postgresql_internals-14 学习笔记(七)—— parallel 并行
不完全来自这本书,把查到的和之前的文章重新汇总整理了一把。
一、 并行简介
1. 优点
- 充分利用系统资源,为慢查询提速
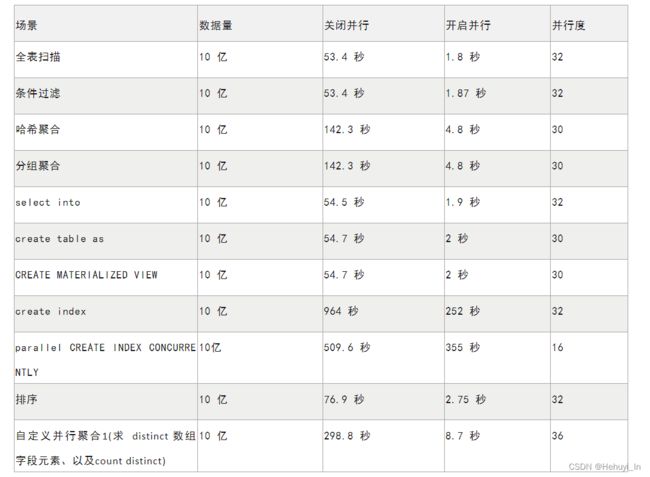
- 理想情况下,未达上限时提速几乎能与并行度线性相关,一些例子:
2. 缺点
- 过于简单的语句使用并行可能更慢
- 并行+并发度过高容易打爆CPU和内存
- 如果系统本身负载较高,并行可能会适得其反
3. 支持并行的功能
参考:PostgreSQL: Feature Matrix
4. 无法使用并行的语句
- 涉及修改和锁定数据的语句:update,delete,select for update
例外命令:以下语句可以在查询部分用到并行 CREATE TABLE ... AS,SELECT INTO,CREATE MATERIALIZED VIEW,REFRESH MATERIALIZED VIEW
- 隔离级别为串行化
- 可以被暂停的语句
- 用DECLARE CURSOR创建的游标
- FOR x IN query LOOP .. END LOOP形式的 PL/pgSQL 循环
- 在并行查询中调用的函数内部的查询(避免worker数递归增长)
- 定义了parallel unsafe的函数:默认包括所有用户函数及部分标准函数
SELECT * FROM pg_proc WHERE proparallel = 'u';5. 并行受限的语句
计划中可并行部分越多,潜在的性能增益就越大。然而,某些操作仅能由leader进程严格顺序执行,即使它们本身不会干扰并行化。换句话说,它们不能出现在Gather节点下面的计划树中。
- 无法展开的子查询
最明显的案例是扫描CTE结果(在计划中表示为CTE扫描节点):

