黑马点评学习笔记
黑马点评学习笔记
- 黑马点评学习笔记
-
- 1.短信登录
- 1.1 登录
-
- 为什么要进行优化?
- 如何进行优化?
- 1.2 校验登录状态
-
- 用户信息放在本地的哪里呢?
-
- 什么是ThreadLocal?
- 补充知识点:ThreadLocal很容易造成内存泄漏问题!
- 1.3 登录拦截器
-
- 如何实现?
- 1.4 Tomcat的运行原理
- 1.5 session共享问题
-
- 我们如何解决这个问题?
- session共享应该满足以下三方面
- 1.6 redis代替session的实现
-
- 如何实现?
- 1.7 解决状态登录刷新问题
-
- 解决方案一:
-
- 一开始我们在登录的相关代码设置了有效期,但是这个存在什么问题呢?
- 但是这里会涉及一个在我们手动创建的类注入对象的问题
- 那用构造函数注入,谁来帮我们注入呢?
- 那这里怎么注入StringRedisTemplate呢?
- 那为什么不能直接在拦截器上加上@Component呢?
- 还需要注意一个问题就是:
- 解决方案二:
- 2.缓存
-
- 那么在我们的web应用开发的过程中,也是离不开缓存的
- 基于此来讨论缓存带来的一些作用和它的一些成本
黑马点评这个很早就学过了,最近在整理简历所以也对进行了笔记整理和补充
黑马点评学习笔记
1.短信登录
1.1 登录
对返回的信息(即存在session中的信息)进行优化
为什么要进行优化?
- 内存压力:session是tomcat的内存空间,这里面存的信息越多,对整个服务来讲,压力就会越大,所以将一些不重要不相关的信息存进去没必要
- 敏感信息:一般来说我们登录成功后只返回用户的账号、头像、昵称就好了,创建时间、密码、电话这些敏感信息都不需要返回,因为存在泄露风险
如何进行优化?
返回一些必要的信息即可
具体就是定义一个UserDTO,里面只有需要存储的必要信息
我们在存储到session之前,先将user转成userDTO
如何转?
正常来说,我们可以new一个dto对象,然后手动一个个存进去就好了
但是我们可以使用现成工具类BeanUtil(cn.hutool.core.bean),他有一个copyProperties方法,意思就是拷贝属性
在后面还会有将user转成map,beanToMap
1.2 校验登录状态
在检验登录状态这一步,我们需要判断用户是否存在,如果存在我们确实可以直接放行,但检验这一步不能只是白做检验这一步了,因为后续的操作可能会用到登录的用户信息,所以我们可以将登录的用户信息进行缓存,方便后面具体的业务使用
用户信息放在本地的哪里呢?
一般会把用户保存到ThreadLocal,那么后续业务就可以直接从ThreadLocal中获取
什么是ThreadLocal?
ThreadLocal就是一个线程域对象,在业务中每一个请求到达我们的服务(进入tomcat)都是一个独立的线程
如果不使用ThreadLocal会出现什么问题?
如果直接保存到一个本地变量那里就可能会出现多线程并发修改数据的安全性问题
但是使用ThreadLocal可以将数据保存到每一个线程的内部,在线程内部会创建一个map去保存,所以每一个线程都有自己独立的存储空间,那么每个请求来了之后都有自己独立的存储空间,相互之间没有干扰(这就是线程隔离)
补充知识点:ThreadLocal很容易造成内存泄漏问题!
那ThreadLocal内存泄漏问题是怎么导致的?
ThreadLocalMap中使用的 key 为ThreadLocal的弱引用,而 value 是强引用。所以,如果ThreadLocal没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,
ThreadLocalMap中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。简单来说就是
因为ThreadLocal底层是ThreadLocalMap,当线程Threadlocal作为key(弱引用),user作为value(强引用)然后jvm不会把强引用的value回收掉,所以value没被释放
如何解决内存泄漏的问题?
