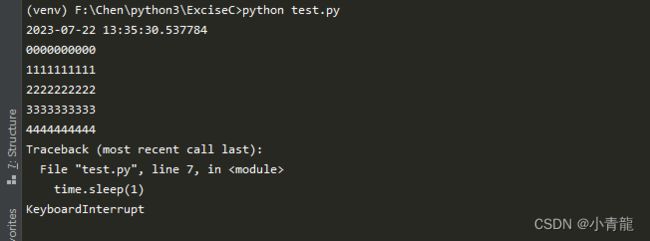
这一点你可以在运行上述代码时(buffering>1),通过CTRL+C手动中断程序来验证:
你会发现,f.write()输出到缓冲区的部分内容,在程序中断时,自动刷新了缓冲区,输出到了sys.stdout.
2. 普通文本文件
# -*- coding:utf-8 -*-
import time
with open("test.txt","w",buffering=-1) as f:
for i in range(10):
time.sleep(1)
out_str = "{}".format(i)*10+"\n"
print(out_str,end="")
f.write(out_str)
print(str(f.isatty()))
f.write(str(f.isatty())+"\n")
打开两个命令行窗口,一个执行python test.py,另一个执行tail -F test.txt(先执行这个)
2.1 buffering=-1, io.DEFAULT_BUFFER_SIZE
系统默认的缓冲区,io.DEFAULT_BUFFER_SIZE,我机器上是8192字节大小,当缓冲区内容满了后才刷新缓冲区,示例中输出的代码显然未使缓冲区填满,但是with代码块结束后,会自动关闭文件对象,文件关闭后会自动调用flush进行刷新缓冲区。所以最后,一次性将缓冲区内容写入到了设备上的文件内。
2.2 buffering=0,文本模式不支持关闭缓冲区

2.3 buffering=1,行缓冲
行缓冲,缓冲区内容每满一行(即遇到换行符),就刷新缓冲区,将内容转储到文件中。
2.4 buffering>1,io.DEFAULT_BUFFER_SIZE
演示效果同2.1
3. 二进制文件
# -*- coding:utf-8 -*-
import time
with open("test.png","bw",buffering=-1) as f:
for i in range(10):
time.sleep(1)
out_str = "{}".format(i)*10
print(bytes(out_str.encode("gbk")),end="",flush=True)
f.write(bytes(out_str.encode('gbk')))
print(bytes(str(f.isatty()).encode('gbk')),end="",flush=True)
f.write(bytes(str(f.isatty()).encode('gbk')))
3.1 buffering=-1,io.DEFAULT_BUFFER_SIZE
使用系统默认缓冲区io.DEFAULT_BUFFER_SIZE,我这里默认8192字节
可以看出,当python test.py执行完后,才一次性将缓冲区刷新,写入到test.png文件的。
3.2 buffering=0,关闭缓冲区
关闭缓冲区,内容会实时写入到文件中。
3.3 buffering=1,io.DEFAULT_BUFFER_SIZE
buffering=1,则使用默认io.DEFAULT_BUFFER_SIZE缓冲区大小,在网上有些资料说,buffering=1时,代表缓冲区大小为1字节,但是从这里的测试结果来看,buffering=1时,使用的是io.DEFAULT_BUFFER_SIZE默认缓冲区。
3.4 buffering>1,指定的大小的缓冲区
我这里将设置buffering=30进行测试
可以看出,缓冲区每满30字节,即刷新缓冲区。
python中文件IO操作
disable-output-buffering