如果CTE部分没有物化,执行计划不包括CTE scan节点,则不会应用此限制

- 临时表,不支持并行扫描

- 定义了parallel restricted的函数,只允许使用串行
SELECT * FROM pg_proc WHERE proparallel = 'r';二、 并行进程数
几个容易弄混的进程和参数,关系图如下
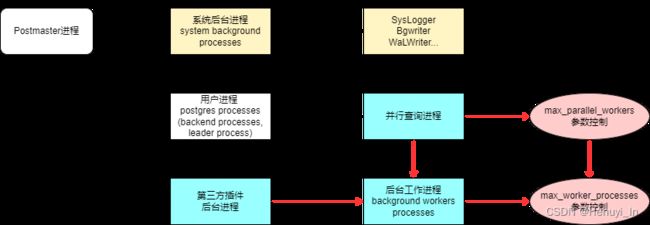
1. max_worker_processes
- 整个实例可以同时运行的Background workers Processes最大数量
- 默认值为8,设置为0表示禁用并行,重启数据库生效
- 备库上此参数值必须 >= 主库
- 修改后重启生效,建议一起修改max_parallel_works和max_parallel_works_per_gather
Background workers Processes:
虽然名字里也带Background字样,但它不包含SysLogger,Bgwriter,WaLWriter等系统后台进程,主要是动态启动的进程:例如并行查询进程,插件的后台进程等,即图中蓝绿色部分
2. max_parallel_workers
- pg 10新增
- 整个实例 并行查询进程(参考上图)可以同时运行的最大数量
- 也就是说它是max_worker_processes的一部分,因此其值不能大于max_worker_processes(大于则无效)
- 默认值为8,设置为0表示禁用并行,修改不需重启
max_parallel_workers代表的是最多的worker数量,设置为1代表有1个worker,加上主进程一起其实并行度为2;设置为0,才会只有主进程,才是串行。它其实是主进程最多可以fork的进程数量?如果最多可以fork出一个,实际上是有两个进程
Workers Launched: 1 不代表是串行,而是主进程fork了一个子进程,加上主进程一起其实并行度为2
3. max_parallel_workers_per_gather
- 单条QUERY中,每个EXEC NODE最多能开启多少个并行worker
- 默认值为2,设置为0表示禁用并行,修改不需重启
- 不要设置太大(推荐1-4),每个worker都会消耗同等的work_mem,可能争抢严重
- 其值不超过max_work_processer和max_parallel_works
三个参数大小关系为
max_worker_processes>=max_parallel_workers>=max_parallel_workers_per_gather
4. max_parallel_maintenance_workers
- pg 11新增
- 用于并行创建索引(只支持btree类型)
- 默认是2,在满足并行条件时会使用两个worker执行
- 配合maintenance_work_mem参数,可以有效提升创建索引的速度。
二、 何时可以使用并行
1. 并行最小表大小
并行最小表大小取决于min_parallel_table_scan_size参数,除非创建表时指定了并行参数,否则小表不用并行。计算公式为:

这意味着每当表增大3倍,就会多用一个并行进程(不超过上限时):
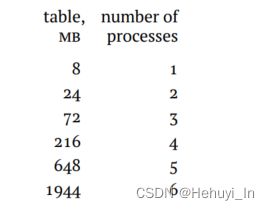
一些案例


如果取消限制,则能使用3个进程

如果将max_parallel_workers限制为5,并且执行两个上面语句,其中一个实际只能分配到两个worker,因为3+2已经达到5的上限
强制使用并行
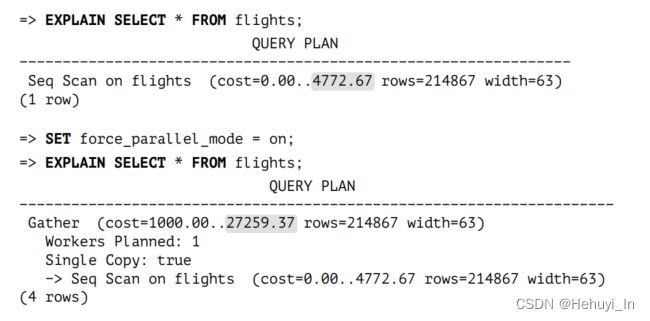
三、 并行执行计划代价预估
- 如果有需要,可以关闭parallel_leader_participation,以禁止leader进程生成并行执行计划
- 并行有额外的代价,因此并不是所有语句都适合用并行
- 即使可以使用并行执行计划,也不代表其中每部分都会用到并行,也可能会存在串行的部分
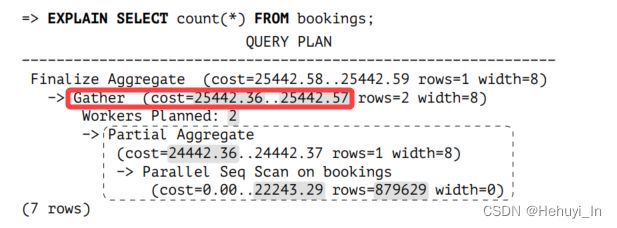
1. 执行计划简介
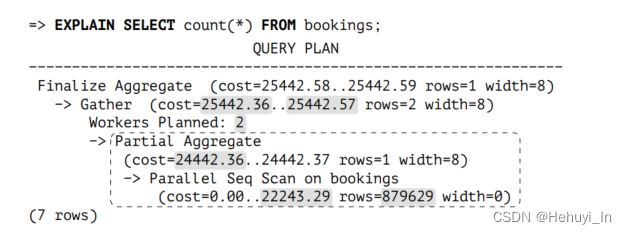
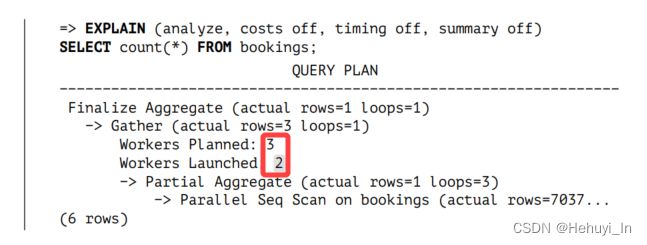
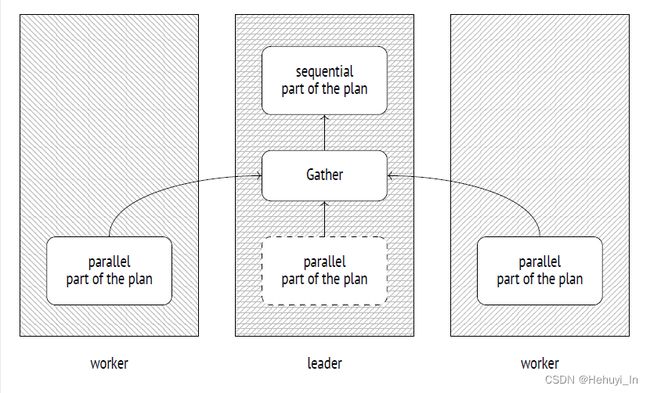
- Gather下的所有节点(node) 均为并行执行计划的部分,由并行worker和leader进程执行。本例中worker为2 (workers planned: 2),leader进程数为1,因此总并行度应该是3而不是2
- Gather节点本身和其上方的所有节点为执行计划中的串行部分,仅由leader进程执行
- rows=部分表示每个进程(包括worker和leader进程)处理的预估行数,leader进程处理的行数会略少
2. 并行全表扫描部分
在本例中factor是2.4,行数预估算法
SELECT reltuples::numeric, round(reltuples / 2.4) AS per_process FROM pg_class WHERE relname = 'bookings';
预估算法
SELECT round((relpages * current_setting('seq_page_cost')::real +reltuples / 2.4 * current_setting('cpu_tuple_cost')::real)::numeric, 2) FROM pg_class WHERE relname = 'bookings';
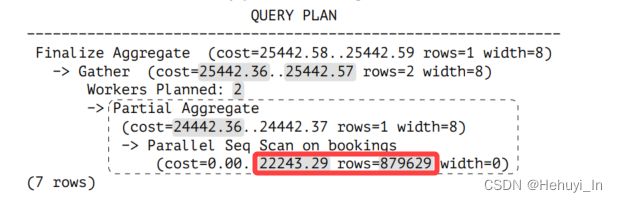
3. 聚集部分
WITH t(startup_cost)
AS (SELECT 22243.29 + round((reltuples / 2.4 * current_setting('cpu_operator_cost')::real)::numeric, 2) FROM pg_class WHERE relname = 'bookings')
SELECT startup_cost,startup_cost + round((1 * current_setting('cpu_tuple_cost')::real)::numeric, 2) AS total_cost FROM t;
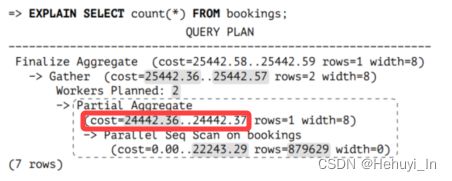
4. Gather节点
Gather节点由leader进程执行,负责启动worker进程并收集它们返回的数据。
就执行计划而言,启动进程的成本估计(无论其数量如何)由parallel_setup_cost参数定义,进程之间每传输1行的成本估计为parallel_tuple_cost。
在这个例子中,启动成本(用于启动进程)占优势;这个值会被添加到Partial Aggregate节点的启动成本中。总成本还包括传输两行的成本,被添加到Partial Aggregate节点的总成本中。
SELECT 24442.36 + round(current_setting('parallel_setup_cost')::numeric,2) AS setup_cost,
24442.37 + round(current_setting('parallel_setup_cost')::numeric +2 * current_setting('parallel_tuple_cost')::numeric,2) AS total_cost;
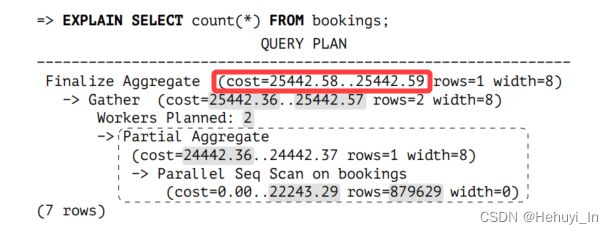
5. 最终聚集部分(Finalize Aggregate)
Finalize Aggregate节点汇总了Gather节点从并行进程中接收到的所有结果。
它的启动成本基于汇总三行的成本;这个值会被添加到Gather节点的总成本中(因为需要所有行才能计算结果)。Finalize Aggregate的总成本还包括返回一行的成本。
WITH t(startup_cost) AS (SELECT 25442.57 + round((3 * current_setting('cpu_operator_cost')::real)::numeric, 2) FROM pg_class WHERE relname = 'bookings')
SELECT startup_cost,startup_cost + round((1 * current_setting('cpu_tuple_cost')::real)::numeric, 2) AS total_cost FROM t;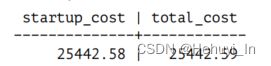
6. 依赖关系
成本估计之间的依赖关系取决于节点是否需要在将结果传递给父节点之前累积数据。
- 聚合操作在获取所有输入行之前无法返回结果,因此其启动成本基于下层节点的总成本
- Gather节点在获取到行之后立即开始向上游发送,因此其启动成本基于下层节点的启动成本,总成本则基于下层节点的总成本