ThreadLocalMap实现中已经考虑了这种情况,在调用set()、get()、remove()方法的时候,会清理掉 key 为 null 的记录。使用完ThreadLocal方法后最好手动调用remove()方法什么是弱引用?
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。
在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
1.3 登录拦截器
前面的校验登录状态 我们写在了userController,但是实际上会有很多业务都需要去检验用户的登录状态
但是我们不可能在每一个业务的econtroller 中都编写这一堆校验的代码
这时就应该要想到SpringMVC中的拦截器,它可以在所有controller执行之前去做
如果我们使用了拦截器,那么用户的请求就不再能够直接访问到我们的controller,所有的请求都必须先经过拦截器,再由拦截器判断该不该放行让请求到达controller
所以有了拦截器 我们可以把校验登录状态的相关代码都放到拦截器中去做,那这样一来所有的controller都可以不用再写有关校验的代码了
但这种方法会存在一个小问题:
拦截器确实可以帮助我们实现对用户登录的校验,但是校验完之后的后续的业务中,我们可能需要用到用户信息。
我们可以在校验那一步拿到用户信息,那后续业务如何获得呢?
我们需要把在拦截器中拦截得到的用户信息传递到controller里面去,而且在传递过程中需要注意 线程的安全问题用什么来解决?
综合来看,还是用到了前面提到过ThreadLocal,我们在拦截器中可以把拦截到的用户信息保存到ThreadLocal中
如何实现?
- 实现一个接口HandlerInterceptor
- 实现三个方法preHandle前置拦截、postHandle在Controller执行之后、afterCompletion在视图渲染之后返回给用户之前
在保存用户信息的时候我们可以将ThreadLocal的相关代码写到工具类UserHolder中
在preHandle中一般放行路径存在数据库中,方便管理(但我们现在写出来)
1.4 Tomcat的运行原理
- 当用户发起请求,会访问我们向tomcat注册的端口(任何程序想要运行,都需要有一个线程对当前端口号进行监听,tomcat也不例外)
- 当监听线程知道用户想要和tomcat连接时,就会由监听线程创建socket连接,socket都是成对出现的,用户通过socket互相传递数据
- 当tomcat端的socket接受到数据后,此时监听线程会从tomcat的线程池中取出一个线程执行用户请求
- 在我们的服务部署到tomcat后,线程会找到用户想要访问的工程,然后用这个线程转发到工程中的controller、service、dao中,并且访问对应的DB
- 在用户执行完请求后,在统一返回,此时找到tomcat端的socket,再将数据写回到用户端的socket,完成请求和响应
也就是说
每个用户其实对应都是去找tomcat线程池中的一个线程来完成工作的, 使用完成后再进行回收,每个线程都是独立的(这也是为什么后面用ThreadLocal做到线程隔离,每个线程操作自己的一份数据)
1.5 session共享问题
问题:多台Tomcat并不共享session存储空间,当请求切换到到不同tomcat服务时导致数据丢失的问题
具体来说就是
每个tomcat中都有一份属于自己的session,假设用户第一次访问第一台tomcat并且把自己的信息存放到第一台服务器的session中
但是第二次这个用户访问到了第二台tomcat,那么在第二台服务器上,肯定没有第一台服务器存放的session
所以此时整个登录拦截功能就会出现问题(假设登录拦截功能部署在了第一台服务器)
我们如何解决这个问题?
-
早期方案:session拷贝
就是当任意一台服务器的session修改时,都会同步给其他的tomcat服务器的session
但是这种方案有两大问题:
- 内存损耗:每台服务器中都有完整的一份session数据,服务器压力过大
- 同步问题:session拷贝数据时,可能会出现延迟
-
基于redis完成:也就是把原先保存到session的信息,保存到redis中
session共享应该满足以下三方面
- 数据共享
- 内存存储(因为session是基于内存的所以它的读写效率比较高,例如登录校验这种访问频率比较高,如果读写效率低,是难以满足高并发的这种需求的)
- k-v结构
1.6 redis代替session的实现
如何实现?
