Linux地址空间
Linux地址空间
文章目录
-
-
- Linux地址空间
-
- 程序地址空间
- 进程地址空间
-
- 写时拷贝
- 总结
-
程序地址空间
我们在之前的语言的学习过程中有提到过程序的地址空间,它到底是什么样的呢?
我们来看下面这张图片:
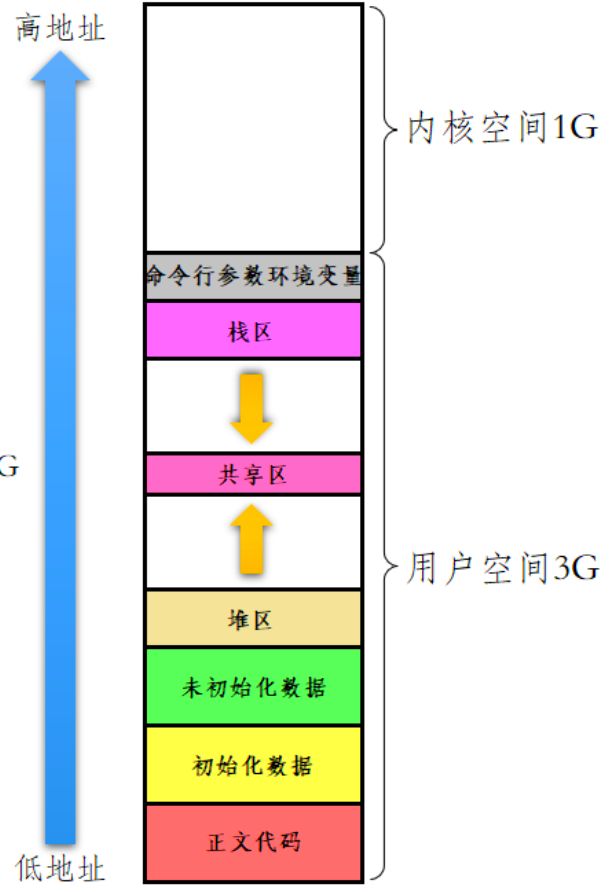
我们通过一段代码来验证一下是不是这样的:
#include 
虽然代码很粗糙,但是不难看出和这张图片基本是相符的。
我们来看另一段代码:
#include 我们用fork创建了一个子进程,在几秒后让子进程修改s_val的值,我们看看父子进程会有什么变化呢?
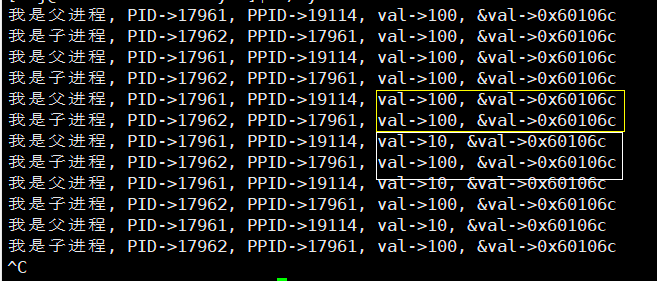
我们发现在子进程修改了s_val的值后,父进程还是输出s_val原来的值,甚至他们输出的地址还是一样的。这是为什么呢?
按照之前学的来看,同一个物理地址输出的应该是同一个值,但这里又不是相同的值。
其实这就要提出一个虚拟地址的概念了,我们在语言层面上操作的地址都不是物理地址,而是操作系统根据物理地址和页表转化过来的。我们之前也提了,操作系统不会放心给用户这么大的权限的,所以说如果你用语言写一个内存泄露,操作系统真的就会内存泄露吗?这显然是否定的。
看上去输出的同一个地址,本质其实不是相同的。

所以说我们称呼它为程序的地址空间是不够准确的,我们应该称呼它为进程的地址空间。
进程地址空间
进程地址空间本质上是一种内核数据,在Linux系统中由结构体mm_struct实现。
类比之前的那张图片,看看内核中的mm_struct是怎么实现的:
struct mm_struct
{
unsigned int code_start;
unsigned int code_end;
unsigned int init_start;
unsigned int init_end;
unsigned int uninit_start;
unsigned int uninit_end;
unsigned int heap_start;
unsigned int heap_end;
unsigned int stack_start;
unsigned int stack_end;
……
}
- code : 代码区
- init: 初始化数据区
- uninit: 未初始化数据区
- heap: 堆区
- stack: 栈区
操作系统创建进程时创建一个PCB(其中有一个结构体指针指向mm_struct)和mm_struct。
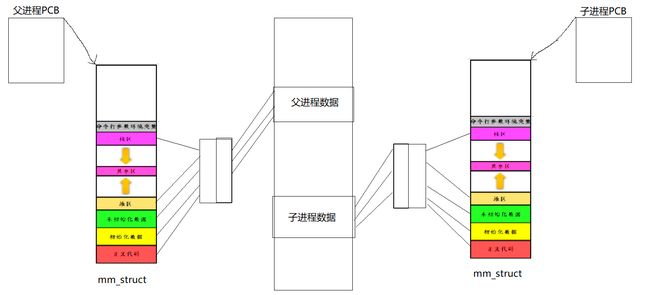
一开始子进程被创建的时候和父进程共享同一块空间,但是当子进程需要修改数据时,将父进程的数据进行拷贝,再将子进程的数据进行修改,分别通过页表映射到不同的物理地址。
写时拷贝
其中的拷贝技术就是写时拷贝。
为什么会发生写时拷贝呢?
原因是进程间有独立性,每个进程都共享相同的资源,为了达到进程间互不干扰的目的,不让子进程影响父进程,就有了写时拷贝。
一般来说,子进程不会用到父进程所有的数据,且子进程不对数据进行修改等操作,就没有必要对数据进行写时拷贝,但这不代表进程不能进行写时拷贝。况且在必要时才对数据进行写时拷贝也能提高空间的利用率。
总结
为什么有进程地址空间?
- 有了进程地址空间后,不会出现进程间的错误访问问题了。因为页表只会映射属于各个进程自己的物理地址区间。
- 每个进程看到的都是基本完全相同的空间,包括进程地址的划分等。(可以参考上一张图片)
- 给每个进程进行洗脑,让它们认为自己独占整个内存空间,能够更好的完成进程的独立性以及进程调度和内存管理。
创建一个进程实际上就是创建了PCB(task_struct)、mm_struct和页表。