四、 其他并行参数
1. parallel_setup_cost
启动并行worker的cost,启动并行worker需要建立共享内存等操作,属于额外成本,默认为1000。
2. parallel_tuple_cost
- 优化器通过并行进程处理一行数据的成本,默认是0.1。
- 表示每个Tuple从worker传递给leader的代价,即worker将一个tuple放入共享内存队列,然后leader从中读取的代价,默认值为0.1
- 进程间的row交换成本,按node评估的输出rows来乘。
3. min_parallel_table_scan_size
pg 10新增(9.6版本名为min_parallel_relation_size),开启并行的条件之一,表占用空间小于此值可能不会开启并行,并行顺序扫描场景下扫描的数据大小通常等于表大小,默认值8MB。
注意还有其他条件决定是否启用并行,所以并不是小于它的表就一定不会启用并行。
4. min_parallel_index_scan_size
pg 10新增,开启并行的条件之一,实际上并行扫描不会扫描索引所有数据块,只是扫描索引相关数据块,默认值512KB。
5. force_parallel_mode
强制开启并行,可以用于测试,也可以作为hint,OLTP生产环境不建议开启。
6. enable_partitionwise_aggregate
并行分区表分区聚合
7. enable_parallel_hash
并行HASH计算
8. enable_partitionwise_join
并行分区表JOIN
9. parallel_leader_participation
LEADER主动获取并行WORKER的返回结果
10. enable_parallel_append
并行APPEND(分区表),UNION ALL查询
11. parallel_workers
前面都是数据库的参数,parallel_workers是表级参数,可以在建表时设置,也可以后期设置。
参考
初探PostgreSQL中的并行
PostgreSQL 9.6 并行计算 优化器算法浅析-阿里云开发者社区
PostgreSQL: Feature Matrix
PostgreSQL 11 并行计算算法,参数,强制并行度设置-阿里云开发者社区
Postgresql 并行查询原理与实践_pg并行查询_瀚高PG实验室的博客-CSDN博客