数据类型的选择
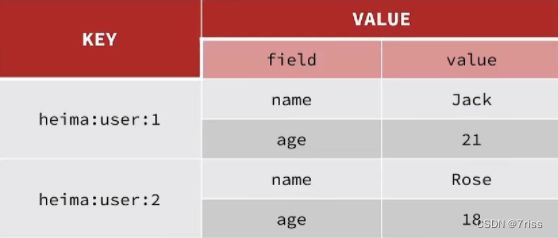
由于存入的数据比较简单,我们可以考虑使用String,或者是使用哈希,如下图,如果使用String,同学们注意他的value,用多占用一点空间,如果使用哈希,则他的value中只会存储他数据本身,如果不是特别在意内存,其实使用String就可以啦。
在redis中保存单个对象比较常见的两种方式:
String结构:
其实就是把我们的Java对象序列化为json字符串
看起来比较直观,但是把整个数据都变成一个串,字段与字段之间都耦合在了一个整体,只能对整个做curd
内存占用较多,因为这里面还会有json串的格式,例如大括号、冒号、引号等,如果这个数据越长里面包含了这种符号也越来越多会有额外的一些数据存储
哈希结构
哈希结构和String结构有比较大的差别
就是把我们Java对象中的每一个字段都作为value中的一个field和value去保存
每个字段都是独立的,我们可以针对单个字段做curd
内存占用更少,因为哈市结构只需要保存数据本身就可以了
使用String结构,就是一个简单的key,value键值对的方式
如何设计key?
在使用session保存用户信息的时候,我们使用例如code作为key,那我们在redis中也用code作为key可以吗?
这显然是不可以的
因为session有一个特点,每一个不同的浏览器在发起请求的时候都有一个独立的session,也就是说在tomccat内部维护了很多很多的session,那么不同浏览器携带的手机号来的时候都是自己独立的session,他们都以code为key,但互相之间互不干扰。
但redis是共享的内存空间,不管是谁来发起请求,在后台只有一个redis,大家都往里面存,不同的手机号都用code为key那就会一直被覆盖,因此大部分数据会丢失。
因此我们要保证每个手机号来的时候保存的key都是不一样的
那既然每个手机号都要有不同的key,那我们可以直接使用手机号作为key
这样做有两个好处:
- 确保每个手机号都有自己唯一的key
- 还有助于我们在后面获取验证码进行验证
关于取数据的问题:
因为tomcat会自动地帮我们去维护session,浏览器发起请求了,就给浏览器创建一个新session,如果session存在,就不用创建。那tomcat怎么知道你的session在哪里?创建session的时候就会自动创建sessionid写到用户浏览器的cookie,那么以后每次请求就会带着cookie、带着sessionid,那样自然就会找到session,那么就会自动从session帮助我们取出数据,这就不用担心取数据的问题
但是现在在redis中怎么取数据呢?
在redis中,我们用手机号作为key存进去了(value是验证码),那用户要进行登录的时候还得带着这个信息来取这个验证码。短信验证码登录、注册的时候用户会提交手机号和验证码,那我们根据这个手机号就能在redis中取出数据(这也是为什么我们要用手机号作为key)
但是呢如果我们采用phone:手机号这个的数据来存储当然是可以的,但是如果把这样的敏感信息存储到redis中并且从页面带过来不太合适
因此我们使用一个随机的token去存储用户数据
随机token其实就是随机字符串,例如可以用uuid来生产成
UUID这个工具类有两种,一种是java.util另一种是cn.hutool.core.lang(在这里使用了这个)
UUID.randomUUID().toString(true),不带下划线的随机值
不像session,tomcat会自动帮我们把sessionid自动写入到浏览器,我们需要自己手动将这个ttoken返回给前端(即我们在保存用户到redis之后需要返回token给客户端(浏览器))然后客户端(浏览器)就会把这个token保存下来,以后每次请求就都会携带这个token,服务器看到它拿着这个token的时候,我们就可以基于这个token来从redis中获取数据
我们把token返回给前端,前端如何确保每次都能携带token?
前端在接收到token之后,会把token保存到sessionStorage中
sessionStorage就是浏览器的一种存储方式
每次都携带的具体实现:
- 首先先从sessionStorage中获取到这个保存好的token
- 然后用拦截器(这里用的axios拦截器)实现在每次发送请求的时候把这个token作为请求头放进去(这里会起一个名字,例如authorization)
- 那么以后凡是有axios发起的这种请求,即所有的ajax请求都会携带authorization这个头,也就是token
- 将来我们在服务端就可以获取到authorization这个请求头,从而拿到token,从而去实现对于登录的验证
key的有效期
我们最好给key设置一个有效期
就像我们平时在登录的时候获取验证码 系统会提示说验证码五分钟内有效或者两分钟有效
那为什么我们要加这个限制?
因为如果我们不加以限制,这个验证码往redis中一存就不管了,那么以后每当有人登录或者注册需要发送验证码,redis里都会存这么一条数据,长期以往redis里就会存了无数条数据而且永远不删除,这样redis就会被占满
所以为了避免这样的问题发生,我们在存redis的这个key一定要设置一个有效期
设置有效期有两种方式:
- 指定时间以及时间单位
- 直接利用duration来设置有效期

1.7 解决状态登录刷新问题
解决方案一:
一开始我们在登录的相关代码设置了有效期,但是这个存在什么问题呢?
就是只要登陆成功之后过了30分钟就会失效
但我们都知道实际上用户可能会超过30min仍在活跃状态(即一直在访问不同的页面),因此有效时间也需要重新设置为30min才行,不然可能用户用着用着就失效了!
只要用户30min没有任何操作就失效否则就根据用户的操作刷新有效时间
具体的实现就是在登录拦截器上写上与有效时间相关代码
但是这里会涉及一个在我们手动创建的类注入对象的问题
在LoginIntercepter我们要设置有效期和获取用户信息就需要StringRedisTemplate,即我们需要注入StringRedisTemplate,但是这个地方的注入我们不能使用@Autoware或者@Resourse等这样一些注解,我们只能使用构造函数来去读
因为LoginInterceptor这个类它的对象是我们手动new出来的,他不是通过我们的一些component等等这些注解来去构建的,也就是说这个类的对象不是由spring创建的(由spring创建的对象,spring能帮助我们去做这种依赖注入,例如@Autoware),所以拦截器无法使用这些注解
那用构造函数注入,谁来帮我们注入呢?
那就看谁用了这个类的对象
当初是在MvcConfig里用到了它(new LoginInterceptor()),所以我们就在这里进行注入
那这里怎么注入StringRedisTemplate呢?
因为这个MvcConfig带有@Configuration注解,说明这个类将来是由spring去构建的(由spring构建的对象就能做依赖注入
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors() {
// 登录拦截器
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
);
}
}
那为什么不能直接在拦截器上加上@Component呢?
因为拦截器是一个非常轻量级的组件,只有在需要时才会被调用,并且不需要像控制器或服务一样在整个应用程序中可用。因此,将拦截器声明为一个Spring Bean可能会引导致性能下降。
拦截器是在spring容器初始haul之前执行的,加什么Component注解都没用mvc配置类的拦截器是new出来的,加注解会空指针异常
还需要注意一个问题就是:
StringRedisTemplate有一个特点是要求key和value都是String
所以当我们的数据中有不是String类型的数据要通过StringRedisTemplate存储到redis的时候就会错误,例如这里的我们要把UserDTO存储到redis中,就因为userid是Long类型而出现了类型转换的问题
因此我们在存储数据到这个map的时候
![]()
必须要确保里面的每一个值都要以String的形式存储,即map里面的key和value都必须是String类型
两种方法:
-
不用BeanUtil这个工具类,自己new一个map出来
-
还是用BeanUtil这个工具类,这个工具类允许你对key和value做自定义

但这个方案实际上是存在问题的
在这个方案中,他确实可以使用对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径,假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行
解决方案二:
既然之前的拦截器无法对不需要拦截的路径生效,那么我们可以添加一个拦截器,在第一个拦截器中拦截所有的路径,把第二个拦截器做的事情放入到第一个拦截器中,同时刷新令牌,因为第一个拦截器有了threadLocal的数据,所以此时第二个拦截器只需要判断拦截器中的user对象是否存在即可,完成整体刷新功能。
第一个拦截器:
public class RefreshTokenInterceptor implements HandlerInterceptor {
private StringRedisTemplate stringRedisTemplate;
public RefreshTokenInterceptor(StringRedisTemplate stringRedisTemplate) {
this.stringRedisTemplate = stringRedisTemplate;
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的token
String token = request.getHeader("authorization");
if (StrUtil.isBlank(token)) {
return true;
}
// 2.基于TOKEN获取redis中的用户
String key = LOGIN_USER_KEY + token;
Map<Object, Object> userMap = stringRedisTemplate.opsForHash().entries(key);
// 3.判断用户是否存在
if (userMap.isEmpty()) {
return true;
}
// 5.将查询到的hash数据转为UserDTO
UserDTO userDTO = BeanUtil.fillBeanWithMap(userMap, new UserDTO(), false);
// 6.存在,保存用户信息到 ThreadLocal
UserHolder.saveUser(userDTO);
// 7.刷新token有效期
stringRedisTemplate.expire(key, LOGIN_USER_TTL, TimeUnit.MINUTES);
// 8.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 移除用户
UserHolder.removeUser();
}
}
第二个拦截器:
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.判断是否需要拦截(ThreadLocal中是否有用户)
if (UserHolder.getUser() == null) {
// 没有,需要拦截,设置状态码
response.setStatus(401);
// 拦截
return false;
}
// 有用户,则放行
return true;
}
}
注册两个拦截器
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 登录拦截器
registry.addInterceptor(new LoginInterceptor())
.excludePathPatterns(
"/shop/**",
"/voucher/**",
"/shop-type/**",
"/upload/**",
"/blog/hot",
"/user/code",
"/user/login"
).order(1);
// token刷新的拦截器
registry.addInterceptor(new RefreshTokenInterceptor(stringRedisTemplate)).addPathPatterns("/**").order(0);
}
}
order的值越大执行的优先级越低
2.缓存
缓存的读写性能较高,这就是被用作数据交换的缓冲区的原因
比较常见的一个例子就是计算机
在计算机里主要的构造就是CPU、内存、磁盘
CPU的运算能力已经远远地超过了内存和磁盘这种读写数据的能力
但是CPU所作的任何运算都需要先从内存或者磁盘里读到数据放到自己的寄存器才可以做运算。正是因为这种数据读写能力远远地低于CPU的运算能力,所以说计算机的性能受到了限制
因此为了解决这个问题,就在CPU的内部添加了一个缓存
也就是说CPU会把经常需要读写的一些数据放到CPU的缓存里面去,那么当我们去做高速运算的时候就不需要等半天从内存和磁盘里把数据读过来再运算了,而是直接从缓存里拿到数据进行一个运算
这样就可以充分地让CPU的运算能力得到释放
因此衡量CPU是否强大的一项标准就是CPU的缓存的大小
缓存越大能缓存的数据自然也就越多,那么处理起来的性能就会越好
那么在我们的web应用开发的过程中,也是离不开缓存的
比如说作为一个外部应用,用户肯定要通过浏览器向我们发起请求
-
浏览器缓存
那么在这个时候,浏览器首先就可以建立缓存
浏览器能缓存什么东西呢?
比如我们页面的一些静态资源(我们访问一个页面,页面里面有很多的一些css、js和图片,这些东西一般都是不变的,浏览器就可以把它缓存在本地,这样就无需每次访问都要去加载这些数据了,这样就可以大大地降低网络的延迟,提高页面的响应速度,这就是浏览器缓存)
在浏览器缓存中未命中的一些数据,就会去到我们的tomcat,那也就是我们所编写的那些Java应用,
-
应用层缓存
在tomcat里面,也就是我们的Java应用,我们还可以添加应用层的缓存
什么是应用层的缓存呢?
简单来说,我们去创建一个map,然后把我们从数据库查到数据放到map以后再来的时候,直接从map里读取给你,那这样一来就减少了数据库的查询效率
所以这也是一种应用层的缓存
当然一般情况下我们不用map来做缓存,我们可以利用所需的redis来做缓存
因为redis本身的读写能力很强、速度很快,读写延迟往往在微妙的级别,所以说用它来做应用层的缓存再合适不过
-
数据库层缓存
当缓存未命中的情况下,请求依然还会落到数据库。那么数据库层面它也可以去添加缓存
数据库缓存什么呢?
缓存索引
MySQL数据库聚簇索引,他会给id创建索引,那这些索引数据我们就可以把它缓存起来
那这样一来,当我们去根据这些索引进行查询的时候,就可以在内存里快速检索得到结果,而不用每次都要去读磁盘,那么效率就会大大提升
这就是数据库层面的缓存
-
CPU的多级缓存以及磁盘
当然数据查找最终还是要落到磁盘,还有做一些复杂的排序或者是一些表关联、还会用到CPUU去做运算等
所以最终的数据库还会去访问我们的CPU和磁盘
那这时候自然就会用到我们之前提到过的CPU的多级缓存以及磁盘也可以建立读写缓存

结论:所以在整个web开发的每一个阶段都可以去添加缓存,其缓存的应用场景非常丰富,但是缓存也不能乱用,任何东西都是双刃剑,引入缓存之后带来好处但同时也会有一些成本。
基于此来讨论缓存带来的一些作用和它的一些成本
作用:
-
降低后端负载
请求进入了我们的tomcat之后,以前我们是要先去查数据库,而数据库本身因为要去做数据的磁盘读写,所以相对来讲效率是比较低的,导致了我们整个业务的延迟会比较高,特别是一些复杂也去的sql,查询起来就更慢了,这样呢往往给数据库带来比较大的压力。
这时候如果有了缓存请求,进入了tomcat之后直接在缓存里查到数据返回给前端,不用去查数据库,这对于后端来说,压力就会大大减小
-
提高读写效率,降低响应时间
像数据库的读写往往是磁盘的读写,时间往往是比较长的,那假如我们使用了缓存,例如redis,它的读写延时往往是在微秒级别的,那这个时间就会缩短,读写效率大大提高。这时候我们就能够应对更高的并发请求了。所以在一些用户量比较大、并发比较高的业务里使用缓存就能够去解决这样的高并发问题了
成本:
-
数据的一致性成本
数据本来是保存到数据库的,现在把它缓存一份放到了内存当中,比如redis,那么用户查询的时候优先去查询redis,这样可以减轻数据库压力,但是如果数据库的数据发生了变化,而这时候redis里面或者说缓存里面的数据还是旧的数据,那拿到的或者读到的就是旧数据,这时候两者就产生了不一致。如果是一些比较重要的数据不一致甚至可能会带来比较严重的一些问题,所以这就是数据的一致性的成本
-
代码维护成本
那为了解决一致性问题会给我们的代码维护带来了极大的成本,因为我们要去解决这个一致性啥的过程中需要有非常复杂的一些业务编码,而且在缓存一致性处理过程中还会出现缓存击穿等这些问题,为了解决这些问题,代码的复杂度就会提高很多,那以后开发和维护起来的成本也就越来越高
-
运维成本
为了避免缓存雪崩这样的问题,还有保证缓存的这个高可用
缓存往往会需要搭建成集群模式,而缓存集存的这样一种部署、维护就会有额外的一些人力上的成本
并且在这些集群部署的过程中还会有一些硬件成本